Is Performance Still Important Joe Chang qdpma com

")

 • Could be on its own server •")
 infinitely powerful CPUs • Don’t need good")





 Scaling Expectations 350 300 1. 51 X 250 200 1. 54 X 150")


 2 • Inserts distributed across all pages • All pages active")






 on NUMA (multisocket) is possible, •")






 L 2 L 2 CPU CPU IO Hub Memory Controller")



 CPU CPU memory controller IO Hub Memory access latency Local node")


")





 • One physical core supports simultaneous threads")

 practices DDR 4 DDR4 DDR 4 C DDR 4 C DDR")








 v")









 • Long ago, several SQL Server experts reported • a clustered")



 • Memory management strategy •")



? • Contention issues? High concurrency, NUMA")







- Slides: 83
Is Performance Still Important Joe Chang qdpma. com
About Joe SQL Server consultant since 1999 Query Optimizer execution plan cost formulas (2002) True cost structure of SQL plan operations (2003? ) Database with distribution statistics only, no data 2004 Decoding statblob/stats_stream • writing your own statistics • Disk IO cost structure • Tools for system monitoring, execution plan analysis • • • See http: //www. qdpma. com/ Exec. Stats download: http: //www. qdpma. com/Exec. Stats. Zip. html Blog: http: //sqlblog. com/blogs/joe_chang/default. aspx
Performance - Short Version • Processors & Systems are powerful, • … but total compute is distributed over many cores • Round-trip memory latency • Software is sophisticated, but not intelligent • Full software stack has many layers • What happens underneath? • Database – Cost Based Optimizer, data distribution stats • Application and Database • Scaling up is difficult/challenging • Must be architected to details of underlying DB & HW • Rethink Scaling – up, out, down? 1 -socket
The Environment • Application (web, client) • Could be on its own server • Database • Tables, unique & foreign keys, procedures • Database Engine • Query optimizer, data distribution statistics Appl. Database RDBMS Operating System • Compute • Processors, memory, storage Server System
Ideal Compute ∞ ∞ • One-few (nearly) infinitely powerful CPUs • Don’t need good multi-threaded code • To manage very many cores • Actual CPUs are almost infinitely fast • To avoid dead cycles waiting for memory access • CPU clock 0. 3 -0. 5 ns, • Actual round trip to DRAM memory 70 ns local, 120 ns remote ∞ Memory • Single-cycle round-trip memory access
The Processor PCI-E Mem Controller • Xeon E 5/7 v 4 • up to 24 cores • Broadwell • 256 K L 2, 2. 5 M L 3 • Xeon SP • up to 28 cores • Skylake • 1 M L 2, 1. 37 M L 3
Processors 2 • AMD EPYC • • 32 -core MCM 8–core die 512 K L 2 2 M L 3 • IBM POWER 9 • 12 core SMT 8 • Power. VM • 24 core SMT 4 • Linux
56 cores in 2 – socket system 112 cores in 4 – socket 2 X logical processors with HT IBM POWER SMT 4 -8 Memory • • Memory • 1, 2 or 4 processor (sockets) Memory System 6 memory channels • Memory • Bandwidth is scaling • 100 MHz in 1998 • 2666 MT/s today • Round trip latency is stalled • 45 -50 ns at DRAM interface • Non-uniform memory access (NUMA) 48 PCI-e lanes
Memory Node 0 • CPU clock is 0. 5 – 0. 3 ns, Socket 0 QPI Socket 1 Memory Node 1 Memory • Round-trip local node memory latency is 70 ns (140+ cycles) • Remote node memory latency – 120 ns? (280+ cycles) • High memory bandwidth • 8 byte wide x 2666 MT/s = 21 GB/s channel • 4 -6 channels per socket • Memory access is non-uniform • in multi-socket system • Implications • Transaction processing constrained by memory latency • Hyper-Threading (aka SMT) is work around • Column-store works great B-tree index One memory value points to next location
