Machine Learning Deep Learning Measuring performance for classification


























T b=(1, 0)T c=(0, 1)T d=(1, 1)T ta= -1")

 OR 분류 문제 w(0)=(-0. 5, 0. 75)T, b(0)=0. 375")





























![Performance [Mishkim et al. 2015]](https://slidetodoc.com/presentation_image_h/a5e3675bee4a3e4b04b3a911b5e70c74/image-62.jpg "Performance [Mishkim et al. 2015]")

 “A Fast Learning Algorithm for Deep Belief Nets”")









 • We understand the")







- Slides: 81
Machine Learning & Deep Learning
Measuring performance for classification • confusion matrix
Measuring performance for classification • confusion matrix
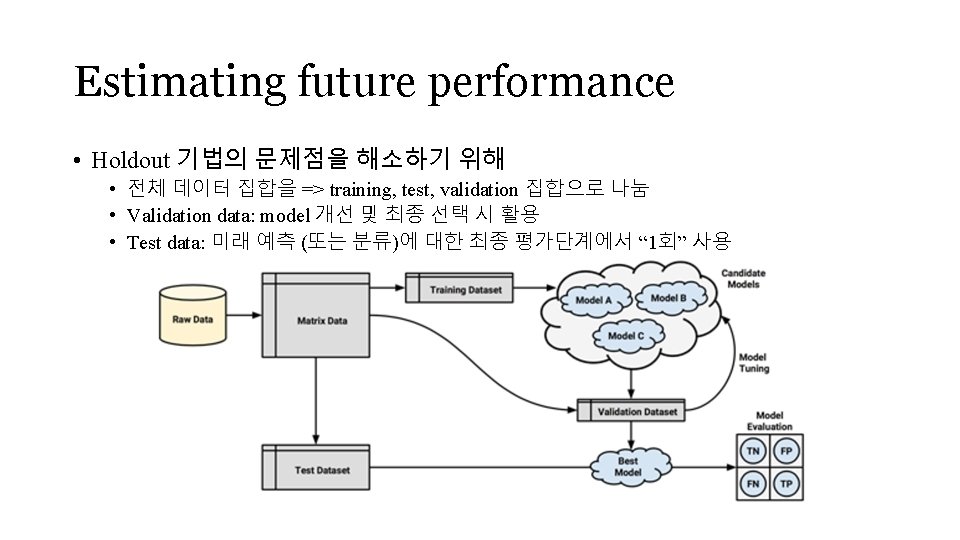
Estimating future performance • Holdout method • 일반적으로, 전체데이터의 2/3 => training, 1/3 => testing • holdout을 여러 번 반복하여 best model을 취함 • test data는 model 생성에 영향을 미치지 않아야 함 • 하지만, random하게 잡은 training data에 대하여 다수의 model을 생성한 후, test data에 대 하여 best model을 찾는 것이어서, • hold-out 기법에서의 test performance는 공정하지 않음
Performance Evaluation
Neural Networks
Neural Networks
Logistic Regression vs. Neural Networks
Neural Networks
AND/OR problem
Multilayer Perceptrons No one on earth had found a viable way to train. Marvin Minsky, 1969
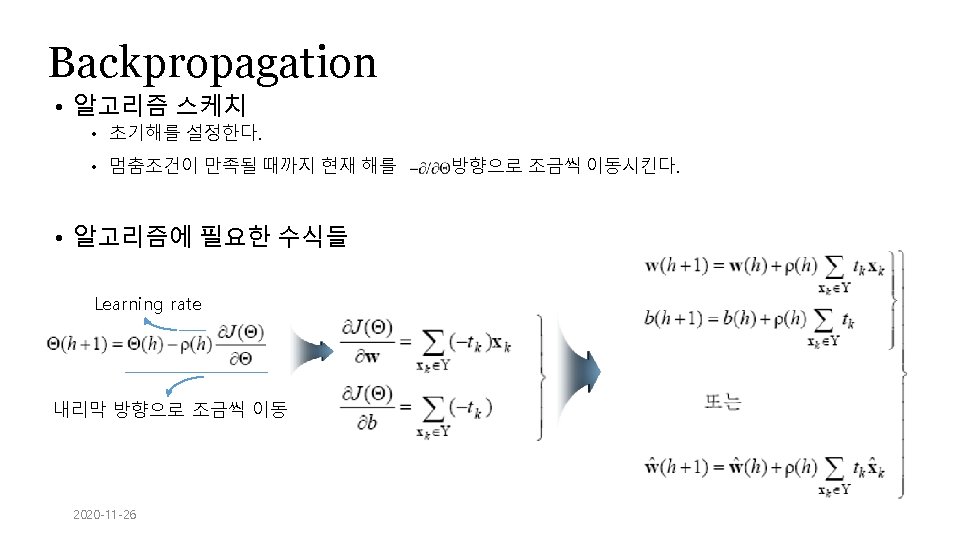
Backpropagation
Backpropagation A dataset Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc …
Backpropagation Training the neural network Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc …
Backpropagation 초기 weight값은 random하게 설정 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc …
Backpropagation Training data를 하나씩 입력 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 1. 4 2. 7 1. 9
Backpropagation 각 노드의 activation 결과에 따라 출력값 계산 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 1. 4 2. 7 0. 8 1. 9
Backpropagation 계산된 출력값과 실제 정답 출력값을 비교 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 1. 4 2. 7 0. 8 0 1. 9 error 0. 8
Backpropagation Error값에 따라 weight 조정 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 1. 4 2. 7 0. 8 0 1. 9 error 0. 8
