Review CPI Type CPIi for type Frequency CPIi






 31 26 25 Op")

![基本操作(Step 1 & 2) • Step 1 - IF – IR <-- Mem[PC] -----](https://slidetodoc.com/presentation_image_h/998ddfdc9feee1991ae6e24d17a5bdfa/image-10.jpg "基本操作(Step 1 & 2) • Step 1 - IF – IR <-- Mem[PC] -----")
16")



? -资源利用率高 Time (clock cycles) Inst 3 2020/11/25 Reg Im Reg Dm Im")



![在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode](https://slidetodoc.com/presentation_image_h/998ddfdc9feee1991ae6e24d17a5bdfa/image-23.jpg "在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode")

![• WB – ALU instruction » Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or »](https://slidetodoc.com/presentation_image_h/998ddfdc9feee1991ae6e24d17a5bdfa/image-25.jpg "• WB – ALU instruction » Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or »")
 Time (clock cycles) 2020/11/25 Ifetch DMem Reg ALU")







 Instr 4 Reg Mem Reg Mem Reg ALU Instr 3")
 Time (clock cycles) Instr 1 Instr 2 Stall Instr")


 • 机器 B:")
 Time (clock cycles) and r 6, r 1, r")
) Instr. J tries to read operand before Instr.")



 or r 8, r 1, r 9 Reg DMem")
 and r 6, r 1, r 7 or 2020/11/25")





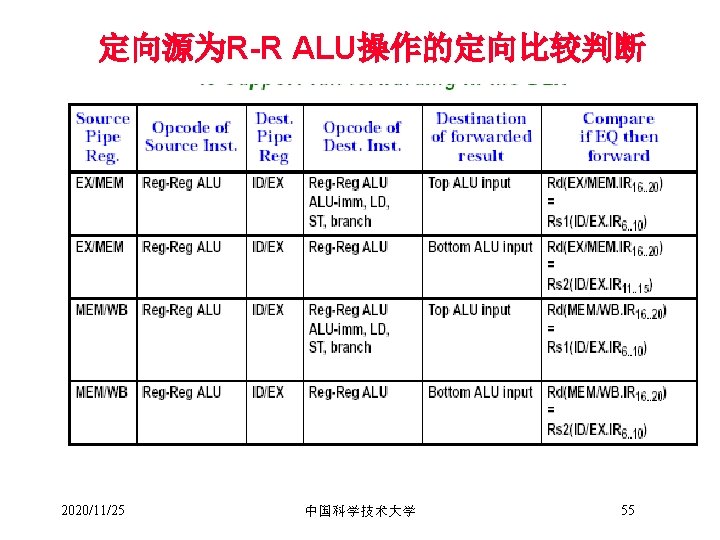

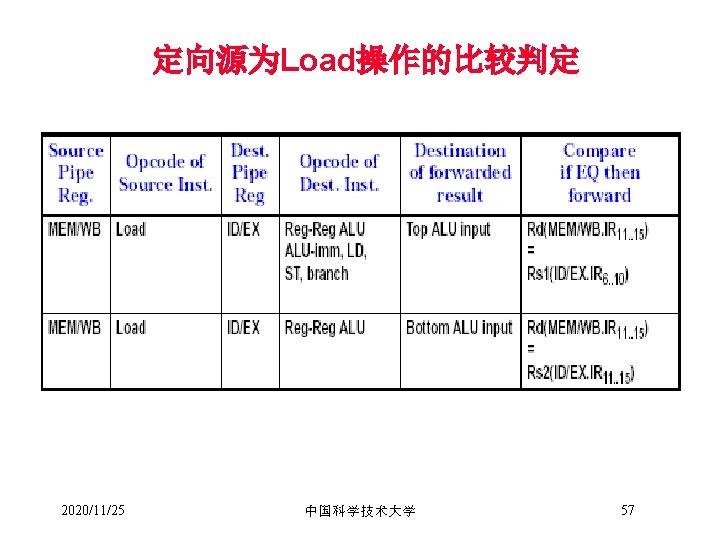






















 – 定义为完成某一操作所需的cycle数 – 定义为使用当前指令所产生结果的指令与当前指令间的最小间隔周期数 • 循环间隔(Repeat/Initiation interval) –")


















- Slides: 111
Review: 性能评测 • 平均CPI? – 每类指令的使用频度 Type CPIi for type Frequency CPIi x freq. Ii Arith/Logic 4 40% 1. 6 Load 5 30% 1. 5 Store 4 10% 0. 4 branch 3 20% 0. 6 Average CPI: 4. 1 2020/11/25 中国科学技术大学 2
