STATISTICA VS REGOLE Alessandro Maisto Alcune nozioni di




 è l’operazione che suddivide il testo in unità testuali")












































")
















 •")


- Slides: 70
STATISTICA VS REGOLE Alessandro Maisto
Alcune nozioni di base • Token e Type ‘Il cane che uccise il gatto che uccise il topo’ • 10 tokens: {il, cane, che, uccise, il, gatto, che, uccise, il, topo} • 6 Types: • • • Il Cane Che Uccise Gatto Topo
Alcune nozioni di base • Part-of-Speech e Lemma • ‘Il cane che uccise il gatto, che uccise il topo’ DET N PRON V DET N Il cane che uccidere il gatto che uccidere il topo
Nozioni di Base • Pre-Processing • Normalizzazione del Testo: sostituzione Maiuscole, eliminazione punteggiatura… ‘il cane che uccise il gatto che uccise il topo’ • Rimozione delle ‘Stop Word’: ‘Cane uccise gatto uccise topo’
Tokenizzazione • La tokenizzazione (tokenization) è l’operazione che suddivide il testo in unità testuali minime • In linea generale viene considerata unità minima una sequenza di caratteri alfanumerici inclusa tra due spazi bianchi • Se specificato, un programma elettronico può identificare come unità minimo anche sequenze che includano spazi bianchi come nel caso delle Polirematiche (Carta di credito, ma anche Museo Archeologico o Bilbo Baggins)
Tokenizzazione • Non è un’operazione scontata: Questo non è un giallo, è romanzo d’amore! 1. 2. 3. La sequenza Questo non è preceduta da uno spazio bianco La sequenza giallo, è considerato un unico token? La sequenza d’amore va separata? • Il testo può essere pre-trattato per aggiungere spazi bianchi prima dei segni di punteggiatura o dopo gli apostrofi
La Statistica dei Testi ‘In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to eat: it was a hobbit-hole, and that means comfort. It had a perfectly round door like a porthole, painted green, with a shiny yellow brass knob in the exact middle. The door opened on to a tube-shaped hall like a tunnel: a very comfortable tunnel without smoke, with panelled walls, and floors tiled and carpeted, provided with polished chairs, and lots of pegs for hats and coats – the hobbit was fond of visitors. The tunnel wound on and on, going fairly but not quite straight into the side of the hill – The Hill, as all the people for many miles round called it – and many little round doors opened out of it, first on one side and then on another. No going upstairs for the hobbit: bedrooms, bathrooms, cellars, pantries (lots of these), wardrobes (he had whole rooms devoted to clothes), kitchens, dining-rooms, all were on the same floor, and indeed on the same passage. The best rooms were all on the left-hand side (going in), for these were the only ones to have windows, deep-set round windows looking over his garden and meadows beyond, sloping down to the river. ’ Lo Hobbit, Capitolo 1
Calcolo delle occorrenze the 17 and 12 a 11 on 9 of 6 to 6 in 5 it 5 with 5 for 4 round 4 all 3 going 3 hobbit 3 hole 3
the and of to a he in was they it that had his you on for not were as i at all with but said them their bilbo there 6040 4406 2481 2087 1919 1879 1456 1385 1342 1152 1007 949 905 779 771 718 714 695 687 686 658 654 653 592 583 539 525 503
Comparazione tra testi di Dimensioni diverse the 17 and 12 a 11 on 9 of 6 to 6 in 5 it 5 with 5 for 4 round 4 all 3 going 3 hobbit 3 hole 3 the and of to a he in was they it that had his you on for not were as i at all with but said them their bilbo there 6040 4406 2481 2087 1919 1879 1456 1385 1342 1152 1007 949 905 779 771 718 714 695 687 686 658 654 653 592 583 539 525 503
said 51 said 34 frodo 42 frodo 30 night 34 gollum 28 aragorn 31 up 28 river 29 down 21 boats 28 sam 20 out 26 now 19 grat 25 must 18 dark 25 out 18 sam 24 under 17 ‘Il Signore degli anelli – La compagnia dell’anello’, capitolo 9 Tokens: 8243 ‘Il signore degli anelli - Le due torri’, capitolo 7 Tokens: 4946
