Intel Xeon Processor E 5 2699 v 4















: remark #30521: (PAR) Loop at line 49 cannot be parallelized")

 { int i,")


 { int i,")


 { int")
 ((a)>(b)? (a):")








 SGI Altix UV (Ultra. Violoet) 2000 256")

 1, 024 Core Frequency 733 MHz Peak Performance")






- Slides: 51
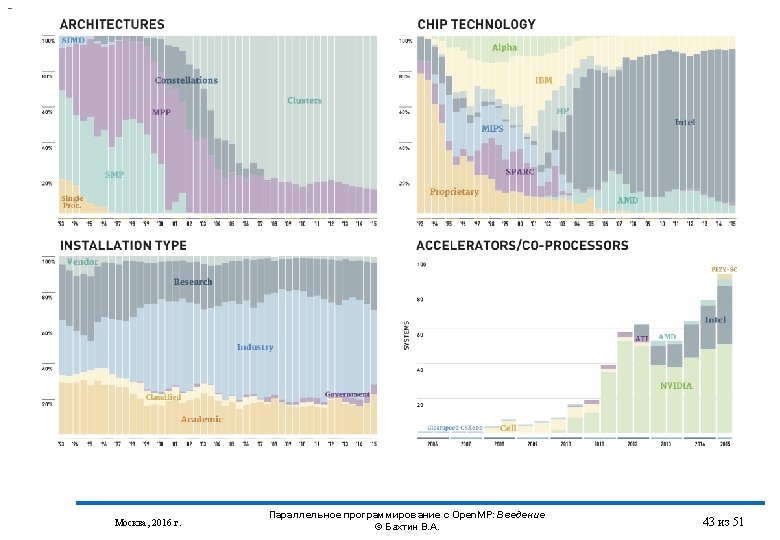
Тенденции развития современных процессоров Intel Xeon Processor серии E 5 -2699 v 4 (55 M Cache, 2. 20 GHz) 22 ядра, 44 нити E 5 -2698 v 4 (50 M Cache, 2. 20 GHz) 20 ядер, 40 нитей E 5 -2697 v 4 (45 M Cache, 2. 30 GHz) 18 ядер, 36 нитей E 5 -2697 A v 4 (40 M Cache, 2. 60 GHz) 16 ядер, 32 нити E 5 -2667 v 4 (25 M Cache, 3. 20 GHz) 8 ядер, 16 нитей Intel® Turbo Boost Intel® Hyper-Threading Intel® Intelligent Power Intel® Quick. Path Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 10 из 51
Тенденции развития современных процессоров Intel Core i 7 High End Desktop Processors i 7 -6950 X Extreme Edition (25 M Cache, up to 3. 50 GHz), 10 ядер, 20 нитей i 7 -6900 K Processor (20 M Cache, up to 3. 70 GHz), 8 ядер, 16 нитей i 7 -6850 K Processor (15 M Cache, up to 3. 80 GHz), 6 ядер, 12 нитей Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 11 из 51
Автоматизированное распараллеливание test. cpp(49): remark #30521: (PAR) Loop at line 49 cannot be parallelized due to conditional assignment(s) into the following variable(s): b. This loop will be parallelized if the variable(s) become unconditionally initialized at the top of every iteration. [VERIFY] Make sure that the value(s) of the variable(s) read in any iteration of the loop must have been written earlier in the same iteration. test. cpp(49): remark #30525: (PAR) If the trip count of the loop at line 49 is greater than 188, then use "#pragma loop count min(188)" to parallelize this loop. [VERIFY] Make sure that the loop has a minimum of 188 iterations. #pragma loop count min (188) for (i=0; i<n; i++) { b = A[i]; if (A[i] > 0) {A[i] = 1 / A[i]; } if (A[i] > 1) {A[i] += b; } } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 20 из 51
Вычисление числа с использованием Win 32 API #include <stdio. h> #include <windows. h> #define NUM_THREADS 2 CRITICAL_SECTION h. Critical. Section; double pi = 0. 0; int n =100000; void main () { int i, thread. Arg[NUM_THREADS]; DWORD thread. ID; HANDLE thread. Handles[NUM_THREADS]; for(i=0; i<NUM_THREADS; i++) thread. Arg[i] = i+1; Initialize. Critical. Section(&h. Critical. Section); for (i=0; i<NUM_THREADS; i++) thread. Handles[i] = Create. Thread(0, 0, (LPTHREAD_START_ROUTINE) Pi, &thread. Arg[i], 0, &thread. ID); Wait. For. Multiple. Objects(NUM_THREADS, thread. Handles, TRUE, INFINITE); printf("pi is approximately %. 16 f”, pi); } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 21 из 51