是否可以使 CPI < 4. 1? • 在一条指令执行过程中下图有许多空闲部件 – 可以让指令重叠执行? ? PCWr Reg. Dst ALUSel. A Reg. Wr 32 PC 32 Rd Rb bus. A A Reg File Rw bus. W bus. B 1 1 Mux 0 Imm 16 2020/11/25 Ra Ext. Op 4 B << 2 Extend 1 32 32 0 Memto. Reg Zero 32 0 1 32 32 2 3 32 中国科学技术大学 32 ALU Control ALUOp ALUSel. B 3 ALU Out 32 5 Rt 0 Mux Wr. Adr 32 Din Dout 5 32 Rt Mem Data Reg Ideal Memory 1 Rs 1 ALU RAdr 0 Mux 32 Instruction Reg 32 32 PCSrc Mux PCWr. Cond Zero Ior. D Mem. Wr IRWr
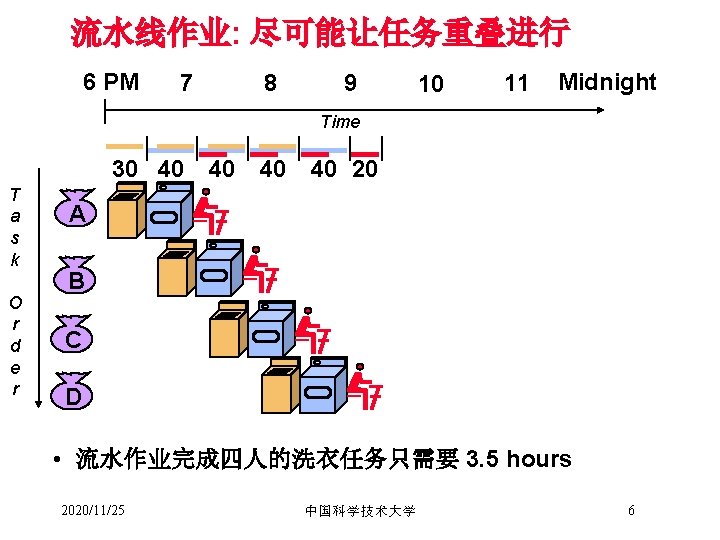
3. 1 流水线的基本概念 • 洗衣为例 • Ann, Brian, Cathy, Dave 每人进行洗衣的动作: wash, dry, and fold • washer需要 30 minutes A B C D • Dryer 需要 40 minutes • “Folder” 需要 20 minutes 2020/11/25 中国科学技术大学 4
Sequential Laundry 6 PM 7 8 9 10 11 Midnight Time 30 40 20 T a s k O r d e r A B C D • 顺序完成这些任务需要 6 小时 • 如果采用流水作业, 需要多长时间? 2020/11/25 中国科学技术大学 5
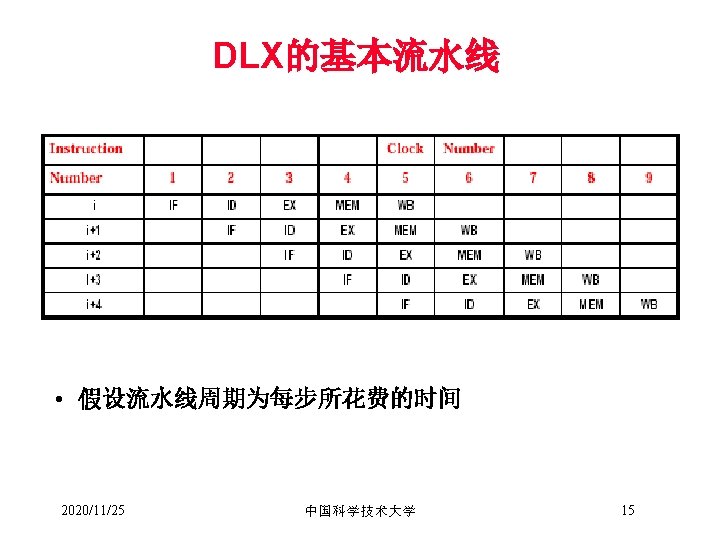
3. 2 DLX的基本流水线 • 指令流水线:CPU执行大量的指令,指令吞吐率非常重要 • DLX 的指令格式 Register-Register (R-type) 31 26 25 Op 2120 rs rt ADD R 1, R 2, R 3 16 15 rd Register-Immediate (I-type) 31 26 25 Op 2120 rs Jump / Call (J-type) 31 26 25 Op rt 1110 6 5 0 func SUB R 1, R 2, #3 16 15 0 immediate JUMP end offset added to PC 0 (jump, jump and link, trap and return from exception) §所有指令相同长度 §在指令格式中寄存器位于同一位置 §只有Loads和Stores可以对存储器操作 2020/11/25 中国科学技术大学 8
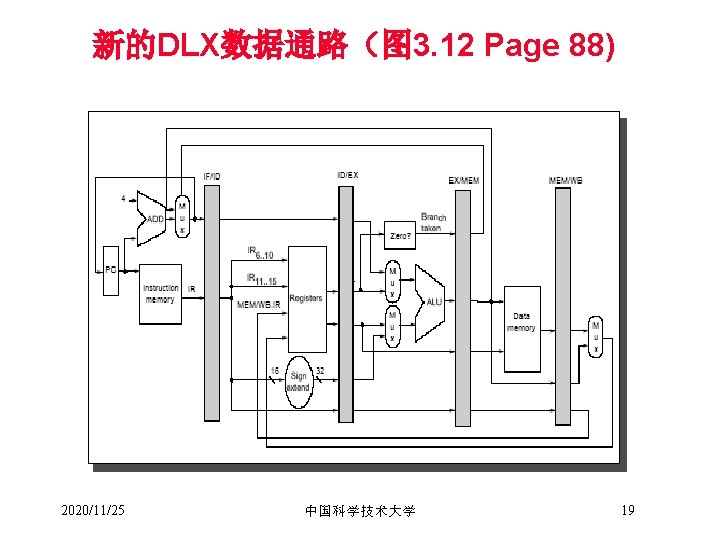
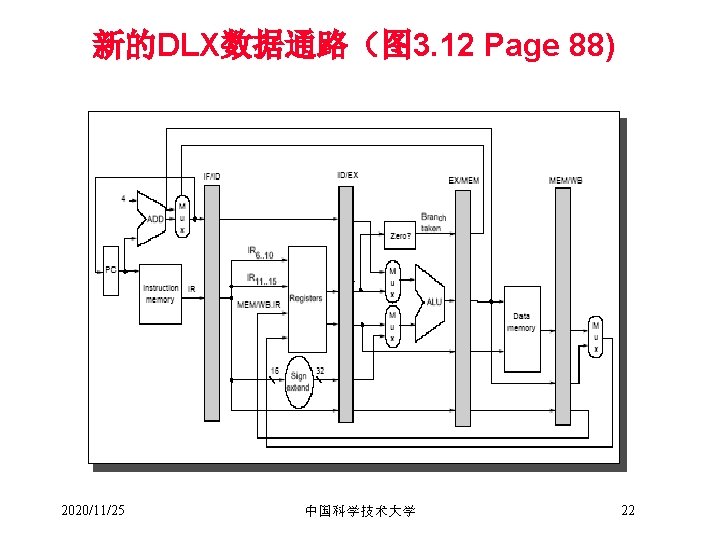
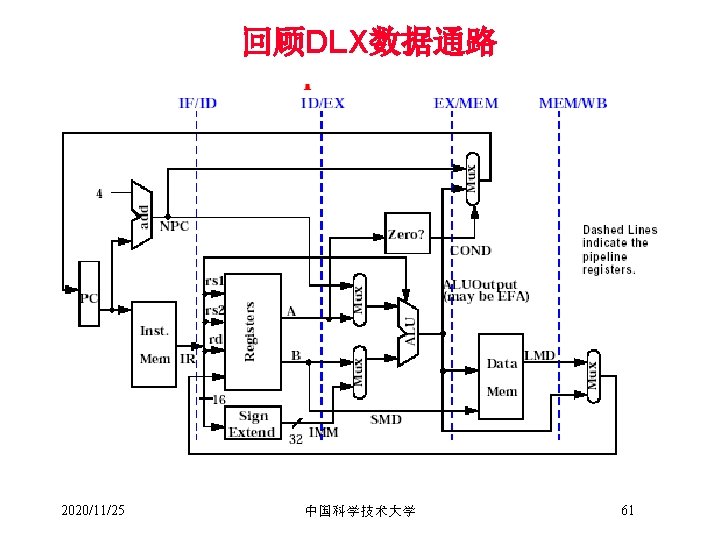
DLX数据通路一种简单实现 Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc Next SEQ PC Adder 4 Zero? RS 1 L M D MUX Data Memory ALU Imm MUX RD Reg File Inst Memory Address RS 2 Write Back MUX Next PC Memory Access Sign Extend WB Data 2020/11/25 中国科学技术大学 9
基本操作(Step 1 & 2) • Step 1 - IF – IR <-- Mem[PC] ----- fetch the next instruction from memory – NPC <-- PC + 4 ----- compute the new PC • Step 2 step ID - instruction decode and register fetch – A <-- Regs[IR 6. . 10] – B <-- Regs[IR 11. . 16] » 可能读取的寄存器值没有用,但没有关系,译码后如果无用,以 后操作就不用 – Imm ((IR 16)16 ## IR 16 -31 2020/11/25 中国科学技术大学 10
