Rethink Server Sizing www qdpma com Joe Chang





")


 blah (IO)")
 & Pentium (P 5 1993) Scale 10 mm = 1. 0")





 L 2 CPU L 2 • Really cheap AGP")


 CPU CPU 4 Processors in node is typical Memory Controller")









 2009 -10+ • Quad-core for 2 -way, L 3 2 M/core")

 3 die options,")



 Scale 10 mm = 2.")
 Scale 10 mm =")
 https: //fuse. wikichip. org/news/1017/isscc-2018 -intels-skylake-sp-mesh-and-floorplan/")


, formerly multi-processor New Scaling Scenarios? MC MC MC MC MC")







































, formerly multi-processor Scaling – NUMA Optimized MC MC MC MC")
, formerly multi-processor Scaling – Not NUMA Optimized MC MC MC")


 - Intel source http: //www. tomshardware. com/news/amd-intel-epyc-xeon-benchmarks, 35993. html")








- Slides: 93
Rethink Server Sizing www. qdpma. com Joe Chang jchang 6 at yahoo. com & Solid. Q
Please silence cell phones Veuillez faire taire les téléphones portables Por favor silencio teléfonos celulares Vänligen tysta mobiltelefoner Пожалуйста, отключите сотовые телефоны � 静音手机, ﻳﺮﺟﻰ ﺇﺳﻜﺎﺕ ﺍﻟﻬﻮﺍﺗﻒ ﺍﻟﻤﺤﻤﻮﻟﺔ
Explore everything PASS has to offer Free online webinar events Local user groups around the world Free 1 -day local training events Online special interest user groups Business analytics training Get involved Free Online Resources Newsletters PASS. org
SQL Server consultant - 1999 Root cause Joe Chang www. qdpma. com Query Optimizer Cost Model Based on random vs. sequential IO Parallel execution plan modeling limitations SQL Exec. Stats Data collection done rights Index and stats scripts
Rethink Server Sizing 2018 Joe Chang qdpma. com Jchang 6 at yahoo
About Joe SQL Server consultant since 1999 Query Optimizer execution plan cost formulas (2002) True cost structure of SQL plan operations (2003? ) Database with distribution statistics only, no data 2004 Decoding statblob/stats_stream • writing your own statistics • Disk IO cost structure • Tools for system monitoring, execution plan analysis • • • See http: //www. qdpma. com/ Exec. Stats download: http: //www. qdpma. com/Exec. Stats. Zip. html Blog: http: //sqlblog. com/blogs/joe_chang/default. aspx ? ? ?
Agenda – Rethink Server Sizing • History of Processors and Server Systems • Server Processors Today • Scaling Options – General Concepts • Up, Out, etc. • What is important in Database Transactions • Memory latency • A true story Column store is great solution for DW, Different topic, other sessions • Single versus Multi-Processors (NUMA) • 1 S: powerful enough, all memory local and fast • 2 S: did you architect DB + App together for NUMA?
Rethink Server Sizing • What are we doing today/is it not best or wrong? • whatever the infrastructure/VM people gives? • whatever Azure/AWS offers, and like it? • specify your own hardware? PCI-E QPI PCI-E C MC • Why is the server multi-processor? C QPI L 3 MC PCI-E • Are you kidding? No MC L 3 MC • What are performance scaling options? • What about VM’s • Single processor QPI MC 76 ns MC
Why Multi-processor? • What is a server? • • Multi-processor blah (memory) blah (IO) blah (whatever) • Why multi-processor? Because everyone does it? • & its always been that way! – not a good answer • OK, but was there a time it was not? • If you are old enough, yes • Then what happened? Dumb answer
Original 486 (1989) & Pentium (P 5 1993) Scale 10 mm = 1. 0 in CPU Control Address Data L 2 Cache Tag Memory PCMC PCI, Cache, Memory 82434 LX LBX 82433 LX PCI SIO PCEB ISA or EISA 486 local bus bridge? 80486 1µm P 5 0. 8µm P 54 0. 6µm 82430 NX PCIset L 2 Cache on system bus • In this era, most systems were not multi-processor • Because MP was still very new • Bridge chip connects CPU, (L 2) cache, memory and IO When dinosaurs & RISC processors still roamed the earth
