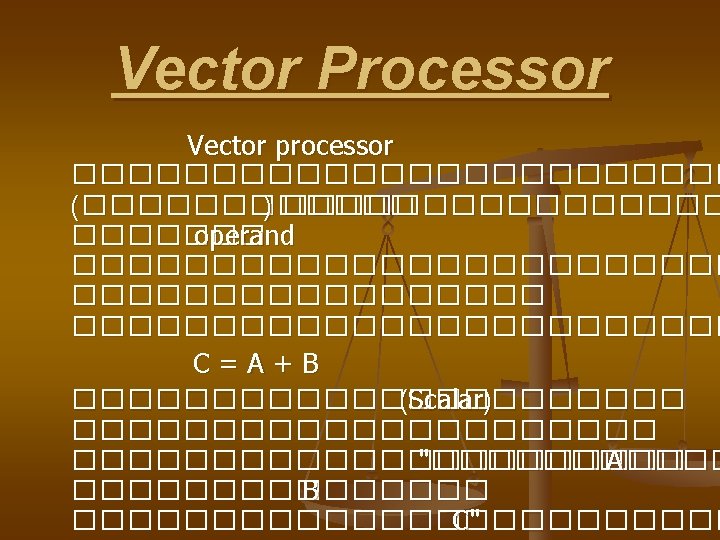
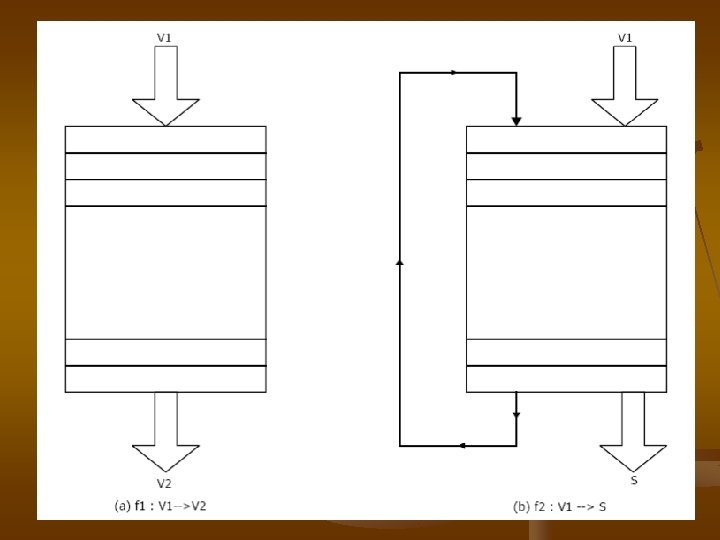
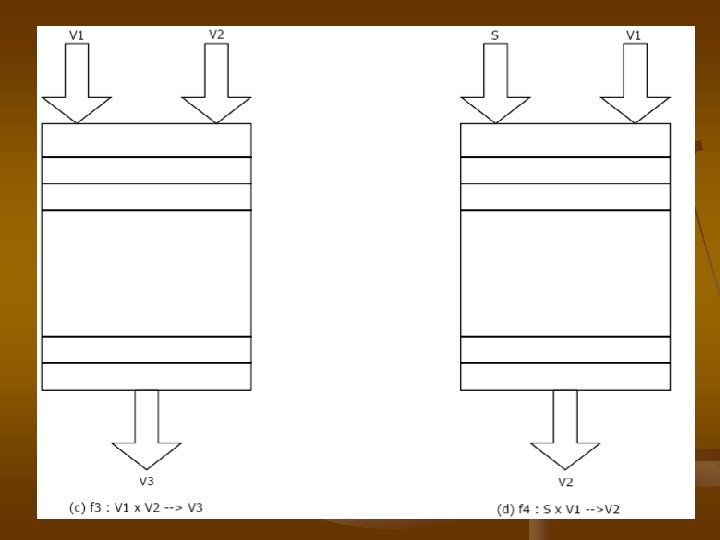
Vector Processor Vector Processor operand memorytomemory operand processor






































 The pipeline")


 ������� 1972. The control Processor ��� ASC ������ high")
 the memory buffer unit (MBU-Aupair) ������ �� central The")
 Central processor ���� continuous stream")





������� vector parameter ���������")







 ��� programmed input-output ( PIO )������ register �������")
























































! Invariant expression movement �� loop ��� vector operation �������� replaced ��� vector ����")



Reorder the execution sequence A A 2+A 3 A 1 A 2+A 3 A")
Temporary storage management ����� ��� optimization ��� vectorizing compiler ������� intermedate vector ������������ execute")
Code avoidance ������ optimization ��� vector operation �������� copy optimizatiion ��������������� copy arry ����������")

 Turning for interaction ��������������� user interaction �� vectorization Cray 1 ��� VP-200 ����������")




 Array")



















- Slides: 166
Vector Processor
Vector Processor ���������� operand ����� memory-tomemory, operand ���������� processor ������������������ register-to-register, operand
Memory-tomemory Vector Processor
���������� memory-to-memory ���������� Advance Scientific Computer ��� Texas Instruments Inc, ������� Cyber 200 ��� Control Data Corp ����� ETA-10 ��� ETA Systems Inc �������� Control Data Corp ����������� 1970 s ���������� 1980 s ����������� startup
Register-toregister Vector Processor
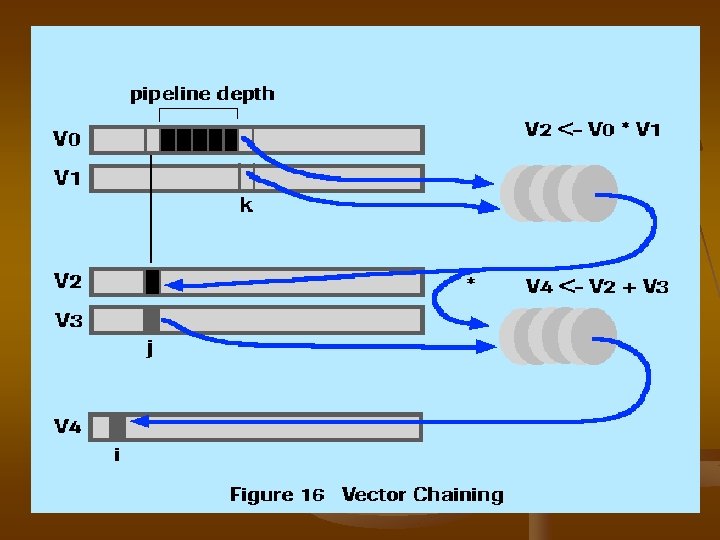
Cary Supercomputer & Vector Chaining
1. Vector Processing Requirement
1. 1 Characteristics of Vector Processing
Table 1 Some Representative Vector Instructions
���������� Vector Processor ������� Pipeline ������� Vector��� Field ����� n n n !. 1 Operation Code ������������ function ������ operation !. 2 Vector register �������� memory !. 3 Address increment !. 4 Address effect ������� base address ��� effect �������� memory �������� offset ������ + ��� – !. 5 Vector length ���
Vector-length register �������� Vector operation �� Vector processing ��� Pipeline Overhead ��� pipeline processing �������� setup time ����������� operands ��� functional units overhead ����� Flushing time ���� decoding ����� Vector ������������ pipeline Flushing time ������� Vector ��� Scalar processing ������ Vector pipeline ����� Check ����������� Vector ����������� process ���� Vector �������
n Enrich set the vector instruction Instruction set ����� process ������� access memory ������ instruction ��������� n Combine scalar instruction
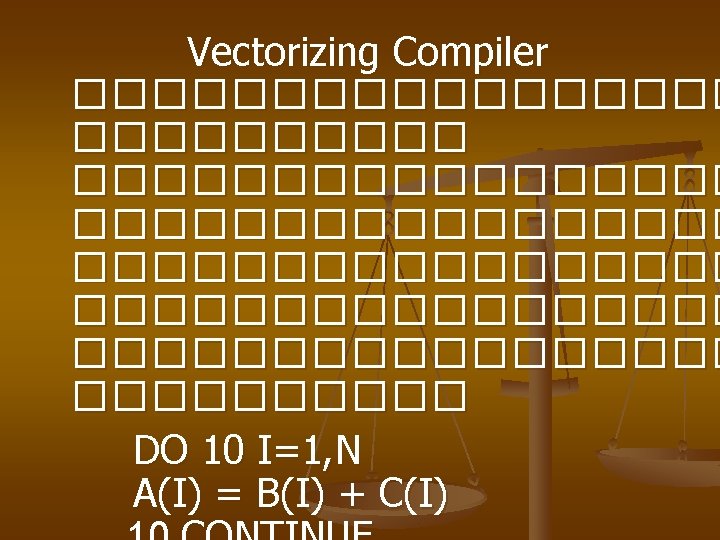
n Choose suitable algorithms �������� Algorithm ����������� processor ����������� pipeline processor n Use a vectorizing compiler Compiler ���������� Vector instruction ������ Vectorizing compiler ������� sequential ������ parallelism
��� 4 ������������� Parallelism �� advanced programming n n Parallel algorithm (A( High-level languages (L( Efficient object code (O( Target machine code (M( Degree ��� parallelism ������������������������ suitable algorithm ��� high parallelism ������� large-scale matrix ������� parallel language ������ highlevel language �������� parallel language �������� User
1. 2 Multiple Vector Task Dispatching
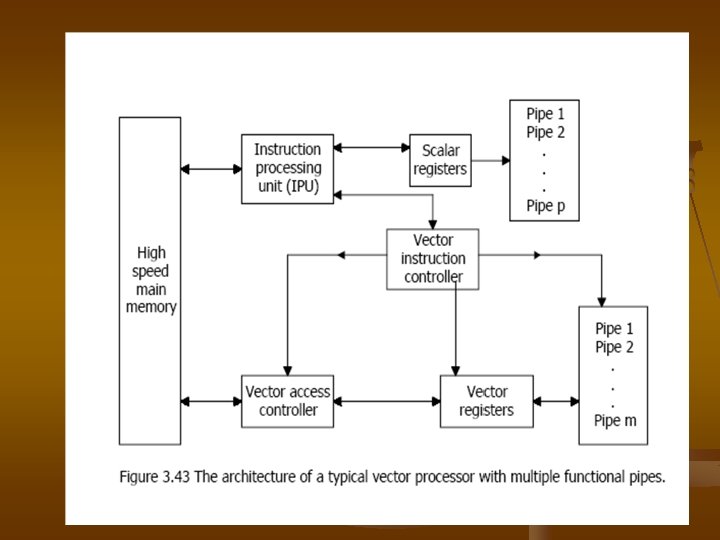
1. 2 Multiple Vector Task Dispatching �������� Parallel ������ multi-pipeline Vector processor ���������� Vector supercomputer ��� 3. 43 ����������� Vector processor main memory ������������ access ������������ Vector ���� scalar Formats Instruction processing unit (IPU) fetch ��� decode���� scalar ����� Vector ������� scalar processor
Figure 3. 42 Parallelism regeneration in using a vectorizing compiler for programs writen in sequential language
�������� Vector ����� IPU Vector instruction controller ������� execution function ��������� Vector ������ address ��� effective Vector-operand , setting up Vector access controller ��� Vector processor ���������� Vector ������������ machine vector access controller ������� fetch vector operand������
1. 3 Pipelined Vector processing Methods
1. 3 Pipelined Vector processing Methods ����������� Process vector ��� 3 ���� n !. 1 Horizontal processing ���������� >��� ����� row ������� Vector Y ��������� Yi ��� i. . m ����� YI = ÓNj=1 Zij Ta (horizontal) = (mn + 14 m)r ���������� scalar pipeline processor speed up ���
n n !. 2 Vector processing ������� carried out ������� calumn !. 3 Vector looping ������� ->��� �������� Horizontal
2. early vector processor
2. 1 Architecture of star-100 and IT-ASC
2. 1 Architecture of star-100 and IT-ASC ����������� 2 �������. control data corporation ������� star ���� 1965 ������� 1973 ������� a four million byte eight million optional ������������ stan-alone operations ������� star-100 ����� stream processor, virtualaddressing, hardware misroinstructions, semiconductor memoryregisterfile ��� pipelined floating-point arithmetic. ������� the star �� cycle time 1. 28 us ���� 32