基本操作-Step 3, 执行阶段 根据译码的结果,有四种情况 • Memory Reference – ALUOutput <-- A + (IR 16)16 ## IR 16. . 31 ----- effective address – SMD <-- B ----- data to be written if it is a STORE -- SMD (store mem data) = MDR • Register - Register ALU instruction – ALUOutput <-- A op B • Register - Immediate ALU instruction – ALUOutput <-- A op ((IR 16)16 ## IR 16. . 31)) • Branch/Jump – ALUOutput <-- NPC + (IR 16)16 ## IR 16. . 31 – cond <-- A op 0 --- for conditional branches A’s value is the condition base (= for BEQZ) – 在简单的 Load-Store机器中,不存在即需要计算存储器地址,指令地址, 又要进行ALU运算的指令,因此可以将计算有效地址与执行合二为一, 在一个流水段中进行。 2020/11/25 中国科学技术大学 11
Step 4 & Step 5 Step 4 MEM - memory access/branch completion • memory reference – LMD <--- Mem[ALUOutput] ------- if it’s a load; LMD (load memory data) = MDR 或 – Mem[ALUOutput] <-- SMD • branch – if (cond) then PC <-- ALUOutput else PC <-- NPC – for Jumps the condition is always true Step 5 WB - write back • Reg - Reg ALU – Regs[IR 16. . 20] <-- ALUOutput • Reg - Immed ALU – Regs[IR 11. . 15] <-- ALUOutput • Load – Regs[IR 11. . 15] <-- LMD 2020/11/25 中国科学技术大学 12
为什么用流水线? • 假设执行100条指令 • 单周期机器 – 45 ns/cycle x 1 CPI x 100 inst = 4500 ns • 多周期机器 – 10 ns/cycle x 4. 6 CPI (due to inst mix) x 100 inst = 4600 ns • 理想流水线机器 – 10 ns/cycle x (1 CPI x 100 inst + 4 cycle drain) = 1040 ns 2020/11/25 中国科学技术大学 16
为什么用流水线(cont. )? -资源利用率高 Time (clock cycles) Inst 3 2020/11/25 Reg Im Reg Dm Im Reg 中国科学技术大学 Reg Dm ALU Inst 4 Im Dm ALU Inst 2 Reg ALU Inst 1 Im ALU O r d e r Inst 0 ALU I n s t r. Reg Dm Reg 17
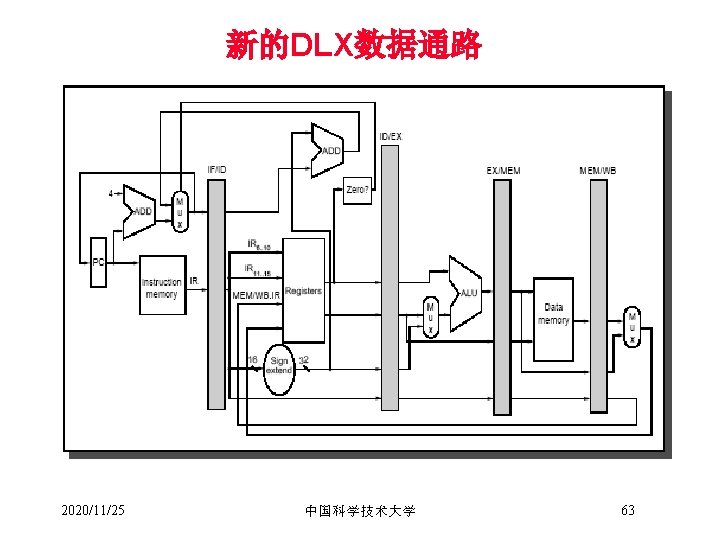
