install packagesXML install packagesstringr libraryXML librarystringr t html




 • install. packages(\"stringr\") • library(XML) • library(stringr) • t")
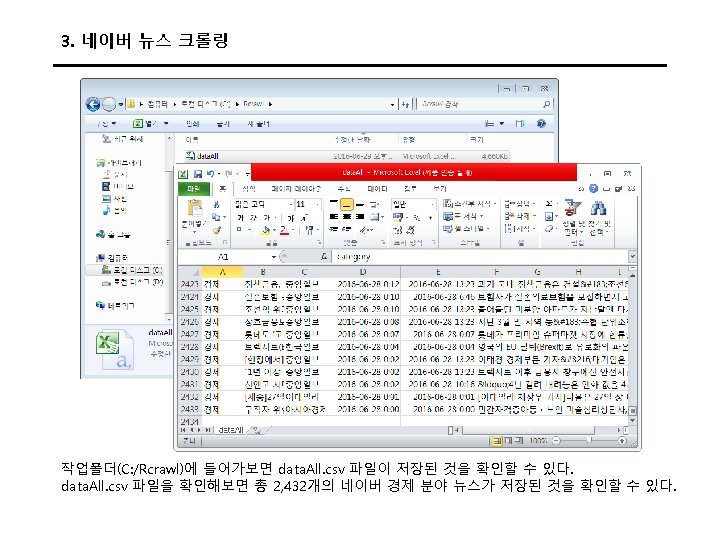
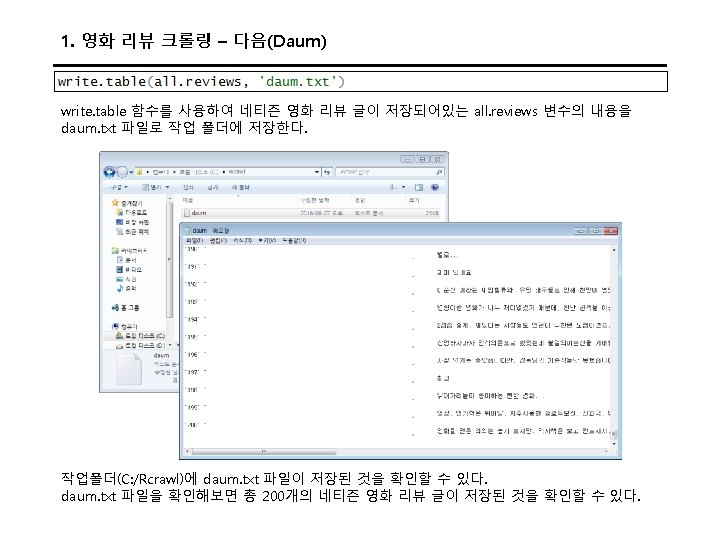
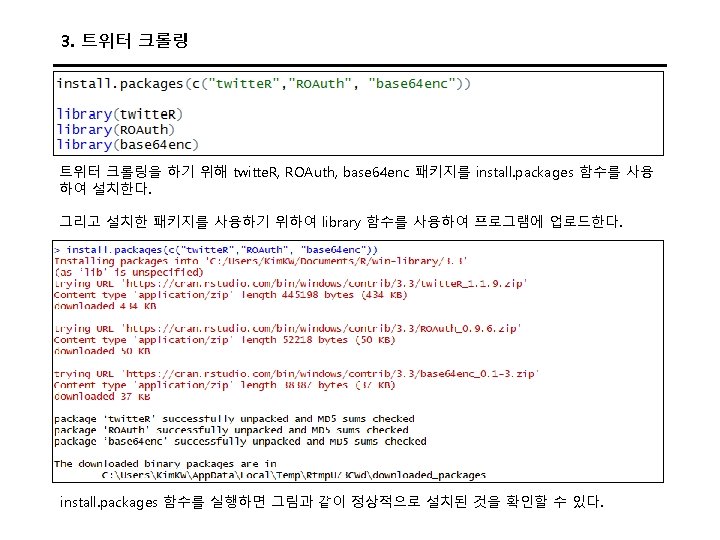
뉴스 크롤링 • install. packages("XML") • install. packages("stringr") • library(XML) • library(stringr) • t <- html. Tree. Parse("http: //www. ibtimes. com/first-quarter-earnings-worst-financial-crisisanalysts-say-recession-not-horizon-2368146", use. Internal. Nodes=TRUE, trim=TRUE) • minutes <- xpath. SApply(t, "//p", xml. Value) • • write. csv(minutes, "c: /asd. csv") View(minutes)

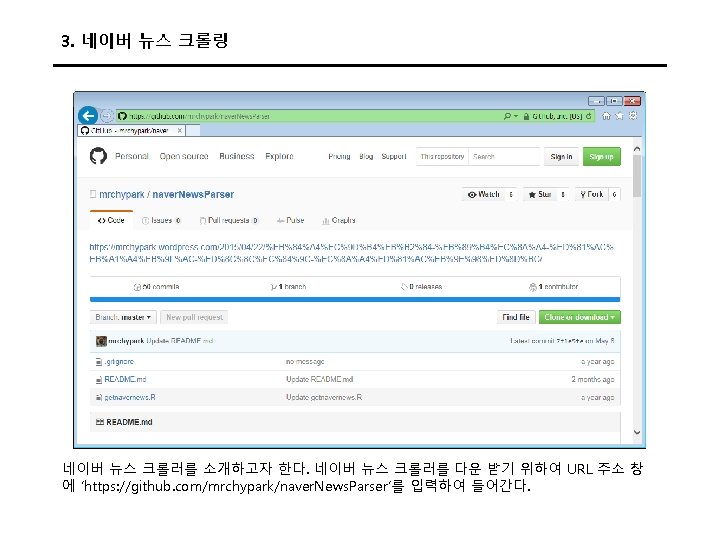
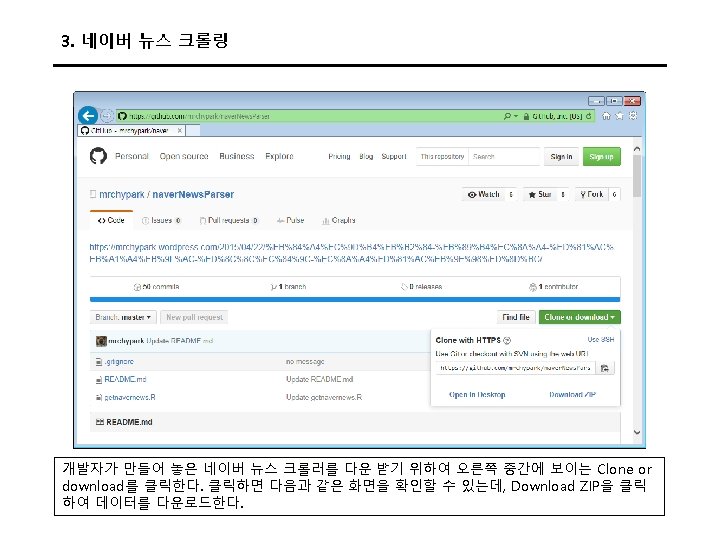
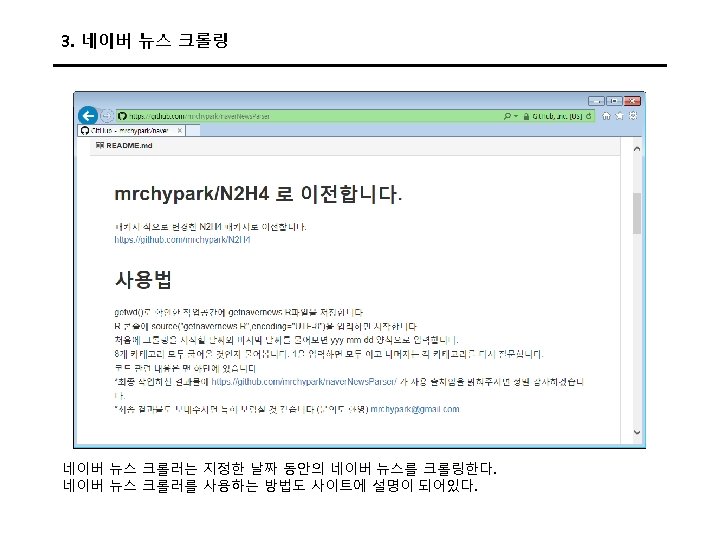






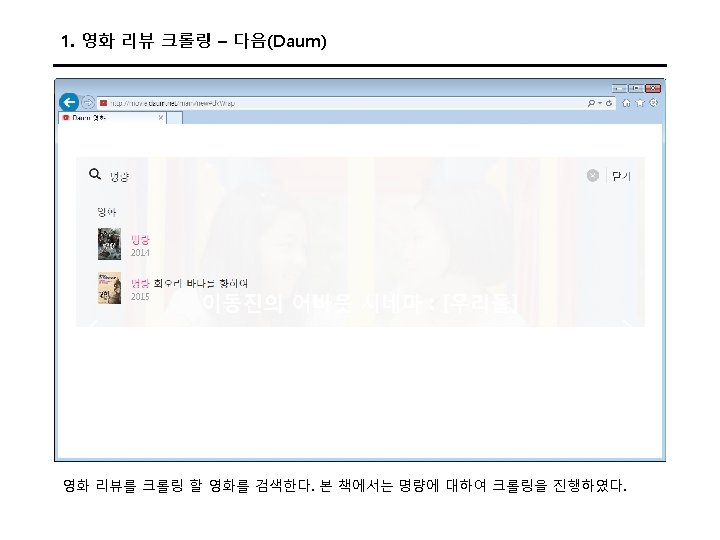