Calcolo della Frequenza Parole Occorrenze frequenze Parole occorrenze frequenze Said 51 0, 006187 Said 34 0, 006874 Frodo 42 0, 005095 Frodo 30 0, 006066 Night 28 0, 004125 Night 11 0, 002224 Libro 1 capitolo 9 Libro 2 capitolo 7
the and of to a he in was they it that had his you on for not were as i at all with but said them their bilbo there 6040 4406 2481 2087 1919 1879 1456 1385 1342 1152 1007 949 905 779 771 718 714 695 687 686 658 654 653 592 583 539 525 503 the and of to a he in was they it that had his you on for not were as i at all with but said them their bilbo there 0, 061855 0, 045121 0, 025408 0, 021373 0, 019652 0, 019243 0, 014911 0, 014184 0, 013743 0, 011797 0, 010313 0, 009719 0, 009268 0, 007978 0, 007896 0, 007353 0, 007312 0, 007117 0, 007035 0, 007025 0, 006738 0, 006698 0, 006687 0, 006063 0, 00597 0, 00552 0, 005376 0, 005151
Tf – idf •
Tf – idf Capitolo 1, lo Hobbit the 0, 056213 said 0, 008561 and 0, 048327 bilbo 0, 004168 a 0, 02422 like 0, 004168 to 0, 023882 thorin 0, 00383 of 0, 02084 gandalf 0, 003717 he 0, 019038 dwarves 0, 003267 in 0, 013631 door 0, 003042 was 0, 01273 baggins 0, 002816 i 0, 012279 little 0, 002704 on 0, 011152 hobbit 0, 002704 Term Frequency Con Stopwords Term Frequency Senza Stopwords plates gandalf map 0, 059822 0, 059115 0, 053391 belladonna 0, 047857 dungeons 0, 04451 beautiful 0, 043684 grandfather coffee glasses pantry 0, 040877 0, 035893 TF-IDF per capitolo
Statistica Tesuale • Permette semplici e rapide analisi di testi • Computazionalmente vantaggiosa • Non Language-Dependent • Presenza di margini di errore ‘statisticamente tollerabili’
Nuovo tracollo per il settore auto ad aprile: le immatricolazioni lo scorso mese sono state praticamente azzerate accusando gli effetti del lockdown. La Motorizzazione ha immatricolato 4. 279 autovetture, con una variazione di 97, 55% rispetto ad aprile 2019, quando ne sono state registrate 174. 924. Nel mese di marzo 2020 sono state invece immatricolate 28. 389 autovetture, con una variazione di -85, 39% rispetto a marzo 2019. Nei primi quattro mesi 'targate' 351. 611 autovetture contro 712. 991 (-50, 69%). Sulla stessa linea i dati per Fca che lo scorso mese ha immatricolato 1. 620 vetture rispetto a 44. 173 di aprile 2019 con un calo del 96, 33%. La quota sale al 37, 86% contro il 25, 25% di aprile 2019. Nei primi quattro mesi dell'anno vendute 87. 504 auto contro 176. 371 dello stesso periodo del 2019 (-50, 39%). Dal Lingotto fanno sapere che essendo proseguito anche in aprile il contesto straordinariamente difficile per il mercato dell'auto provocato dalla pandemia di coronavirus, sono naturalmente poco confrontabili le immatricolazioni del mese e del primo quadrimestre dell'anno con i risultati del 2019. Infatti, a partire dall'11 marzo sono state chiuse tutte le attività non necessarie - incluso le concessionarie e ogni punto di vendita di automobili - e solo nell'ultima settimana di aprile alcune attività produttive e commerciali hanno potuto riprendere, con la conseguenza che rispetto all'anno scorso il mercato dell'auto in Italia ad aprile perde il 97, 6% e nel quadrimestre il 50, 7%. Gian Primo Quagliano, presidente del Centro Studi Promotor, sottolinea che "per tornare alla normalità ci vuole una terapia d'urto come emerge anche a livello europeo". La situazione non e' piu' rosea infatti nel resto dell'Europa. Proprio domani il cancelliere Angela Merkel incontrerà i dirigenti e i sindacati delle maggiori aziende automobilistiche tedesche, duramente colpite dalla crisi provocata dalla pandemia per discutere di aiuti di Stato sotto forma di incentivi all'acquisto. Monika Schnitzer, una rappresentante dei Saggi dell'economia, ha espresso dei dubbi sulla richiesta di questi aiuti definendola "puro lobbismo". Oggi l'Ifo ha reso noti i dati sul comparto auto che e' sceso a -85, 4 punti ad aprile, dai -13, 2 punti a marzo: è stato raggiunto il crollo piu' grande e il valore più basso dalla riunificazione della Germania.
