Snoop Filtering and CoarseGrain Memory Tracking Andreas Moshovos
















 bit vector 1 • Not-Cached Any zero")

















 addresses")





 •")



































 • Miss-rate does not increase •")


: Region Miss 49 21 Address: Region Tag 10 RVA Index 6")

 48 -way 52")








- Slides: 91
Snoop Filtering and Coarse-Grain Memory Tracking Andreas Moshovos Univ. of Toronto/ECE Short Course at the University of Zaragoza, July 2009 Some slides by J. Zebchuk or the original paper authors
JETTY Snoop-Filtering for Reduced Power in SMP Servers Andreas Moshovos Babak Falsafi, ECE, Carnegie Mellon Gokhan Memik, ECE, Northwestern Alok Choudhary, ECE, Northwestern Int’l Conference on High-Performance Architecture, 2001
Power is Becoming Important • Architecture is a science of tradeoffs • Thus far: Performance vs. Cost vs. Complexity • Today: vs. Power • Where? – Mobile Devices – Desktops/Servers Our Focus
Power-Aware Servers • Revisit the design of SMP servers – 2 or more CPUs per machine – Snoop coherence-based • Why? – File, web, databases, your typical desktop – Cost effective too • This work - a first step: Power-Aware Snoopy-Coherence
Power-Aware Snoop-Coherence • Conventional – All L 2 caches snoop all memory traffic – Power expended by all on any memory access • Jetty-Enhanced – – – Tiny structure on L 2 -backside Filters most “would-be-misses” Less power expended on most snoop misses No changes to protocol necessary No performance loss
Roadmap • Why Power is a Concern for Servers? • Snoopy-Coherence Basics • An Opportunity for Reducing Power • JETTY • Results • Summary
Why is Power Important? Power Could Ultimately Limit Performance • • Power Demands have been increasing Deliver Energy to and on chip Dissipate Heat Limit: – Amount of resources & frequency – Feasibility • Cooling a solution: Cost & Integration? Reducing Power Demands is much more convenient
What can be done? • Redesign Circuits • Clock Gating and Frequency Scaling – A lot has been done thus far – Still active • Rethink Architectural Decisions – Orthogonal to others Reduce Power Under Performance Constraints
The “Silver Bullet” Solution • Good if there was one • However, till one is found. . . • Look at all structures • Rethink Design • Propose Power-Optimized versions • This is what we’re doing for performance
Snoopy Cache Coherence CPU Core L 1 L 2 t Hi Main Memory All L 2 tags see all bus accesses Intervene when necessary
How About Power? CPU Core L 1 L 2 iss m m Main Memory All L 2 tags see all bus accesses Perf. & Complexity: Have L 2 tags why not use them Power: All L 2 tags consume power on all accesses
JETTY: A Would be Snoop-Miss Filter Would be Snoop-Miss: Would be Snoop-Hit: CPU n JETTY addr Not here! Don’t Know Detect most misses using fewer resources Imprecise: May filter a would-be miss Never filters snoop-hits
Potential for Savings Exist • Most Snoops miss – 91% AVG • Many L 2 accesses are due to Snoop Misses – 55% AVG • Sizeable Potential Power Savings: – 20% - 50% of total L 2 power
Exclude-Jetty • Subset of what is not cached Exclude JETTY not cached How? Cache recent snoop-misses locally
Exclude-Jetty • Subset of what you don’t have Works well for producer-consumer
Include-Jetty • Superset of what is cached include JETTY cached not cached How? Well. . .
Include-Jetty bit vector 0 address f( ) bit vector 1 • Not-Cached Any zero bit • May be Cached All bits set g( ) bit vector 2 h( ) Later I was told this is a Bloom filter…
Include-Jetty • Superset of what you have Partial overlapping indexes worked better This is a counting bloom filter: L-CBF: A Low Power, Fast Counting Bloom Filter Implementation Elham Safi, Andreas Moshovos and Andreas Veneris, In Proc. Annual International Symposium on Low Power Electronics and Design (ISLPED), Oct. 2006.