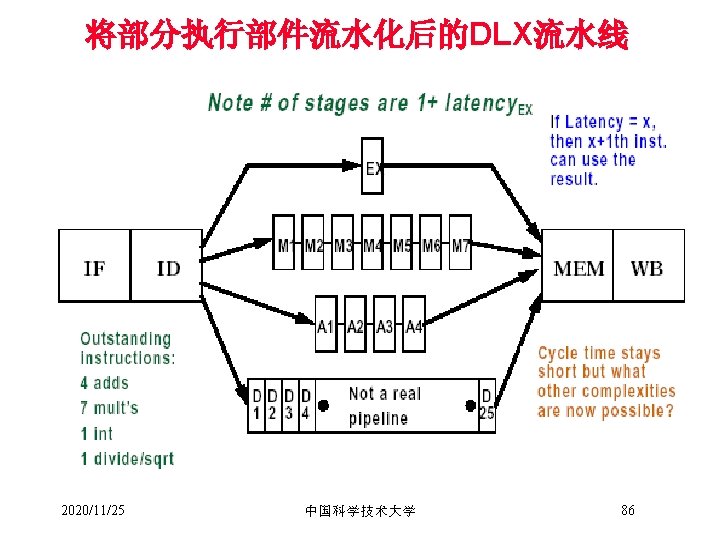
在新的Datapath下各段的操作 • IF – IF/ID. IR ←Mem[PC]; – IF/ID. NPC, PC ←(if ((EX/MEM. opcode == branch) & EX/MEM. cond) {EX/MEM. ALUOutput} else {PC+4}); • ID – ID/EX. A ←Regs[IF/ID. IR[rs]]; ID/EX. B ← Regs[IF/ID. IR[rt]]; – ID/EX. NPC←IF/ID. NPC; ID/EX/IR ← IF/ID. IR; – ID/EX/Imm ← sign-extend(IF/ID. IR[immediate field]); • EX – ALU instruction » EX/MEM. IR ← ID/EX. IR; » EX/MEM. ALUOutput ← ID/EX. A func ID/EX. B; or » EX/MEM. ALUOoutput ← ID/EX. A op ID/EX. Imm; 2020/11/25 中国科学技术大学 23
– Load or store instruction » EX/MEM. IR ← ID/EX. IR » EX/MEM. ALUOutput ← ID/EX. A + ID/EX. Imm » EX/MEM. B ← ID/EX. B – Branch instruction » EX/MEM. ALUOutput ← ID/EX. NPC + (ID/EX. Imm << 2) » EX/MEM. cond ← (ID/EX. A == 0); • MEM – ALU Instruction » MEM/WB. IR ←EX/MEM. IR » MEM/WB. ALUOutput ←EX/MEM. ALUOutput; – Load or store instruction » MEM/WB. IR ←EX/MEM. IR; » MEM/WB. LMD ← Mem[EX/MEM. ALUOutput]; or Mem[EX/MEM. ALUOutput] ← EX/MEM. B; (store) 2020/11/25 中国科学技术大学 24
• WB – ALU instruction » Regs[MEM/WB. IR[rd]] ← MEM/WB. ALUOutput; or » Regs[MEM/WB. IR[rt]] ← MEM/WB. ALUOutput; – For load only » Regs[MEM/WB. IR[rt]] ← MEM/WB. LMD 2020/11/25 中国科学技术大学 25
简化的 Pipelining(图 3. 11 Page 87) Time (clock cycles) 2020/11/25 Ifetch DMem Reg ALU O r d e r Ifetch ALU I n s t r. ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Ifetch Reg Ifetch 中国科学技术大学 Reg DMem Reg 26
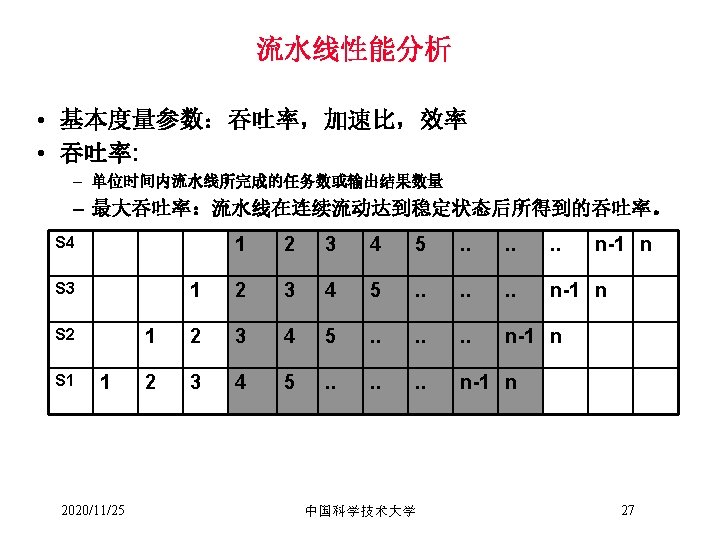
例3. 1时空图 8 7 6 5 4 3 2 1 1 2 2020/11/25 3 4 5 6 7 8 9 10 11 12 中国科学技术大学 13 14 15 16 17 18 19 30 20
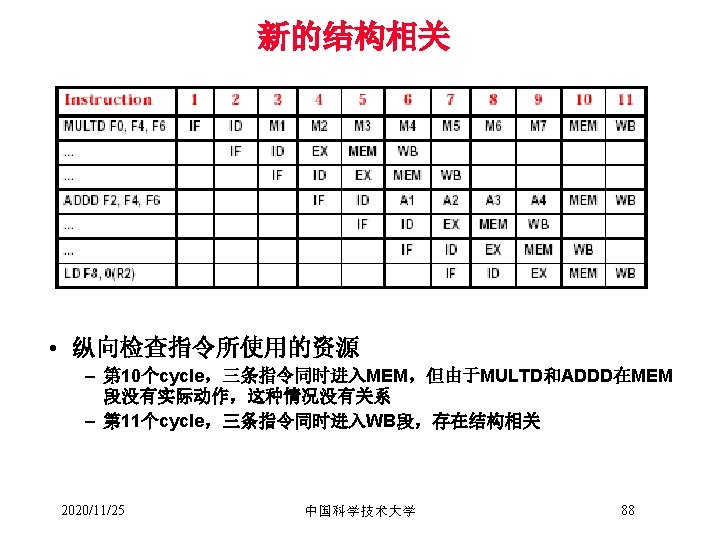
单个存储器引起的结构相关 Time (clock cycles) Instr 4 Reg Mem Reg Mem Reg ALU Instr 3 Mem ALU Instr 2 Reg ALU Instr 1 Mem ALU O r d e r Load ALU I n s t r. Mem Reg Detection is easy in this case! (right half highlight means read, left half write) 2020/11/25 中国科学技术大学 36