The star-100 ��� arithmetic pipelines ���� 2 ������� �� (��� 4. 5) The pipeline processor ����� 64 bit floating point henceforth FLP ����� unit ��� 32 bit FLP multiply unit. pipeline ������� 4 ��������� The exponent compare ������������ The exponent ��������� The shifted ��� unshifted ��������� ��� The exponent ���������� normalized ���� transmit ������������ upper or lower half of sum ������� function ��������� data bus ���������� output ������ input ������� receive ������
����� hardware ������������ 64 bits ������� pipeline ���� 2 ������ 32 bit ������ (32 bit) arithmetic ��������� The 32 bit multiply pipeline ���������� multiplier recording logic, multiplicand-getting network ��� severol levels of carry-save address ������ multiplication processor number 2 ��� 4. 6 b ����� pipline add unit , a non pipelined devide unit, a pipeline multi punpose unit ��� some pipelined merge unit ���� pipeline. o processornumber 2 ������ processor number. The multipurpose pipeline �� 24 ������������� , root , ������ arrrrithmetic logic operetion ����� The regiater devide unit ��� nonpipelined
The star-100 �� 130 scalar instructions ��� 65 vector instructions ����������� Table 4. 1 Vectors �� the star -100 ������������ 2 �������� arrays ��� 32 -bit ���� 64 -bit FLP numbers The sparse vector instructions ������ sparse vectors ����� pipeline ������ streamng operations ������������ 40 ns ������������ input --> output ����� pipeline ��� FLP ��� 160 ns ������ 4 pipeline ������� FLP MULTIPLE PIPELINE ���� = 320 ns ������� CPU spreed ������ ,
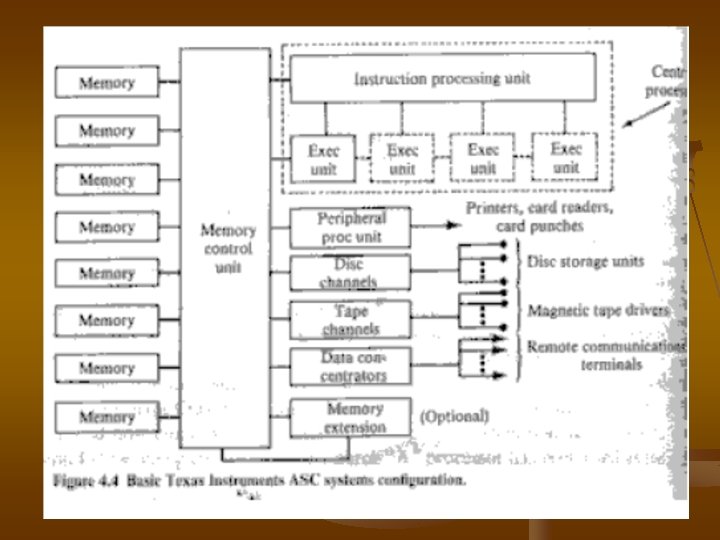
Texas Instrunent Advanced Scientific Computer(ASC) ������� 1972. The control Processor ��� ASC ������ high degree of pipelining �� instruction ��� arimetic level. ����������� ASC ����� ��� 4. 4 The central processing unit ����� the operating system. ���� disk ������� tape ��������� ��� storage unit . Data concentretors ������������ inter active terminal ������������ 8 �������� 1��� 160 ns ��� world lenght = 32 bit. 8 ������ one memory. The memory control unit ������������ a memory buses
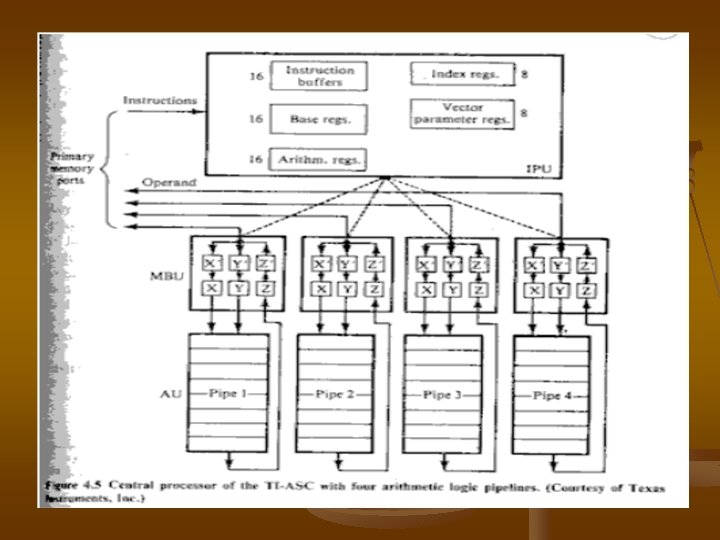
The central processor unit (IPU) the memory buffer unit (MBU-Aupair) ������ �� central The ASC central processor ��� instruction type ������ list ����� table 4. 3 ��������� ASC/arimetic pipeline ����� table 4. 4 ��������� 0. 6 ��� 1. 5 magaflops ��� 3 ��� 10 megaflop ��� pipeline