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mesa scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mesa avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mesa avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mesa scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mesa avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mesa avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917 Sinonimia Auto/ Autovettura
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mesa scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mesa avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mesa avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917 Sinonimia Auto/ Autovettura
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mesa scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mesa avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mesa avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917 Sinonimia Auto/ Autovettura Relazioni Morfo fonologiche Immatricolare, Immatricolazione immatricolato
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mesa scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mesa avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mesa avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917 Sinonimia Auto/ Autovettura Relazioni Morfo fonologiche Immatricolare, Immatricolazione immatricolato
il di essere a % aprile e da 2019 avere un che per in auto con ad primo marzo rispetto mese scorso anno immatricolare punto la contro autovettura 0, 109562 0, 061753 0, 023904 0, 01992 0, 017928 0, 015936 0, 013944 0, 011952 0, 00996 0, 00996 0, 007968 0, 007968 0, 005976 0, 005976 il di essere a in aprile e da 2019 mese avere un che per auto con ad primo marzo rispetto scorso su anno immatricolare punto contro autovettura quattro 0, 12753 0, 062753 0, 024291 0, 020243 0, 016194 0, 01417 0, 012146 0, 010121 0, 010121 0, 008097 0, 006073 0, 006073 0, 004049 aprile 2019 mese avere auto primo marzo rispetto scorso anno immatricolare in punto autovettura quattro 4 piu' 25 attività 39 immatricolazione pandemia infatti mercato grande variazione dare provocare 0, 023669 0, 017751 0, 014793 0, 011834 0, 008876 0, 008876 0, 005917 0, 005917 0, 005917 0, 005917 Sinonimia Auto/ Autovettura Relazioni Morfo fonologiche Immatricolare, Immatricolazione immatricolato Altre relazioni Semantiche Date: Aprile, Marzo, Mese Anno, 2019
Sinonimia • La principale risorsa per la sinonimia è Word. Net: • È un risorsa per l’inglese creata dalla Princeton University • È un enorme Database Lessicale dove Nomi, Verbi, Aggettivi, e Avverbi sono raggruppati in SYNSET, set di sinonimi cognitivi, ciascuno dei quali rappresenta un distinto concetto
Sinonimia • La struttura di Word. Net non include solo Sinonimi ma anche relazioni di iperonimia e iponimia (ISA), Meronimia (Part of), Antonimia • Comprende oltre 155 mila parole raggruppate in 175 mila synset per un totale di oltre 200 mila coppie parola-senso • Esistono due versione italiane: • Ital. Word. Net: creato dal CNR, contiene 47. 000 lemmi, 50. 000 synset e 130. 000 relazioni • Multi. Word. Net: Sviluppato in italia da FBK e parte di un progetto multilingue che include Spagnolo, Portoghese, Romeno, Ebraico e Latino. L’ultima versione include 32. 700 synset e 41. 500 lemmi
Relazione Morfo/Fonologica • Tra alcune parole è possibile riscontrare una relazione morfo- fonologica che corrisponde ad relazione semantica ed una equivalenza sintattica. • Smani-are Verbo • Smani-a Nome (Nominalizzazione) • Smani-oso Aggettivo (Aggettivalizzazione) Antonio smaniava di tornare a casa Antonio era smanioso di tornare a casa Antonio aveva smania di tornare a casa • Equivalenza Parafrastica • (Principio di invarianza morfemica) • Antonio desiderava tornare a casa (non rispetta il principio) • Antonio desidera Maria desidera Antonio (non rispetta il principio)
Altre relazioni Semantiche • Esplorare automaticamente relazioni semantiche di tipo differente è possibile percorrendo due strade possibili: • Definizione di Regole ad-hoc: è possibile stabilire una serie di pattern o grammatiche locali per descrivere un fenomeno specifico