Scaling 1 to 2 to 4 sockets • Generic database design, • no strategy for achieving memory locality on NUMA Memory Node 0 • 1 -Socket • All memory accesses to local node SMB SMB Memory Node 0 SMB Memory Node 2 SMB Socket 2 Memory Node 1 QPI SMB SMB • For greater memory capacity Socket 3 QPI Socket 1 SMB • 25% local, 75% remote • Xeon E 7, SMB Socket 0 SMB SMB • 4 -Socket Memory Node 3 • 50% local, 50% remote Memory Node 1 • 2 -Socket
(Simple) Scaling Expectations 350 300 1. 51 X 250 200 1. 54 X 150 100 50 0 1 -S 2 -S 4 -S Hypothetical transaction, 3 M real CPU-operations (not no-µops), 3% incur round-trip memory, latency 70 ns local, 125 ns remote node, 2 GHz – 667 tx/s for single cycle memory • 1 -socket, all memory local • 2 -socket, 50/50 local/remote mem 1 -S 3 GHz, 137 tx/s, • 4 -socket, 25/75 local/remote (90/145) 6. 7% increase over 2 GHz
Software / Database
Database – Index Key 1 • Identity or other sequential key • Inserts go to end of table • Low disk IO, • active rows concentrated into few pages • Worked fine on old 4 -way CPU • Uniform memory architecture • 12, 000(? ) single row insert tx/s CPU Memory MCH Memory • Multi-core multi-socket NUMA • Concurrent inserts from many cores and different sockets • 1, 500 single row inserts/sec on 4 -way, • 70 K/s on single socket 4 -core, 40 K/s on 1 S-10 c Memory CPU Memory • Does not work well on modern 4 -way CPU B-tree index image from: http: //buildingbettersoftware. blogspot. com/2016/07/what-about-indexing-sql-server-tables. html
Unique Identifier (GUID) 2 • Inserts distributed across all pages • All pages active • Poor buffer cache hit ratio • High disk IO CPU CPU • Works OK on old 4 -way Memory MCH Memory • Uniform memory architecture • Memory typically 8 -64 GB • Storage array: 100 -1000 HDDs • Works reasonably well on modern • Multi-core multi-socket NUMA • Multi-TB memory, All Flash Storage • 95 K/s single row insert tx on 4 S
• Lead column – some kind of grouping Memory • Option 3: Compound key Memory • 1) One hot spot, 2) everything warm Memory • Option 1, 2 or Memory Best for Modern Systems? • TPC-C Warehouse and District • Even better, application uses lead key value to set connection, with affinity to specific node • Option 4: Block ranges • Each thread/spid gets a block of values (TPC-E benchmark) • What does your database use?
Imaginary Database Engine Tables Unique keys Foreign keys Query Optimizer Architect/Design Database Tables, unique keys, foreign keys Business logic – SQL Indexes Execution Plan Query Optimizer produces a good execution plan Storage Engine executes the plan SQL Indexes partitioning Hardware imaginary All in perfect harmony with server system architecture
Real Database Engine Tables Unique keys Foreign keys SQL Indexes partitioning Query Optimizer Execution Plan Storage Engine Hardware NUMA Statistics Sample accuracy Compile Parameter values Recompile temp table / table variable Database automatically generates statistics on indexes and columns Procedures are compiled with initial parameter values Variables treated as unknown Temp tables subjects to auto-stats Table variables assume 1 row unless OPTION (RECOMPILE) Statistics automatically updates per set point rules
Database & Application Server • Database engines are highly robust • Very heavy use of standard (sized) pages (8 KB – SQL Server) for as many operations as possible • Pages and Virtual Address Space (VAS) easily recycled • But some things make direct OS VAS allocations • CLR, network packet size > 8060 bytes, Spatial functions • Then database engine may need to be periodically recycled, just like application servers