Вычисление числа с использованием Win 32 API void Pi (void *arg) { int i, start; double h, sum, x; h = 1. 0 / (double) n; sum = 0. 0; start = *(int *) arg; for (i=start; i<= n; i=i+NUM_THREADS) { x = h * ((double)i - 0. 5); sum += (4. 0 / (1. 0 + x*x)); } Enter. Critical. Section(&h. Critical. Section); pi += h * sum; Leave. Critical. Section(&h. Critical. Section); } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 22 из 51
Вычисление числа с использованием POSIX Threads #include <pthread. h> #define NUM_THREADS 2 pthread_mutex_t mutex. Reduction; double pi = 0. 0; int n =100000; void main () { int i, thread. Arg[NUM_THREADS]; pthread_t thread. Handles[NUM_THREADS]; pthread_mutex_init (&mutex. Reduction, NULL); for (i=0; i<NUM_THREADS; i++) { thread. Arg[i] = i+1; if (pthread_create(&thread. Handles [i], NULL, Pi, &thread. Arg[i]) != 0) return EXIT_FAILURE; } for (i=0; i<NUM_THREADS; i++) { if (pthread_join(&thread. Handles [i], NULL) != 0) return EXIT_FAILURE; } pthread_mutex_destroy(&mutex. Reduction ); printf("pi is approximately %. 16 f”, pi); } Параллельное программирование с Open. MP: Введение Москва, 2016 г. © Бахтин В. А. 24 из 51
Вычисление числа с использованием POSIX Threads static void *Pi (void *arg) { int i, start; double h, sum, x; h = 1. 0 / (double) n; sum = 0. 0; start = *(int *) arg; for (i=start; i<= n; i=i+NUM_THREADS) { x = h * ((double)i - 0. 5); sum += (4. 0 / (1. 0 + x*x)); } pthread_mutex_lock(&mutex. Reduction); pi += h * sum; pthread_mutex_unlock(&mutex. Reduction); return NULL; } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 25 из 51
Вычисление числа с использованием MPI #include "mpi. h" #include <stdio. h> int main (int argc, char *argv[]) { int n =100000, myid, numprocs, i; double mypi, h, sum, x; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid); h = 1. 0 / (double) n; sum = 0. 0; Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 26 из 51
Вычисление числа с использованием MPI for (i = myid + 1; i <= n; i += numprocs) { x = h * ((double)i - 0. 5); sum += (4. 0 / (1. 0 + x*x)); } mypi = h * sum; MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if (myid == 0) printf("pi is approximately %. 16 f”, pi); MPI_Finalize(); return 0; } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 27 из 51
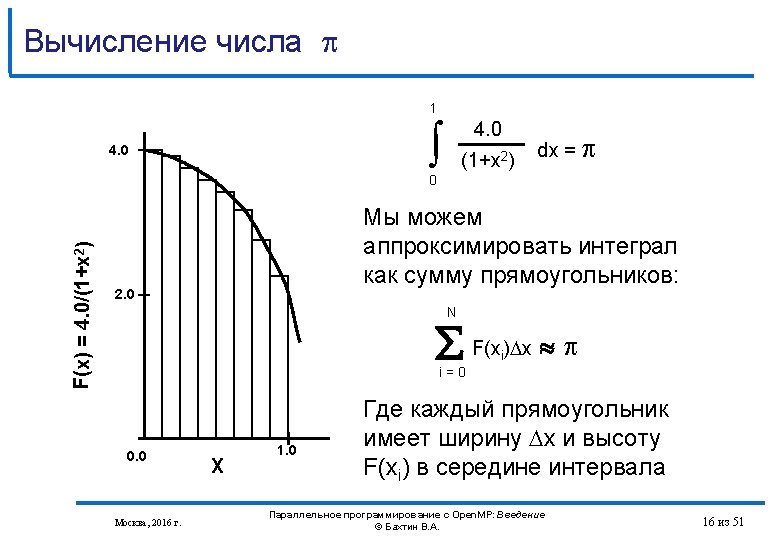