Hybrid-Jetty • Some cases Exclude-J works well • Some other Include-J is better • Combine – Access in parallel on snoop – Allocation • IJ always • If IJ fails to filter then to EJ • EJ coverage increases
Latency? • Jetty may increase snoop-response time • Can only be determined on a design by design basis • Largest Jetty: – Five 32 x 32 bit register files
Results • Used SPLASH-II – Scientific applications – “Large” Datasets • e. g. , 4 -80 Megs of main memory allocated • Access Counts: 60 M-1. 7 B – 4 -way SMP, MOESI – 1 M direct-mapped L 2, 64 b 32 b subblocks – 32 k direct-mapped L 1, 32 b blocks • Coverage & Power (analytical model)
better Coverage: Hybrid-Jetty • Can capture 74% of all snoop-misses
better Power-Savings • 28% of overall L 2 power
Summary • Power is becoming important – Performance, Reliability and Feasibility • Unique Opportunities Exist for Servers • JETTY: Filter Snoops that would miss – – 74% of all snoops 28% of L 2 power saved No protocol changes No performance loss
Power efficient cache coherence C. Saldanha, M. Lipasti Workshop on Memory Performance Issues (in conjunction with ISCA), June 2001.
Serial Snooping • Avoids Speculative transmission of Snoop packets. • Check the nearest neighbor • Data supplied with minimum latency and power MEMORY
TLB and Snoop Energy-Reduction using Virtual Caches in Low-Power Chip-Multiprocessors Magnus Ekman, *Fredrik Dahlgren, and Per Stenström Chalmers University of Technology Ericsson Mobile Platforms Int’l Symposium on Low Power Electronic Design and Devices, Aug. 2002
Page Sharing Tables • On snoop requesting node gets a page-level sharing vector If a PST entry is evicted the whole page must be evicted Paper by same authors demonstrates the Jetty is not beneficial for small-scale CMPs
Region. Scout: Exploiting Coarse Grain Sharing in Snoop Coherence Andreas Moshovos moshovos@eecg. toronto. edu Int’l Conference on Computer Architecture 2005 29
Improving Snoop Coherence CPU I$ D$ interconnect Main Memory § Conventional Considerations: Complexity and Correctness NOT Power/Bandwidth § Can we: (1) Reduce Power/bandwidth (2) Leverage snoop coherence? § Remains Attractive: Simple / Design Re-use Yes: Exploit Program Behavior to Dynamically Identify Requests that do not Need Snooping 30
Region. Scout: Avoid Some Snoops CPU I$ D$ interconnect Main Memory • Frequent case: non-sharing even at a coarse level/Region • Region. Scout: Dynamically Identify Non-Shared Regions – First Request to a Region Identifies it as not Shared – Subsequent Requests do not need to be broadcast • Uses Imprecise Information – Small structures – Layer on top of conventional coherence – No additional constraints 31
Roadmap • Conventional Coherence: – The need for power-aware designs • Potential: Program Behavior • Region. Scout: What and How • Implementation • Evaluation • Summary 32
Coherence Basics CPU CPU X p s o no sn p o o t hi Main Memory • Given request for memory block X (address) • Detect where its current value resides 33
Conventional Coherence not Power-Aware/Bandwidth-Effective CPU CPU L 2 iss m Main Memory All L 2 tags see all accesses Perf. & Complexity: Have L 2 tags why not use them Power: All L 2 tags consume power on all accesses Bandwidth: broadcast all coherent requests 34
Region. Scout Motivation: Sharing is Coarse Typical Memory Space Snapshot: colored by owner(s) addresses • Region: large continuous memory area, power of 2 size • CPU X asks for data block in region R 1. No one else has X 2. No one else has any block in R Region. Scout Exploits this Behavior Layered Extension over Snoop Coherence 35
Optimization Opportunities CPU I$ D$ CPU I$ SWITCH Memory • Power and Bandwidth – Originating node: avoid asking others – Remote node: avoid tag lookup D$
better % of all requests Global Region Misses Potential: Region Miss Frequency Region Size Even with a 16 K Region ~45% of requests miss in all remote nodes