Backpropagation 또 새로운 training data를 입력 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 6. 4 2. 8 1. 7
Backpropagation 각 노드의 activation 결과에 따라 출력값 계산 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 6. 4 2. 8 0. 9 1. 7
Backpropagation 계산된 출력값과 실제 정답 출력값을 비교 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 6. 4 2. 8 0. 9 1 1. 7 error -0. 1
Backpropagation Error값에 따라 weight 조정 Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 6. 4 2. 8 0. 9 1 1. 7 error -0. 1
Backpropagation Training data Fields class 1. 4 2. 7 1. 9 0 3. 8 3. 4 3. 2 0 6. 4 2. 8 1. 7 1 4. 1 0. 1 0. 2 0 etc … 6. 4 2. 8 0. 9 1 1. 7 error -0. 1 Error 가 임계점 이하로 떨어질 때까지 weight 조정을 반복
Backpropagation • 퍼셉트론 학습 a=(0, 0)T b=(1, 0)T c=(0, 1)T d=(1, 1)T ta= -1 tb= -1 tc= -1 td=1 • 예) AND 분류 문제 c d 1 x 1 a 2020 -11 -26 b x 2 ? ? ? y
Artificial Neural Networks • 예) OR 분류 문제 w(0)=(-0. 5, 0. 75)T, b(0)=0. 375 ① d(x)= -0. 5 x 1+0. 75 x 2+0. 375 Y={a, b} ② 2020 -11 -26 d(x)= -0. 1 x 1+0. 75 x 2+0. 375 Y={a}
Artificial Neural Networks • Deep Networks An abstracted feature Input layer Non-output layer = Auto-encoder Output layer Hidden layer Hierarchical feature layer output layer쪽으로 갈수록 Feature abstraction이 강해짐
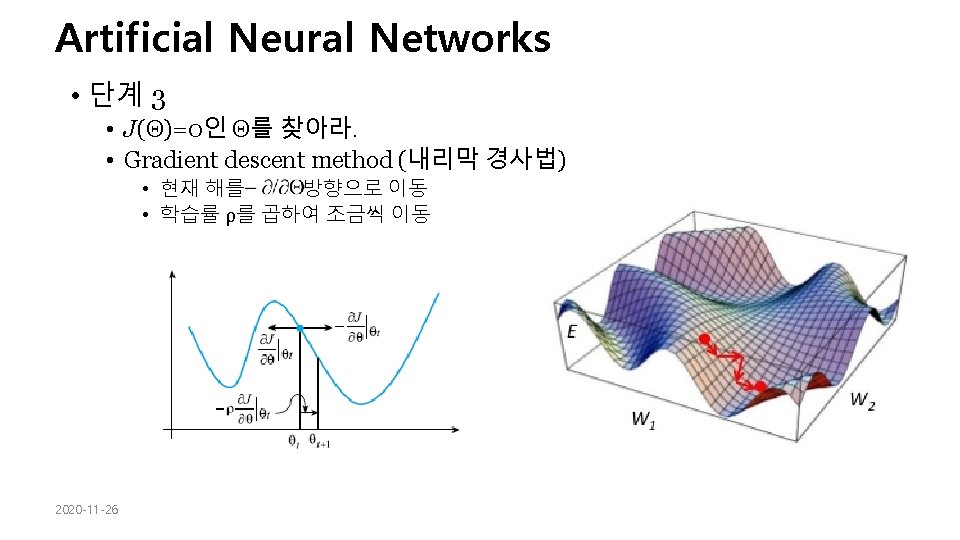
• Artificial Deep Networks Neural Networks Learning Multi-layer network 학습을 한꺼번에 하지 않고, 각 layer별로 단계 적으로 수행
Feature detectors
what is each of nodes doing?
Hidden layer nodes become self-organised feature detectors 1 5 10 15 20 25 … … 1 strong +ve weight low/zero weight 63
What does this unit detect? 1 5 10 15 20 25 … … 1 strong + weight low/zero weight Top row에 있는 pixel에 강하게 반응하는 feature 63
What does this unit detect? 1 5 10 15 20 25 … … 1 strong + weight low/zero weight Top left corner의 dark 영역에 강하게 반응하는 feature 63
Feature abstraction Deep Neural Networks 특정 위치의 line을 탐지하는 feature들의 layer Line-level feature들을 이용하여 윤곽을 탐지하는 feature들의 layer etc … v etc …
Deep Neural Networks Feature abstraction
Backpropagation
Breakthrough in 2006 & 2007 by Hinton & Bengio
Breakthrough
Breakthrough
Image Recognition Demo Toronto Deep Learning - http: //deeplearning. cs. toronto. edu/