消除结构相关(图 3. 18 Page 98) Time (clock cycles) Instr 1 Instr 2 Stall Instr 3 2020/11/25 Reg Ifetch DMem Reg ALU Ifetch Bubble Reg DMem Bubble Ifetch 中国科学技术大学 Reg Bubble ALU O r d e r Load ALU I n s t r. ALU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Bubble DMem 37 Reg
流水线的加速比计算 For simple RISC pipeline, CPI = 1: 2020/11/25 中国科学技术大学 39
例如: Dual-port vs. Single-port • 机器A: Dual ported memory (“Harvard Architecture”) • 机器 B: Single ported memory, 但其流水线实现时比非流 水实现时钟频率快 1. 05 倍 • Ideal CPI = 1 for both,Load指令CPI = 2 • 所执行的指令中Loads指令占 40% Speed. Up. A = Pipeline Depth/(1 + 0) x (clockunpipe/clockpipe) = Pipeline Depth Cycle Timeunpipeb = 1. 05 Cycle. Timepipe Speed. Up. B= Pipeline Depth/(1 + 0. 4 x 1) x (cycle. Timeunpipe/(cycletimepipe) = (Pipeline Depth/1. 4) x 1. 05 = 0. 75 x Pipeline Depth Speed. Up. A / Speed. Up. B = Pipeline Depth/(0. 75 x Pipeline Depth) = 1. 33 • Machine A 比Machine B快 2020/11/25 中国科学技术大学 40
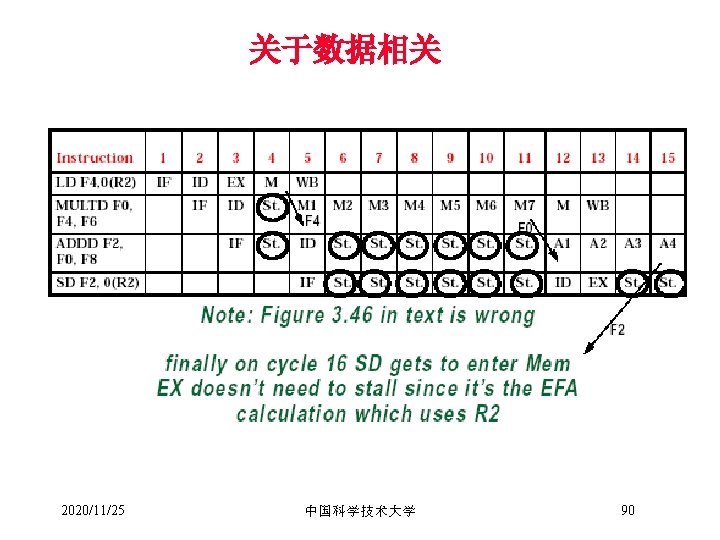
数据相关问题(图 3. 20 Page 100) Time (clock cycles) and r 6, r 1, r 7 or r 8, r 1, r 9 Ifetch DMem Reg DMem Ifetch Reg ALU sub r 4, r 1, r 3 Reg ALU Ifetch ALU O r d e r add r 1, r 2, r 3 xor r 10, r 11 2020/11/25 WB ALU I n s t r. MEM ALU IF ID/RF EX 中国科学技术大学 Reg Reg DMem 41 Reg
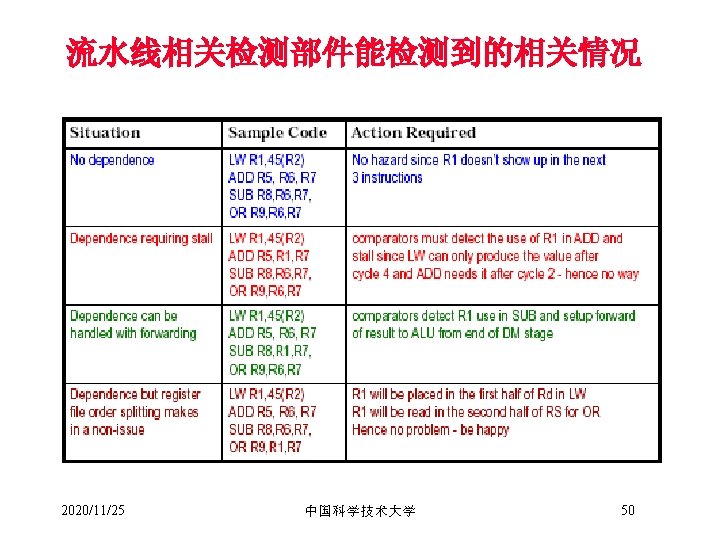
三种基本的数据相关 • 写后读相关(Read After Write (RAW)) Instr. J tries to read operand before Instr. I writes it I: add r 1, r 2, r 3 J: sub r 4, r 1, r 3 • 由于实际的数据交换需求而引起的 2020/11/25 中国科学技术大学 42