Region. Scout at Work: Non-Shared Region Discovery CPU CPU 2 3 1 2 Region Miss Global Region Miss Main Memory Record: Non-Shared Regions Record: Locally Cached Regions First request detects a non-shared region
Region. Scout at Work: Avoiding Snoops CPU CPU 1 2 Global Region Miss Main Memory Record: Non-Shared Regions Record: Locally Cached Regions Subsequent request avoids snoops
Region. Scout is Self-Correcting CPU 1 2 CPU 2 Main Memory Record: Non-Shared Regions Record: Locally Cached Regions Request from another node invalidates non-shared record
Implementation: Requirements • Requesting Node provides address: address Region Tag offset lg(Region Size) • At Originating Node – from CPU: – Have I discovered that this region is not shared? • At Remote Nodes – from Interconnect: – Do I have a block in the region? CPU
Remembering Non-Shared Regions address Region Tag offset Non-Shared Region Table valid Few entries 16 x 4 in most experiments • Records non-shared regions • Lookup by Region portion prior to issuing a request • Snoop requests and invalidate
What Regions are Locally Cached? Region Tag offset counter • If we had as many counters as regions: – Block Allocation: counter[region]++ – Block Eviction: counter[region]-– Region cached only if counter[region] non-zero • Not Practical: – E. g. , 16 K Regions and 4 G Memory 256 K counters
What Regions are Locally Cached? Region Tag offset Cached Region Hash hash M os ho vo s © p bits counter “Counter”: + on block allocation - on block eviction Few entries, e. g. , 256 P-bit 1 if counter non-zero used for lookups • Use few Counters Imprecise: – Records a superset of locally cached Regions – False positives: lost opportunity, correctness preserved
Roadmap • Conventional Coherence • Program Behavior: Region Miss Frequency • Region. Scout • Evaluation • Summary M os ho vo s ©
Evaluation Overview • Methodology • Filter rates – Practical Filters can capture many Region Misses • Interconnect bandwidth reduction M os ho vo s ©
Methodology • In-House simulator based on Simplescalar – – – – – Execution driven All instructions simulated – MIPS like ISA System calls faked by passing them to host OS Synchronization using load-linked/store-conditional Simple in-order processors Memory requests complete instantaneously MESI snoop coherence 1 or 2 level memory hierarchy WATTCH power models • SPLASH II benchmarks – Scientific workloads – Feasibility study M os ho vo s ©
Filter Rates Identified Global Region Misses better M os ho vo s © CRH Size For small CRH better to use large regions Practical Region. Scout filters capture a lot of the potential
M os ho vo s © CMP better Messages Bandwidth Reduction Region Size Moderate Bandwidth Savings for SMP (15%-22%) More so for CMP (>25%)
Related Work • Region. Scout – Technical Report, Dec. 2003 • Jetty – Moshovos, Memik, Falsafi, Choudhary, HPCA 2001 • PST – Eckman, Dahlgren, and Stenström, ISLPED 2002 • Coarse-Grain Coherence – Cantin, Lipasti and Smith, ISCA 2005 M os ho vo s ©
Summary • Exploit program behavior/optimize a frequent case – Many requests result in a global region miss • Region. Scout – – – – Practical filter mechanism Dynamically detect would-be region misses Avoid broadcasts Save tag lookup power and interconnect bandwidth Small structures Layered extension over existing mechanisms Invisible to programmer and the OS 51 M os ho vo s ©
Coarse-Grain Coherence J. Cantin, M. Lipasti and J. E. Smith ISCA 2005
Coarse-Grain Coherence • Exploits the same phenomenon as Region. Scout • Protocol extended to keep track of region state as well – Additional optimizations • Uses an additional region tag array to do so • Region replacements – Must scan and find the block and evict them
Flexible snooping: adaptive forwarding and filtering of snoops in embedded-ring multiprocessors K. Strauss, X. Shen, J. Torrellas International Symposium on Computer Architecture, June 2006.
