CS 177 Lecture 4 Sequence Alignment Tom Madej








")






)/λ • sij is the score for")




![Organizing the computation – dynamic programming table Align j Align[i, j] = i Align(Si,](https://slidetodoc.com/presentation_image_h/2bb60b7b08ce6a07ce6d78639f38469e/image-22.jpg "Organizing the computation – dynamic programming table Align j Align[i, j] = i Align(Si,")



; space O(nm) where n, m are")


")
 • Extremely fast, can be on the order")

. •")





. • Extend the")





 = exp(-e")






 phylogenetic tree for the sequences. • Construct the")


")
 • One column per residue in the query sequence.")

 the inclusion")

 at NCBI. • Contains alignments from Smart,")

- Slides: 60
CS 177 Lecture 4 Sequence Alignment Tom Madej 10. 04
Overview • • The alignment problem. Homology, divergence, convergence. Amino acid substitution matrices. Pairwise sequence alignment algorithms: dynamic programming, BLAST. Multiple sequence alignment. PSI-BLAST, position specific score matrices. Databases of multiple sequence alignments.
What is a sequence alignment? • A linear, one-to-one correspondence between some of the symbols in one sequence with some of the symbols in another sequence. • May be DNA or protein sequences. • A (sequence) alignment can also be derived from a superposition of two protein structures, it is then sometimes called a structure alignment.
Exercise! • From http: //www. ncbi. nlm. nih. gov/Structure/ go to the MMDB summary page for 1 npq. • Click on the colored bar for chain “A”. • Scroll down and select the VAST neighbor 1 KR 7 A. • Click on “View 3 D Structure” at the top to view the structural superposition using Cn 3 D. • The sequence alignment will be shown in a separate window.
Divergence and Convergence • Two proteins may be similar because of divergence from a common ancestor (i. e. they are homologous). • … or, perhaps two proteins may be similar because they perform similar functions and are thereby constrained, even though they arose independently (functional convergence hypothesis, they are then called analogous).
Divergence vs. Convergence • Convergence can occur; e. g. there exist enzymes with different overall structures but remarkably similar arrangements of active site residues to carry out a similar function. • So how can one establish homology?
Homology “… whenever statistically significant sequence or structural similarity between proteins or protein domains is observed, this is an indication of their divergent evolution from a common ancestor or, in other words, evidence of homology. ” E. V. Koonin and M. Y. Galperin, Sequence – Evolution – Function, Kluwer 2003
Two arguments… • We see a continuous range of sequence similarity. Convergence is extremely unlikely for highly similar protein families. It then appears implausible to invoke it for less similar families. • The same or very similar functions may be carried out by proteins with very different structures (folds). Therefore, functional constraints cannot force convergence of the sequence or structure between proteins.
Sequence identity for VAST neighbors of 1 NQP A (a globin)
Global and local alignment • Alignment programs may be modified, e. g. by scoring parameters, to produce global or local alignments. • Local alignments tend to be more useful, as it is highly possible that a significant similarity may encompass only a portion of one or both sequences being compared.
DNA and proteins • Much more sensitive comparison is possible between protein sequences than DNA sequences. • One reason is that the third codon in the genetic code is highly redundant, and introduces noise into DNA comparisons. • Another reason is that the physico-chemical properties of the amino acid residues provide information that is highly relevant to comparison.
Molecular Cell Biology, Lodish et al. Fig. 3 -2.
Molecular Cell Biology, Lodish et. al Fig. 3 -2.
We are faced with several problems… • How do you quantify amino acid similarity? • How can you handle gaps in the alignment? • How do you define the overall similarity score? • Can you compute an optimal alignment? • Can you compute an alignment efficiently? • Can you calculate statistical significance?