采用定向技术避免数据相关(图 3. 21 Page 102) or r 8, r 1, r 9 Reg DMem Ifetch Reg ALU and r 6, r 1, r 7 Ifetch DMem ALU sub r 4, r 1, r 3 Reg ALU O r d e r add r 1, r 2, r 3 Ifetch ALU I n s t r. ALU Time (clock cycles) xor r 10, r 11 2020/11/25 中国科学技术大学 Reg Reg DMem 46 Reg
采用定向技术仍然存在相关(图 3. 23 Page 153) and r 6, r 1, r 7 or 2020/11/25 DMem Ifetch Reg DMem Reg Ifetch r 8, r 1, r 9 中国科学技术大学 Reg Reg DMem ALU sub r 4, r 1, r 6 Reg ALU O r d e r lw r 1, 0(r 2) Ifetch ALU I n s t r. ALU Time (clock cycles) Reg DMem 47 Reg
and r 6, r 1, r 7 or r 8, r 1, r 9 Reg DMem Ifetch Reg Bubble Ifetch Bubble Reg Bubble Ifetch Reg DMem Reg ALU sub r 4, r 1, r 6 Ifetch ALU O r d e r lw r 1, 0(r 2) ALU I n s t r. ALU Time (clock cycles) DMem 2020/11/25 中国科学技术大学 48
采用软件方法避免数据相关 Try producing fast code for a = b + c; d = e – f; assuming a, b, c, d , e, and f in memory. Slow code: LW LW ADD SW LW LW SUB SW 2020/11/25 Rb, b Rc, c Ra, Rb, Rc a, Ra Re, e Rf, f Rd, Re, Rf d, Rd Fast code: LW LW LW ADD LW SW SUB SW 中国科学技术大学 Rb, b Rc, c Re, e Ra, Rb, Rc Rf, f a, Ra Rd, Re, Rf d, Rd 49
采用定向技术硬件所需做的修改 Next. PC mux MEM/WR EX/MEM ALU mux ID/EX Registers Data Memory mux Immediate 2020/11/25 中国科学技术大学 54
四种可能的解决冲突的方法 #4: 延迟转移 – 定义分支发生在一系列指令之后 branch instruction sequential successor 1 sequential successor 2. . . . sequential successorn branch target if taken Branch delay of length n – 5级流水只需要一个延迟槽就可以确定目标地址和确定条件 – DLX 使用这种方式 2020/11/25 中国科学技术大学 66
评估减少分支策略的效果 Scheduling Branch CPI scheme penalty Stall pipeline 3 1. 42 Predict taken 1 1. 14 Predict not taken 1 Delayed branch 0. 5 1. 07 speedup v. unpipelined 3. 5 1. 0 4. 4 1. 26 1. 09 4. 5 4. 6 1. 31 speedup v. stall 1. 29 1. 14 = 1 + 1*14%*100% 1. 09 = 1+1*14%*65% 1. 07 = 1+ 0. 5*14% Conditional & Unconditional = 14%, 65% change PC 2020/11/25 中国科学技术大学 68
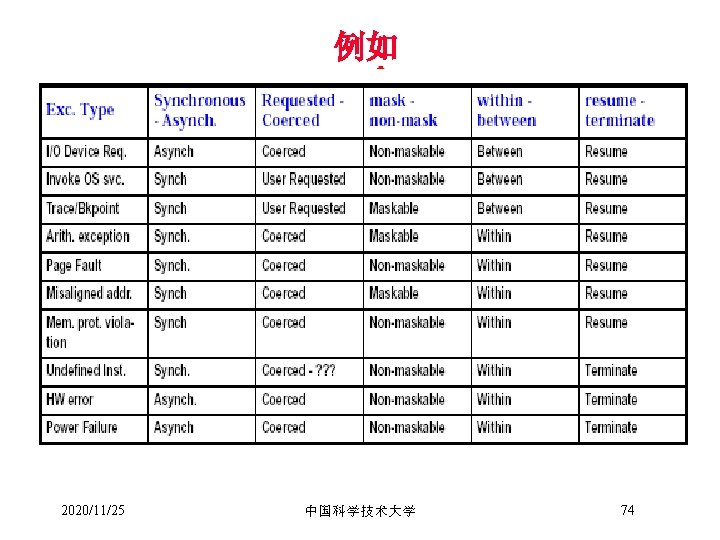