Predictors and algorithms Ka rin Str au ss Ring-specific set of addresses: node can supply in predictor / algorithm action on negative prediction action on positive prediction Subset forward then snoop Super set Exact Con forward Agg forward snoop then forward then snoop Fl exi ble Sn oo pin g 55
Predictor implementation • Subset – associative table: subset of addresses that can be supplied by node Ka rin Str au ss Fl exi ble Sn oo pin g • Superset – bloom filter: superset of addresses that can be supplied by node – associative table (exclude cache): addresses that recently suffered false positives • Exact – associative table: all addresses that can be supplied by node – downgrading: if address has to be evicted from predictor table, corresponding line in node has to be downgraded 56
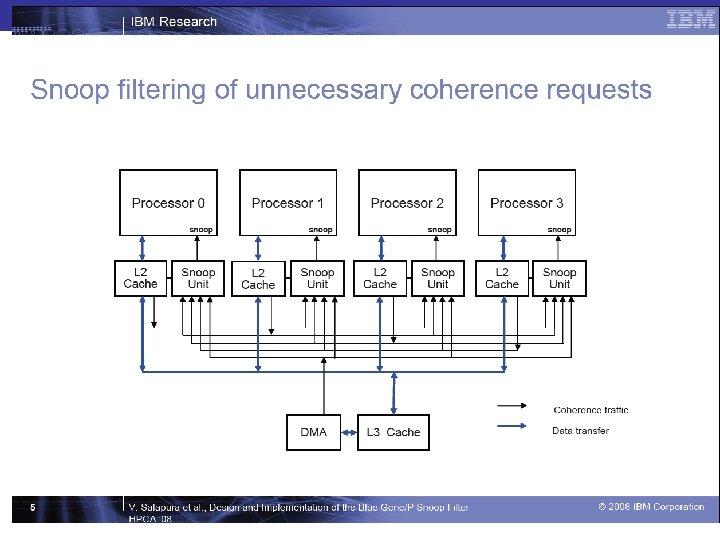
Design and Implementation of the Blue Gene/P Snoop Filter Valentina Salapura, Matthias Blumrich, Alan Gara Int’l Conf. on High-Performance Computer Architecture, 2008
Three Mechanisms • Stream registers – Contiguous data areas – Adaptive to cache arbitrarily sized contiguous regions with a single register – Stream registers track strided and sequential streams • Snoop caches – Cache of recently executed snoop requests – Multiple requests to same line do not have to cause multiple snoop lookups – Snoop caches track locality • Range filter – Identify regions of known non-shared data – Configured by software
Stream Registers • Base = where the block starts • Mask = which bits are common – Example: base 0111 mask 1101 01 X 1 may be in the cache • Over time Mask becomes all zeros • How to reset? • Cache Wrap – – – Each set uses Round-Robin replacement Count replacements per set Cache wrap when all counters > ways Copy all streams to history and use combination Next time throw out history
Time Stream Registers: An Example • Direct mapped cache with two blocks cache Stream registers empty 001 / 111 empty 001 / 1 X 1 011 empty 101 001 / 111 011 101 / 111 101 001 / 1 X 1 111 101 / 1 X 1 • At this point the filter reports that the cache contains: – 001 and 011 – 101 and 111 • The first two are not there • Eventually the filter becomes saturated and can filter much • How can we get rid of the 011 / 1 x 1?
