Chapter 4 The Structures of DNA 1 2


























")
 ccc.")

















 stretches of")








 A cartoon of the hammerhead secondary structure")
















 Three views of the structure of the")

: A short amino acid sequence with characteristic properties, often those")





 • Lymphocyte Enhancer Factor-1 (LEF-1), which regulates T-cell gene expression")





- Slides: 87
Chapter 4 The Structures of DNA 1
2
3
4
Phosphodiester linkage: repeating sugar-phosphate backbone. 5
6
Tautomeric states The capacity to form an alternative tautomer is a frequent source of errors during DNA synthesis 7
8
Hydrogen bonding is important for the specificity of base pairing • Hydrogen bond formation between two DNA strands creates disorder (water) and increases entropy, thereby stabilizing the double helix. • Stacking – Relatively water-insoluble bases are flat – Perpendicular to the direction of the helix axis – Electron cloud interaction (π-π) between bases contribute significantly to the stability of the double helix. 9
An A: C base pair would be unstable because water would have to be stripped off the donor and acceptor groups without restoring the hydrogen bond formed within the base pair. 10
Base flipping • Enzymes involved in homologous recombination and DNA repair are believed to scan DNA for homology or lesions by flipping out one base after another. • This not energetically expensive because only one base is flipped out at a time. • DNA is more flexible than might be assumed at first glance 11
DNA is usually a right-handed double helix DNA has 10. 5 base pairs per turn of the helix in solution 12
The Double Helix has Minor and Major Grooves • The DNA is a long extended polymer with two grooves that are not equal in size to each other. – Minor and major grooves • The angle at which the two sugars protrude from the base pairs (i. e. the angle between the glycosidic bonds) is about 120° (for the narrow angle) or 240° (for the wide angle). • As a result, as more and more base pairs stack on top of each other, the narrow angle between the sugars on one edge of the base pairs generates a minor grove and the large angle on the other edge generates a major groove. 13
14
The major groove is rich in chemical information A: hydrogen bond acceptor D: hydrogen bond donors H: nonpolar hydrogen M: methyl group 15
16
In right-handed DNA, the glycosidic bond is always in the anti conformation. In the left-handed helix, the fundamental repeating unit usually is a purine-pyrimidine dinucleotide, with the glycosidic bond in the anti conformation at pyrimidine residues and in the syn conformation at purine residues. 17
18
19
DNA denaturation curve 20
Dependence of DNA denaturation on G + C content and on salt concentration Red: low concentration of salt Green: high concentration of salt 21
DNA Topology • The number of times one strand would have to be passed through the other strand in order for the two strands to be entirely separated from each other is called the linking number (Lk) • The linking number, which is always an integer, integer is an invariant topological property of covalently closed, circular DNA (ccc. DNA), no matter how much the shape of DNA molecule is distorted. 22
Linking Number is Composed of Twist and Writhe • The linking number is the sum of two geometric components called the twist (Tw) and the writhe (Wr). • Twist is simply the number of helical turns of one strand about the other, that is, the number of times one strand completely wraps around the other strand. – The helical crossovers (twist) in a right-handed helix are defined as positive such that the linking number of DNA will have a positive value. 23
Writhe • Writhe is that the long axis of the double helix crosses over itself, often repeated in three-dimensional space. • Interwound or plectonemic writhe is that the long axis is twisted around itself. • Toroid or spiral twist is that the long axis is wound in a cylindrical manner, as often occurs when DNA wraps around protein. 24