The primary functions ��� IPU ����������� (function �������� ) Central processor ���� continuous stream of instructions ������� the IPU ��� pipeline������� 48 program address ������������ operand address. Instructions ��������� octette (8 word ) ������� IPU ������� instruction ����� MBUAU���������� arithmetic pipeline The MBU ������������ arithmetic pipeline ������������ MBU ������ arithmetic unit ���� continubus strems of operands The MBU ������� 8 ����� X ����� Y ������� input �������
2. 2 Vector Procssing �� Streamins Mode
2. 2 Vector Procssing �� Streamins Mode continous streamins ����� The high bandwidth inter leaved memories ����� mutiple pipeline ����� stars ������������������������ vector mode ���� maxtrix multiplicetion , polynomial evaluction ���������� star ������������������������ The Fortren compiler �� star ����� Ton ����� Fortren ����� TON ������������ Fortren ����� Assemble �������
����������� C+1 TON The effective staring address ��������� The effective field lengh ����������� field lengh ������� the ending address ���� The effective staring address ��� The effective field lengh ����������� th bu ������ operand ����������� ( I +d )th �������� operand ����� d
. 1 The reading of address ������� (�� stream unit )������� vector parameter ��������� n. 2����� the effective addresses ��� field lenght ���������� vectoroperations n. 3����� bs read – write bus ����� G(sub – func) ������� operand ��� result n
3. Sciencetific Attached Processor
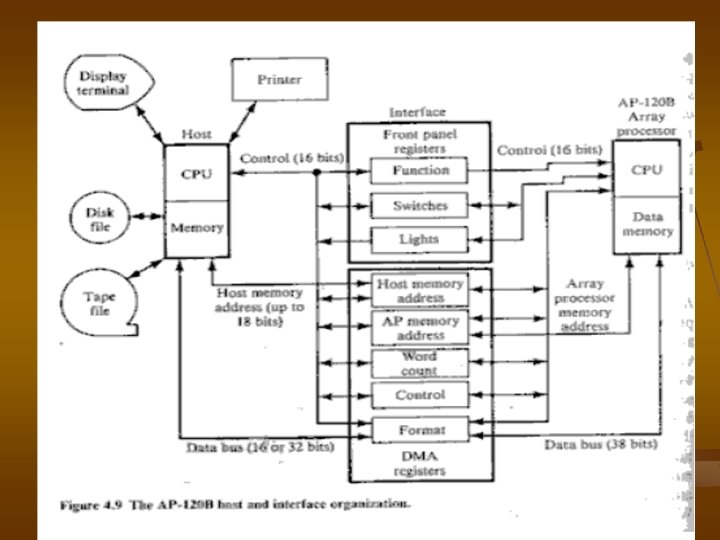
. 3 Sciencetific Attached Processor Attached Prcessor ������������������� AP-120 B ��� FPS -164 ���� back-end ���������� Vector ���� Arrays(Matrices) ����������
����������� direcmemory access ( DMA ) ��� programmed input-output ( PIO )������ register ������� 2 ���� �� interface unit ����� 1 ���� function ������� I/O ��� interface unit ������ array processor ��� simulate front panel ��� host ����� switches register ������ host ������ ��������� ��� Addresses �� array processor light register �������� array processor ��� function register �������
DMA register set ����� host ����� memory address register AP memory register , word count register , control register , format register ����������� mode �������� format register ������ FLP format ��� host ������ AP-120 B Interface logic ����������� host ���� AP-120 B ����������� AP-120 B ��� 38 bits ������� 2 ‘s complement 28 bits ������� 10 bits biased by 512 ��������������������� 32 bits ��� host ����������
����� function ��� AP 120 B ������� 4. 10 processor �������� 6 ���� I/O section , memory section , control memory , control unit, data bus ��� arithmetic 2 ����� memory ����� data memory( MD), table memory ( TM ) ��� 2 datapads ( DPX and DPY) control memory ���� program memory ������ 64 bit words ��� 50 ns ycle time program memory ����� 4 K words in 256 word Instruction register ���� fetch , ecoded ��� executed ������ control unit
S pad �� control unit �� 2 ���� S-pad memory ��� integer ALU S-pad memory����� 16 directly address ��� register ������ address ALU ����� operand address ������� address ALU ����������� 16 bit �������� address ALU ������ register , MA ������� data memory , TMA ������� table memory ��� DPA ������� data pads ������ � ��� address ALU ������� clear , increment , decrement , logical ,
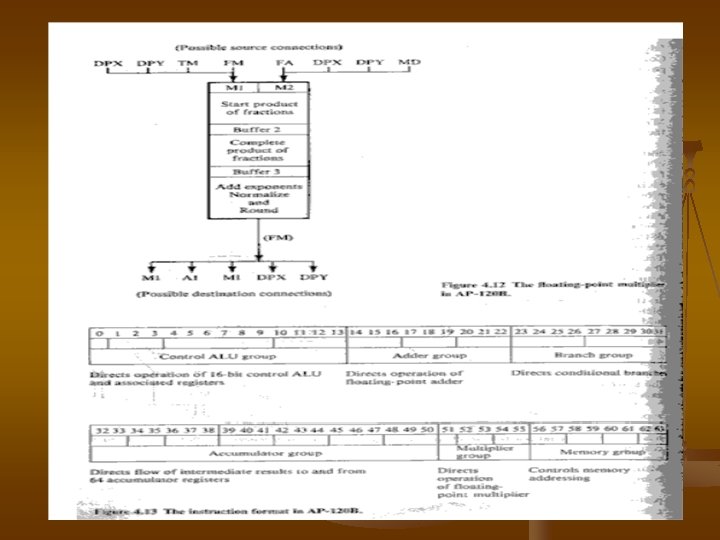
FA����� 2 input register ��� A 1 ��� A 2 ��� two-segment pipeline ������� 4. 11 ���� output ��� 38 bit �������� ��� FM �� M 1 ��� M 2 input register ��� threesegmentpipeline ������������� machine cycle ��� 167 ns ����� maximum through put rate ����� AP-120 B ���� 12 mega floatingpoint ������� AP-120 B ������������ ��� sections ��� processor ������ 2 pipeline arithmetic unit ( FA and FM ) 1 integer ALU , memory ������� ( PM, MD, TM ) ������������
two floating-point arithmetic units ��� FA ��� FM ������ 2 block ������ ��� accumulator ( DPX , DPY ) ���������� inhandling operands ��� intermediate ��������� block ������ vector operand ��� 16 components ���������� FA ��� FM ������ block ����
Seven buses �� AP-120 B ��������� parallel processing ��� FA ��� FM �� multibus input ports ������� �� words ���� � operands ���� � �������� moved ������� different function unit �� machine cycle ���� total data path banwidth �� math ��� execution speed ��� pipeline
���� � levels ��� pipeline �� AP 120 B �� �� described parallel function units ������ long instruction word ��� AP-120 B ����� 64 bits ����� �� 10 command fields ( ��� 4. 13 ) ����� command field ���� specific unit ���� single AP-120 B instruction ��������� 10 operations ��� machine cycle ����� 4. 13 multiple memory access register transfer , interger arithmetic ��� floating-point computations ����������� multiple memories multiple functional units parallel data path ��� multiple command
3. 2 Back-End Vector Computation
