More Tips for Training Neural Network Hungyi Lee










")























 Gradient")
 v")

")












")
")









 Ø In each iteration l Each neuron has p%")
 Thinner! Ø In each iteration l Each neuron has")


% (dropout rate)")
















 Otherwise: (decrease)")






 • First make a big jump")
 ……")

- Slides: 94
More Tips for Training Neural Network Hung-yi Lee
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Review: Training Neural Network •
Review: Gradient descent •
Review: Backpropagation Layer Error signal for backprop Layer Forward Pass Backward Pass … …
Review: Backpropagation Layer L-1 Layer L Error signal for backprop …… Backward Pass …… … … ……
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Problem of Sigmoid Function Derivative of Sigmoid Function is always smaller than 1
Vanishing Gradient Problem Backward Pass: Layer L-1 Layer L …… • Error signal is getting smaller and smaller …… … … …… Gradient is smaller … …
Vanishing Gradient Problem Input Layer 1 Layer 2 Layer L Output …… vector x …… …… …… vector y …… Learn very slowly Learn faster Still random Already converge … The weights are converged based on random!?
Re. LU • Rectified Linear Unit (Re. LU)
Re. LU Backward Pass: Layer L-1 Layer L …… …… … … ……
Re. LU Backward Pass: Layer L-1 Layer L …… 0 1 No 1 Attenuation 0 …… … … 0 0 … … ……
Re. LU Backward Pass: All the weights connected to this neuron will have zero gradient. Layer L 1 0 …
Maxout • Re. LU or PRe. Lu is just a special case of Maxout Input + + Max +
Maxout – Re. LU is special case Input Re. LU Input + Max +
Maxout – Re. LU is special case Input Re. LU Input + Max + Learnable Activation Function
Maxout - Training by Backpropagation • In forward pass, we know which z would be the max + + Input Max + + Max +
Maxout - Training by Backpropagation • In forward pass, we know which z would be the max + + Input + + + • In backward pass, treat it as network whose neurons having linear activation functions
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Problem of Sigmoid …… …… … … Larger difference, Larger gradient …… … … tiny derivative How about ≈1 0 Large difference
Re. LU is probably not suitable for output layer Re. LU More similar? Only one dimension is 1, and others are all 0 Re. LU Ø Larger output means larger confidence It is better to let the output bounded. Better?
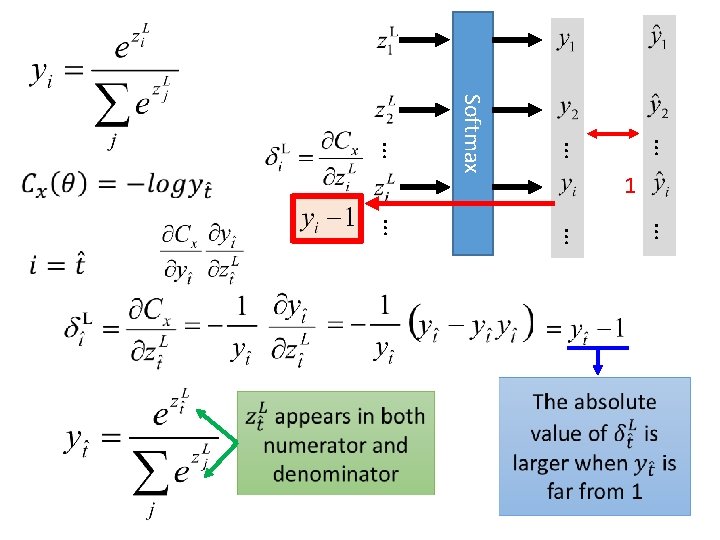
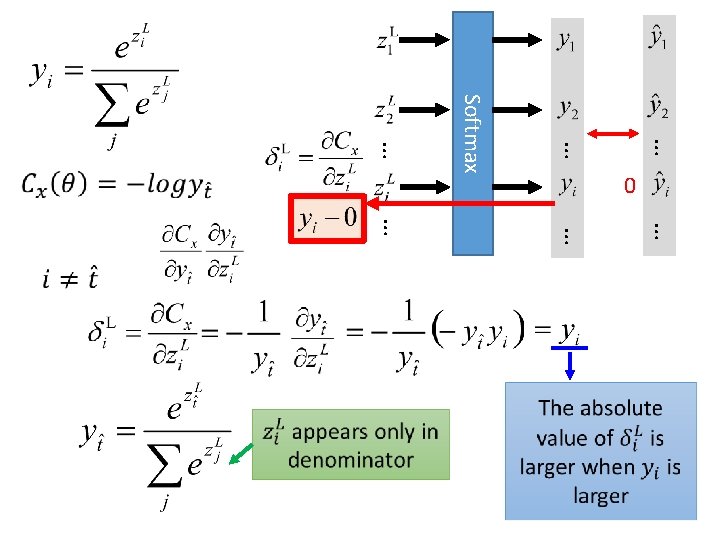
Softmax • Softmax layer as the output layer Ordinary Output layer
Softmax • Softmax layer as the output layer Softmax Layer 3 1 -3 0. 88 20 0. 12 2. 7 0. 05 ≈0
Softmax Define cost function Minimize … … … Softmax Only one dimension is 1, and others are all 0 … … … Index of the dimension which is 1
Softmax Define cost function Minimize Cross Entropy … … Softmax … … Don’t we have to decrease other dimensions?
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Data Preprocessing For each dimension i: …… …… The means of all dimensions are 0, and the variances are all 1
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Outline - Training Activation Function Cost Function Data Preprocessing Momentum Training Generalization Learning Rates
Outline - Training Activation Function Cost Function Data Preprocessing Momentum Training Generalization Learning Rates
Problem of Gradient descent cost Very slow at the plateau Gradient is small Stuck at local minima Gradient is Zero parameter space
In physical world …… • Momentum How about put this phenomenon in gradient descent?
Original Gradient descent Gradient Movement ……
Gradient descent with Momentum v 0=0 (vi : movement at the i-th update) Gradient Movement Momentum ……
Gradient descent with Momentum v 0=0 (vi : movement at the i-th update) v 0=0 …… ……
Gradient descent with Momentum cost Problem Gradient Movement Momentum Gradient = 0 parameter space