异常的类型 • I/O device request • invoking an OS service from a user program – e. g. via an unimplemented instruction on a Mac • • • tracing instruction execution breakpoint integer or FP arithmetic error such as overflow page fault misaligned memory access memory protection violation undefined instruction hardware malfunction - like parity or ECC error power failure 2020/11/25 中国科学技术大学 72
异常响应请求的种类 • Synchronous vs. Asynchronous – synchronous caused by a particular instruction – asynchronous - external devices and HW failures • User requested vs. Coerced – requested is predictable and can happen after the instruction • User maskable vs. user non-maskable – e. g. arithmetic overflow on some machines is user maskable • Within vs. Between instructions – within ==> synchronous, key is that completion is prevented – some asynchronous are also within • Resume vs. Terminate program – implications for how much state must be preserved 2020/11/25 中国科学技术大学 73
DLX中的异常 • IF – page fault, misaligned address, memory protection violation • ID – undefined or illegal opcode • EX – arithmetic exception • MEM – page fault, misaligned address, memory protection violation • WB – none 2020/11/25 中国科学技术大学 78
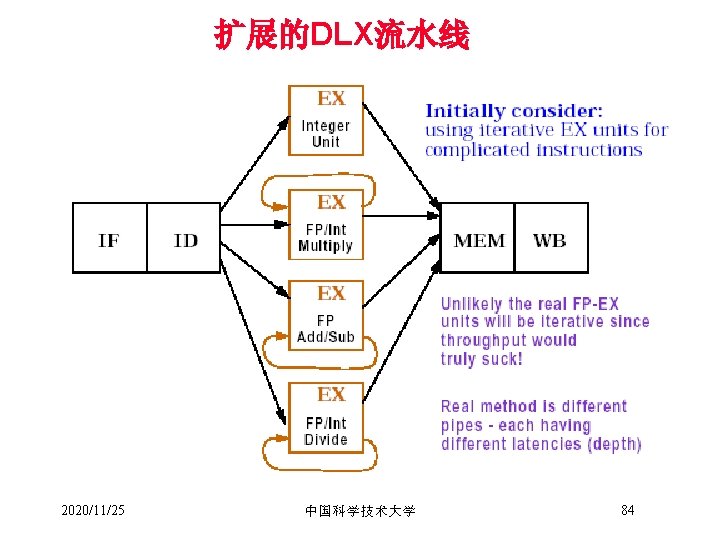
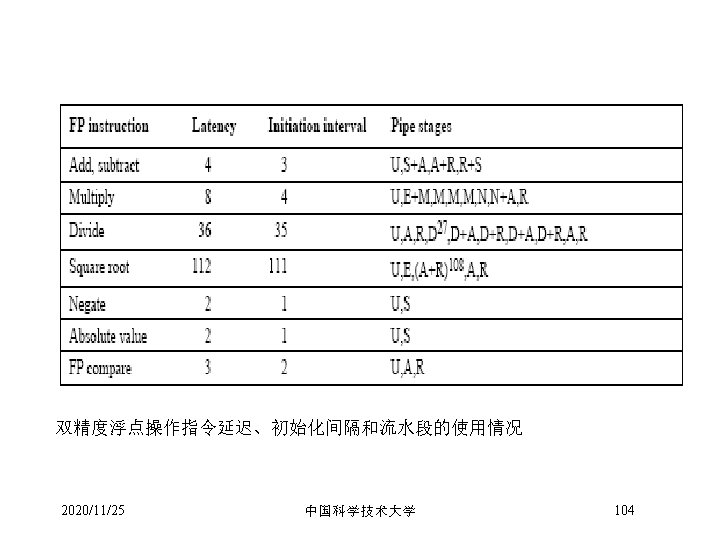
Latency & Repeat Interval • 延时(Latency) – 定义为完成某一操作所需的cycle数 – 定义为使用当前指令所产生结果的指令与当前指令间的最小间隔周期数 • 循环间隔(Repeat/Initiation interval) – 发射相同类型的操作所需的间隔周期数 • 对于EX部件流水化的新的DLX Function Unit Integer ALU Data Memory (Integer and FP loads(1 less for store latency)) FP Add Latency 0 1 Repeat Interval 1 1 3 1 FP multiply 6 1 FP Divide (also integer divide and FP sqrt) 24 25 2020/11/25 中国科学技术大学 85
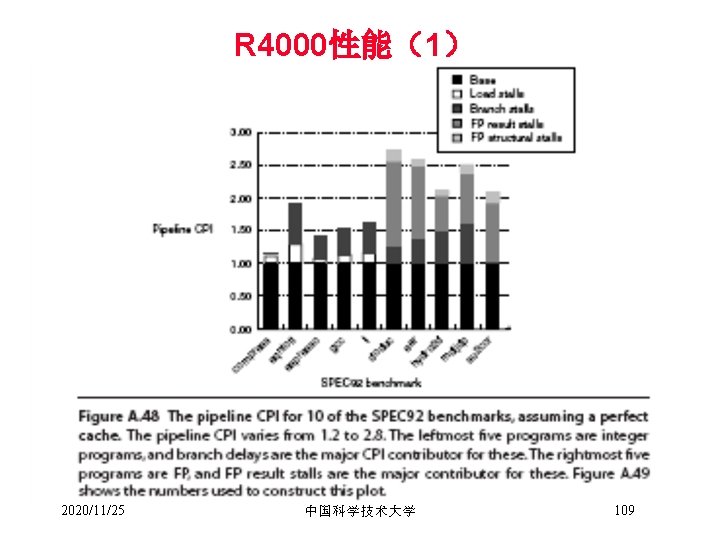
