Xen 3 0 and the Art of Virtualization





















 ¾ Enable Guest OSes to be run without paravirtualization modifications §")
 (32 -bit) Linux xen 64 Unmodified OS")




































- Slides: 62
Xen 3. 0 and the Art of Virtualization Ian Pratt Keir Fraser, Steven Hand, Christian Limpach, Andrew Warfield, Dan Magenheimer (HP), Jun Nakajima (Intel), Asit Mallick (Intel) Computer Laboratory
Outline ¾Virtualization Overview ¾Xen Architecture ¾New Features in Xen 3. 0 ¾VM Relocation ¾Xen Roadmap
Virtualization Overview ¾Single OS image: Virtuozo, Vservers, Zones § Group user processes into resource containers § Hard to get strong isolation ¾ Full virtualization: VMware, Virtual. PC, QEMU § Run multiple unmodified guest OSes § Hard to efficiently virtualize x 86 ¾Para-virtualization: UML, Xen § Run multiple guest OSes ported to special arch § Arch Xen/x 86 is very close to normal x 86
Virtualization in the Enterprise Consolidate under-utilized servers to reduce Cap. Ex and Op. Ex X Avoid downtime with VM Relocation Dynamically re-balance workload to guarantee application SLAs X X Enforce security policy
Xen Today : Xen 2. 0. 6 ¾Secure isolation between VMs ¾Resource control and Qo. S ¾Only guest kernel needs to be ported § User-level apps and libraries run unmodified § Linux 2. 4/2. 6, Net. BSD, Free. BSD, Plan 9, Solaris ¾Execution performance close to native ¾Broad x 86 hardware support ¾Live Relocation of VMs between Xen nodes
Para-Virtualization in Xen ¾Xen extensions to x 86 arch § Like x 86, but Xen invoked for privileged ops § Avoids binary rewriting § Minimize number of privilege transitions into Xen § Modifications relatively simple and self-contained ¾Modify kernel to understand virtualised env. § Wall-clock time vs. virtual processor time • Desire both types of alarm timer § Expose real resource availability • Enables OS to optimise its own behaviour
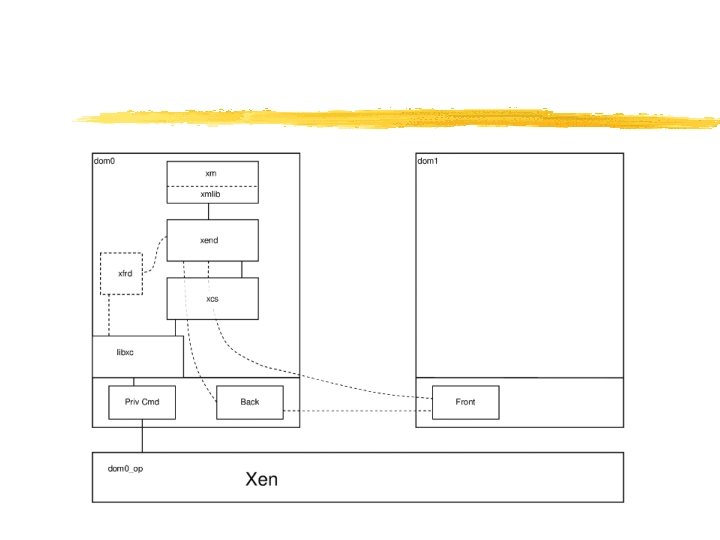
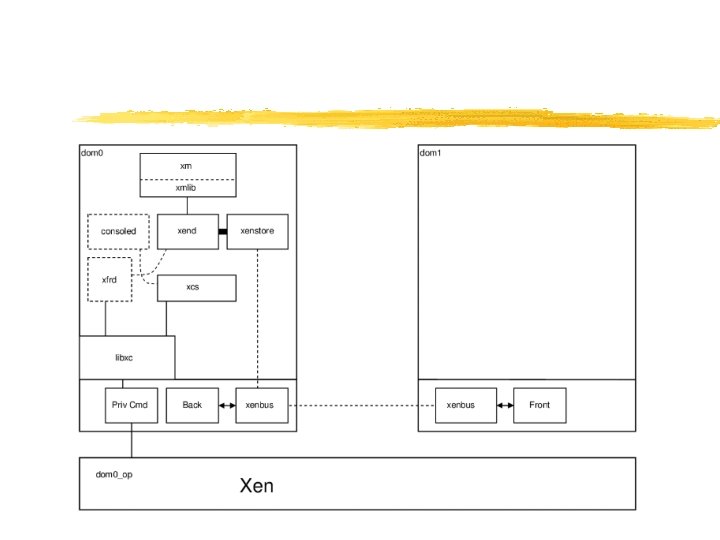
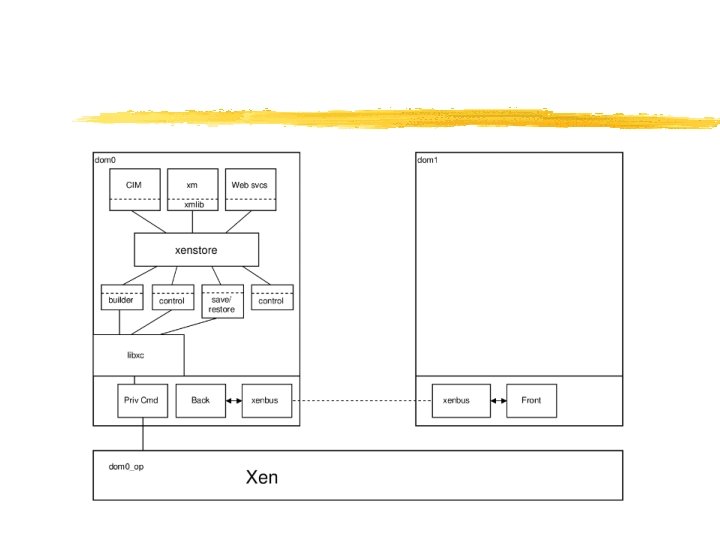
Xen 2. 0 Architecture VM 0 VM 1 VM 2 VM 3 Device Manager & Control s/w Unmodified User Software Guest. OS (Xen. Linux) (Xen. BSD) Back-End Front-End Device Drivers Native Device Driver Control IF Native Device Driver Safe HW IF Event Channel Virtual CPU Virtual MMU Xen Virtual Machine Monitor Hardware (SMP, MMU, physical memory, Ethernet, SCSI/IDE)
Xen 3. 0 Architecture AGP ACPI PCI x 86_32 x 86_64 IA 64 VM 0 Device Manager & Control s/w VM 1 Unmodified User Software VM 2 Unmodified User Software Guest. OS (Xen. Linux) Back-End SMP Native Device Driver Control IF Native Device Driver Safe HW IF Front-End Device Drivers Event Channel Virtual CPU VM 3 Unmodified User Software Unmodified Guest. OS (Win. XP)) Front-End Device Drivers Virtual MMU Xen Virtual Machine Monitor Hardware (SMP, MMU, physical memory, Ethernet, SCSI/IDE) VT-x