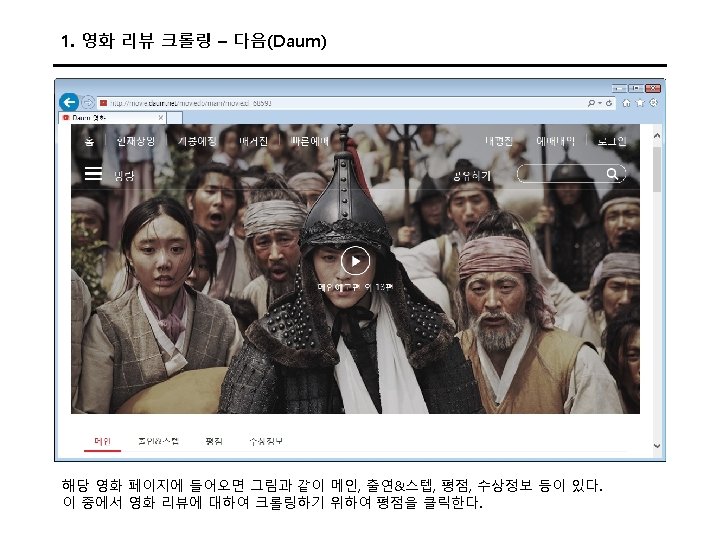
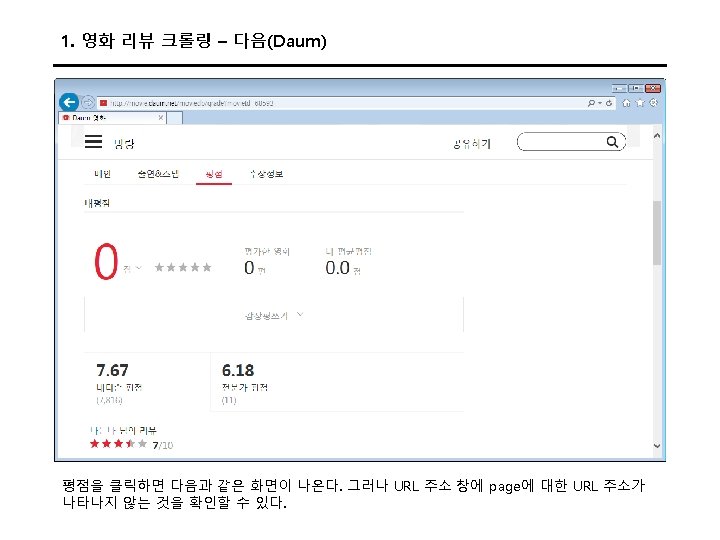
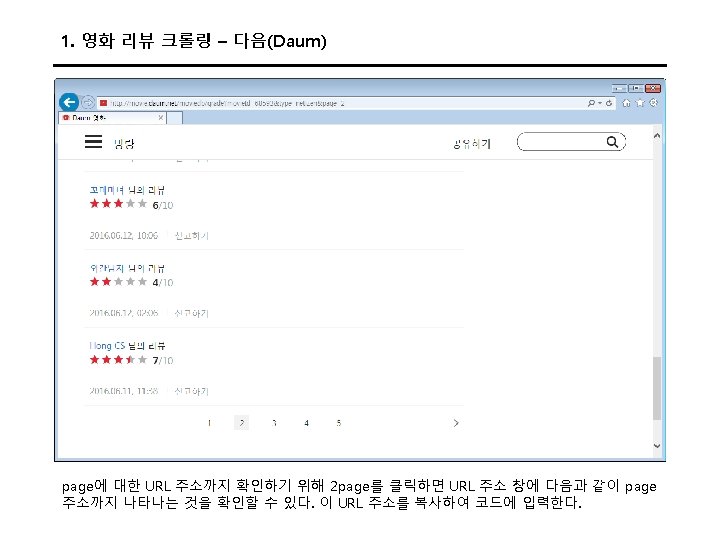

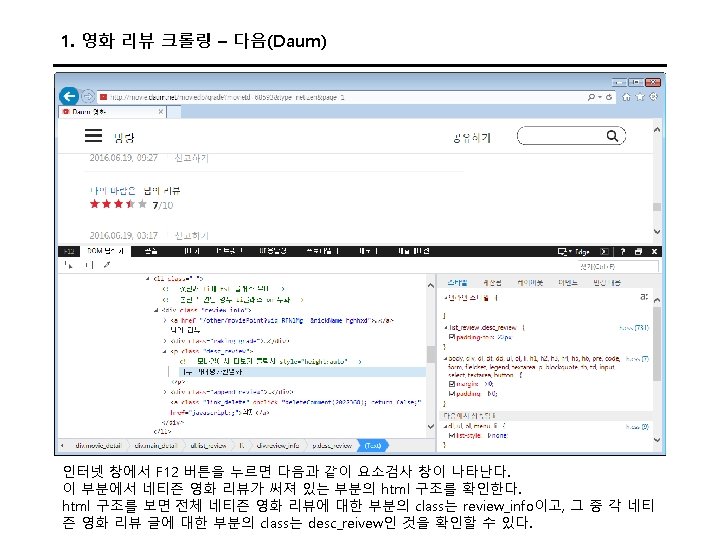



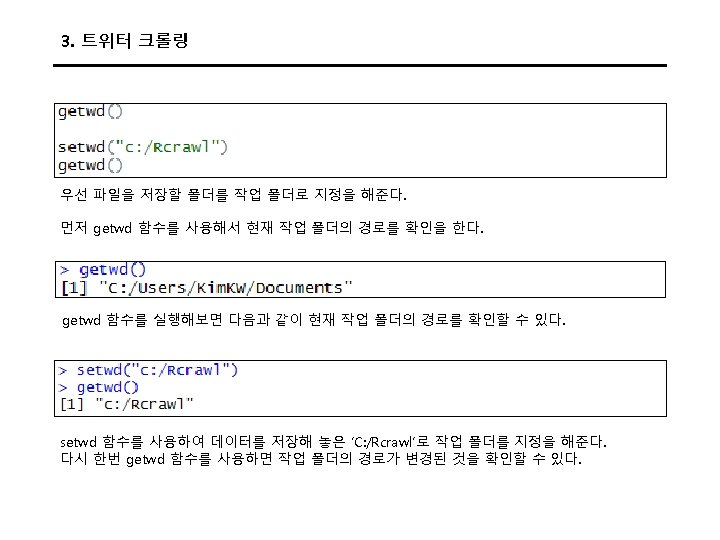
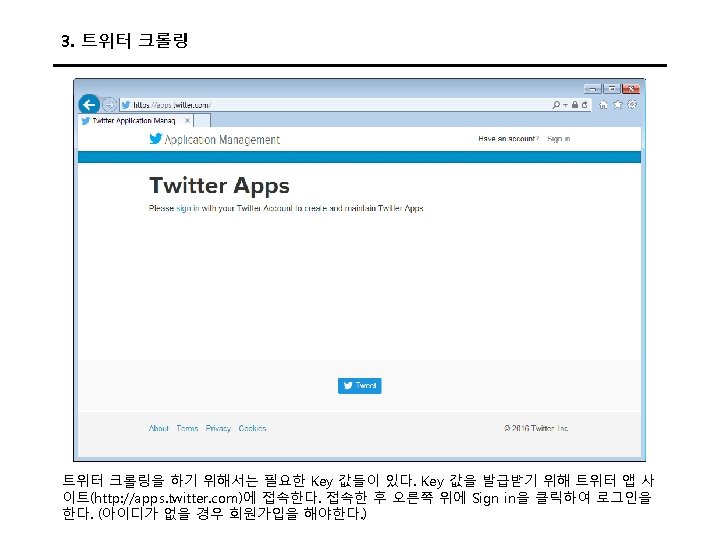
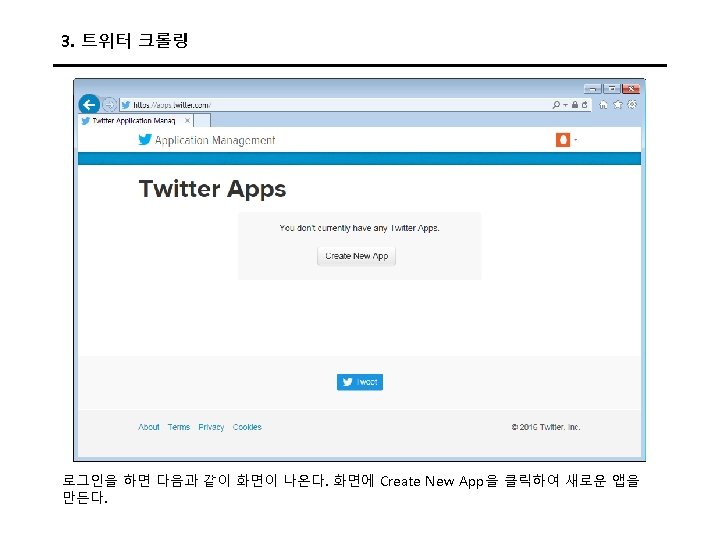
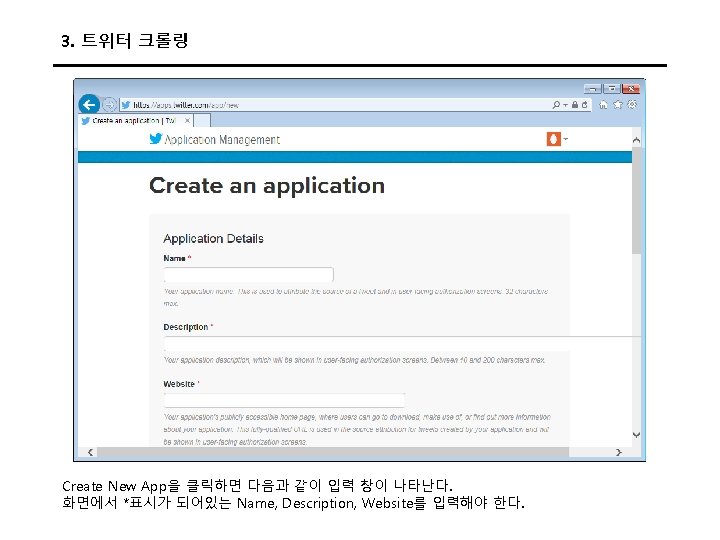
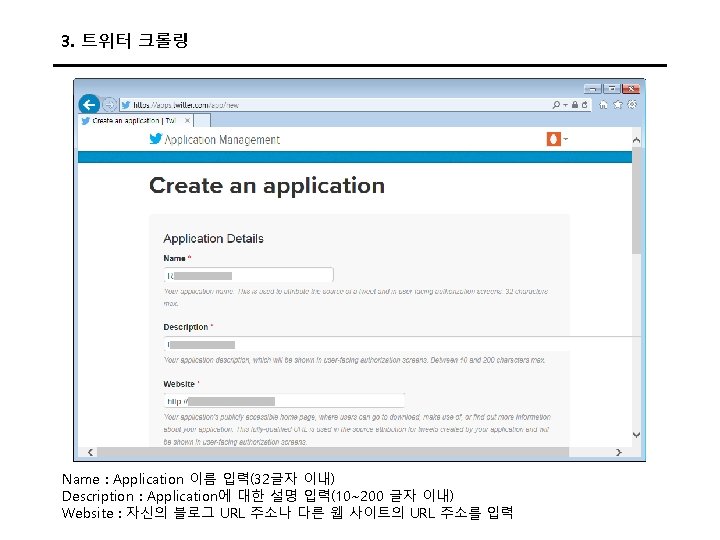
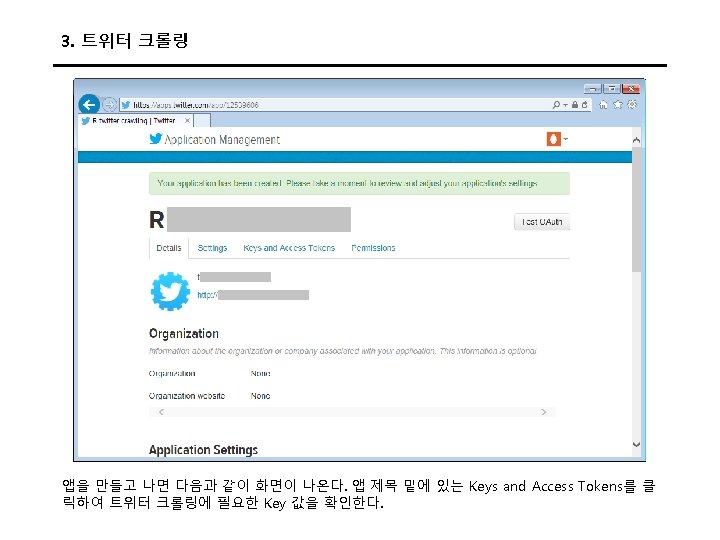