Altre relazioni Semantiche • Esplorare automaticamente relazioni semantiche di tipo differente è possibile percorrendo due strade possibili: • Definizione di Regole ad-hoc: è possibile stabilire una serie di pattern o grammatiche locali per descrivere un fenomeno specifico
Altre relazioni Semantiche • Esplorare automaticamente relazioni semantiche di tipo differente è possibile percorrendo due strade possibili: • Definizione di Regole ad-hoc: è possibile stabilire una serie di pattern o grammatiche locali per descrivere un fenomeno specifico
Altre relazioni Semantiche • Esplorare automaticamente relazioni semantiche di tipo differente è possibile percorrendo due strade possibili: • Definizione di Regole ad-hoc: è possibile stabilire una serie di pattern o grammatiche locali per descrivere un fenomeno specifico o etichettare un dizionario elettronico con informazioni riguardanti la classe semantica di appartenenza • Calcolo della similarità semantica: la Semantica Distribuzionale calcola la similarità semantica costruendo enormi matrici di cooccorrenza
Semantica Distribuzionale • L’idea è quella di trasformare le parole in vettori numerici per calcolarne la similarità: • Punto di partenza teorico della Distrbutional Semantics è Harris: un elemento può essere definito come la somma di tutti i contesti in cui appare • L’idea di base è che se un’unità linguistica A e un’altra unità B co-occorrono con lo stesso gruppo di parole G, esse hanno lo stesso significato • I modelli esistenti di Distributional Semantics si dividono in 3 gruppi: • Modelli che calcolano la co-occorrenza considerando l’intero testo come contesto • Modelli che calcola la co-occorrenza in finestre che vanno da 5 a 10 parole • Modelli che utilizzano le relazioni sintattiche per calcolare la co-occorrenza • La matrice di co-occorrenza ha valore solo se calcolata su testi di grosse dimensioni (oltre 250 milioni di parole) • La maniera in cui viene successivamente calcolata la somiglianza è simile basata su modelli matematici (Distanza di Euclide, Cosine Similarity) che generano un valore di Somiglianza/distanza tra due vettori numerici
Un esempio «The horse raced past the barn fell» barn fell horse past raced the
Un esempio «The horse raced past the barn fell» barn fell horse past raced the
Come Funziona? 5 «The horse raced past the barn fell» barn fell horse past raced the 5
Come Funziona? 4 5 «The horse raced past the barn fell» barn fell horse past raced the barn fell horse 5 past raced the 5 4
Come Funziona? 3 4 5 «The horse raced past the barn fell» barn fell horse past raced the barn fell horse 5 past 4 raced 5 the 5 3 4
Come Funziona? 2 3 4 5 «The horse raced past the barn fell» barn fell horse past raced the barn fell horse 5 past 4 raced 5 the 3 5 3 4 5 4 2
Come Funziona? 1 2 4 3 5 «The horse raced past the barn fell» barn fell horse past raced the 2 4 3 6 fell horse 5 past 4 raced 5 the 3 5 3 4 5 4 2
Come Funziona? 0 1 2 4 3 5 «The horse raced past the barn fell» barn fell 5 fell horse past raced the 2 4 3 6 1 3 2 4 horse 5 past 4 raced 5 the 3 5 3 4 5 4 2
Come Funziona? «The horse raced past the barn fell» barn fell horse past raced the barn 0 0 2 4 3 6 fell 5 0 1 3 2 4 horse 0 0 0 5 past 0 0 4 0 5 3 raced 0 0 5 0 0 4 the 0 0 3 5 4 2
Semantica Distribuzionale • I modelli che utilizzano come conteso di ogni parola l’intero testo in cui la parola compare analizzano corpora composti da migliaia di testi attribuendo un valore di cooccorrenza per ogni volta che un termine compare in un testo assieme ad un altro termine. • I modelli basati sulla distanza sintattica utilizzano i parser sintattici per calcolare la struttura a dipendenze della frase e calcolare così il valore di co-occorrenza Berlusconi, che è stato presidente del governo per quasi vent'anni, è stato condannato per corruzione
Semantica Distribuzionale • I modelli che utilizzano come conteso di ogni parola l’intero testo in cui la parola compare analizzano corpora composti da migliaia di testi attribuendo un valore di cooccorrenza per ogni volta che un termine compare in un testo assieme ad un altro termine. • I modelli basati sulla distanza sintattica utilizzano i parser sintattici per calcolare la struttura a dipendenze della frase e calcolare così il valore di co-occorrenza