486 & P 5 Multi-Processor CPU L 2 Tag CPU Bridge L 2 Tag Memory & IO Controller 80486 – 32 -bit data bus CPU Bridge L 2 Tag Bridge Need: custom bridge chip + memory & IO controller MP bus was 64 -bit? 33 MHz? 512 MB Compaq, other companies has 4 -way systems with their custom chips Original bridge chips designed for 486 with 512 K L 2 cache, then updated for P 5 – same L 2 Inadequate to support scaling with P 54 Compaq added 2 M 3 rd level cache – easier than modifying L 2? Custom part + low volume = very expensive
Compaq Pro. Liant 4000 Compaq 4 x Pentium 100 MHz, 1517 tpm. C, 4 x Pentium 133 MHz, 2455 tpm. C, 4 x Pentium 133 MHz, 3516 tpm. C, Learning curve 3500 May 1995, Syb Oct 1995, SQL Dec 1995, Ora tpm-C 3000 133 MHz 2500 2000 1500 133 MHz 1000 500 0 May_95 Early 4 x P 5 (66 MHz) < 1000 tpm. C? Oct_95 Dec_95
Split-Transaction Bus CPU L 2 Tag CPU Bridge Memory & IO Controller L 2 Tag Memory & IO Controller Alternative: split transaction bus, Overlapped 1) command / address and 2) data transfers Two lane road versus 1 -lane CPU Bridge L 2 Tag Bridge 1995/6 Old 4 -way shared bus 1) processor arbitrates for bus, 2) Issues memory access 3) When access completes, releases bus ? Inefficient use of available bus cycles
Pentium P 54 C: 2 -way 1994 P 54 C L 2 Cache Tag Memory System Controller PCI South Bridge really sucked – my opinion Pentium P 54 C second version – 0. 6µm supported simple 2 -way, 2 processors, common external bus shared L 2 cache https: //people. cs. clemson. edu/~mark/330/p 6. html
Pentium Pro 1995/6 L 2 L 2 CPU CPU Command & Address Data PB PB PCI DC PCI DP DC MIC SB 450 GX/KX chipset (errata) Initial system was supposed to 4 -way But – 256 K L 2 was not sufficient for scaling So, 2 -way P Pro w/256 K L 2 first 4 -way P Pro w/512 K L 2 later, finally 1 M +Scale 10 mm = 1. 0 in DP MIC • L 2 cache on backside bus • Reduce activity on FSB • Glue-less multi-processing • No special parts • Split-transaction bus • Overlapped Address & Data 4 x. P Pro 166 MHz, 5, 677 tpm. C, May 1996 (512 K) Compaq 4 x. P Pro 200 MHz, 10, 547 tpm. C, Aug 1997 (1 M L 2) http: //www. informit. com/articles/article. aspx? p=481869&seq. Num=3 Pentium Chronicles – Robert Colwell
Pentium II/III 1997 -99 (&2000/1) L 2 CPU L 2 • Really cheap AGP PCI South Bridge L 2 • Desktop chipset • Memory and PCI North Bridge L 2 • 2 -way system, 1997 May L 2 CPU • No need to have 1 S L 2 CPU • 4 -way (1998 Jun) with • big memory • multiple PCI busses CPU RCG Memory & IO Controller MUX MUX RCG L 2 PXB Scale 10 mm = 1. 0 in 450 NX for Pentium II Xeon Klamath 0. 35µm Deschutes 0. 25µm Katmai 0. 25µm Cascades 0. 18µm
2 -way as baseline standard server • Did wonderful things happen w/multi-processor? • Internet Information Services (multi-threaded) • VB 6 (no multi-threading) component under IIS • 2 -way system, Windows 2000 Server, IIS, VB 6 • Crashes after ~500, 000 demand zero faults • Demand Zero: 4 KB page, zeroed out (4 K x 500 K = 2 B) • Fixed in later SP - still crashes eventually • Recycling still a “feature” of IIS today? • Single processor system – runs forever(ish) We needed learned to program for multi-processor systems Early code was pretty buggy 32 -bit OS
Server. Works Chipsets 1998 -00? Pentium III • 2 memory channels Pentium III • Extra capacity • Multiple PCI busses HE-SL CIOB PCI-64/66 South Bridge • 66 MHz/64 -bit • PCI-X at 100 or 133 MHz Pentium Pro bus required a license from Intel Fujitsu had one, RCC designed P 6 chipset, manufactured by Fujitsu RCC -> Server. Works, could not get P 4 bus license http: //www. informit. com/articles/article. aspx? p=481869&seq. Num=7 Upgrading and Repairing Servers, Scott Mueller, Mark Edward Soper, Barrie Sosinsky http: //www. sql-server-performance. com/2004/chipsets-pros-cons/2/
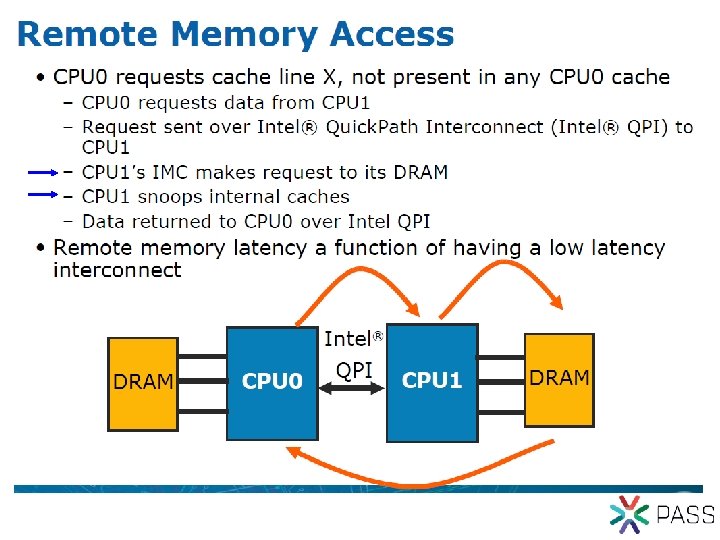