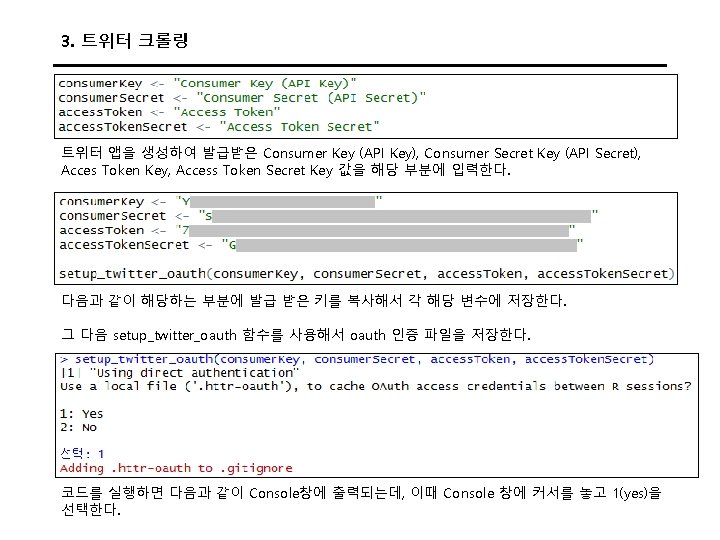
3. 트위터 크롤링 Keys and Access Tokens를 누르면 다음과 같이 나온다. 여기에서 Consumer Key (API Key)와 Consumer Secret (API Secret) 값을 코드에 입력한다.
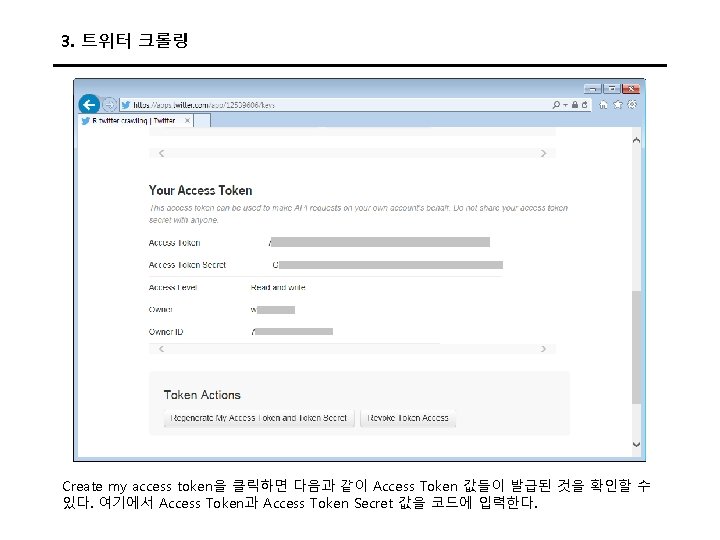



4. 다음 뉴스 크롤링 - 파이썬 import requests from bs 4 import Beautiful. Soup from urllib. parse import quote # headers = {'User-Agent': 'Mozilla/5. 0 (Macintosh; Intel Mac OS X 10_10_1) Apple. Web. Kit/537. 36 (KHTML, like Gecko) Chrome/39. 