Rethinking the Server System
Rethinking 2 -way “best practice” UPI disabled 2 x Xeon Gold 6132 2. 6 GHz, 14 cores per die, HT Base system Processor Base + 2 CPU 6132 14 c, 2. 6 GHz $2, 111 5120 14 c, 2. 2 GHz $1, 555 6126 12 c, 2. 7 GHz $1, 776 4116 12 c, 2. 1 GHz $1, 002 5115 10 c, 2. 4 GHz $1, 221 4114 10 c, 2. 2 GHz _$694 $1, 900 $2, 115 ea. $6, 128 8180 8176 8168 8160 6148 6138 28 c, 2. 5 GHz $10, 009 28 c, 2. 1 GHz $8, 719 24 c, 2. 6 GHz $5, 890 24 c, 2. 1 GHz $4, 702 20 c, 2. 4 GHz $3, 072 20 c, 2. 0 GHz $2, 612 1 x Xeon Platinum 8180 2. 5 GHz, 28 cores, HT Processor Base + 1 CPU $10, 876 ea. $12, 756 1 x Xeon Gold 6148 2. 4 GHz, 20 cores, HT Processor Base + 1 CPU $3, 096 $4, 963
General Advice • Scaling to 100 cores (processors) on NUMA (multisocket) is possible, • If both database and application server have been architected together to achieve memory locality, • If index keys do not result in excessive contention DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 • Use up to 28 cores if necessary • Hyper-Threading great for transaction processing • Memory capacity not an issue with All-Flash Storage DDR 4 • Otherwise, consider 1 -socket server
Summary - Short • Hardware is powerful App. • But is distributed over many cores • Parallelism – even distribution of work • Avoid contention • Many layers in full software stack • Database Engine is very sophisticated • But not intelligent • Employs specific methods • Which may or may not mesh with your database architecture and logic • Drag and Drop development tools Database RDBMS
Modern Performance • Processors & Servers today are incredibly powerful • But also complex – compute capability is distributed • weak point is roundtrip memory access • Great for code that streams memory • The full software stack is very deep & sophisticated • Rich feature set, but not intelligent • Database transaction processing • emphasizes round-trip memory access • BI etc. emphasizes streaming operations? • Web/App software – memory allocation & contention?
Hardware • History – how we got here from 1995 to 2017 • Non-Uniform Memory Access (NUMA) • Server Systems today • Integrated Memory Controller (AMD 2003/4) • Multi-core processors (2005? ) • All-Flash-Array (AFA), Solid-State Disk/Device (SSD) • Network – 10 Gb. E, 100 Gb. E, Infini-Band Intel Much has changed in hardware over 20+ years “Best Practices” from 1997 not entirely applicable today Need to rethink what is best for today
Early Symmetric Multi-Processor CPU CPU L 2 & bridge Memory Controller memory IO Hub Memory Controller 1993 -95, 4 -way SMP systems Intel 486 & Pentium Custom chip required to bridge Intel 80486/Pentium processors to proprietary bus for SMP support First generation had acceptable scaling for 486 processors, poor scaling with Pentium processors PCI CPU 4 -way base system ~$20 K? Acceptable for databases L 2 cache controller North Bridge South Bridge Multi-processor systems for application servers did not have much traction (my best recollection). 2 -way system had only slightly lower cost structure than 4 -way system?
Split Transaction Bus CPU CPU L 2 & bridge Memory Controller memory IO Hub Memory Controller Scaling was limited in first generation Pentium 4 -way systems 1 P – 4 P ~2. 2 X? Split Transaction bus: Address and data lines uncoupled PCI Software needed serious rework too
Intel Pentium Pro (1996) L 2 L 2 CPU CPU IO Hub Memory Controller L 2 CPU North Bridge Glue-less: bus supports multiple processors, does not require a bus adapter Memory access latency ~140 ns PCI memory 1996 Intel Pentium Processors 2 -way system has only slightly higher cost structure than single processor system. Wide adoption of dual-processor by default, (4 way for databases). AGP PCI Web/Application code showed some scaling from 1 P to 2 P, questionable beyond 2 P (mostly attributed to memory allocation? )