Speech Recognition
Deep Learning Vision • Students • Not too late to be a world expert • Not too complicated • Practitioner • Accurate enough to be used in practice • Many read-to-use tools such as Tensor. Flow • Many easy & simple programming languages such as Python
Deep Learning의 문제 • Activation function problem • Backpropagation과정과 연관 • Weight initialization
Solving the XOR problem
Solving the XOR problem How can we get W & b from the training data?
Solving the XOR problem
Backpropagation w가 cost함수에 미치는 영향 w=? x Cost = ^y - y
Backpropagation: chain rule 활용
Backpropagation: chain rule 활용
Activation function: sigmoid ?
Deep network -> poor result
Vanishing gradient Gradient 값을 back propagate 시키게 되면 input layer 방향으로 진행될 수록 값이 미약해짐 ? Sigmoid function이 문제
Vanishing gradient: sigmoid function? 1 Re. LU: Rectified Linear Unit max {0, z} 0
Performance
Activation Functions Leaky Re. LU
Performance [Mishkim et al. 2015]
Weight Initialization 이 노드의 weigh가 0이면 전방의 모든 weight가 0이 됨
Weight Initialization Hinton et al. (2006) “A Fast Learning Algorithm for Deep Belief Nets” => Restricted Boltzmann Machine encoding decoding
RBM Deep Learning : pre-training step
RBM Deep Learning : fine tuning step
Weight Initialization • Xavier/He initialization • Makes sure the weights are “just right”, not too small, not too big • Using the number of input (fan_in) and output (fan_out)
Avoiding overfitting • Learning 시에만 dropout Prediction 시에는 모든 노드 사용
Deep Network의 설계 • Forward NN • Convolutional NN • Recurrent NN • ? ? ? NN
Convolutional NN
Convolutional NN
Convolutional NN 6
Convolutional NN
Recurrent NN • For sequence data (or time series data) • We understand the sentences based on the previous words + current word • NN/CNN cannot learn the sequence data
Recurrent NN
Recurrent NN
Recurrent NN
Recurrent NN
RNN applications • Language modeling • Speech recognition • Machine translation • Conversation modeling • Image/Video captioning • Image/Music/Dance generation
RNN structures
RNN structures Training RNNs is very challenging !