Non-Uniform Memory Access (NUMA) CPU CPU 4 Processors in node is typical Memory Controller Path to memory is non-uniform Cross-bar Memory Controller CPU CPU Remote memory is far away Inter-node communication is expensive? Memory Controller CPU CPU CPU IA-32 processors: memory access must complete in order Scaling is possible However, certain operations exhibit negative scaling, sometimes severely so. Important: Identify bad operations, then code around it. Unfortunately, this very little detail was not explained upfront? P 6 bus: memory operations need to complete in order
SQL Server 2000 – 16 -way - SAP Long ago Network interrupts handled by single processor (affinity) On 4 -way, 27 K RPC/sec On 16 -way – 12 K/sec? Since then Intel Extended Message Signaled Interrupts (MSI-X) and many other techniques Software does not run well on NUMA by accident
8 -way Pro. Fusion - 1999 CPU CPU CPU Cache Coherency Filter MAC PB CPU Corollary (acquired by Intel) 8 -way chipset for Pentium III Point product – was not continued for Xeon (desktop Pentium 4) DIB PB CPU PB PCI-66? Compaq/HP did their own version for Xeon MP https: //www. hpcwire. com/1996/08/16/corollary-debuts-multiprocessing-architecture-for-pentium-pro/ Memory Access Controller (MAC) and Data Interface Buffer (DIB)
Scaling: late 1990’s - early 2000’s L 2 L 2 CPU CPU 1. 6 -1. 7 X RCG Memory & IO Controller MUX Memory Controller 1. 5 X? MUX Memory Controller L 2 MUX 1. 7 -1. 8 X L 2 PXB • Shared bus multi-processors • Very little latency penalty 1 S->2 S • Big cache to reduce traffic for 4 P on shared bus • P 6 bus lacked protocols for NUMA • Memory operations had to complete in order 8 -way+
Itanium 2001/2+ n io s i h T d i l s i e t n y l l a t f le a l b k n
AMD Opteron - 2003/04 HT HT MC L 2 L 1 I Core L 2 L 1 D Core L 1 D L 1 I L 2 MC HT HT MC L 2 L 1 I Core L 2 Core L 1 D L 1 I L 2 MC IO Hub Memory access latency Local node ~60 -70 ns Remote node ~100 ns? Memory controller integrated into CPU die Hyper-Transport – point to point protocol between processors and IO Hub 64 -bit, 16 GP registers, pipelined FP Multi-processor system inherently has non-uniform memory access but absolute memory latency is low Remote node latency is comparable to memory on north bridge AMD emphasized memory bandwidth scaling with nodes. Excellent performance in applications sensitive to memory latency. (Bad) NUMA characteristics were muted? Opteron 130 nm not important, MP needed, 2 P for app, 4 P for database L 1 64 K+64 K L 2 1 M 193 mm 2 Scale 10 mm = 1. 0 in http: //www. chip-architect. com/news/2003_09_21_Detailed_Architecture_of_AMDs_64 bit_Core. html
Two 130 nm processors, 1 M cache IO Hub Scale 10 mm = 2. 0 in AMD Opteron, 193 mm 2 16. 92 x 11. 41 mm 105. 9 M trans Intel Banias 83 mm 2 10. 49 x 7. 91 mm 77 M transistors Opteron 1 M L 2 9. 5 x 8. 7 mm = Banias (Pentium M)1 M L 2 7. 25 x 4. 15 mm = (inclusive of ECC, tags, controls) P. Pro 256 K = 202 mm 2 at 0. 5µm, 1 M projects to 804 mm 2, 202 mm 2 at 0. 5µm, and 50. 5 mm 2 at 0. 13µm https: //www. anandtech. com/show/1083 Banias https: //www. anandtech. com/show/1399 Dothan 82. 65 mm 2 30. 09 mm 2
Early Intel multi-core 2006 -07 C C C 4 M L 2 2 Pentium 4 die in one package – Pentium D dual-core processor, Xeon 50 xx, 2005 C 4 M L 2 5000 P MCH 2 dual-core die in one package – quad-core processor C C 4 M L 2 5400 MCH MC CPU CPU Snoop Filter for 64 M 7300 MCH 4 S system, 1 processor per FSB Conroe, dual-core 4 M shared L 2 65 nm Penryn, DC 6 M L 2 45 nm Scale 10 mm = 1. 0 in Dunnington, 3 x DC, 3 M L 2 each, 16 M L 3 45 nm 2 -way with multi-core processors Too powerful for entry requirements But virtualization became popular Put multiple small VMs on one 2 -way
Hot chips 18, Core & Blackford chipset Big improvement in memory latency between E 7520 chipset for last Net. Burst and 5000 P chipset for first Core 2 processors HP zx 1 chipset for 2 -way Itanium 95 ns memory latency? Hot chips 18 Blackford: A Dual Processor Chipset for Servers and Workstations Inside Intel Core Microarchitecture LH: Lindenhurst, aka E 7520