Non-Uniform Memory Access NUMA CPU CPU CPU Memory Controller CPU CPU Access to memory is nonuniform. Memory Controller Memory could be local to a processor node, or on a remote node Cross-bar Memory Controller CPU CPU Memory Controller CPU 4 -way is great, but … I want Big Iron! CPU CPU What’s the big deal? Software was not designed for non-uniform memory Scaling is possible However, certain operations exhibit negative scaling, sometimes severely so. Important: Identify bad operations, then code around it. Unfortunately, this very little detail was not explained upfront?
Key Lessons from 1996 -2002 • 4 -way probably best general choice for databases • Scaling on NUMA is possible but requires deep skills • 8 -way Pro. Fusion in 1999 was a point product • 2 -way de facto choice for application servers • Very little cost (or volume) increment over 1 P • Almost always some benefit from 2 P over 1 P • at minimum cost increment • 4 -way usually did not have price-performance benefit • Scaling to 4 -way may be poor – memory allocation I am not a proponent of “Best Practices. ” Too many people are great collectors of best practices, while paying no attention to the underlying reason for a specific best practice, whether it is applicable in the current circumstance, or has since become obsolete. Best practices does not absolve the practitioner from responsibility for poor decisions.
8 -way Pro. Fusion L 2 L 2 CPU CPU Cache Coherency Filter MAC PB DIB PB PB PCI
AMD Opteron (2003) CPU CPU memory controller IO Hub Memory access latency Local node ~60 -70 ns Remote node ~100 ns? Memory controller integrated into CPU die Hyper-Transport – point to point protocol between processors and IO Hub Multi-processor system inherently has non-uniform memory access but absolute memory latency is low Remote node latency is comparable to memory on north bridge AMD emphasized memory bandwidth scaling with nodes. Excellent performance in applications sensitive to memory latency (OLTP). (Bad) NUMA characteristics were muted? was not important, needed 2 P for app, 4 P for database
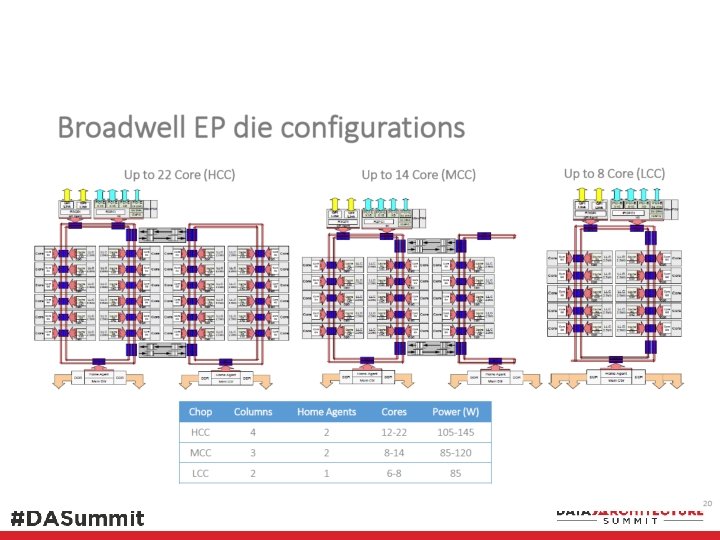
Multi-core Processors 2006 -2016 2006 Conroe dual-core 65 nm 2008 Dunnington 6 -core, 16 M L 3 45 nm 2010 Nehalem-EX 8 -core 45 nm up to L 3 3 M/c 2011 Westmere-EX 10 -core 32 nm, 3 M/c Xeon Phi x 200*, 72 -core, 14 nm 2014 Ivy Bridge 15 -core 22 nm 2012 Sandy Bridge 8 -core 32 nm 2. 5 M/c Skylake SP, 28 -core, 14 nm PCI-E 2015 Haswell 18 -core 22 nm PCI-E Mem Controller 2016 Broadwell 24 -core 14 nm
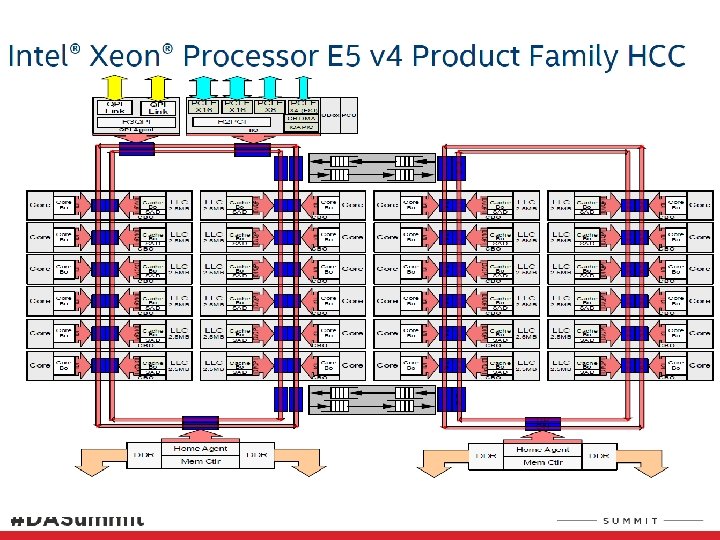
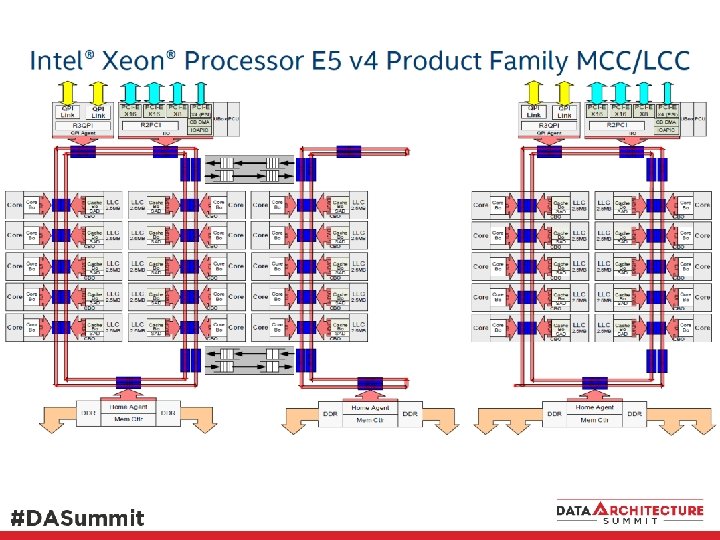
2016 Processors, Xeon E 5/7 v 4 mem Gfx LLC C C PCI-E PCI-E Agent C C Mem Controller Xeon E 3 v 5/6 Skylake / Kaby Lake 4 cores 64 GB max memory latency 42 cycles + 51 ns? PCI-E LCC 10 cores MCC 15 cores Xeon E 5/E 7 v 4, Broadwell Each recent generation processor core is roughly 20 -40 X more powerful than Pentium II 400 MHz 1000 X at socket level? PCI-E HCC 24 cores (E 5 v 4, 22 -cores)
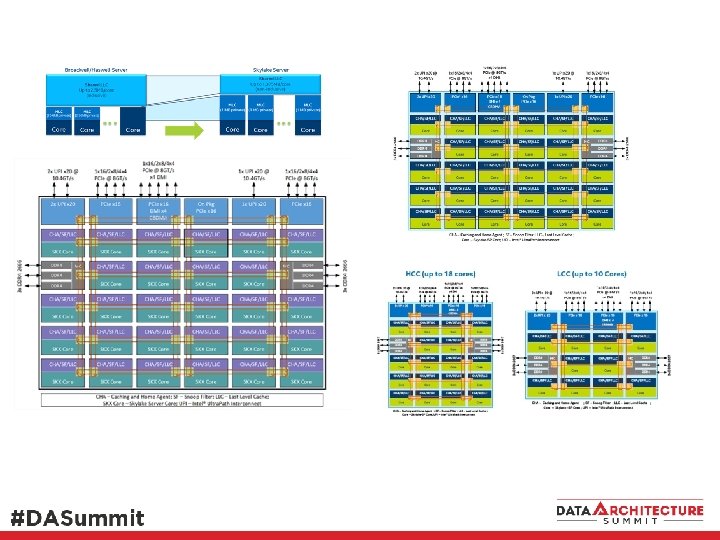
Memory 2017 Intel Xeon SP HCC 24 cores (E 5 v 4, 28 -cores) MCC 18 cores Memory LCC 10 cores
System Architecture Options 2016 SMB SMB Memory Node 0 SMB Socket 2 Memory Node 2 QPI Socket 1 SMB SMB Socket 3 QPI Socket 2 SMB Xeon E 7 Socket 0 QPI Memory Node 1 Socket 1 Memory Node 3 QPI Socket 1 SMB SMB Socket 0 Memory Node 1 Memory Node 0 2 Sockets, Xeon E 5 v 4 Memory Node 3 Xeon E 5 v 4600 Socket 0 Memory Node 2 Socket 0 4 Sockets Memory Node 1 Memory Node 0 1 Socket desktop/E 3 SMB