Gradient Movement NAG Momentum • Momentum Gradient = 0 • Nesterov’s Accelerated Gradient (NAG) Gradient = 0
Gradient descent, Momentum, NAG Methods: Gradient descent Momentum NAG Source: http: //www. cs. toronto. edu/~fritz/absps/momentum. pdf
Outline - Training Activation Function Cost Function Data Preprocessing Momentum Training Generalization Learning Rates
Learning Rates cost Very Large small Large Error Surface Just make epoch
Learning Rates • Not always true
Adaptive Learning Rates • Each parameter should have different learning rates Smaller Learning Rate Larger Gradient Larger Learning Rate Smaller Learning Rate
RProp • Each parameter should have different learning rates Gradient descent: 1 -1 Another Aspect:
RProp - Problem • RProp is problematic for stochastic gradient descent Gradient descent: 0. 1 1 Stochastic Gradient descent: 0. 9 -0. 1 -1 -1 -1
Adagrad • Divide the learning rate by “average” gradient Estimated while updating the parameters Larger learning rate Smaller learning rate
Adagrad
Adagrad • Divide the learning rate by “average” gradient • The “average” gradient is obtained while updating the parameters 1/t decay
RMSProp Error Surface can be complex in deep learning. Smaller Learning Rate Larger Learning Rate
RMSProp
http: //www. reddit. com/r/Machine. Learning/comments/2 gopfa/visual izing_gradient_optimization_techniques/cklhott (By Alec Radford)
http: //www. reddit. com/r/Machine. Learning/comments/2 gopfa/visual izing_gradient_optimization_techniques/cklhott (By Alec Radford)
Not the whole story …… • Adadelta • http: //www. matthewzeiler. com/pubs/google. TR 2012/go ogle. TR 2012. pdf • Adam • http: //arxiv. org/pdf/1412. 6980. pdf • Ada. Secant • http: //arxiv. org/pdf/1412. 7419 v 4. pdf • “No more pesky learning rates” • Using second order information • http: //arxiv. org/pdf/1206. 1106. pdf
Outline Activation Function Cost Function Data Preprocessing Training Generalization
Outline - Generalization Activation Function Cost Function Data Preprocessing Training Weight Decay Generalization Dropout
Outline - Generalization Activation Function Cost Function Data Preprocessing Training Weight Decay Generalization Dropout
Weight Decay • Our Brain
Weight Decay • The parameters closer to zero is preferred. Training data: … … Testing data: To minimize the effect of noise, we want w close to zero.
Weight Decay • New cost function to be minimized • Find a set of weight not only minimizing original cost but also close to zero Regularization term: Original cost (e. g. minimize square error, cross entropy …) (not consider biases. why? )
Weight Decay • New cost function to be minimized Gradient: Update: Smaller and smaller
Outline - Generalization Activation Function Cost Function Data Preprocessing Training Weight Decay Generalization Dropout
Dropout Training: (stochastic gradient descent) Ø In each iteration l Each neuron has p% to dropout
Dropout Training: (stochastic gradient descent) Thinner! Ø In each iteration l Each neuron has p% to dropout The structured of the network is changed. l Using the new network for training For each iteration, we resample the dropout neurons
Dropout Testing: Ø No dropout l If the dropout rate at training is p%, all the weights times (1 -p)%
Dropout - Intuitive Reason 我的 partner 會擺爛,所以 我要好好做 Ø When teams up, if everyone expect the partner will do the work, nothing will be done finally. Ø However, if you know your partner will dropout, you will do better. Ø When testing, no one dropout actually, so obtaining good results eventually.
Dropout - Intuitive Reason • Why the weights should multiply (1 -p)% (dropout rate) when testing? Training of Dropout Assume dropout rate is 50% Testing of Dropout No dropout Weights from training Weights multiply (1 -p)%
Dropout - Ensemble Training Set Ensemble Set 1 Set 2 Set 3 Set 4 Network 1 Network 2 Network 3 Network 4 Train a bunch of networks with different structures