Time Avoiding Saturation: Exploiting Cache Warping cache Stream registers Shadow empty empty 001 / 111 empty 001 / 1 X 1 011 empty 101 empty 001 / 1 X 1 011 101 / 111 empty 101 empty 001 / 1 X 1 111 101 / 1 X 1 empty Cache Warp Can discard Shadow
Exploiting Access Semantics and Program Behavior to Reduce Snoop Power in Chip Multiprocessors Chinnakrishnan S. Ballapuram Ahmad Sharif Hsien-Hsin S. Lee ASPLOS 2008
Software-Hardware Hybrid • Software Directs hardware what to do – Mechanisms very similar to Jetty and Region. Scout • Paper incorrectly states that: – Jetty does not work for CMPs • It does not work well for small scale CMPs – Region. Scout works only for busses • Is interconnect agnostic
Region. Tracker: A Framework for Coarse. Grain Optimizations in the On-chip Memory Hierarchy Jason Zebchuk, Elham Safi and Andreas Moshovos Int’l Symposium on Microarchitecture, 2007
Future Caches: Just Larger? E PF L, Ja n. 20 08 CPU I$ D$ interconnect 10 s – 100 s of MB Main Memory 1. “Big Picture” Management 2. Store Metadata Aenao Group/Toronto 66
Conventional Block Centric Cache E PF L, Ja n. 20 08 Fine-Grain View of Memory L 2 Cache • “Small” Blocks – Optimizes Bandwidth and Performance • Large L 2/L 3 caches especially Big Picture Lost Aenao Group/Toronto 67
“Big Picture” View E PF L, Ja n. 20 08 Coarse-Grain View of Memory L 2 Cache • Region: 2 n sized, aligned area of memory • Patterns and behavior exposed – Spatial locality • Exploit for performance/area/power Aenao Group/Toronto 68
Exploiting Coarse-Grain Patterns Coarse-Grain Framework Power-Efficient DRAM Speculation Circuit-Switched Coherence Stealth Prefetching Virtual Tree Coherence Spatial Memory Streaming CPU Region. Scout Embed coarse-grain Run-time Adaptive Cache information in tag array Hierarchy Management via Reference Analysis n Support many different optimizations with less area Destination-Set Prediction overhead n E PF L, Ja n. 20 08 L 2 Cache Coarse-Grain Coherence Tracking Adaptable optimization FRAMEWORK • Many existing coarse-grain optimizations • Add new structures to track coarse-grain information Hard to justify for a commercial design Aenao Group/Toronto 69
Region. Tracker Solution E PF L, Ja n. 20 08 L 2 Cache L 1 Data Blocks L 1 Block Requests L 1 Region Probes L 1 Region Responses Data Array Region Tag Array Tracker Block Requests Manage blocks, but also track and manage regions Aenao Group/Toronto 70
Region. Tracker Summary E PF L, Ja n. 20 08 • Replace conventional tag array: – – 4 -core CMP with 8 MB shared L 2 cache Within 1% of original performance Up to 20% less tag area Average 33% less energy consumption • Optimization Framework: – Stealth Prefetching: same performance, 36% less area – Region. Scout: 2 x more snoops avoided, no area overhead Aenao Group/Toronto 71
Road Map E PF L, Ja n. 20 08 • Introduction • Goals • Coarse-Grain Cache Designs • Region. Tracker: A Tag Array Replacement • Region. Tracker: An Optimization Framework • Conclusion Aenao Group/Toronto 72
Goals 1. Conventional Tag Array Functionality E PF L, Ja n. 20 08 – Identify data block location and state – Leave data array un-changed 2. Optimization Framework Functionality – – Is Region X cached? Which blocks of Region X are cached? Where? Evict or migrate Region X Easy to assign properties to each Region Aenao Group/Toronto 73
Coarse-Grain Cache Designs Large Block Size Tag Array E PF L, Ja n. 20 08 Data Array Region X • Increased BW, Decreased hit-rates Aenao Group/Toronto 74
Sector Cache Tag Array E PF L, Ja n. 20 08 Data Array Region X • Decreased hit-rates Aenao Group/Toronto 75
Sector Pool Cache Tag Array E PF L, Ja n. 20 08 Data Array Region X • High Associativity (2 - 4 times) Aenao Group/Toronto 76
Decoupled Sector Cache Tag Array Status Table E PF L, Ja n. 20 08 Data Array Region X • Region information not exposed • Region replacement requires scanning multiple entries Aenao Group/Toronto 77