0. 2171. 95 Safari/537. 36'} # file output fid = open('ouput. txt', 'w+', encoding='utf 8') # keyword & page start, end keyword = quote('3 d 프린터') page_start =1 page_end =158 for page in range(page_start, page_end+1):
 # url 2 url = 'http: //search. daum. net/search? w=news&q='+keyword+'&spacing=0 &DA=PGD&p='+page_str+'&sd=20170501000000&ed=2017053123")
page_str = str(page) # url 2 url = 'http: //search. daum. net/search? w=news&q='+keyword+'&spacing=0 &DA=PGD&p='+page_str+'&sd=20170501000000&ed=2017053123 5959&period=u' # requset & response : status code response = requests. get(url, headers=headers) #print('status code: %d' % response. status_code) soup = Beautiful. Soup(response. content, 'lxml', from_encoding='uf -8') posts = soup. find_all("div", "cont_inner") for post in posts: title = post. find("a", "f_link_b") title_text = title. get_text() desc = post. find("p", "f_eb desc") desc_text = desc. get_text() fid. write('%stn%sn' % (title_text, desc_text)) print('%s' % title_text)




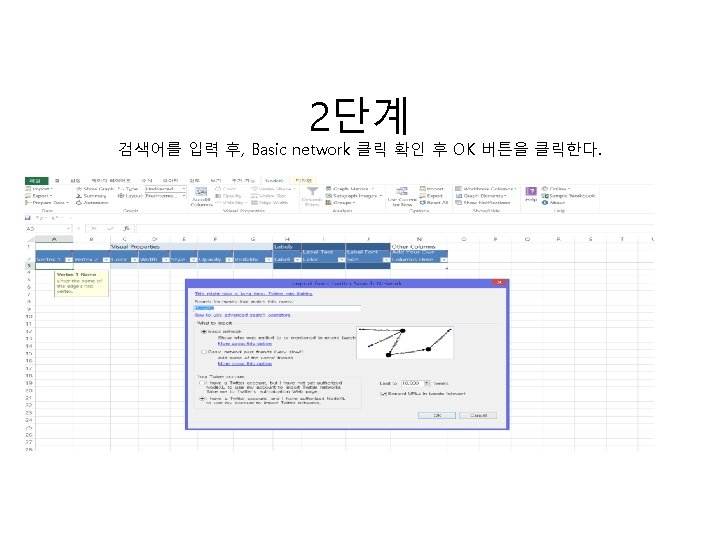
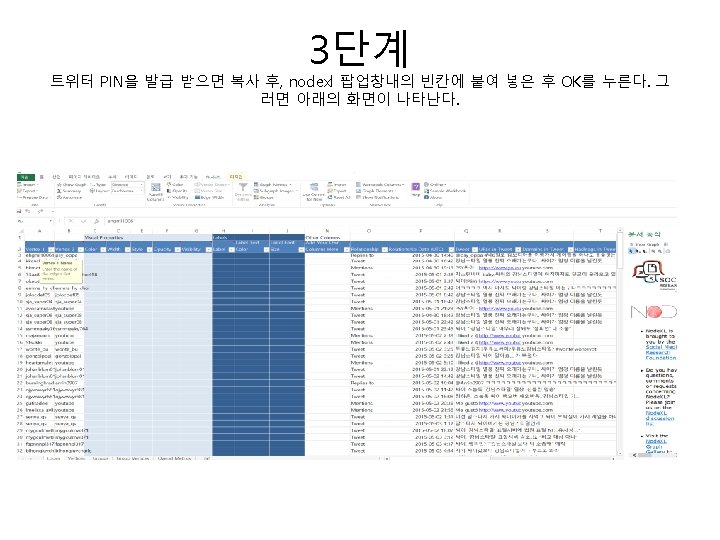
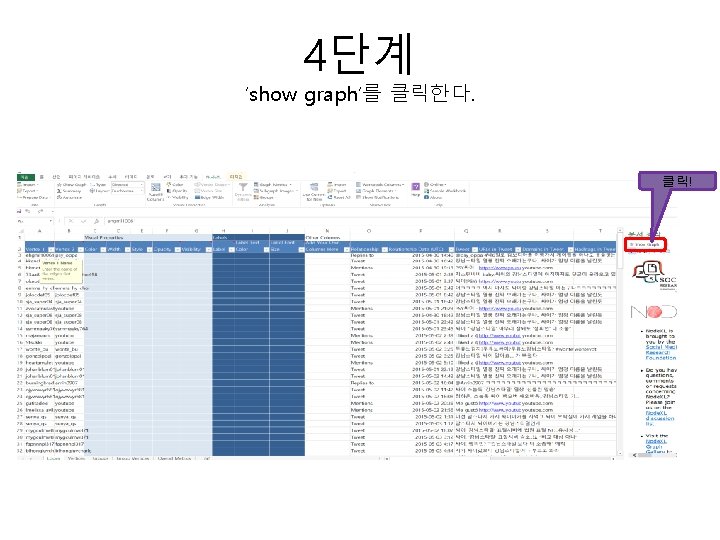


1. 빈도, word clod 분석
 install. packages(\"Ko. NLP\") install. packages(\"RColor. Brewer\") install. packages(\"wordcloud\") library(Ko.")