System Architecture Options 2016 DDR 4 DDR 4 DDR 4 Agent QPI DDR 4 PCI-E x 8 DDR 4 DDR 4 DDR 4 PCH DDR 4 C DDR 4 LLC DDR 4 Gfx C DDR 4 C Xeon E 5 v 4 DDR 4 mem 2 Sockets DDR 4 Xeon E 3 v 5/6, 4 cores
DDR DDR DDR DDR DDR DDR DDR SMB SMB DDR DDR SMB DDR DDR DDR DDR DDR DDR DDR DDR DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR 4 DDR DDR SMB DDR 4 DDR SMB DDR DDR DDR DDR DDR SMB DDR 4 SMB DDR 4 All 3 remote sockets are 1 -hop away 2 X memory capacity, but … SMB adds latency! 2 remote sockets are 1 -hop away 3 rd is 2 -hops away SMB DDR 4 QPI Xeon E 7 v 4 or E 5 Xeon E 5 4600 v 4 SMB DDR 4 4 Socket Xeon E 5 and E 7
Memory 32 GB DDR 4 -2400 RDIMM 2400 Million Transfers per sec 64 bits (8 bytes) data + 8 bit ECC 2400 MT/s x 8 Bytes = 19. 2 GB/s CL 17 or 17/17/17 2400 MT/s is data rate Address rate (clock) is 1200 MHz Clock = 0. 833 ns RP – row precharge RCD – row activate CL – column ad 17 clocks or 14. 16 ns 42. 5 ns for random access Note on binary and decimal 1 MB typically means 1024 x 1024 = 1, 048, 576 1 MB/s means 1, 000 bytes/sec Write rate is also 1200 MHz
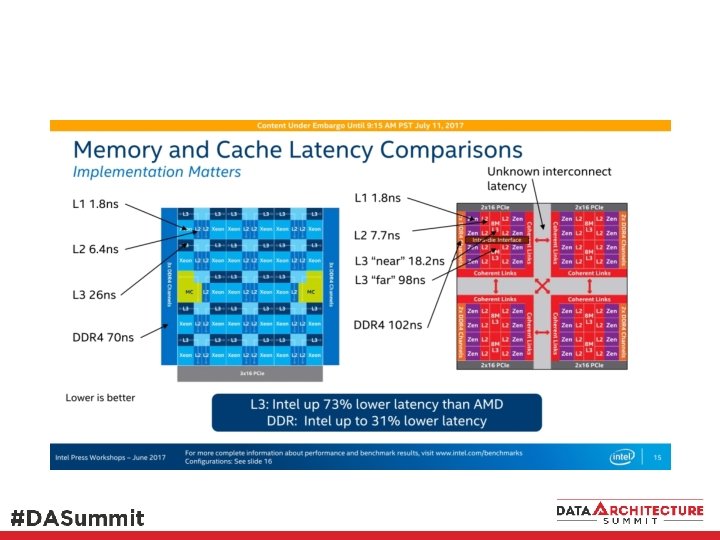
Hardware 1998 versus 2016 1998 Pentium II Xeon 400 MHz 4 processor sockets/cores 2016 Xeon E 5/E 7 Broadwell core 2. 2 GHz base, 3. 4 GHz turbo 4 -socket, 96 cores, 192 logical Memory bandwidth 800 MB/s limited by system bus, shared between 1 -4 processors Memory bandwidth 19. 2 GB/s per memory channel 4 channels, 76. 8 GB/s per socket Shared between 4 -24 cores Memory latency 60 -70 ns at DRAM 140 ns at processor Memory latency 42. 5 ns at DRAM Local node: L 3 + 65 ns at core (80 ns? ) Remote: 125 ns? Xeon E 7: Add 15 ns (? ) for memory expander 8 GB (32 x 256 MB) 6 TB (96 x 64 GB)
SMT/HT • Generic term: Simultaneous Multi-Threading (SMT) • One physical core supports simultaneous threads • Intel term: Hyper-Threading • All main line Intel processors are 2 logical per physical • Other processors • IBM POWER 7 4 threads per core, POWER 8 – 8 threads • SPARC 8 threads per core 1 st generation Intel Pentium 4/Xeon (MP) HT implementation was problematic 2 nd generation HT in Nehalem and later is good – or software has become better?
Performance Expectations • Immense Compute – cores + logical procs • Massive memory 6 TB (96 x 64 GB DIMMs) • Million+ IOPS with AFA/SSD storage Questions • Distribute work uniformly over very many cores? • Emphasize streaming memory? • i. e. Analysis, BI, column-store • Workload heavy on round-trip memory latency? • pointer chasing code
Rethinking “best” (good) practices DDR 4 DDR4 DDR 4 C DDR 4 C DDR 4 DDR4 DDR 4 DDR 4 DDR 4 C QPI DDR 4 C DDR 4 C DDR 4 C DDR 4 Suppose I need about 20 cores C C C C C C 2 x Xeon E 5 -2630 v 4 2. 2 GHz, 10 cores per die, HT 12 DIMMs/socket 80 PCI-E lanes 1 x Xeon E 5 -2698 v 4 2. 2 GHz, 20 cores, HT 12 DIMMs 40 PCI-E lanes CPU: ____ $667 ea. Motherboard $500 CPU: ___ $3226 Motherboard $300 2 socket Xeon 10 -core system base cost is about $1700 less than 1 socket 20 -core, But is this all?
VM & some other apps DDR 4 DDR4 DDR 4 C DDR 4 C DDR 4 DDR4 DDR 4 DDR 4 DDR 4 C QPI DDR 4 C DDR 4 C DDR 4 C DDR 4 Suppose workload is virtual, consisting of 1, 2 and 4 CPU VMs C C C C C C VM might use local node memory (check with your VM expert) 2 socket Xeon 10 -core system could be the more cost effective system