Esempi di Valori di Similarità presidente berlusconi repubblica 0, 55… prodi 0, 34… essere|stare 0, 53… silvio 0, 32… governo 0, 51… governo 0, 30… nuovo 0, 49… centrodestra 0, 30… consiglio 0, 49… elezione 0, 27… eleggere 0, 48… rumor 0, 27… primo 0, 47… politico 0, 26… nominare 0, 46… ccd 0, 26… seguito 0, 46… guidare 0, 24… politico 0, 45… radicale 0, 24…
Tagging sintattico automatico • POS Tagging • Lemmatizzazione • Parsing
Part of Speech Tagging • L’identificazione delle categorie grammaticali è un’operazione che può essere effettuata automaticamente e funge da base per una serie di task statistici o basati su regole • Statistici: può essere utile distinguere Nomi da Aggettivi o Verbi ecc. • Rule Based: il corretto POS Tagging ha un ruolo fondamentale per ogni analisi di questo genere
Part of Speech Tagging • Può essere affrontato in modo semi automatico con un tagging non deterministico • Ad ogni parola viene aggiunto il Tag di ogni suo possibile significato: pesca, N (la pesca), pesca, V (pescare) • Nella maggior parte dei casi si utilizzano algoritmi probabilistici (metodi stocastici) e di machine learning
Part of Speech Tagging • Un esempio efficace di metodo stocastico per il POS Tagging è stato presentato già nel 1988 da Church. Il modello ha raggiunto una precisione del 95 -99% sull’Inglese: • La categoria è assegnata in base al prodotto di due probabilità: Lessicale e Contestuale: Parola Part of speech I Pron 5837 N 1 see V 771 INTER 1 a DET 23013 PREP 6 bird N 26 • La probabilità lessicale è calcolata dividendo la frequenza di una categoria per un singolo token per la frequenza del token: see, V = 771/772 = 0. 064 • La probabilità contestuale è calcolata dividendo la frequenza del trigram (V, DET, N) per la frequenza del bigram (Det, N): see, V = 3412/53091 = 0. 064 • Se vogliamo calcolare la probabilità che nella stessa posizione ci sia un N: 629/53091 = 0. 01
Part of Speech Tagging • Un altro sistema chiamato Averaged Perceptron Tagger prende in analisi più fattori: • Il punto di partenza è un Training Set contenente un gran numero di frasi già taggate • Se una parola è associata ad un solo tag nel training set, allora il tag viene assegnato automaticamente • In caso la parola sia sconosciuta o associata a più tag interviene l’algoritmo, calcolando il peso di ogni tag per la parola: • Ad ogni iterazione l’algoritmo calcola un valore per ogni tag • Al termine delle iterazioni, il tag con il maggior peso viene attribuito • Il peso è calcolato su una serie di probabilità a livello lessicale, morfosintattico e sintattico (contestuale)
Part of Speech Tagging • Un altro sistema chiamato Averaged Perceptron Tagger prende in analisi più fattori: • Il punto di partenza è un Training Set contenente un gran numero di frasi già taggate • Se una parola è associata ad un solo tag nel training set, allora il tag viene assegnato automaticamente • In caso la parola sia sconosciuta o associata a più tag interviene l’algoritmo, calcolando il peso di ogni tag per la parola: • Ad ogni iterazione l’algoritmo calcola un valore per ogni tag • Al termine delle iterazioni, il tag con il maggior peso viene attribuito • Il peso è calcolato su una serie di probabilità a livello lessicale, morfosintattico e sintattico (contestuale)
Lemmatizzazione • Operazione che consiste nel ridurre un token alla sua forma canonica (Lemma) • In italiano il lemma equivale al maschile singolare per nomi ed aggettivi (e femminile singolare per i nomi femminili), infinito presente per i verbi • In lingua inglese la lemmatizzazione è spesso sostituita da un’altra operazione chiamata Stemming. • Lo stemming consiste nel ridurre un token alla radice. • Per l’inglese è dimostrato che la differenza tra Stemming e Lemmatizzazione è insignificante
Lemmatizzazione • La lemmatizzazione può essere effettuata con metodi statistici o attraverso l’uso di Dizionari. • Conoscendo la Part of Speech di una parola è semplice disambiguare tra i possibili lemmi ad essa associati pesca, N = pesca; pesca, V = pescare • Questa operazione permette di ricondurre token differenti ad un’unica forma e dunque riduce il costo computazionale del calcolo statistico migliorando, nel contempo, la qualità dei risultati. • Nei metodi rule based è fondamentale effettuare una corretta lemmatizzazione dato che è in questa fase che è possibile aggiungere informazioni morfosintattiche e semantiche.