Interwound writhe Toroidal writhe 25
• Interwound writhe and spiral writhe are topologically equivalent to each other and are readily interconvertible geometric properties of ccc. DNA. • Twist and writhe are interconvertible. • A molecule of ccc. DNA can readily undergo distortions that convert some of its twist to writhe or some of the writhe to twist without the breakage of any covalent bonds. 26
• The only constraint is that the sum of the twist number (Tw) and the writhing number (Wr) must remain equal to the linking number (Lk). • Lk = Tw + Wr 27
• Lko is the linking number of fully relaxed (free of supercoiling) ccc. DNA under physiological condition. • The extent of supercoiling is measured by the difference between Lk and Lko, which is called the linking difference – ∆Lk = Lk - Lko – If ∆Lk < 0, 0 the DNA is said to be negatively supercoiled – If ∆Lk > 0, the DNA is positively supercoiled • Superhelical density is defined as σ = ∆Lk/Lko 28
• Circular DNA molecules purified from both bacteria and eukaryotes are usually negatively supercoiled, having values of σ of about -0. 06. • Negative supercoils can be thought of as a store of free energy that aids in processes that require strand separation, such as DNA replication and transcription. • Because Lk = Tw + Wr, negative supercoils can be converted into untwisting of the double helix. – Regions of negatively supercoiled DNA, therefore, have a tendency to partially unwind. – Thus, strand separation can be accomplished more easily in negatively supercoiled DNA than in relaxed DNA. 29
30
Nucleosomes Introduce Negative Supercoiling in Eukaryotes • The double helix is wrapped almost two times around the outside circumference of a protein core in left-handed manner. • It turns out that writhe in the form of left-handed spirals is equivalent to negative supercoils. • Thus, the packaging of DNA into nucleosomes introduces negative superhelical density. 31
Topoisomerase • The linking number is an invariant property of topologically constrained DNA. • The linking number can only be changed by introducing interruptions into the sugarphosphate backbone. • Topoisomerases can introducing transient single-stranded (topoisomerase I) or double-stranded (topoisomerase II) breaks into the DNA. 32
• Topoisomerase II requires ATP, whereas topoisomerase I do not requires ATP to remove supercoils. • DNA gyrase is a special topoisomerase II to introduce, rather than remove supercoils in prokaryotes. • DNA gyrase is responsible for the negative supercoiling of chromosomes in prokaryotes 33
Schematic mechanism of action for topoisomerase II 34
Schematic mechanism of action of topoisomerase I 35
• Catenation: replication of circular DNA • Entangled DNA: replication of linear DNA • Knotted DNA: sitespecific recombination 36
Two subunit is required. ATP hydrolysis for activity, the energy released by this hydrolysis is used to promote conformational changes in the topoisomerase-DNA complex rather than to cleave or rejoin DNA. 37
Model for the reaction cycle catalyzed by a type I topoisomerase 38
DNA molecules of the same length but of different linking number are called DNA topoisomers can be separated by agarose gel electrophoresis 39
Relaxed and supercoiled DNA topeisomers are resolved by gel electrophoresis. The speed with which the DNA molecules migrate increases as the number of superhelical turns increase. 40
• Ethidium causes DNA to unwind by 26°, reducing the normal rotation per base pair from ~36° to ~10°. • Ethidium decreases the twist of DNA • 36 base per turn when saturated with ethidium • For ccc. DNA, this decreases in Tw must be compensated by increasing in Wr. • Addition of ethidium will relax DNA 41
• Binding of ethidium increases Wr, its presence greatly affects the migration of ccc. DNA during gel electrophoresis. • In the presence of nonsaturating amount of ethidium, negatively supercoiled circular DNAs are more relaxed and migrate more slowly, whereas relaxed ccc. DNAs become positively supercoiled and migrate more rapidly. 42