Intel 2 & 4 -way Processor Strategy • Big L 2/L 3 cache for processors in 4 -way 1998 -2011 • when schedule allowed, some band-aid when not • mostly to improve scaling beyond 2 P, some gain at 1 P • high cost & (really high price), but worth it 0. 18µm Coppermine 256 K L 2 45 nm Penryn 6 M L 2 65 nm Cedar Mill 2 x 2 M L 2 0. 18µm Cascades 2 M L 2 System architecture support huge memory capacity Next slide: Nehalem 65 nm Tulsa 2 x 1 M L 2, 16 M L 3 Dunnington 3 x 3 M L 2, 16 M L 3 Scale 10 mm = 1. 0 in
Nehalem (& Westmere) 2009 -10+ • Quad-core for 2 -way, L 3 2 M/core QPI • Processor connects directly to memory 5520 IOH • 8 -core for 4 -way, also 8 S • • Scalable Memory Buffer - doubles capacity Adds cost to platform Higher memory latency L 3 3 M/core SMB SMB SMB SMB IOH Change in scaling Now 10 mm = 0. 71 in Prev. 10 mm = 1. 0 in IOH Nehalem-EX model connects to memory via Scalable Memory Buffer (SMB), (doubles) capacity, adds memory latency and cost Westmere 10 c EX / 6 c EP
Sandy Bridge 2012 strategy shift PCI-E QPI C L 3 Cache • Sandy Bridge (Xeon E 5) • 8 -cores for 2 and 4 sockets • Xeon E 5 2600 and 4600 series L 3 Cache MC MC PCI-E QPI C L 3 Cache MC MC • 4 memory channels • 2 memory controllers • 18/12 DIMM slots • No SMB expanders! • 40 PCI-E lanes high core count is now not just for 4 -way Succeeds Westmere-EP, also superset Scale 10 mm = 0. 71 in MC
Ivy Bridge, Haswell, Broadwell 2013 -16 Ivy Bridge (22 nm, 2013/14) 3 die options, 6, 10 and 15 cores PCI-E Haswell (22 nm, 2014/15) 8, 12 and 18 core options QPI C C C MC MC PCI-E QPI C C C C C MC MC C C PCI-E QPI C C C MC LCC MCC C C C Broadwell (14 nm, 2016) 10, 15 and 24 core options MC HCC Abandoned old small die for 2 -way, big die for 4 -way Scale 10 mm = 0. 71 in
Xeon E 5 v 1 -4 2012 -16 QPI PCI-E C C C QPI PCI-E C C C C C C C MC MC QPI PCI-E 2013 -16 Xeon E 5 v 2, 3 and 4 2600 series for 2 -way SMB SMB PCI-E C C C C MC MC PCI-E SMB SMB SMB C QPI PCI-E 4600 series for 4 -way note: 2 QPI links SMB SMB QPI Ivy Bridge Haswell Broadwell v 2 v 3 v 4
4 -way Xeon E 7 v 2 -4 2013 -16 C C C C C C C C C SMB C C C C SMB PCI-E MC MC QPI PCI-E MC QPI SMB SMB C C C C C C C C C C C C MC MC MC 2014 -16 Xeon E 7 v 2, 3 and 4 for 4 -way+ note: SMB memory expander MC SMB C SMB SMB C SMB QPI SMB PCI-E
Sky Lake – Xeon SP, 2017 MC MC Key L 3 cache + 2 nd AVX Caching and Home Agent Skylake core L 2 cache extension MC MC Skylake (14 nm) 3 die options, 10, 18 and 28 cores LCC, HCC, (both 2 UPI) XCC (3 UPI) Grid interconnect Products from 4 to 28 core and every increment of 2 cores Skylake desktop Key L 3 cache + 2 nd AVX Caching and home agent Skylake core L 2 cache extension Skylake 4+2 122 mm 2, Coffee lake 149. 6 mm 2 LCC 10 core 325 mm 2 22. 26 x 14. 62 mm HCC 18 core 485 mm 2, 22. 26 x 21. 56 mm XCC 28 core 694 mm 2 32. 18 x 21. 56 mm Full frame camera sensor 864 mm 2 36 x 24 mm https: //en. wikichip. org/wiki/intel/microarchitectures/skylake_(server) Scale 10 mm = 0. 71 in
Sky Lake XCC 28 -core https: //en. wikichip. org/wiki/intel/microarchitectures/skylake_(server) Scale 10 mm = 2. 0 in
Skylake - North Cap MC MC https: //en. wikichip. org/wiki/intel/microarchitectures/skylake_(server) Scale 10 mm = 1. 0 in
Skylake Caching and home agent https: //en. wikichip. org/wiki/intel/microarchitectures/skylake_(server) https: //fuse. wikichip. org/news/1017/isscc-2018 -intels-skylake-sp-mesh-and-floorplan/
Scaling Previous and current
Old: Scale Up versus Scale Out Scale up – bigger systems X Scaling up requires a lot of re-architecture work Scaling out requires a lot of re-architecture work Is there a pattern? Scale out – many systems, network connected In principle, 1 S is starting point, but no one bothers Oracle Exadata Database Machine 1 st gen: RAC 2 -CPU nodes, up to 2 nodes 2 nd gen: ditto or 2 nodes of 8 -way (Nehalem-EX)
Scale Up (die size), formerly multi-processor New Scaling Scenarios? MC MC MC MC MC MC MC MC MC MC MC New Scale Out (multi-socket/processors), formerly cluster nodes 4 -28 cores per processor, 1 S, 2 S or 4 systems, scale out is dead?