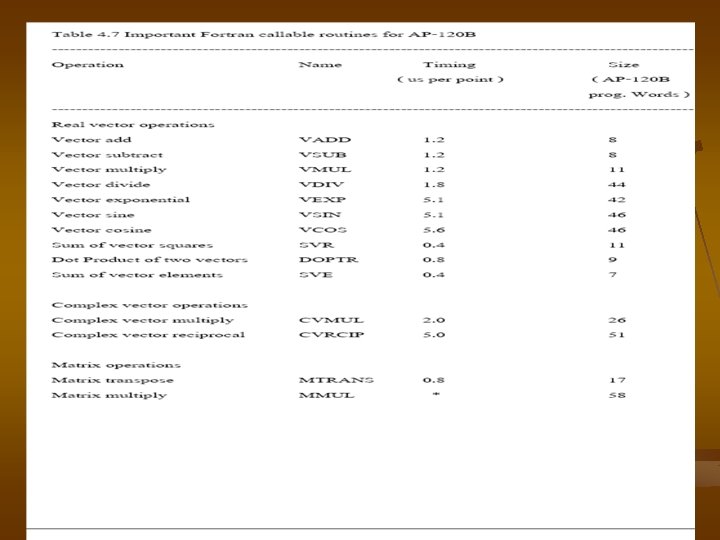
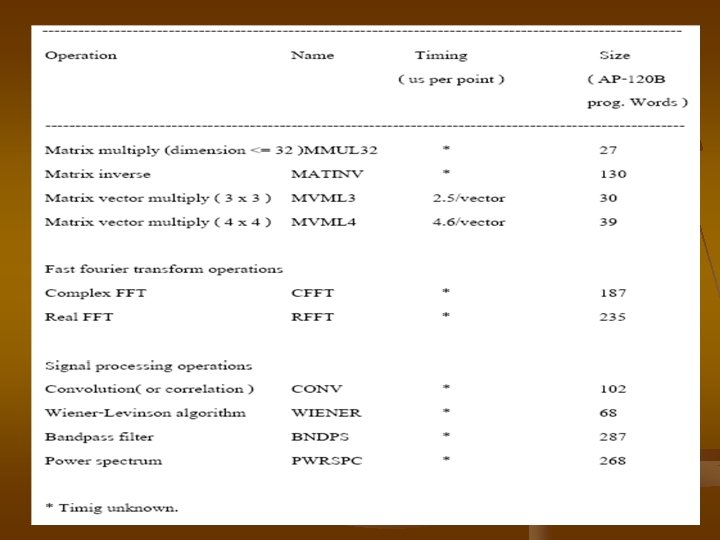
3. 2 Back-End Vector Computation ������� AP-120 B ����� vector supercomputers ���� vector instruction ����� long instruction ����� microoperations ������ parallel software ������� 200 packages ���������� vector ��������� mathematicallibraly vector-processing routine ���� Fortran callable ��� host computer ������� calls are handled ��� array processor executive ( APEX ) soft ware ��� decodes
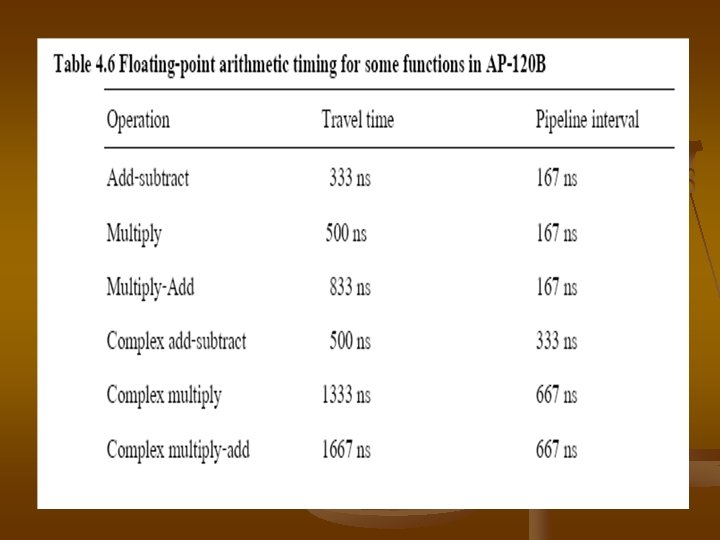
��� automatically passes ������ parameter ����� AP-120 B �� return ������� host computer ������������ add new ���� special routines ����� mathematics libraly �� Fortran ���� �� AP assembly languagecode ��� program ����������� In addition ���� signal processinglibraly dedicated ����� dagital signal processing application ����� Fortran callable routines �� libraries �������� 4. 6 ��� time measured �� microsecond ��� program
�� AP-120 B ��������� floating-point adder ��������������� ������� n n n !. 1 A 1 + A 2 !. 2 A 1 – A 2 !. 3 A 2 – A 1 !. 4 A 1 EQV A 2 !. 5 A 1 AND A 2 !. 6 A or A 2 !. 7 Convert A 2 from signed magnitude to 2’s complement format !. 8 Convert A 2 from 2’s complement to signed magnitude format !. 9 Scale A 2 !. 10 Absolute value of A 2 !. 11 Fix A 2
floating-point �� AP-120 B �������� 4. 7 ��� travel time ����������� transfer ����� source ����� destination ��� pipeline interval ������� successively avaliable result pipline interval ������ maximum throughput rate ������� vector oriented computations ��������� vector processing in the AP-120 B �������� semicolon “ ; ” ����� parallel operations ������ comma “ , “ ����� operands doubleslash “ // “ ����
AP-120 B ������� extensively �� field ��� digital-signal processing ��� execute ����� fast Fourier transform ( FFT ) �� AP-120 B ����� FFT program ����� program memory ��� AP 120 B array ������ transformed�� main memory ��� host computer FFT compution ������ step ������ n n !. 1 The host computer issues an I/O instruction to initiate the FFT program in the AP-120 B !. 2 The AP-120 B request host DMA cycles to transfer the array of data from host memory to data memory in the AP 120 B. the floating-point format is converted during the flow of data through the interface unit !. 3 The FFT computations are performed over a 38 -bit floating-point dataarray. !. 4 The AP-120 B requests the host DMA cycles to return the results of the FFT frequency-domain coefficients array.