Design Requirements • Small block size (64 B) • Miss-rate does not increase • Lookup associativity does not increase • No additional access latency E PF L, Ja n. 20 08 – (i. e. , No scanning, no multiple block evictions) • Does not increase latency, area, or energy • Allows banking and interleaving • Fit in conventional tag array “envelope” Aenao Group/Toronto 78
E PF L, Ja n. 20 08 Region. Tracker: A Tag Array Replacement L 1 Region Vector Array Data Array L 1 Evicted Region Buffer Block Status Table • 3 SRAM arrays, combined smaller than tag array Aenao Group/Toronto 79
Common Case: Hit E PF L, Ja n. 20 08 Ex: 8 MB, 16 -way set-associative cache, 64 -byte blocks, 1 KB region 49 21 Address: Region Tag 10 RVA Index 6 0 Region Offset Block Offset Data Array + BST Index 19 6 Region Vector Array (RVA) 0 Block Status Table (BST) …… Region Tag k oc 0 V way 1 4 Aenao Group/Toronto 15 k oc bl bl status 3 2 To Data Array 80
Worst Case (Rare): Region Miss 49 21 Address: Region Tag 10 RVA Index 6 0 Region Offset Block Offset Ptr Data Array + BST Index 19 6 Region Vector Array (RVA) Evicted Region Buffer (ERB) No Match! E PF L, Ja n. 20 08 0 Block Status Table (BST) …… Region Tag k oc 0 V way Aenao Group/Toronto 15 k oc bl bl status Ptr 3 2 81
Methodology • Flexus simulator from CMU Sim. Flex group – Based on Simics full-system simulator • 4 -core CMP modeled after Piranha – Private 32 KB, 4 -way set-associative L 1 caches – Shared 8 MB, 16 -way set-associative L 2 cache – 64 -byte blocks • • P P D$ I$ Miss-rates: Functional simulation of 2 billion instructions per core Interconnect Performance and Energy: Timing simulation using SMARTS sampling methodology L 2 Area and Power: Full custom implementation on 130 nm commercial technology 9 commercial workloads: – WEB: Spec. WEB on Apache and Zeus – OLTP: TPC-C on DB 2 and Oracle – DSS: 5 TPC-H queries on DB 2 Aenao Group/Toronto 82
Miss-Rates vs. Area Relative Miss-Rate Sector Cache (0. 25, 1. 26) 48 -way 52 -way 14 -way be tte r 15 -way Relative Tag Array Area • Sector Cache: 512 KB sectors, SPC and RT: 1 KB regions • Trade-offs comparable to conventional cache Aenao Group/Toronto 83
Performance & Energy better Energy Reduction in Tag Energy Normalized Execution Time Performance better • 12 -way set-associative Region. Tracker: 20% less area • Error bars: 95% confidence interval • Performance within 1%, with 33% tag energy reduction EPFL, Jan. 2008 Aenao Group/Toronto 84
Road Map • Introduction • Goals • Coarse-Grain Cache Designs • Region. Tracker: A Tag Array Replacement • Region. Tracker: An Optimization Framework • Conclusion Aenao Group/Toronto 85
Region. Tracker: An Optimization Framework Stealth Prefetching: Average 20% performance improvement Drop-in Region. Tracker for 36% less area overhead L 1 RVA Data Array L 1 ERB L 1 BST Region. Scout: In-depth analysis Aenao Group/Toronto 86
Snoop Coherence: Common Case CPU Read x+n x+1 x+2 x is m s CPU m is s Main Memory Many snoops are to non-shared regions Aenao Group/Toronto 87
Region. Scout CPU Read x CPU Miss Global Region Miss Main Memory Non-Shared Regions Locally Cached Regions Eliminate broadcasts for non-shared regions Aenao Group/Toronto 88
Region. Tracker Implementation Locally Cached Regions Already provided by RVA Non-Shared Regions Add 1 bit to each RVA entry • Minimal overhead to support Region. Scout optimization • Still uses less area than conventional tag array Aenao Group/Toronto 89
Region. Tracker + Region. Scout 4 processors, 512 KB L 2 Caches n 1 KB regions Reduction in Snoop Broadcasts n 50% HMEAN 40% better 30% 20% 10% 0% RS 7 KB RS 12 KB RS 22 KB RSRT Avoid 41% of Snoop Broadcasts, no area overhead compared to conventional tag array Aenao Group/Toronto 90
Result Summary • Replace Conventional Tag Array: E PF L, Ja n. 20 08 – 20% Less tag area – 33% Less tag energy – Within 1% of original performance • Coarse-Grain Optimization Framework: – 36% reduction in area overhead for Stealth Prefetching – Filter 41% of snoop broadcasts with no area overhead compared to conventional cache Aenao Group/Toronto 91