$/core Xeon SP – Price per core HW cost is mostly irrelevant 8180 28 c, 2. 5 GHz 8176 28 c, 2. 1 GHz $10, 009 $8, 719 8168 24 c, 2. 6 GHz 8160 24 c, 2. 1 GHz $5, 890 $4, 702 6148 20 c, 2. 4 GHz 6138 20 c, 2. 0 GHz 6139 18 c, 2. 3 GHz $3, 072 $2, 612 $2, 445 6130 16 c, 2. 1 GHz $1, 894 6132 14 c, 2. 6 GHz 5120 14 c, 2. 2 GHz $2, 111 $1, 555 6126 12 c, 2. 7 GHz 4116 12 c, 2. 1 GHz $1, 776 $1, 002 5115 10 c, 2. 4 GHz 4114 10 c, 2. 2 GHz $1, 221 _$694 41 xx 8 c 1. 7 -2. 1 $306 -501 cores two 14 -core processors less expensive than one 28 -core (also 2 x 22 c)
Multiprocessor – Tunnel Vision 2 -way standard baseline server MC MC MC 18 -22 cores have low $/core amortized for: Processors + motherboard + chassis + adapters Assume memory configuration fixed per-core AWS – 24 cores best? No 18 -c SKU actually uses HCC die? 2 x 10 -cores or less good for dedicated host at medium workloads
A very long story less long • Once a valid reason for multi-processor CPU • The 2 -way system was cheap, 4 -way for databases • Then 2 -way evolved into a real server • Multi-Core / integrated memory controller • 2 -way multi-core too powerful for low-end • but virtualization created new justification • for 2 -way as baseline standard system • 2012/13, Intel adjusts big-die 4 S, little-die 2 S • Big memory 4 S, standard memory 2 S • 3 die options (LCC, MCC, HCC), 4 to many cores, • 2016, Intel skips SMB memory expander on 4 S CPU MCH PXB SB
What is important for database transactions? What does DB engine code do? Need a slide for locks?
Index Seek System tables 1. Navigate system tables, IAM Find locator for index root 2. Read index root page Find locator for next level 3. Read index intermediate level. Find locator for leaf level … 4. Read leaf level page In other words: access memory address, which points to next address i. e. : Pointer chasing http: //buildingbettersoftware. blogspot. com/2016/07/what-about-indexing-sql-server-tables. html
Find Row within a Page Read header Read row offset at end of page to determine individual row locations Then read row Page header is 96 bytes, processor cache line size - 64 bytes (since P 4) some Itanium L 2 – 128 line Should SQL Server force 2 cache lines for each row offset access? (depending on offset, average row size? and which columns are accessed? ) Put first 32 -bytes of offset slot array after page header? Index rebuild with 64 -byte row align option? http: //forsharingknowledge. blogspot. com
Page header 96 bytes 8 KB page – 8192 bytes - 96 bytes page header = 8096 bytes Max row size = 8060 bytes Body – row data Row offsets slot array
Accessing columns within a row Fixed len Variable len Read row header, size, sys. columns for column info Fixed length (not null) data locations are known Get Null bitmap, column offset array to locate individual variable length columns https: //aboutsqlserver. com/2013/10/15/sql-server-storage-engine-data-pages-and-data-rows/ , Dmitri Korotkevitch Need a slide for locks?
Locks spid dbid Obj. Id Ind. Id Type Resource Mode Status Anyone have a good diagram for locks? External Protocols Named Pipes TCP/IP Shared Memory Tables – Indexes Database Engine Triggers T-SQL Stored Proc Storage Engine Transaction Services File Manager Utilities Bulk Load DBCC Backup/Restore Virtual Interface SQL CLR Query Processor Buffer Manager Parser Lock Manager Optimizer SQL Manager Access Methods: Rows, Indexes Versions, Pages Allocations Database Manager Query Executor SQL OS API Lock Manager Memory Manager Synchronization Services Thread Scheduler Worker Threads Deadlock Monitor Resource Monitor Lazy Writer Scheduler Monitor Based on diagram from EMC SQL Server whitepaper I/O Manager Buffer Pool External Components (Hosting API) CLR MDAC
CPU Clock, L 3, Memory Latency CPU clock cycle @2. 5 GHz = 0. 4 ns L 2 L 3 Skylake SP: 1 M L 2, 14 cycles, Single processor memory latency 76 ns, 2 -Socket 50/50 local/remote access, 2. 5 GHz 12 cycles 18 ns 45 cycles L 3 19. 5 ns? 190 cycles average latency 115 ns = 287. 5 cycles Multi-processor local node memory latency 90 ns, 225 cycles Multi-processor 1 -hop remote node memory latency 140 ns, 350 cycles 2. 5 GHz
Some basic calculations Based on a very simple model
This really happened 2 Xeon E 5 -2680 processors 8 -cores each, HT enabled 16 cores, 32 threads total 2. 7 GHz base frequency (3. 3 Turbo? ) 75 transactions per sec per thread BIOS/UEFI Update performance tanks WTF!@#$%& - it’s not my fault? Frequency set to 135 MHz (1/20 th of 2. 7 GHz) ? ? What is performance? When frequency drops from 2. 7 GHz to 135 MHz? No, I was not smoking bad weed No, I (probably) was not drinking
Frequency 135 MHz vs 2700 MHz 100 instructions, 95 single cycle, 5 memory round-trips average memory latency 114 ns 2. 7 GHz – 2. 7 instructions per ns 35 + 570 = 605 ns 95 / 2. 7 5 * 114 ns core utilization = 100/(2. 7*605) = 6. 1% 135 MHz – 1 instruction in 7. 4 ns 704 + 570 = 1274 ns core util. = 100/(. 135*1274) = 58% 95*7. 4 Performance/thread ratio = 1274/605 = 2. 1 X (prelim) w/HT enabled, perf @ 2. 7 GHz doubles, perf @ 135 MHz ~ 50% higher? Told you I (probably) was not drinking
Tx/sec Estimated Frequency Scaling GHz Most frequency scaling performance gains achieved up to 1 GHz, Another 13. 6% in 1 S from 1. 0 – 2. 5 GHz, only 10. 5% in 2 S, Less than 5% from 2. 5 GHz – 5. 0 GHz Frequency scaling better in 1 S (76 ns) than in 2 S (114 ns avg. mem. latency)
Hard Evidence - Summary • Performance from 135 MHz - 2. 7 GHz (20 X) • 3 X? • Hyper-Threading scaling almost linear (@ 2 GHz+) • 2 logical processors on each core • -> memory latency effect DW/column store – poor scaling w/HT • Performance per thread 2 S versus 4 S • 2 -way – one local, one remote node • 4 -way – one local, three remote nodes Requesting core SQL Server 2012(? ) – parallel execution plans stay within a soft-NUMA node MC 89 ns Local node MC MC MC 1 Hop Remote node 139 ns
Conclusions • Memory latency is important • Can we buy low latency memory? • App + DB not optimized for NUMA either? • 1 S – all memory local • 2 S – 50/50 local-remote • Local node memory latency longer than 1 S • 4 S – 25/75 local-remote (+ SMB in older systems) Application and DB must be architected together using affinity settings in SQL Server to achieve memory locality Initial data load into memory must be via NUMA elements of app server App server must know NUMA partitioning for key value ranges Huge effort to retrofit - F^ck, F^ck!