Chapter 5 The Structure and Versatility of RNA 43
RNA contains ribose and uracil and is usually single-stranded • The backbone of RNA contains ribose rather than 2’-deoxyribose. • RNA contains uracil in place of thymine. – Thymine is in effect 5 methyl-uracil. • RNA is usually found as a single polynucleotide chain. 44
45
In an RNA molecule having regions of complementary sequences, the intervening (noncomplementary) stretches of RNA may become “looped out” to form one of the structures illustrated in the figure: a bulge, an internal loop, or a hairpin loop. RNA chains fold back on themselves to form local regions of double helix similar to A-form DNA The presence of 2’ hydroxyls in the RNA backbone prevents RNA from adopting a B-form helix.
Base-stacking interactions promote and stabilize the tetraloop structure. The gray circles between the riboses shown in purple represent the phosphate moieties of the RNA backbone. Horizontal lines represent base-stacking interactions. 47
Pseudoknot The Pseudoknot structure is formed by base pairing between noncontiguous complementary sequences. 48
Non-Watson-Crick base pair G: U base pair N 3 of uracil and the carbonyl on C 6 of guanine Carbonyl on C 2 of uracil and N 1 of guanine 49
• A thermosensor for virulence gene expression. • The prf. A regulatory gene in L. monocytogenes is controlled at the level of translation by temperature-dependent unmasking of the ribosome-binding site (RBS). • The blue ellipses represent ribosome subunits.
Triple Base Pairing 51
• RNase P cleaves off a leader segment from the 5’ end of the precursor RNA in helping to generate the mature and functional t. RNA. • RNase P is composed of both RNA and protein; however, the RNA moiety alone is the catalyst. • The protein moiety of Rnase P facilitates the reaction by shielding the negative charges on the RNA so that it can bind effectively to its negatively charged substrate. • The RNA moiety is able to catalyze cleavage of the t. RNA precursor in the absence of the protein if a small, positively charged counterion, such as the peptide spermidine, is used to shield the repulsive, negative charges.
Structure of RNase P The crystal structure of a bacterial ribonuclease P holoenzyme, illustrated here, shows the RNA subunit (in purple) and the protein subunit (in blue) in complex with t. RNA (in yellow). Metal ions in the catalytic center are shown as small red spheres.
The Hammerhead Ribozyme Cleaves RNA by the Formation of a 2’, 3’ Cyclic Phosphate • The hammerhead is a sequence-specific ribonuclease that is found in certain infectious RNA agents of plants known as viroids, which depend on self-cleavage to propagate. • When the viroid replicates, it produces multiple copies of itself in one continuous RNA chain. • Single viroids arise by cleavage, and this cleavage reaction is performed by the RNA sequence around the junction. • One such self-cleaving sequence is called the “hammerhead” because of the shape of its secondary structure.
Structure of the hammerhead ribozyme (Upper left) A cartoon of the hammerhead secondary structure with its three stems highlighted in color. (Dotted lines) Watson–Crick base-pair interactions; (orange with arrow) the scissile bond at C 17. (Diagonal lines) Extrahelical interactions. (Right) The 3 D structure of the hammerhead with a magnesium(red) in the catalytic center. This view of the structure shows stem I (top right), stem II (middle left), and stem loop III (bottom) with the colors corresponding to those in the cartoon. The site of cleavage is at cytosine 17 (C 17).
Chapter 6 The Structure of Proteins 56
Four levels of Protein Structure 57
The common structural features of amino acids 58
59
Figure 6 -3
61
Figure 6 -4
63
Ramachandran Plot
