Network Structure Hungyi Lee Three Steps for Deep


 • Fully Connected Layer • Recurrent Structure • Convolutional/Pooling")























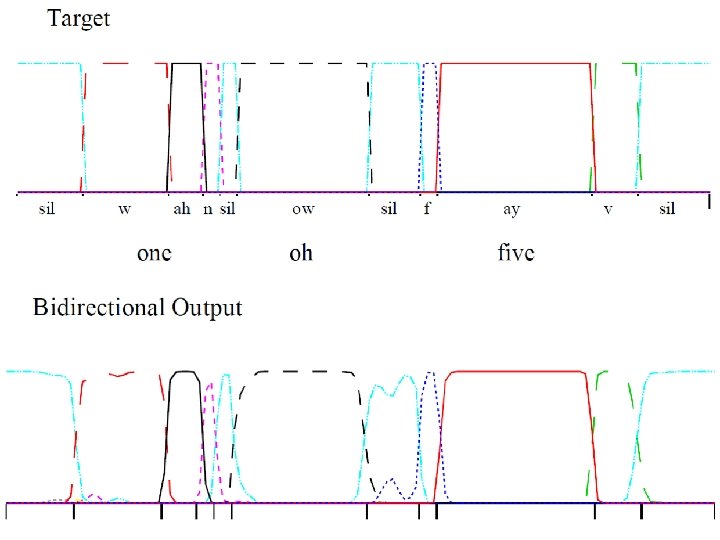
 Speech Recognition: Frame classification on TIMIT y 1 y 2")










 filter (kernel)")