OLTP: TPC-C & TPC-E Benchmarks DDR 4 DDR4 DDR 4 C DDR 4 C DDR 4 DDR4 DDR 4 DDR 4 DDR 4 C QPI DDR 4 C DDR 4 C DDR 4 C DDR 4 TPC-C and TPC-E benchmarks (sort-of*) shows good scaling 2 -> 4 P (sockets) C C C C C C Oh yeah, TPC-C and TPC-E employ NUMA optimizations in both the Application and Database architecture. Was your OLTP environment architected for NUMA? both application and database? * TPC-E results only published for 2, 4 and 8 -sockets, no recent TPC-C results
DDR 4 DDR4 DDR 4 DDR 4 C C DDR 4 DDR 4 C C DDR 4 C QPI DDR 4 C C DDR 4 How did I arrive at this? 2 socket Xeon E 5 -2680 (v 1) Sandy-Bridge 2. 7 GHz, 8 cores per die, HT enabled 16 cores total, 32 logical processors Performance: 50 transactions/sec per thread 1, 600 tps over 32 threads 20 CPU-ms per tx BIOS/UEFI update: 135 MHz 16. 67 tps per thread 60 CPU-ms per tx 3 X reduction in performance? ? ?
Amdahl’s Law Revisited Originally for vector processing, but applies to any situation involving partial scaling of the total workload This case: Frequency scaling from 135 MHz to 2, 700 MHz (20 X) Assume average round-trip memory latency is 100 ns (75 ns local node, 125 ns remote node, 50/50 split) Performance gain 3 X: implies 3. 052% of instructions incur a round-trip memory access 97% of instructions speed up by 20 X on frequency 3% have no speedup (round-trip memory) Simplified model, not considering L 2 and L 3 implications
More fun with numbers Core frequency 2. 7 GHz – 0. 37 ns per clock Round-trip memory 100 ns – 270 cycles 5. 86 M-cycles per tx (zero latency memory), 3. 052% require round-trip memory access of 270 cycles 5. 86 M x (0. 9695{cache} + 0. 0305 {memory} x 270) = 53. 94 M cycles Of 54 M cycles for each transaction, only 5. 86 M are work-related 48. 14 M are no-op cycles waiting for memory, 89% dead-cycles So, how effective is Hyper-Threading?
Scaling 2 Socket to 4 Socket SMB SMB SMB DDR DDR DDR SMB DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR CPU per tx 30% than 2 S Scaling 2 S -> 4 S ~1. 5 X? DDR DDR DDR DDR SMB DDR DDR SMB SMB DDR Xeon E 7 -8837 (v 1), 8 -core, 2. 66 GHz, HT disabled, Westmere SMB DDR 4 Sockets SMB adds 15 -20 ns latency? 4 Sockets Xeon E 7 -8857 v 2, 12 core, 3. 0 GHz, no HT, Ivy Bridge
Round-trip Memory Latency • 3 main points • Frequency scaling: 135 to 2700 MHz (20 X) • – 3 X performance • Hyper-Threading shows “almost linear” scaling • Scaling 2 to 4 -socket, • CPU per tx increases 30%, • 23% reduction in performance per core • 2 S -> 4 S scaling is 1. 54 X • Implied 1 S -> 2 S scaling 1. 55 X?
DDR 4 DDR4 DDR 4 DDR 4 DDR 4 New Standard System for OLTP C C C C C C C Proposed: Single Socket, low latency to memory and does not need NUMA optimization C C C C C C C Xeon E 5 v 4: 768 GB max memory (12 x 64 GB) New Xeon whatever 6 memory channels 18 DIMM sockets – 1152 GB Between 3 D XPoint and/or Flash storage, Ridiculous high memory config not necessary Multi-socket plus NUMA optimization for special circumstances Can drive almost all workloads, even super giant enterprises, Possibly better than existing multi-socket system More so with memory-optimized tables and natively compiled procedures
Cloud and Managed Hosting • Azure L Series: Xeon E 5 -(2673? ) v 3 • Cores 4, 8, 16, 32. RAM 32/64/128/256 GB • 2 socket • Dv 3 Series: Xeon E 5 -2673 v 4, 20 core(? ) 2. 3 GHz? • 2, 4, 8, 16, 32, 64 cores • 2 socket system • M Series Xeon E 7 -8890 v 3 2. 5 GHz, 18 core • 64 and 128 core • 4 socket system,
Storage – Fiber Channel • Powerful storage today – 10 -16 GB/sec bandwidth • 8 or more x 4 PCI-E NVMe SSDs over 32 PCI-e lanes • SAN engineers confuse • Gbit/sec of FC with GBytes/sec requirement • Lots of infrastructure on 8 Gbit/sec FC – 2 links • 0. 75 -0. 80 GB/s per 8 Gbit/s link • Some 16 Gbit/sec, not much 32 Gb/s