Helices • • Right-handed helix Repeating every 5. 4Å along the helical axis Each turn of the -helix has 3. 6 amino acid. Every backbone N-H group donates a hydrogen bond to the backbone C=O group of the amino acid four residues earlier ( i + 4 — i hydrogen bonding) • Proline has a cyclic chemical structure – Proline is a helix-breaking residue • The side chains project away from the helix. 65
66
-sheet • -sheet is a highly extended form of the polypeptide bond. • Stabilization of the -sheet structure comes from alignment of regions of polypeptide in this extended conformation such that hydrogen bonds can form between carbonyl groups of one strand NH groups of adjacent strand. • Typically, a region of -sheet is composed of four to six separate stretches of polypeptide, each eight to ten amino acids in length. 67
68
parallel sheet antiparallel sheet 69
The Tertiary Structure • The tertiary structure of a protein refers to the usually compact, three dimensionally folded arrangement that the polypeptide chain adopts under physiological conditions. • Segments of the chain may be a helices or strands; the rest have less regular conformations (e. g. , turns or loops between secondary-structure elements that allow these elements to pack tightly against each other). 70
Quaternary Structure • Subunit • Protomer • oligomer 71
The yeast transcription factor GCN 4. (a) Three views of the structure of the GNC 4 coiled-coil. (Left) Representation that shows chemical bonds as sticks and atoms as junction, with carbon in gray, oxygen in red, and nitrogen in blue. The carboxyl termini of the two identical polypeptide chains are at the top. Note the ladder of hydrophobic side chains (mostly gray) at the interface between the two helices. (Center) Representation with polypeptide backbone as an idealized ribbon and side chains as sticks. Note that the two chains coil very gently around each other. (Right) The same representation as in the center, but viewed end-on from the top. (b) Structure of the GCN 4 complex with DNA, illustrating the disorder-to-order transition of the so-called “basic region” —the segment amino-terminal to the coiled-coil, which, upon binding, folds into an a helix in the major groove of DNA.
Domain • A part of a polypeptide chain with a folded structure that does not depend for its stability on any of the remaining parts of the protein. • Each domain generally falls within the 50 - to 300 -residue 73
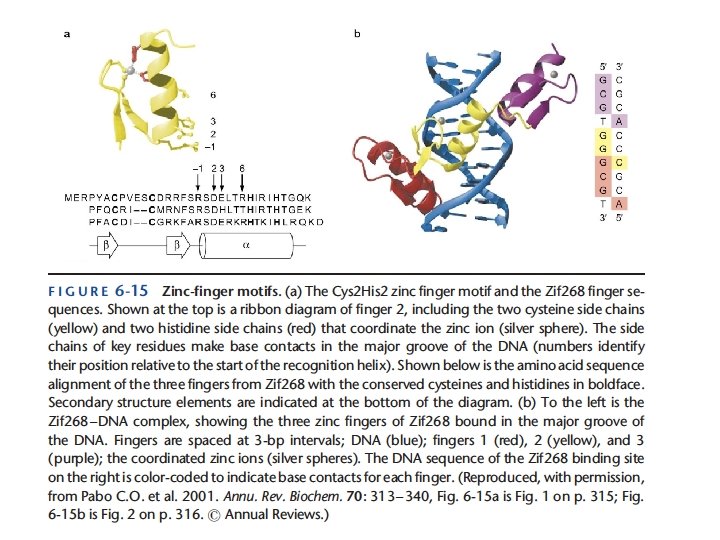
Motif • Motif (sequence): A short amino acid sequence with characteristic properties, often those suitable for association with a specific kind of domain on another protein. (Note that the term “domain” is sometimes incorrectly applied to such sequence motifs. ) • Motif (structural): A domain substructure that occurs in many different proteins, often having some characteristic amino acid sequences properties (e. g. , the helix-turn-helix motif in many DNA-recognition domains) 74
Figure 6 -10
Figure 6 -11
Box 6 -4
Figure 6 -12
DNA recognition by the repressor of bacteriophage l
Lymphocyte Enhancer Factor-1 (LEF-1) • Lymphocyte Enhancer Factor-1 (LEF-1), which regulates T-cell gene expression in concert with several other factors, is a three helix bundle that fits into the substantially widened minor groove of bent DNA. • Most of the amino acid side chains that face into the minor groove are nonpolar, nonpolar and one of them inserts part way between two adjacent base pairs, helping to stabilize the nearly 90° bend in the DNA axis. 81
• A: T and T: A look the same in this respect, as do G: C and C: G, C: G but base sequence also influences the propensity for the DNA double helix to bend or twist—that is, to adopt conformations that deviate from an ideal Watson–Crick double helix. • This sensitivity to the influence of base sequence on the propensity of DNA to bend and twist is sometimes called “indirect readout, ” to distinguish it from the sequence specificity provided by direct polar and nonpolar contacts with base pairs. 82
The LEF-1 protein bound to DNA
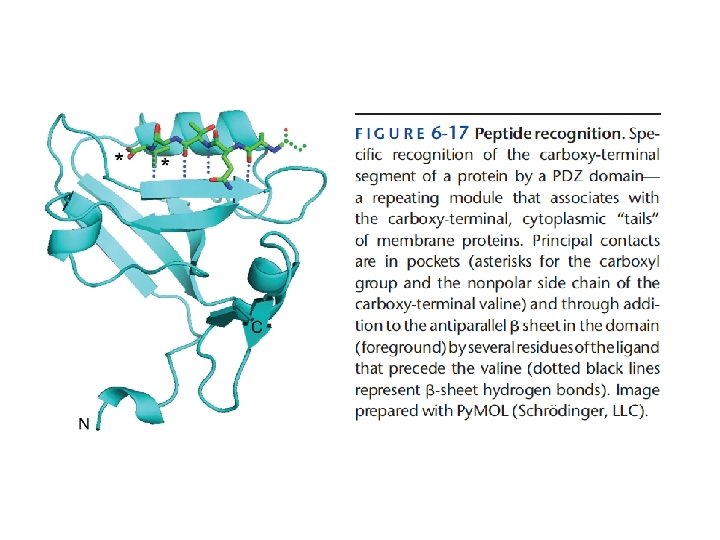
Figure 6 -18
86
Figure 6 -19