- Slides: 52
Network Structure Hung-yi Lee 李宏毅
Three Steps for Deep Learning Step 1: Neural Network Step 2: Cost Function Step 3: Optimization Step 1. A neural network is a function composed of simple functions (neurons) Ø Usually we design the network structure, and let machine find parameters from data Step 2. Cost function evaluates how good a set of parameters is Ø We design the cost function based on the task Step 3. Find the best function set (e. g. gradient descent)
Outline • Basic structure (3/03) • Fully Connected Layer • Recurrent Structure • Convolutional/Pooling Layer • Special Structure (3/17) • Spatial Transformation Layer • Highway Network / Grid LSTM • Recursive Structure • External Memory • Batch Normalization • Sequence-to-sequence / Attention (3/24)
Prerequisite • Brief Introduction of Deep Learning • https: //youtu. be/Dr. WRl. EFefw? list=PLJV_el 3 u. VTs. Py 9 o. CRY 30 o. BPNLCo 89 yu 49 • Convolutional Neural Network • https: //youtu. be/Fr. KWi. Rv 254 g? list=PLJV_el 3 u. VTs. Py 9 o. C RY 30 o. BPNLCo 89 yu 49 • Recurrent Neural Network (Part I) • https: //youtu. be/x. CGid. Aey. S 4 M? list=PLJV_el 3 u. VTs. Py 9 o CRY 30 o. BPNLCo 89 yu 49 • Recurrent Neural Network (Part II) • https: //www. youtube. com/watch? v=r. Tqm. Wlnwz_0&list =PLJV_el 3 u. VTs. Py 9 o. CRY 30 o. BPNLCo 89 yu 49&index=25
Basic Structure: Fully Connected Layer
Fully Connected Layer Output of a neuron: Layer …… …… Neuron i Output of one layer: …… …… Layer nodes : a vector
Fully Connected Layer to Layer …… …… Layer nodes from neuron j (Layer to neuron i (Layer ) )
Fully Connected Layer : bias for neuron i at layer l …… …… Layer nodes bias for all neurons in layer l
Fully Connected Layer : input of the activation function for neuron i at layer l : input of the activation function all the neurons in layer l …… …… …… Layer nodes
Relations between Layer Outputs …… …… Layer nodes
Relations between Layer Outputs … … …… …… Layer nodes
Relations between Layer Outputs …… …… Layer nodes
Relations between Layer Outputs …… …… Layer nodes
Basic Structure: Recurrent Structure Simplify the network by using the same function again and again
Reference K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink, J. Schmidhuber, "LSTM: A Search Space Odyssey, " in IEEE Transactions on Neural Networks and Learning Systems, 2016 Rafal Józefowicz, Wojciech Zaremba, Ilya Sutskever, “An Empirical Exploration of Recurrent Network Architectures, ” in ICML, 2015 https: //www. cs. toronto. edu/~ graves/preprint. pdf
Recurrent Neural Network h and h’ are vectors with the same dimension • y 1 h 0 f x 1 y 2 h 1 f x 2 y 3 h 2 f h 3 …… x 3 No matter how long the input/output sequence is, we only need one function f
Deep RNN … … … b 0 c 1 c 2 c 3 f 2 b 1 y 1 h 0 f 1 x 1 f 2 b 2 y 2 h 1 f 1 x 2 f 2 b 3 …… y 3 h 2 f 1 x 3 h 3 ……
Bidirectional RNN x 1 b 0 f 2 x 2 b 1 c 1 f 3 f 1 x 1 b 2 c 2 y 1 a 1 h 0 f 2 x 3 f 1 x 2 b 3 c 3 y 2 a 2 h 1 f 2 f 3 y 3 a 3 h 2 f 1 x 3 h 3
Pyramidal RNN • Reducing the number of time steps W. Chan, N. Jaitly, Q. Le and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition, ” ICASSP, 2016
Naïve RNN • y h f x h' Wh h y Wo h' Wi x h' softmax Ignore bias here
yt LSTM yt ct-1 ct LSTM ht-1 Naive xt ht ht-1 ht xt c change slowly ct is ct-1 added by something h change faster ht and ht-1 can be very different
z ct-1 zi zf zf zi z ht-1 xt W Wi Wf zo zo xt Wo ht-1 xt ht-1
xt z W ct-1 ht-1 ct-1 diagonal “peephole ” zf zo zi z ht-1 xt zo zf zi obtained by the same way
yt ct ct-1 tanh zf zi z ht-1 xt zo ht
LSTM yt+1 yt ct+1 ct ct-1 tanh zf zi z tanh zo zf zi z zo ht ht-1 xt ht xt+1
GRU yt ht ht-1 1 reset update r z ht-1 xt h' xt
Example Task • (Simplified) Speech Recognition: Frame classification on TIMIT y 1 y 2 y 3 y 4 TSI TSI I x 1 x 2 x 3 x 4 y 1 y 2 y 3 y 4 …… I N …… Utterance 1 N N S …… S @ @ x 1 x 2 x 3 x 4 …… Utterance 2
Target Delay • Only for unidirectional RNN Delay 3 steps: True labels: x x x TSI TSI TSI I I N N N N
LSTM > RNN > feedforward Bi-direction > uni-direction
Forward direction Reverse direction
Training LSTM is faster than RNN
LSTM: A Search Space Odyssey Standard LSTM works well Simply LSTM: coupling input and forget gate, removing peephole Forget gate is critical for performance Output gate activation function is critical
An Empirical Exploration of Recurrent Network Architectures LSTM-f/i/o: removing forget/input/output gates LSTM-b: large bias Importance: forget > input > output Large bias forget gate is helpful
An Empirical Exploration of Recurrent Network Architectures
Basic Structure: Convolutional / Pooing Layer Simplify the neural network (based on prior knowledge to the task)
Convolutional Layer Receptive Field Sparse Connectivity Each neural only connects to part of the output of the previous layer Different neurons have different, but overlapping, receptive fields ……
Convolutional Layer Sparse Connectivity Each neural only connects to part of the output of the previous layer Parameter Sharing The neurons with different receptive fields can use the same set of parameters. …… Less parameters then fully connected layer
Convolutional Layer Considering neuron 1 and 3 as “filter 1” (kernel 1) filter (kernel) size: size of the receptive field of a neuron Stride = 2 Considering neuron 2 and 4 as “filter 2” (kernel 2) …… Kernel size, no. of filter, stride are all designed by the developers.
Example – 1 D Signal + Single Channel Classification, Predict the future … Audio Signal, Stock Value …
Example – 1 D Signal + Multiple Channel A document: each word is a vector I like this movie very much …… Does this kind of receptive field make sense?
Example – 2 D Signal + Single Channel 0 1 0 0 1 1 0 0 0 1 1 0 0 6 x 6 black & white picture image 7 0 : 8 1 : 9 0 : 0 10: … 1 0 0 1 … Size of Receptive field is 3 x 3, Stride is 1 1 1 : 2 0 : 3 0 : 4 0 : 13 0 : 0 14 : 15: 1 16: 1 Only show 1 filter here …
Example – 2 D Signal + Multiple Channel 7 0 0 : 8 1 1 : 9 0 1 : 0 0 10: 0 0 0 0 … 1 0 0 0 0 1 0 11 00 00 01 00 1 0 0 00 11 01 00 10 0 1 1 0 0 1 00 00 10 11 00 0 11 00 00 01 10 0 0 1 0 0 00 11 00 01 10 0 1 0 6 x 6 colorful image 0 … Size of Receptive field is 3 x 3 x 3, Stride is 1 1 : 2 0 0 : 3 0 1 : 4 0 0 : 13 0 1 : 0 1 14 : 15: 1 0 16: 1 1 1 0 Only show 1 filter here …
Without Zero Padding
Pooling Layer … Average Pooling: Max Pooling: … nodes … … Layer nodes L 2 Pooling:
Pooling Layer Convolutional Layer Which outputs should be grouped together? Pooling Layer Subsampling …… Group the neurons corresponding to the same filter with nearby receptive fields
Pooling Layer Convolutional Layer Which outputs should be grouped together? Pooling Layer Maxout Network How do you know which neurons detect the same pattern? …… Group the neurons with the same receptive field
Combination of Different Basic Layers Tara N. Sainath, Ron J. Weiss, Andrew Senior, Kevin W. Wilson, Oriol Vinyals, “Learning the Speech Front-end. With Raw Waveform CLDNNs, ” In INTERPSEECH 2015
Combination of Different Basic Layers Tara N. Sainath, Ron J. Weiss, Andrew Senior, Kevin W. Wilson, Oriol Vinyals, “Learning the Speech Front-end. With Raw Waveform CLDNNs, ” In INTERPSEECH 2015
Combination of Different Basic Layers Tara N. Sainath, Ron J. Weiss, Andrew Senior, Kevin W. Wilson, Oriol Vinyals, “Learning the Speech Front-end. With Raw Waveform CLDNNs, ” In INTERPSEECH 2015 3 layers
Next Time • 3/10: TAs will teach Tensor. Flow • Tensor. Flow for regression • Tensor. Flow for word vector • word vector: https: //www. youtube. com/watch? v=X 7 PH 3 Nu. YW 0 Q • Tensor. Flow for CNN • If you want to learn Theano • http: //speech. ee. ntu. edu. tw/~tlkagk/courses/MLDS_20 15_2/Lecture/Theano%20 DNN. ecm. mp 4/index. html • http: //speech. ee. ntu. edu. tw/~tlkagk/courses/MLDS_20 15_2/Lecture/Theano%20 RNN. ecm. mp 4/index. html