Parsing Sintattico • Il parsing sintattico si occupa di individuare le strutture sintattiche di una frase collegando ogni parola con un’altra parola dalla quale essa dipende e definendo questa relazione • Gli algoritmi di Parsing sfruttano training set di grosse dimensioni per apprendere le strutture di frase per poi determinare la struttura sintattica di una frase sconosciuta
Un esempio di Analisi • Esempio di analisi di un testo: • Fase 1: definizione e collezione del Corpus: i primi 3 libri di «Cronache del ghiaccio e del fuoco» di George Martin • Fase 2: creazione dei dizionari elettronici ad-hoc (personaggi, luoghi):
Un esempio di Analisi • Fase 3: estrazione delle concordanze per 4 personaggi: John Snow, Arya Stark, Tyrion Lannister e Daenerys Targaryan • Ogni volta che appare un nome legato al personaggio si catturano le 15 parole che lo precedono e le 15 parole che lo seguono.
Un esempio di Analisi • Fase 3: estrazione delle concordanze per 4 personaggi: John Snow, Arya Stark, Tyrion Lannister e Daenerys Targaryan • Ogni volta che appare un nome legato al personaggio si catturano le 15 parole che lo precedono e le 15 parole che lo seguono. su di loro, qualsiasi fine abbiano fatto. Predoni e assassini, è questo che sono tutti. » <John. Snow> percepì un fruscio fra le rosse foglie sopra di lui. Due rami si ci accampiamo sulle rive e forse prendiamo anche qualche pesce. <John. Snow>, portami della carta, è ormai tempo che io scriva a maestro Aemon. » «Trova Tarly e provvedi a che questo parta subito» disse Mormont porgendo il messaggio a <John. Snow>. Poi emise un fischio. Il suo corvo scese in planata
Un esempio di Analisi • Fase 3: estrazione delle concordanze per 4 personaggi: John Snow, Arya Stark, Tyrion Lannister e Daenerys Targaryan • Ogni volta che appare un nome legato al personaggio si catturano le 15 parole che lo precedono e le 15 parole che lo seguono.
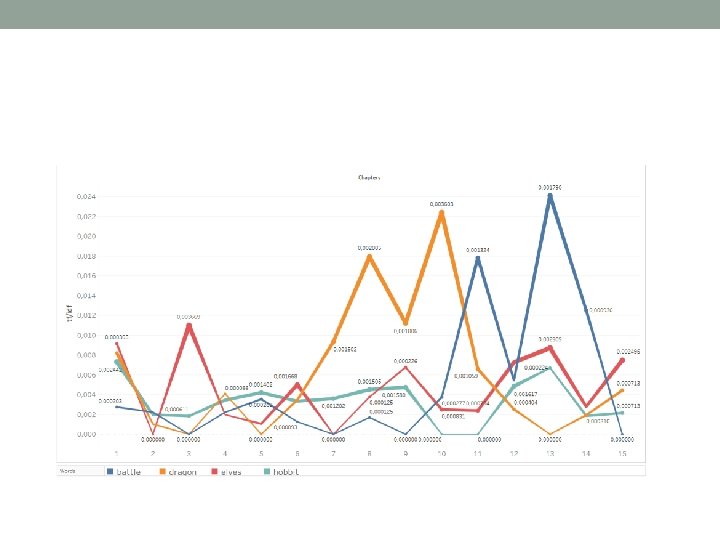
Un esempio di Analisi • Fase 4: estrazione di nomi di personaggi e luoghi e calcolo del TF/IDF per le concordanze dei singoli personaggi
Un esempio di Analisi • Fase 4: estrazione di nomi di personaggi e luoghi e calcolo del TF/IDF per le concordanze dei singoli personaggi su di loro, qualsiasi fine abbiano fatto. Predoni e assassini, è questo che sono tutti. » <John. Snow> percepì un fruscio fra le rosse foglie sopra di lui. Due rami si ci accampiamo sulle rive e forse prendiamo anche qualche pesce. <John. Snow>, portami della carta, è ormai tempo che io scriva a maestro Aemon. » «Trova Tarly e provvedi a che questo parta subito» disse Mormont porgendo il messaggio a <John. Snow>. Poi emise un fischio. Il suo corvo scese in planata
Un esempio di Analisi • Fase 4: estrazione di nomi di personaggi e luoghi e calcolo del TF/IDF per le concordanze dei singoli personaggi