##### text mining setwd("c: /Rtest") install. packages("Ko. NLP") install. packages("RColor. Brewer") install. packages("wordcloud") library(Ko. NLP) library(RColor. Brewer) library(wordcloud) result <- file("tax. txt", encoding="UTF-8") result 2 <- read. Lines(result) head(result 2, 3) result 3 <- sapply(result 2, extract. Noun, USE. NAMES=F) head(unlist(result 3), 20) write(unlist(result 3), "tax_word. txt") myword <- read. table("tax_word. txt") nrow(myword)
 head(sort(wordcount, decreasing=T), 20) palete <- brewer. pal(9, \"Set 1\") x 11()")
wordcount <- table(myword) head(sort(wordcount, decreasing=T), 20) palete <- brewer. pal(9, "Set 1") x 11() wordcloud( names(wordcount), freq=wordcount, scale=c(5, 1), rot. per=0. 5, min. freq=4, random. order=F, random. color=T, colors=palete ) result 2 <- gsub("寃? ", "", result 2) result 2 <- gsub("? ? � ", "", result 2) result 2 <- gsub("? 썝", "", result 2)

 install. packages(c(\"Ko. NLP\", \"arules\", \"igraph\", \"combinat\")) library(Ko. NLP) library(arules) library(igraph) library(combinat) f")
setwd("c: /Rtest") install. packages(c("Ko. NLP", "arules", "igraph", "combinat")) library(Ko. NLP) library(arules) library(igraph) library(combinat) f <- file("tax. txt", encoding="UTF-8") fl <- read. Lines(f) close(f) head(fl, 10) tran <- Map(extract. Noun, fl) tran <- unique(tran) tran <- sapply(tran, unique) tran <- sapply(tran, function(x) {Filter(function(y) {nchar(y) <= 4 && nchar(y) 1 && is. hangul(y)}, x)} ) tran <- Filter(function(x){length(x) >= 2}, tran) names(tran) <- paste("Tr", 1: length(tran), sep="") names(tran)
 wordtran wordtab <- cross. Table(wordtran) wordtab ares <- apriori(wordtran, parameter=list(supp=0.")
wordtran <- as(tran, "transactions") wordtran wordtab <- cross. Table(wordtran) wordtab ares <- apriori(wordtran, parameter=list(supp=0. 07, conf=0. 05)) inspect(ares) rules <- labels(ares, rule. Sep=" ") rules <- sapply(rules, strsplit, " ", USE. NAMES=F) rulemat <- do. call("rbind", rules) ruleg <- graph. edgelist(rulemat[-c(1: 16), ], directed=F) plot. igraph(ruleg, vertex. label=V(ruleg)$name, vertex. label. cex=0. 5, vertex. size=20, layout=layout. fruchterman. reingold. grid) closen <- closeness(ruleg) plot(closen, col="red", xaxt="n", lty="solid", type="b", xlab="단어", ylab="closeness") points(closen, pch=16, col="navy") axis(1, seq(1, length(closen)), V(ruleg)$name, cex=5)
- Slides: 61