Scaling - Hardware • Scaling over cores, single socket • Performance/Throughput @ 1, 2, 4, 8, 12, 16, 20, . . cores • Scaling over sockets • All cores, 1 -socket, 2 -sockets, 4 S as applicable • Scaling with Hyper-Threading (HT/SMT) • Using one logical processor on each core • 2 LP on each core • POWER and SPARC: 4, 6, 8 LP on each core • HT/SMT should probably be enabled • Identify apps that should use LP, and which should not
Software • Databases – OLTP • B-tree: round-trip memory accesses • In-memory, memory-optimized – hash indexes • Databases – DW, Analysis • Use Column-store if appropriate • App/Web servers • Others
RDBMS • Vendors goal: • Magical product • Organization build application strictly to requirements of their business logic • RDBMS auto-magically handles internal database operations • In real life: RDBMS’ are sophisticated, • but not intelligent? • Work based on specific principals and procedures
Tables Unique keys Foreign keys NUMA? SQL API Server Cursors: open, prepare, execute, close? DOP Memory Parallel plans Indexes partitioning Query Optimizer Execution Plan Statistics Tables and SQL combined implement business logic Compile Natural keys with unique indexes, not SQL Sample accuracy Parameter values Recompile temp table / table variable Rows per thread OS LPIM, Large Pages Soft NUMA TCP port mapping Index & Stats Maintenance Actual Plan Storage Engine Row estimate propagation error Hardware SET NO COUNT Information messages NUMA Index and Statistics maintenance policy 1 Logic may need more than one execution plan? Compile cost versus execution cost? Plan cache bloat? The Execution Plan links all the elements of performance Index tuning alone has limited value Over indexing can cause problems as well
Database & Developers • Too much focus on logic? • SQL & Database depends on: • • Clear usable search argument(s) Statistics sampling accuracy (%) and recompute criteria Procedure/SQL Compile values Propagating row estimate accuracy
Database Architecture & Design Tables Unique keys Foreign keys SQL Indexes partitioning Database Architecture: Tables, unique keys, foreign keys Business logic: SQL Performance tuning: Indexes
RDBMS Tables Unique keys Foreign keys SQL Indexes partitioning Query Optimizer Execution Plan Statistics RDBMS automatically generates and maintains data distribution statistics Compile Stored procedures and parameterized SQL enable plan reuse Plans are compiled based on parameter values Sample accuracy Parameter values Query optimizer: Has a model for the cost of SQL operations based on rows and pages involved fuses: Tables, key, SQL, Indexes, Statistics and compile parameter values into an execution plan
Explicit Control Tables Unique keys Foreign keys SQL Indexes partitioning Query Optimizer Execution Plan Statistics Sample accuracy Compile Parameter values Can override when statistics are computed/re-computed, Sampling percentage Can control compile parameter values For skewed data distribution: One business logic might have more than one plan Analytics – perhaps should not use a pre -compiled plan, force recompile for each execution Database architected blind to the inner workings of the RDBMS will not just magically work well, But most can be made to work well by overriding statistics, compile parameters, etc. to achieve the desired execution plans. On www. qdpma. com – look for slide deck Modern Performance
Sequentially Increasing (Identity) • Long ago, several SQL Server experts reported • a clustered index on an integer sequentially increasing value (identity) was “best practice” • Neglected to say that test system was 4 -way SMP • Not 16 -way NUMA • E 3 72 K/s, E 10 10 c 30 K, 4 -way 1500 -6 K • 100 K rows/s with distributed key,