Rethinking the System & Sizing Strategy Post-2014/15
Memory Latency – Important! • Can we buy low latency memory? No – for servers • Specialty memory products – Corsair, G. Skill • Unbuffered, no ECC! DOMINATOR PLATINUM Special Edition CONTRAST 32 GB (2 x 16 GB) DDR 4 3466 MT/s (PC 4 -27700) C 16 Desktop Memory 16 -18 -1836 At 3466 MT/s, clock rate 1733 MHz, cycle 0. 577 ns t. CAS 16 = 9. 23 ns, t. RCD, t. RP 18 = 10. 39 ns t. RAS 36 = 20. 77 ns Server ECC RDIMM/LRDIMM 2666 MT/s, 1333 MHz, cycle 0. 75 ns, 19 -19 -19 (or higher*) *LRDRIMM with=quad-stacked (128 GB) CAS t. CAS etc. 14. 25 ns, 8 Gb DRAMt. RC ~ 46 ns = 21? Cherry picked part + heatsink Micron datasheet says -075 E has 18 -18 -18 timing But no RDIMM product?
The 2 -Socket Standard Server Requesting core MC 89 ns MC MC Local node MC 1 Hop Remote node 46 ns latency at DRAM In 2 S system 43 ns outside DRAM to local node code 18 -19. 5 ns at L 3 46 + 93 ns to remote node core Value of low latency memory diminished by system level delays 139 ns
What else? How about 1 S vs. 2 S? Requesting core MC MC MC 76 ns 89 ns MC MC Local node 1 -way system All Memory Local 2 -way system Non-Uniform Memory Access 19. 5 ns to L 3 76 ns to local memory 89 ns to local memory 139 ns to remote memory 4 S now rare, 8 S almost gone? MC 1 Hop Remote node 139 ns
Scaling Expectations 1 S -> 2 S Requesting core MC 1. 57 X? MC 76 ns NUMA optimized: way, MC 89 ns Local node – 80% locality on 2 - 60% by design, 40% random split 20/20, net: 80% local, 20% remote 2 S average memory latency 99 ns MC MC MC 20% – 1 Hop Remote node 139 ns
sys. dm_os_memory_node_access_stats Troubleshooting Performance Problems in SQL Server 2008 Sunil Agarwal, Boris Baryshnikov, Keith Elmore, Juergen Thomas, Kun Cheng, Burzin Patel SELECT * FROM sys. dm_os_memory_node_access_stats Troubleshooting Performance Problems in SQL Server 2008: “is populated under dynamic trace flag 842 due to its performance impact. “ https: //blog. engineer-memo. com/2013/08/23/windows-azure-vm-で-numa-構成の-sql-server-を検証する/
Scaling Expectations 1 S -> 2 S 1. 57 X? 76 ns 89 ns Local node – 80% 1 Hop Remote node – 20% 139 ns NUMA optimized: 80% locality on 2 -way, 2 S Avg memory latency 99 ns Requesting core MC 1. 37 X? MC 76 ns MC 89 ns Local node – 50% MC MC MC 1 Hop Remote node – 50% Not optimized for NUMA 50/50 local – remote memory 2 S average memory latency: 114 ns Simple model 15% performance per core/thread difference, HP thinks (4 S? ) 30%? 139 ns
1 S vs. 2 S – Cores are not equal! MC MC 2 x 14 c MC ≠ MC MC MC 1 x 28 c Core are not equal between 1 S and 2 S. 2 x 20 c ~ 1 x 28 c? MC MC MC Cores in 1 S about 40% better than cores in 2 S for OLTP? MC
More Bad News • Does your DB have identity columns? • Or other sequentially increasing key? • Or indexes • Inserts and indexes on sequentially increasing key • Serious problem on NUMA systems • With high core count per socket • Identity key ~6000 rows / sec* • GUID key 180, 000 rows/sec* • 1 S – identity key • 4 c/8 t • 10 c/20 t ~70, 000 rows/sec ~40, 000 r/s *Thomas Grosher - Shaving off Microseconds https: //www. sqlsaturday. com/797/Sessions/Details. aspx? sid=83624
1 S and NUMA 1 S system DB + App does not require NUMA optimization? Not yet, but NUMA on-die already here Future processors may have greater NUMA asymmetry? https: //en. wikichip. org/wiki/intel/microarchitectures/skylake_(server)
MC MC
SQL Server on VMware uses their own terminology, read their document carefully, verify it is what you think it means? Recall: 2 S, local node memory latency is higher than 1 S memory access Architecting Microsoft SQL Server on VMware v. Sphere
Storage • Forget All-Flash Array IOPS • AFA can do 1 M+ IOPS • Keep ms/read low at max. SQL Server throughput • • Including checkpoints 1 PCI-E NVMe x 4 SSD per 2. 0 -2. 5 core? 1 ms / Rd? 0. 1 ms / Rd? • Database – File Group – File – Path – Physical Dev • Distribution still important
Network • 10/25/40/100 Gbps preferred • SFP/QSFP has lower latency than Base T/optical? • Parallel network • Backup / Transfers on separate network? • If on less than 40 Gbps? Or Qo. S?