Dropout - Ensemble Testing data x Network 1 Network 2 Network 3 Network 4 y 1 y 2 y 3 y 4 average
Dropout - Ensemble Training of Dropout x 2 x 1 Dropout ≈ Ensemble. x 3 x 4 M neurons …… 2 M possible networks Ø Using one data to train one network Ø Some parameters in the network are shared
Dropout - Ensemble Testing of Dropout ≈ Ensemble. testing data x …… All the weights multiply (1 -p)% y 1 y 2 average y 3 ? ≈ y
Dropout - Ensemble • Experiments on hand writing digital classification Ref: http: //arxiv. org/pdf/1302. 4389. pdf
Practical Suggestion for Dropout • Larger network • If you know your task need n neurons, for dropout rate p, your network need n/(1 -p) neurons. • Longer training time • Higher learning rate • Larger momentum
Not the whole story …… • To learn more about theory of dropout • Baldi, Pierre, and Peter J. Sadowski. "Understanding dropout. " Advances in Neural Information Processing Systems. 2013. • Drop. Connect • Reference: Wan, L. , Zeiler, M. , Zhang, S. , Cun, Y. L. , & Fergus, R. (2013). “Regularization of neural networks using dropconnect”. In Proceedings of the 30 th International Conference on Machine Learning (ICML-13) • Standout • Reference: Ba, J. , & Frey, B. (2013). “Adaptive dropout for training deep neural networks”. In Advances in Neural Information Processing Systems
Concluding Remarks Outlook: Ø How to connect neurons Ø Parameters Initialization Activation Function Cost Function Data Preprocessing Training Generalization Re. LU, Maxout Softmax + Cross Entropy Mean=0, Variance=1 Momentum, NAG, Adagrad, RMSProp Weight decay, Dropout
Appendix
• Optimizaton method • http: //cs. stanford. edu/~jngiam/papers/Le. Ngiam. Coates. L ahiri. Prochnow. Ng 2011. pdf • http: //www. cs. bham. ac. uk/~jxb/INC/l 8. pdf • http: //arxiv. org/pdf/1301. 3584. pdf • For RNN • http: //www. jmlr. org/proceedings/papers/v 28/suts kever 13. pdf
Kludge? • The smallness of the weights means that the behaviour of the network won't change too much if we change a few random inputs here and there. • That makes it difficult for a regularized network to learn the effects of local noise in the data. • Simple is not always better • http: //www. aip. org/history/ohilist/5020_4. html • If one had judged merely on the grounds of simplicity, then some modified form of Newton's theory would arguably have been more attractive. • http: //www. no-free-lunch. org/ • the dynamics of gradient descent learning in multilayer nets has a `self-regularization' effect"
• Use genetic approach • http: //papers. nips. cc/paper/4522 -practicalbayesian-optimization-of-machine-learningalgorithms. pdf
Story of NN • http: //www. reddit. com/r/Machine. Learning/comm ents/25 lnbt/ama_yann_lecun/chivdv 7
Reference • Everything about tuing parameters • http: //arxiv. org/pdf/1206. 5533 v 2. pdf
Activation Functions Softplus: Softsign:
RProp • Each parameter has different learning rate 1 -1 (increase) Otherwise: (decrease)
RProp Original Gradient descent RProp
Adadelta • http: //arxiv. org/pdf/1212. 5701 v 1. pdf
MNIST TIMIT
Error Surface: Square Error v. s. Cross Entropy Red: Square Error Black: Cross Entropy Cost w 1 w 2 Ref: Glorot, X. , & Bengio, Y. (2010). “Understanding the difficulty of training deep feedforward neural networks”. In International conference on artificial intelligence and statistics
Reference • Mean • Variance • Decorrelation
Re. LU Backward Pass: Layer L-1 …… …… … … … …… Layer L …… … …
Momentum v 0=0 (Movement at the last step) • First make a big jump in the direction of the previous accumulated gradient. • Then measure the gradient …… where you end up and make a correction. • Its better to correct a mistake after you have made it! ……
Momentum v 0=0 (Movement at the last step) ……
Why Zero Mean? Input … the same for all j Layer 1 The inputs are always positive … w 1 w 2 …… Hyperbolic Tangent Sigmoid Initial: 3 3 …… 5 5 …… < ? target: 4 2 ……