SQL NUMA Optimization • Database and Application are architected in a coordinated fashion to allow RDBMS to achieve processor-memory locality
TPC-C Benchmark • 8 of 9 tables clustered leading with Warehouse Id • Application maps each key range to a connection to a specific TCP port number • RDBMS tuning setting maps TCP port to affinitized processor • Each processor group only access certain range of cluster key values • Assuming a clean start with no other activity • Data pages will likely be in local node memory
TPC-E • 5 Trade related tables clustered on Trade ID • Cash Transaction, Settlement, Trade, T History, T Request • Trade ID assigned with function Get Next ID • TID Range table has row for each SPID • Each SPID is assigned a block of 100, 000 TID values • Transactions from a specific connection inserts to its own block of pages, • achieving processor-memory locality
Web/App Server • Does not just magically scale (cores/sockets/HT) • Memory management strategy • Multiple heaps, Thread local storage • for high core count and NUMA • Separate long and short lived structures • Global (all threads) versus thread specific • NUMA aware memory management • Contention: Strategy for thread processor affinity • Threads allocate local memory • Scaling limitations • Multiple threads allocating from 1 heap • Undisciplined dynamic memory allocation
Performance has many facets • Frequency, IPC, superscalar, L 1 -L 2 fit • Vector instructions, SIMD – MMX, SSE, AVX, etc. • Memory bandwidth • Memory latency • SMT/HT
Is Performance Still Important? • Hardware is really immensely powerful • Great for parallelized & streaming memory • Round-trip memory latency a big issue • “Best practices” from long ago seriously obsolete • Software – very feature rich and sophisticated Or totally stupid • Business intelligence – go for it • transaction processing possibly problematic • “Best practices” from long ago probably obsolete • OLTP – • either app & database architecture for NUMA • or Single Socket, might need NUMA rework anyways
Is Performance Still Important? • Hardware is really immensely powerful • Most applications OK even with significant inefficiencies • Significant inefficiencies are common • Lack of NUMA strategy • Severe inefficiencies are possible • Contention between threads combined with NUMA
• Does it scale (cores, sockets, HT/SMT)? • Contention issues? High concurrency, NUMA • Processor/Memory affinity on NUMA systems
6 memory channels 48 PCI-e lanes
SMB DDR SMB SMB SMB DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR DDR Agent DDR PCI-E x 8 DDR 4 DDR4 DDR DDR 4 DDR DDR DDR 4 DDR DDR DDR DDR DDR DDR SMB DDR DDR SMB DDR 4 SMB DDR 4 4 x Xeon E 7 v 4 Up to 24 cores/die 24 DIMMs/socket 64 PCI-E lanes, 8 x 8 ? DDR 4 SMB PCH C DDR C 4 cores 4 DIMMs/socket 16 PCI-E SMB LLC DDR Gfx Xeon E 3 v 5/6 C SMB DDR 4 C DDR 4 mem SMB DDR 4 2 x Xeon E 5 v 4 10, 15 & 24* core die 12 DIMMs/socket 80 PCI-E lanes, 8 x 8 ? DDR 4 Mem Controller C C C DDR 4 QPI PCI-E C C C DDR 4 Mem Controller QPI C C C C C C DDR 4 PCI-E C C C DDR 4 System Architecture 2016
Sky Lake – Xeon SP, Xeon Phi Skylake SP 5 vertical, 6 across, 2 other – 28 cores Knights Landing (Xeon Phi x 200) 7 vertical, 6 across, 4 other – 38 spots (2 c/spot)
10, 18, 28 cores
Xeon Phi EDC PCI-E D M I EDC 3 DDR 4 channels DDR MC EDC Misc. EDC 3 DDR 4 channels EDC
PCI-E Mem Controller PCI-E C C C C C Mem Controller C C C
http: //www. tomshardware. com/reviews/intel-optane-ssd-900 p-3 d-xpoint, 5292 -2. html