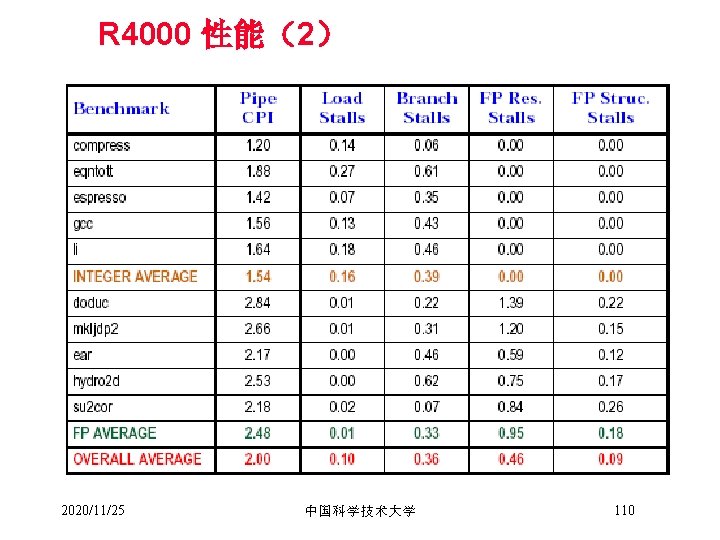
DLX流水线的性能 Stalls per FP operation for each major type of FP operation for the SPEC 89 FP benchmarks 2020/11/25 中国科学技术大学 96
平均每条指令的stall数 The stalls occurring for the MIPS FP pipeline for five for the SPEC 89 FP benchmarks. 2020/11/25 中国科学技术大学 97
图示 IF IS IF RF IS IF EX RF IS IF DS DF EX RF IS IF TC DS DF EX RF IS IF WB TC DS DF EX RF IS IF IF THREE Cycle Branch Latency (conditions evaluated during EX phase) IS IF RF IS IF EX RF IS IF DS DF EX RF IS IF TC DS DF EX RF IS IF WB TC DS DF EX RF IS IF TWO Cycle Load Latency Delay slot plus two stalls Branch likely cancels delay slot if not taken 2020/11/25 中国科学技术大学 101
MIPS R 4000 浮点数操作 • 3个功能部件组成:FP Adder, FP Multiplier, FP Divider • 在乘/除操作的最后一步要 使用FP Adder • FP操作需要2(negate)-112个(square root)cycles • 8 kinds of stages in FP units: Stage Functional unit Description A FP adder Mantissa ADD stage D FP divider Divide pipeline stage E FP multiplier Exception test stage M FP multiplier First stage of multiplier N FP multiplier Second stage of multiplier R FP adder Rounding stage S FP adder Operand shift stage U Unpack FP numbers 2020/11/25 中国科学技术大学 102
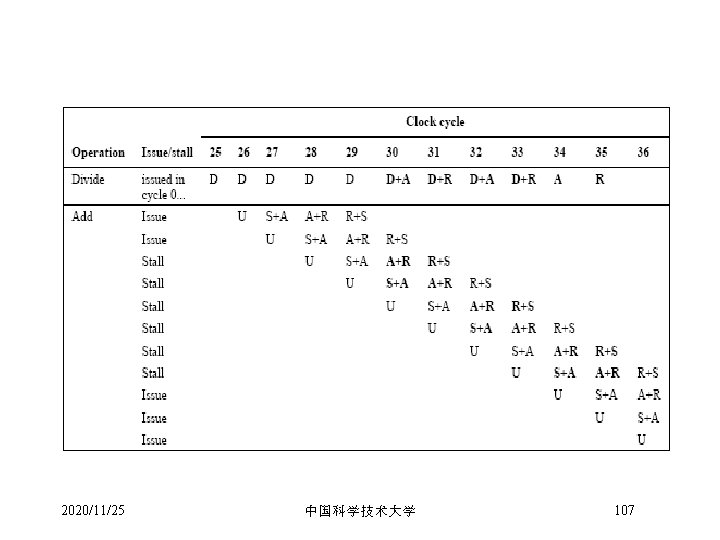
MIPS FP 流水段 FP Instr 1 … Add, Subtract Multiply U Divide U D+R, A, R Square root Negate U Absolute value FP compare Stages: M N R S U 2020/11/25 2 3 4 5 6 7 U E+M A S+A M R A+R M D 28 R+S M … N D+A N+A R D+R, D+A, U S U U E (A+R)108 … A R S A R First stage of multiplier Second stage of multiplier Rounding stage Operand shift stage Unpack FP numbers 中国科学技术大学 A D E 8 Mantissa ADD stage Divide pipeline stage Exception test stage 103
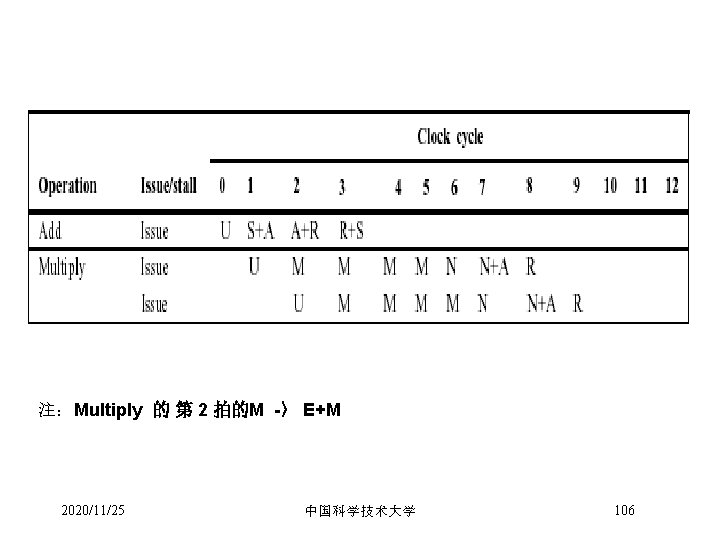
注: Multiply Issue 2020/11/25 U M M -> U E+M M 中国科学技术大学 105