Вычисление числа c использованием Open. MP #include <stdio. h> int main () { int n =100000, i; double pi, h, sum, x; h = 1. 0 / (double) n; sum = 0. 0; #pragma omp parallel for reduction(+: sum) private(x) for (i = 1; i <= n; i ++) { x = h * ((double)i - 0. 5); sum += (4. 0 / (1. 0 + x*x)); } pi = h * sum; printf("pi is approximately %. 16 f”, pi); return 0; } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 28 из 51
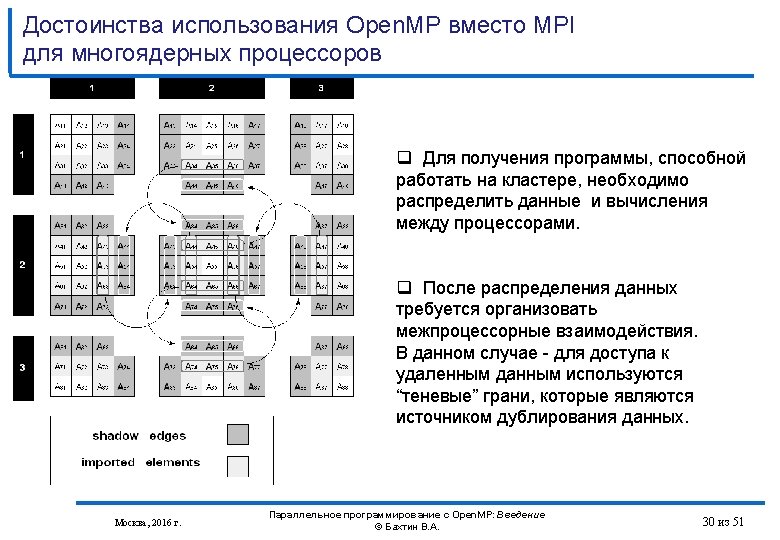
Достоинства использования Open. MP вместо MPI для многоядерных процессоров #define Max(a, b) ((a)>(b)? (a): (b)) #define L 8 #define ITMAX 20 int i, j, it, k; double eps, MAXEPS = 0. 5; double A[L][L], B[L][L]; int main(int an, char **as) { for (it=1; it < ITMAX; it++) { eps= 0. ; for(i=1; j<=L-2; j++) for(j=1; j<=L-2; j++) {eps = Max(fabs(B[i][j]-A[i][j]), eps); A[i][j] = B[i][j]; } for(i=1; j<=L-2; j++) for(j=1; j<=L-2; j++) B[i][j] = (A[i-1][j]+A[i+1][j]+A[i][j-1]+A[i][j+1])/4. ; printf( "it=%4 i eps=%fn", it, eps); if (eps < MAXEPS) break; } } Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 29 из 51
Тесты NAS Analyzing the Effect of Different Programming Models Upon Performance and Memory Usage on Cray XT 5 Platforms https: //www. nersc. gov/assets/NERSC-Staff-Publications/2010/Cug 2010 Shan. pdf Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 32 из 51
Тесты NAS Analyzing the Effect of Different Programming Models Upon Performance and Memory Usage on Cray XT 5 Platforms https: //www. nersc. gov/assets/NERSC-Staff-Publications/2010/Cug 2010 Shan. pdf Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 33 из 51
История Open. MP 1998 2002 2005 Open. MP C/C++ 2. 0 Open. MP C/C++ 1. 0 1997 Open. MP F/C/C++ 3. 0 Open. MP Fortran 1. 1 1999 Москва, 2016 г. 2011 2013 2015 Open. MP F/C/C++ 4. 5 Open. MP F/C/C++ 2. 5 Open. MP Fortran 1. 0 2008 Open. MP Fortran 2. 0 Параллельное программирование с Open. MP: Введение © Бахтин В. А. Open. MP F/C/C++ 3. 1 Open. MP F/C/C++ 4. 0 35 из 51
Open. MP Architecture Review Board AMD ARM Cray Fujitsu HP IBM Intel Micron NEC NVIDIA Oracle Corporation Red Hat Texas Instrument Москва, 2016 г. ANL ASC/LLNL c. OMPunity EPCC LANL LBNL NASA ORNL RWTH Aachen University Texas Advanced Computing Center SNL- Sandia National Lab BSC - Barcelona Supercomputing Center University of Houston Параллельное программирование с Open. MP: Введение © Бахтин В. А. 36 из 51