FPS-164, IBM 3838 AND DATAWEST MATP
4 Vector Processor in Cyber-205 and CDF-NASF
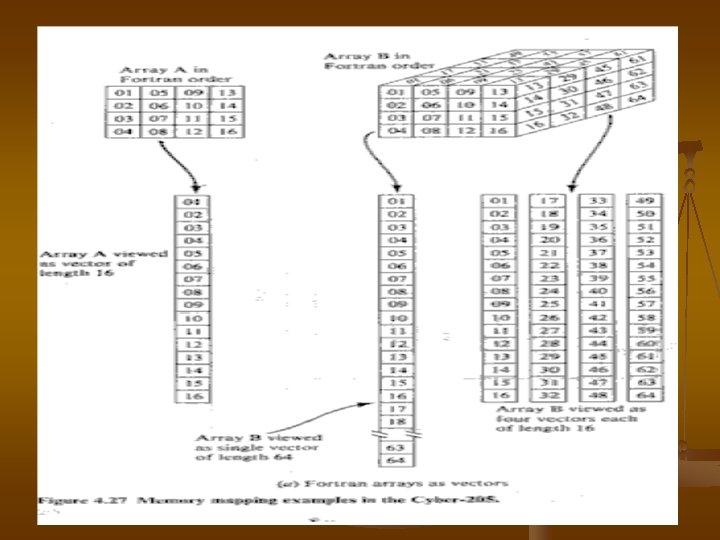
4 Vector Processor in Cyber-205 and CDFNASF �� section ������������ �� Cyber-205 �������������������� vector pipeline ��������� memory mapping�� Cyber-205 ��������� bit vectors ������� vector processing ������ Cyber-205 ����������� I/O configuration �� Cyber-205
4. 1 Fujitsu VP-200 and Special Features
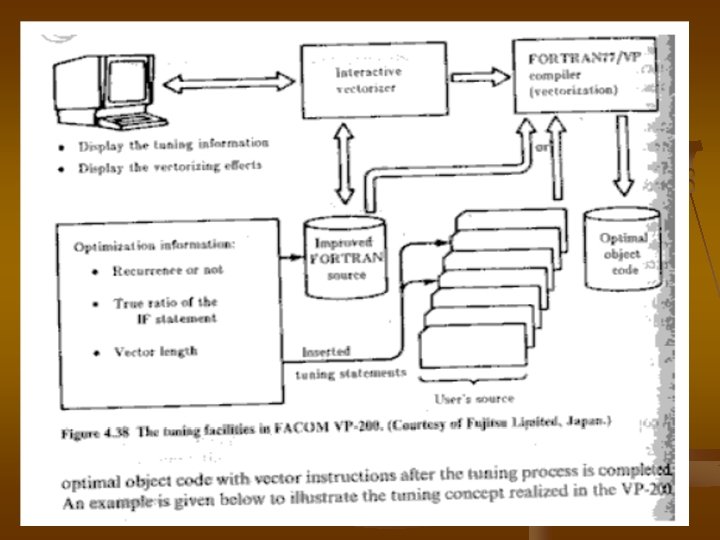
4. 1 Fujitsu VP-200 and Special Features ������ Fujitsu ������ FACOM vector processors VP 200 ������� �� 1982 ������������ ��������� LSI, ������������ , compiler �������������� hardware ��� software ��������� a loosely coupled back-end system. The block diagram ��� the VP-200 �����
�������� the vector register via two load-store pipelines. ������� the two load-store pipes ���� bandwidth ��� 267 M �������������������� ��������� the arithmetic pipes. �� 4 �������������� vector processor���������� vector ����� bit strings, 32 bit fixpoint, ��� 32
Vectorizing complir-Fortran 77/vp A vectorizing compiler, Fortran 77/VP, ������� the FACOM vector processor. Fortran 77 ������������ machine ��������� software ������������ ������� high vectorization ������������ , The Fortran 77/VP compiler vectorrize ������ the simple DO
Conditional vector operations ������������ ������������ ��� DO loops. The FACOM vector processor ��� 3 ������������������������� vector: masked arithmetic operations, compressexpand functions, ��� vector indirect addressing. ������������������������ vector, bit strings(���� mask vectors)
5. VECTORIZATION AND OPTIMIZATION METHODS
5. 1 Parallel language for vector processing
5. 2 Design of a Vectorizing Compiler
5. 2 Design of a Vectorizing Compiler vectorizing compiler �������� stetement �� loop Do ������������ execute object code ��� vector insturction ����������� vectorization �� ������������ compiler vectorizes ��� access ������������
5. 3 Optimization of Vector Function
5. 3 Optimization of Vector Function ������ 9 �������� vector function �������������� apply ������ (a)! Redunddant expression elimination ������������������������ intermedate code ������������ memory access ��� executiontiom ���� (b)!Constant folding at compile time constant folding ���������� runtime �� compile time ������� operation �� array ���������� �� loop Do ��� array ������� A(I)=I for I=1, 2, 3, . . , 100 ���������
(c)! Invariant expression movement �� loop ��� vector operation �������� replaced ��� vector ���� data ��� statement ��� loop-variant, loop-invariant expression ����� loop ��������� “ code motion “ ���� loop two-level DO 20 I = 1, n. . . DO 20 J=1, m. . . B(I, J)=B(I, J) +A(J)*C(J) 20 CONTINUE (d)!Pipeline chianing and parallelization �� vector processor ��� multiple functional pipe , ������ update ��� chianing several pipelines ����� 1 pipeline �� directinput ��� pipeline �������� stroring ����� thus
���� A-B*C ������ executed �� Cray-1 ����� vector register 3 ��� V 1, V 2, V 3 V 1 A V 2 B V 3 C V 2*V 3 V 1 -V 2 ������� looding vector A �� register ������� 2 vector register ���� V 1 B V 2 C V 1*V 2 A V 2 -V 1
(f)Reorder the execution sequence A A 2+A 3 A 1 A 2+A 3 A 4 A 5*A 6 B 1 A 7+A 8 --" B 5 C 1+C 2 B 3*B 4 A 5*A 6 B 5 C 1+C 2 B 2 !B 3*B 4 ���������������� pipeline 3 ������� ��� 1 ������ compiler���� �� reorder execute sequence ������ require pipeline �������
(g)Temporary storage management ����� ��� optimization ��� vectorizing compiler ������� intermedate vector ������������ execute ����� vector �� cray-1 A(1: 4000)=A(1: 4000)*B(1: 4000)+C(1: 4000) ������� vector register 63 ��� 64 component ��������������� intermedate �������
(h)Code avoidance ������ optimization ��� vector operation �������� copy optimizatiion ��������������� copy arry ���������� arry����� copy ������� code sequence A(1: 50)=B(1: 99: 2) …. …. C(1: 50)=2. 0*A(1: 50)
��� compiler adjusts storage-mapping function ������� array A ������� storage ������� array B V 1! B(1: 99: 2) A(1: 50)! V 1 … … V 1! A(1: 50) V 1! 2. 0*V 1 C(1: 50)! V 1; ����� V 1! B(1: 99: 2) V 1! 2. 0*V 1 C(1: 50)! V 1;
(i) Turning for interaction ��������������� user interaction �� vectorization Cray 1 ��� VP-200 ���������� VP��������� 200 ��� display ������������ ��� vectorizing effect ��� user ������ modify source program �� optimized ����� vectorization ������� vectorizing compiler number ��� compiler directive line ������ check ����� source code, true ratio�� IF statement , vector
5. 4 Performance Evaluation of Pipeline Computer
5. 4 Performance Evaluation of Pipeline Computer �� section ���������� pipeline vector processor ���������� processor utilization ��� speedup ������� pipeline ����� pipeline rate , ��� Lood ������ utili. Zation rate ������� resources
����������� K: ����� storage �� function pipe T: ���� pipeline delay �� ������� execute Ni: ������ vector ������ (1<=I<=n) N: ���������� contained �� program W: throughput ��� pipeline computer Ti: ������� required �������� pipelinecomputer (1<=I<=n) Tp: ��������� required ����� task consisting ����� n Sk: speedup ��� pipeline computer |: ������� pipeline computer |: T/K
6. SIMD ARRAY PROCESSOR
6. SIMD ARRAY PROCESSOR ����������� array processor ������������ PE ��������� CU (Control Unit) Array Processor �������� single instruction ��� multiple data streams (SIMD) ������������ Vector �� Matrices �������� SIMD ������� 2 ������� Array processor ������� random-access ��� associative processors �������
6. 1 SIMD INTERCONNECTION NETWORKS
6. 1 SIMD INTERCONNECTION NETWORKS n n n n Interconection network �������� SIMD ������������ single-stage. recirculating network multistage SIMD network �����������. 1 The 1 lliac. 2 The flip network. 3 The n cube. 4 The Omega. 5 The data manipulator. 6 The barrel shifler. 7 Shuffle-exchange network
6. 2 Connection Issues for SIMD Processing
The spece fo SIMD computer n n n ����������� SIMD ������������ � 1983 ������� array processor �������� SIMD ������ random-access memory ������ associative processor ������ SIMD ������� associative ��������� SIMD ���� 5 ������ , ����� word-slice ����� bit-slice ������ Control Unit ��� Word-slice array processor Bit-slice array processor Word-slice associative processors
6. 3 Array and Associative Processors
6. 4 SIMD Computer Perspective
n n n n n �������������������������� Illiac-IV , The BSP, The MPP ������� STARAN Matrix algebra (Multiplication, decomposition and inversion( Matrix eigenvalue calculations Linear and integer programming General circulation weather modeling Beam forming and convolution Filter and fourier analysis Image processing and pattern recognition Wind-tuned experiments Automated map generation Real-time scene analysis