4 GB 3 GB 0 GB Xen S Kernel S User U ring 3 ring 1 ring 0 x 86_32 ¾ Xen reserves top of VA space ¾ Segmentation protects Xen from kernel ¾ System call speed unchanged ¾ Xen 3 now supports PAE for >4 GB mem
x 86_64 264 -247 Kernel U Xen S Reserved 247 User 0 U ¾ Large VA space makes life a lot easier, but: ¾ No segment limit support èNeed to use page-level protection to protect hypervisor
x 86_64 r 3 User Kernel U U syscall/sysret r 0 Xen S ¾ Run user-space and kernel in ring 3 using different pagetables § Two PGD’s (PML 4’s): one with user entries; one with user plus kernel entries ¾ System calls require an additional syscall/ret via Xen ¾ Per-CPU trampoline to avoid needing GS in Xen
Para-Virtualizing the MMU ¾Guest OSes allocate and manage own PTs § Hypercall to change PT base ¾Xen must validate PT updates before use § Allows incremental updates, avoids revalidation ¾Validation rules applied to each PTE: 1. Guest may only map pages it owns* 2. Pagetable pages may only be mapped RO ¾Xen traps PTE updates and emulates, or ‘unhooks’ PTE page for bulk updates
Writeable Page Tables : 1 – Write fault guest reads Virtual → Machine first guest write Guest OS page fault Xen VMM MMU Hardware
Writeable Page Tables : 2 – Emulate? guest reads Virtual → Machine first guest write Guest OS yes emulate? Xen VMM MMU Hardware
Writeable Page Tables : 3 - Unhook guest reads guest writes X Virtual → Machine Guest OS Xen VMM MMU Hardware
Writeable Page Tables : 4 - First Use guest reads guest writes X Virtual → Machine Guest OS page fault Xen VMM MMU Hardware
Writeable Page Tables : 5 – Re-hook guest reads Virtual → Machine guest writes Guest OS validate Xen VMM MMU Hardware
MMU Micro-Benchmarks 1. 1 1. 0 0. 9 0. 8 0. 7 0. 6 0. 5 0. 4 0. 3 0. 2 0. 1 0. 0 L X V Page fault (µs) U L X V U Process fork (µs) lmbench results on Linux (L), Xen (X), VMWare Workstation (V), and UML (U)
SMP Guest Kernels ¾Xen extended to support multiple VCPUs § Virtual IPI’s sent via Xen event channels § Currently up to 32 VCPUs supported ¾Simple hotplug/unplug of VCPUs § From within VM or via control tools § Optimize one active VCPU case by binary patching spinlocks
SMP Guest Kernels ¾ Takes great care to get good SMP performance while remaining secure § Requires extra TLB syncronization IPIs ¾ Paravirtualized approach enables several important benefits § Avoids many virtual IPIs § Allows ‘bad preemption’ avoidance § Auto hot plug/unplug of CPUs ¾ SMP scheduling is a tricky problem § Strict gang scheduling leads to wasted cycles
I/O Architecture ¾ Xen IO-Spaces delegate guest OSes protected access to specified h/w devices § Virtual PCI configuration space § Virtual interrupts § (Need IOMMU for full DMA protection) ¾ Devices are virtualised and exported to other VMs via Device Channels § Safe asynchronous shared memory transport § ‘Backend’ drivers export to ‘frontend’ drivers § Net: use normal bridging, routing, iptables § Block: export any blk dev e. g. sda 4, loop 0, vg 3 ¾ (Infiniband / Smart NICs for direct guest IO)