Un esempio di Analisi • Fase 4: estrazione di nomi di personaggi e luoghi e calcolo del TF/IDF per le concordanze dei singoli personaggi
Un esempio di Analisi • Fase 4: estrazione di nomi di personaggi e luoghi e calcolo del TF/IDF per le concordanze dei singoli personaggi
Altri Esempi
borsellino suo diressero scolando manina borsa estraeva coraggio somma lavoro appassionandosi boccale raccolse cautela inizio barile nuovo 6. 7214961766849655 3. 4154876523731406 3. 3607480883424827 3. 3607480883424827 2. 882922698399655 2. 6034127633906374
NLP basato su Regole ‘Berto e Maso si diressero verso il barile. Guglielmo stava scolando un altro boccale. Allora Bilbo raccolse tutto il suo coraggio e mise la manina nell’enorme tasca di Guglielmo. C’era dentro un borsellino, grande quanto una borsa, per Bilbo. « Eccoci qua! » pensò, appassionandosi al suo nuovo lavoro mentre estraeva con somma cautela il borsellino. « Questo sì che è un buon inizio! » . ’ • Dove si diressero Berto e Maso? • Che stava facendo Guglielmo? • Che azioni compie Bilbo?
I metodi Rule Based ‘Berto e Maso si diressero verso il barile’ 1. Dizionario Elettronico 1. Informazioni di tipo Sintattico e Semantico Berto, Nome + Nome Proprio + Maschile + Animato + Umano si diressero, dirigersi, Verbo + riflessivo + Movimento + pass. Remoto + 3ª p. plurale + Sogg. Animato + Destinazione barile, Nome + singolare + Oggetto + Maschile + Contenitore … 2. Una serie di istruzioni o REGOLE
I metodi Rule Based 1. 2. 3. 4. 5. R 1: Se F contiene ‘Dirigersi’, cerca $Soggetto$ Animato’ e $Destinazione’$ introdotta da preposizione; R 2: Se V 3ª pers. Plurale cerca $Soggetto$ al plurale o più soggetti coordinati; R 3: Scrivi: Agente = $Soggetto$; R 4: Scrivi: Azione = Movimento; R 5: Scrivi: Destinazione = $Destinazione$ Output: Agente = Berto e Maso; Azione = Movimento; Destinazione = Barile.
Riepilogo • Analisi mirate e altamente performanti (dal punto di vista dei risultati) • Maggior attenzione al Linguaggio e ai suoi fenomeni • Comprensione del testo più profonda • Dipendenti dalla lingua, dal topic, dal dominio e dal Task • Mole di lavoro previo su Dizionari e Grammatiche • Computazionalmente inefficiente
Modello Ibrido • I modelli Rule-Based non devono necessariamente essere contrapposti ai modelli Stocastici e al machine learning • È possibile lavorare in sinergia sfruttando la velocità del Machine Learning e la precisione delle regole • Nella quasi totalità dei casi il Question Answering viene effettuato addestrando un algoritmo su un training set di domande e risposte compilato da un operatore umano • Se l’algoritmo deve affrontare una domanda nuova cerca di associarla ad una conosciuta in base al calcolo della similarità e offre una risposta scelta in base ad un calcolo probabilistico • È possibile utilizzare un modello Rule-Based per effettuare operazioni più precise?
Grazie per l’attenzione