Server Sizing Summary & cheap • Multi-processor – was once important/necessary • Now a liability, just say no to MP? • Almost all App+DB servers not optimized for NUMA • Single processor – no kidding! • Up to 28 cores in one socket • High cost per core of big CPUs not an issue MC • SQL Server licensing costs is driver • Single socket – core level performance is better • Need fewer cores, fewer NUMA surprises • 6/12 DIMM slots sufficient w/32 & 64 GB • All-Flash storage, 100 K+ IOPS ok (400 K? ) Your Microsoft account rep has quotas to fill MC 76 ns
Submit by 5 pm Friday, November 16 th to win prizes. 3 Ways to Access: Session evaluations Your feedback is important and valuable. Go to pass. Summit. com Download the Guide. Book App and search: PASS Summit 2018 Follow the QR code link displayed on session signage throughout the conference venue and in the program guide
Thank You Joe Chang • jchang 6@yahoo. com • jchang 61@outlook. com
DRAM DDR 4, 8 Gbit Row MUX Row Addr mux Sense amp array 8 Gbit (2 Gb x 4) 2 Gb addresses – 31 bits 16 banks (24), 512 Mbit per bank Addr bus Address Register Bank Control Column Address I/O gating read data latch data Row address decoder - 131, 072 control Row Address Latch & decoder ctrl Samsung’s 20 nm DDR 4 DRAM 8 Gb DDR 4 DRAM chip 5. 8 mm x 9. 7 mm large die Column decoder 131, 072 rows (217), 128 x 8 columns (210) Making a new DRAM chip is very costly easier to just kill the upper half of the bit-array farthest from sense amp? https: //www. semiwiki. com/forum/f 297/techinsights-samsung-20 -nm-ddr 4 -tsv-enabled-dram-5783. html Sense amp array I/O gating Column address decoder (1024 x 4)
sys. dm_os_buffer_descriptors SYSCONFIG_PAGE server config block BOOT_PAGE database wide info page BULK_OPERATION_PAGE see sys. dm_tran_locks DIFF_MAP_PAGE differential bitmap for a GAM interval. FILEHEADER_PAGEfirst page of every file GAM_PAGE - a GAM allocation map IAM_PAGE - an index allocation map ML_MAP_PAGE minimally-logged extent map for a GAM interval SGAM_PAGE an SGAM allocation map PFS_PAGE - a free-space and allocation status page INDEX_PAGE - an index (B-tree) page in the tree of clustered or non-clustered index, or the leaf of a non-clustered index sys. dm_os_buffer_descriptors DATA_PAGE a data page in a heap or a clustered index FILEHEADER_PAGE TEXT_TREE_PAGE a non-shared text page BOOT_PAGE TEXT_MIX_PAGE a text page shared between various text structures GAM_PAGE, SGAM_PAGE, IAM_PAGE SORT_PAGE - a page used in internal sorts. PFS_PAGE WF_PAGE - a work file page. SORT_PAGE , WF_PAGE UNLINKED_REORG_PAGE DIFF_MAP_PAGE TEXT_TREE_PAGE, TEXT_MIX_PAGE UNLINKED_REORG_PAGE INDEX_PAGE DATA_PAGE
SQL Server NUMA options • TCP port Affinity assignment • Method used on TPC-C and TPC-E benchmarks • Resource Governor – CPU/NUMA node affinity • CREATE (EXTERNAL) RESOURCE POOL • ALTER RESOURCE GOVERNOR – classifier function
Optimizing for NUMA - OLTP • TPC-C example • Main tables have common grouping key • Warehouse ID • App server uses specific TCP port # based on key • SQL Server affinitizes by port# • TPC-E example • Table for blocks of trade ID values • Each SPID gets its own block of 100000 • (SPID mod tot threads) • Ditto on TCP port #, can use Resource Governor?
Optimizing for NUMA - DW • PDW strategy would be great if … • Fact tables partitioned across nodes • Dim tables replicated • NUMA strategy – • if MS brought PDW features into SQL Server • Fact tables partitioned across NUMA nodes • Small Dim tables replicated? • Dim tables distributed?