VT-x / (Pacifica) ¾ Enable Guest OSes to be run without paravirtualization modifications § E. g. legacy Linux, Windows XP/2003 ¾ CPU provides traps for certain privileged instrs ¾ Shadow page tables used to provide MMU virtualization ¾ Xen provides simple platform emulation § BIOS, Ethernet (ne 2 k), IDE emulation ¾ (Install paravirtualized drivers after booting for high-performance IO)
Domain 0 Domain N Guest VM (VMX) (32 -bit) Linux xen 64 Unmodified OS 3 D FE Virtual Drivers Linux xen 64 Native Device Drivers Front end Virtual Drivers Backend Virtual driver Native Device Drivers Device Models 1/3 P Control Panel (xm/xend) 3 P Guest VM (VMX) (64 -bit) Guest BIOS Virtual Platform VMExit Callback / Hypercall VMExit Event channel 0 P Control Interface Processor Scheduler Event Channel Memory Xen Hypervisor Hypercalls I/O: PIT, APIC, IOAPIC 0 D
MMU Virtualizion : Shadow-Mode guest reads Virtual → Pseudo-physical Guest OS guest writes Accessed & dirty bits Updates Virtual → Machine VMM MMU Hardware
VM Relocation : Motivation ¾VM relocation enables: § High-availability Xen • Machine maintenance § Load balancing • Statistical multiplexing gain Xen
Assumptions ¾Networked storage § NAS: NFS, CIFS § SAN: Fibre Channel § i. SCSI, network block dev § drdb network RAID ¾Good connectivity § common L 2 network § L 3 re-routeing Xen Storage
Challenges ¾VMs have lots of state in memory ¾Some VMs have soft real-time requirements § E. g. web servers, databases, game servers § May be members of a cluster quorum è Minimize down-time ¾Performing relocation requires resources è Bound and control resources used
Relocation Strategy Stage 0: pre-migration Stage 1: reservation Stage 2: iterative pre-copy Stage 3: stop-and-copy Stage 4: commitment VM active on host A Destination host selected (Block devices mirrored) Initialize container on target host Copy dirty pages in successive rounds Suspend VM on host A Redirect network traffic Synch remaining Activate on hoststate B VM state on host A released
Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 1
Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2
Pre-Copy Migration: Round 2
Pre-Copy Migration: Final
Writable Working Set ¾Pages that are dirtied must be re-sent § Super hot pages • e. g. process stacks; top of page free list § Buffer cache § Network receive / disk buffers ¾Dirtying rate determines VM down-time § Shorter iterations → less dirtying → …
Rate Limited Relocation ¾Dynamically adjust resources committed to performing page transfer § Dirty logging costs VM ~2 -3% § CPU and network usage closely linked ¾E. g. first copy iteration at 100 Mb/s, then increase based on observed dirtying rate § Minimize impact of relocation on server while minimizing down-time
Web Server Relocation
Iterative Progress: SPECWeb 52 s