Компиляторы, поддерживающие Open. MP 4. 5: GNU GCC 6. 1: Linux, Solaris, AIX, Mac. OSX, Windows, Free. BSD, Net. BSD, Open. BSD, Dragon. Fly BSD, HPUX, RTEMS Open. MP 4. 0: Intel 16. 0: Linux, Windows and Mac. OS Oracle Solaris Studio 12. 4: Linux and Solaris Open. MP 3. 1: Oracle Solaris Studio 12. 3: Linux and Solaris Cray: Cray XT series Linux environment LLVM: clang Linux and Mac. OS IBM 12. 1: Linux and AIX Предыдущие версии Open. MP: PGI 8. 0: Linux and Windows Path. Scale Lahey/Fujitsu Fortran 95 Microsoft Visual Studio 2008 C++ NAG Fortran Complier 6. 0 Open. UH Open. MP 3. 0: Absoft Pro Fortran. MP: 11. 1 Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 37 из 51
Обзор основных возможностей Open. MP C$OMP FLUSH Open. MP: API для написания #pragma omp critical многонитевых приложений C$OMP THREADPRIVATE(/ABC/) CALL OMP_SET_NUM_THREADS(10) • Множество директив компилятора, CALL OMP_TEST_LOCK(LCK) набор функции библиотеки системы поддержки, переменные окружения C$OMP MASTER CALL OMP_INIT_LOCK (LCK) C$OMP ATOMIC • Облегчает создание многонитиевых C$OMP SINGLE PRIVATE(X) SETENVпрограмм на Фортране, C и C++ OMP_SCHEDULE “STATIC, 4” • Обобщение опыта создания C$OMP PARALLEL DO ORDERED PRIVATE (A, B, C) C$OMP ORDERED параллельных программ для SMP и DSM систем за последние 20 лет C$OMP PARALLEL REDUCTION (+: A, B) C$OMP PARALLEL DO SHARED(A, B, C) C$OMP SECTIONS #pragma omp parallel for private(a, b) C$OMP PARALLEL COPYIN(/blk/) C$OMP DO LASTPRIVATE(XX) nthrds = OMP_GET_NUM_PROCS() Москва, 2016 г. C$OMP BARRIER omp_set_lock(lck) Параллельное программирование с Open. MP: Введение © Бахтин В. А. 38 из 51
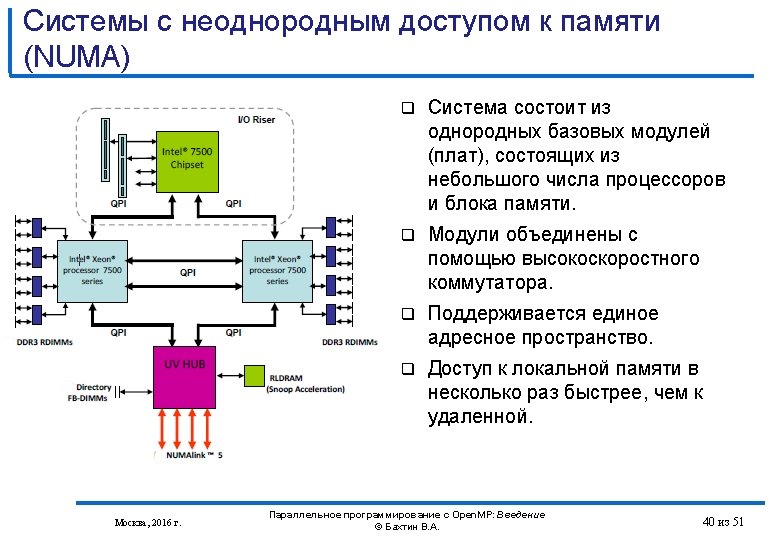
Системы с неоднородным доступом к памяти (NUMA) SGI Altix UV (Ultra. Violoet) 2000 256 Intel® Xeon® processor E 5 -4600 product family 2. 4 GHz-3. 3 GHz - 2048 Cores (4096 Threads) 64 TB памяти NUMAlink 6 (NL 6; 6. 7 GB/s bidirectional) http: //www. sgi. com/products/servers/uv/ Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 41 из 51
Pezy-SC Many Core Processor Logic Cores(PE) 1, 024 Core Frequency 733 MHz Peak Performance Floating Point Single 3. 0 TFlops / Double 1. 5 TFlops Host Interface PCI Express GEN 3. 0 x 8 Lane x 4 Port (x 16 bifurcation available) JESD 204 B Protocol support DRAM Interface DDR 4, DDR 3 combo 64 bit x 8 Port Max B/W 1533. 6 GB/s +Ultra WIDE IO SDRAM (2, 048 bit) x 2 Port Max B/W 102. 4 GB/s Control CPU ARM 926 2 core Process Node 28 nm Package Москва, 2016 г. FCBGA 47. 5 mm x 47. 5 mm, Ball Pitch 1 mm, 2, 112 pin Параллельное программирование с Open. MP: Введение © Бахтин В. А. 45 из 51
Литературa http: //www. openmp. org http: //www. compunity. org http: //www. parallel. ru/tech_dev/openmp. html Москва, 2016 г. Параллельное программирование с Open. MP: Введение © Бахтин В. А. 46 из 51