OLTP NUMA - desired • Group of tables have common lead key • Index – hash • clustering by hash, • Hash values determine NUMA node memory aff. • App server knows stored proc parameter value • based on hash, apply connection string value (App? ) • Resource Governor – affinity by connstr •
Scale up (die size), formerly multi-processor Scaling – NUMA Optimized MC MC MC MC MC MC MC MC MC MC Scale out (multi-socket/processors), formerly cluster nodes
Scale up (die size), formerly multi-processor Scaling – Not NUMA Optimized MC MC MC MC MC Scale out (multi-socket/processors), formerly cluster nodes
Optimized for NUMA MC MC 76 ns Requesting core MC 89 ns MC Local node – 80% MC MC 139 ns 1 Hop Remote node – 20% Local node – 70% MC MC remote node – 10% MC MC MC App server and Database server 1. App server knows to use a specific connection parameter (port number etc. ) for each category of some key value 2. Database server affinitizes that parameter to a specific core 3. Each thread has it own block of ID values TPC-E, 80% locality on 2 -way, 60% by design, 40% random split 20/20, 80% net Implies -> 4 -way 40% split 10/10/10/10 Net 70%
Not Optimized for NUMA MC MC Whatever thread first accesses data page, SQL Server loads into thread’s local memory node 76 ns Requesting core MC 89 ns Any other thread could access same data MC Local node – 50% MC MC 139 ns 1 Hop Remote node – 50% Local node – 25% MC MC Random memory node access 2 -way, 50/50 local-remote Average memory latency 114 ns remote node – 25% MC MC MC 4 -way 25/75 local-remote node Avg. memory latency 126. 5 ns Single socket All memory local Avg. latency: 76 ns?
Skylake (Xeon SP) - Intel source http: //www. tomshardware. com/news/amd-intel-epyc-xeon-benchmarks, 35993. html
Xeon SP versus AMD EPYC MC 89 ns MC MC Local node MC 1 Hop Remote node Requesting Die 0 Local 0 1 89 ns 7 140 2 138 1 Hop Remote Die 3 138 6 238 5 243 Memory Requesting core 139 1 Hop Remote Socket 201 4 243 2 Hop Remote Socket
https: //software. intel. com/sites/default/files/m/4/7/e/15507330 -Intel-Nehalem-Core-Architecture-82 -page. pdf https: //www. slideshare. net/Intel. Software. BR/numa-i-step 2014 Leonardo Borges
Memory Latency 2010? https: //software. intel. com/sites/default/files/m/4/7/e/15507330 -Intel-Nehalem-Core-Architecture-82 -page. pdf
DDR SDRAM DDR 4 -2666 19 -19 -19 - 40? 2666 MT/s data transfer rate 1333 MHz address/command = 0. 75 ns 1 st 19 t. CAS or just CL = 19 x 0. 75 = 14. 25 2 nd 19 t. RCD also = 14. 25 3 rd 19 t. RP also = 14. 25
The Modern Processor Core L 3 Execution Engine L 3 tag? Memory Subsystem Execution Units Front End ROB BPU Scheduler µOP Alloc. Q L 3 L 1 D L 1 I I Fetch I Queue Ring Interconnect L 2 Load Store Decode L 3 tag? Micro-op cache 1. 5 K ops decoded L 1 Instruction & Data cache - inside core, 32 K L 1 I Front-end 32 K L 1 D Mem. Subsys. L 2 Cache 256 KB in desktop, Xeon E 3 1 MB in Xeon SP L 3 – outside of core (Xeon SP*) (shared) https: //www. primeline-solutions. de/files/intel-xeon-scalable-architecture-deep-dive_1. pdf * https: //software. intel. com/en-us/articles/intel-xeon-processor-scalable-family-technical-overview
Tables Unique keys Foreign keys NUMA? SQL API Server Cursors: open, prepare, execute, close? DOP Memory Parallel plans Indexes partitioning Query Optimizer Execution Plan Statistics Tables and SQL combined implement business logic Compile Natural keys with unique indexes, not SQL Sample accuracy Parameter values Compatibility level differences? Recompile temp table / table variable Rows per thread OS LPIM, Large Pages Soft NUMA TCP port mapping Index & Stats Maintenance Actual Plan Storage Engine Row estimate propagation error Hardware SET NO COUNT Information messages NUMA Index and Statistics maintenance policy 1 Logic may need more than one execution plan? Compile cost versus execution cost? Plan cache bloat? The Execution Plan links all the elements of performance Index tuning alone has limited value Over indexing can cause problems as well
Intel 3 D XPoint/Optane vs NAND http: //www. tomshardware. com/reviews/intel-optane-ssd-900 p-3 d-xpoint, 5292 -2. html
Camera Sensor Sizes 1 in 12. 8 x 9. 6 123 mm 2 Four-thirds 17. 3 x 13 225 mm 2 APS-C 23. 6 x 15. 7 370 mm 2 APS-H 28. 7 x 19 545 mm 2 Full Frame 36 x 24 864 mm 2 Scale 10 mm to 1 in APS-C 23. 6 x 15. 7 370 mm 2 APS-H 28. 7 x 19 545 mm 2 Full Frame 36 x 24 864 mm 2 Scale 1 in to 1 in Four-thirds 17. 3 x 13 225 mm 2 1 in 12. 8 x 9. 6 123 mm 2