Iterative Progress: Quake 3
Quake 3 Server relocation
Extensions ¾Cluster load balancing § Pre-migration analysis phase § Optimization over coarse timescales ¾Evacuating nodes for maintenance § Move easy to migrate VMs first ¾Storage-system support for VM clusters § Decentralized, data replication, copy-on-write ¾Wide-area relocation § IPSec tunnels and Co. W network mirroring
Current 3. 0 Status x 86_32 p x 86_64 IA 64 Power Domain 0 Domain U SMP Guests new! ~tools >4 GB memory 16 GB 4 TB ? VT 64 -on-64 Driver Domains Save/Restore/Migrate
3. 1 Roadmap ¾Improved full-virtualization support § Pacifica / VT-x abstraction ¾Enhanced control tools project ¾Performance tuning and optimization § Less reliance on manual configuration ¾Infiniband / Smart NIC support ¾(NUMA, Virtual framebuffer, etc)
Research Roadmap ¾Whole-system debugging § Lightweight checkpointing and replay § Cluster/dsitributed system debugging ¾Software implemented h/w fault tolerance § Exploit deterministic replay ¾VM forking § Lightweight service replication, isolation ¾Secure virtualization § Multi-level secure Xen
Conclusions ¾Xen is a complete and robust GPL VMM ¾Outstanding performance and scalability ¾Excellent resource control and protection ¾Vibrant development community ¾Strong vendor support ¾http: //xen. sf. net
Thanks! ¾The Xen project is hiring, both in Cambridge UK, Palo Alto and New York Computer Laboratory ¾ian@xensource. com
Backup slides
Isolated Driver VMs ¾ Run device drivers in separate domains ¾ Detect failure e. g. § Illegal access § Timeout ¾ Kill domain, restart ¾ E. g. 275 ms outage from failed Ethernet driver 350 300 250 200 150 100 50 0 0 5 10 15 20 25 time (s) 30 35 40
Device Channel Interface
Scalability ¾Scalability principally limited by Application resource requirements § several 10’s of VMs on server-class machines ¾Balloon driver used to control domain memory usage by returning pages to Xen § Normal OS paging mechanisms can deflate quiescent domains to <4 MB § Xen per-guest memory usage <32 KB ¾Additional multiplexing overhead negligible
System Performance 1. 1 1. 0 0. 9 0. 8 0. 7 0. 6 0. 5 0. 4 0. 3 0. 2 0. 1 0. 0 L X V U SPEC INT 2000 (score) L X V U Linux build time (s) L X V U OSDB-OLTP (tup/s) L X V U SPEC WEB 99 (score) Benchmark suite running on Linux (L), Xen (X), VMware Workstation (V), and UML (U)
TCP results 1. 1 1. 0 0. 9 0. 8 0. 7 0. 6 0. 5 0. 4 0. 3 0. 2 0. 1 0. 0 L X V U Tx, MTU 1500 (Mbps) L X V U Rx, MTU 1500 (Mbps) L X V U Tx, MTU 500 (Mbps) L X V U Rx, MTU 500 (Mbps) TCP bandwidth on Linux (L), Xen (X), VMWare Workstation (V), and UML (U)
Scalability 1000 800 600 400 200 0 L X 2 L X 4 L X 8 L X 16 Simultaneous SPEC WEB 99 Instances on Linux (L) and Xen(X)
Aggregate throughput relative to one instance Resource Differentation 2. 0 1. 5 1. 0 0. 5 0. 0 2 4 OSDB-IR 8 8(diff) 2 4 OSDB-OLTP 8 8(diff) Simultaneous OSDB-IR and OSDB-OLTP Instances on Xen