Amino acid substitution matrices • Ab initio approaches; e. g. assign scores based on number of mutations needed to transform one codon to another, or on other physico-chemical measures of a. a. similarity. • Empirical, i. e. derive statistics about a. a. substitutions from collections of alignments. (These work the best).
Computation of scores, empirical approach sij = ln(qij/(pipj))/λ • sij is the score for substituting amino acid type i by type j. • qij is the observed frequency of substitutions of a. a. type i by a. a. type j (in the training set). • pi is the background frequency for a. a. type i in the training set. • λ is a positive constant.
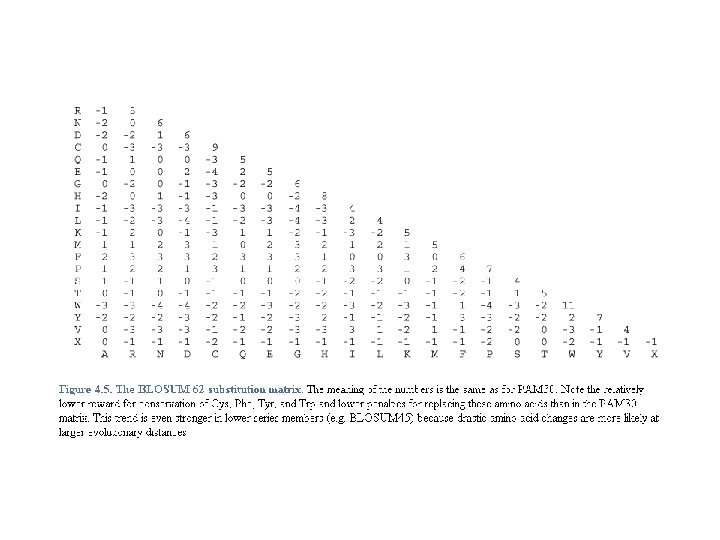
Substitution matrices • There are many different matrices available. • The most commonly used are the BLOSUM or PAM series. • BLAST defaults to the BLOSUM 62 matrix. The BLOSUM matrices have been shown to be more sensitive than the PAM matrices for database searches.
Gap penalties • There is no suitable theory for gap penalties. • The most common type of gap penalty is the affine gap penalty: g = a + bx, where a is the gap opening penalty, b is the gap extension penalty, and x is the number of gapped-out residues. • Typical values, e. g. a = 10 and b = 1 for BLAST.
Dynamic programming overview • Dynamic programming; a computer algorithmic technique invented in the 1940’s. • Has applications to many types of problems. • Key properties of problems solvable with DP: the optimal solution typically contains optimal solutions to subproblems, and only a “small” number of subproblems are needed for the optimal solution. (T. H. Cormen et al. , Introduction to Algorithms, Mc. Graw-Hill 1990).
Dynamic programming algorithm for computing the score of the optimal alignment For a sequence S = a 1, a 2, …, an let Sj = a 1, a 2, …, aj Align(Si, S’j) = the score of the highest scoring alignment between S 1 i, S 2 j S(ai, a’j)= similarity score between amino acids ai and a’j given by a scoring matrix like PAM, BLOSUM g – gap penalty { Align(Si, S’j)= max Align(Si-1, S’j-1)+ S(ai, a’j) Align(Si, S’j-1) - g Align(Si-1, S’j) - g
Organizing the computation – dynamic programming table Align j Align[i, j] = i Align(Si, S’j) = max { Align(Si-1, S’j-1)+ s(ai, a’j) Align(Si-1, S’j) - g Align(Si, S’j-1) - g +s(ai, aj) max
Example of DP computation with g = 0; match = 1; mismatch = 0 Maximal Common Subsequence initialization A A T G C T T A A C C A T T G C G C A T 0 0 0 0 1 1 1 0 1 2 2 2 2 0 1 2 2 3 0 1 0 1 +1 max
Example of DP computation with g = 2; match = 2; mismatch = -1 Initialization (penalty for starting with a gap) A A T G C T T A A C C A T T G 0 -2 -4 -6 -8 -2 2 0 -2 -4 -4 0 4 2 -6 -2 2 3 -8 -4 C -10 G C A T -12 -14 -16 -18 -20 -22 -10 -12 -14 -16 -18 +2 -20 -22 -2 -2 max
The iterative algorithm m = |S|; n = |S’| for i 0 to m do A[i, 0] - i * g for j 0 to n do A[0, j] - j * g for i 0 to m do for j 0 to n A[i, j] max ( A[i-1, j] – g A[i-1, j-1] + s(i, j) A[i, j-1] – g ) return(A[m, n])
Complexity of the DP algorithm • Time O(nm); space O(nm) where n, m are the lengths of the two sequences. • Space complexity can be reduced to O(n) by not storing the entries of dynamic programming table that are no longer needed for the computation (keep current row and the previous row only).
DP technicalities… • One uses a separate table to trace back the computation and determine the actual optimal alignment. • If the gap penalty has different opening and extension costs, then the algorithm becomes a little more complicated (cf. Chapter 3 in Mount).
Exercise! • Copy and paste the sequences for 1 nqp. A and 1 kr 7 A into a notepad. • Go to the web site: http: //pir. georgetown. edu • Select “SSearch Alignment” from the “Search and Retrieval” pulldown menu. • Copy in your sequences (use FASTA format and remove numbers) and then run SSEARCH (Smith-Waterman algorithm, a DP alignment method).
SSEARCH (pir. georgetown. edu)
BLAST (Basic Local Alignment Search Tool) • Extremely fast, can be on the order of 50 -100 times faster than Smith-Waterman. • Method of choice for database searches. • Statistical theory for significance of results. • Heuristic; does not guarantee optimal results. • Many variants, e. g. PHI-, PSI-, RPS-BLAST.
Why database searches? • Gene finding. • Assigning likely function to a gene. • Identifying regulatory elements. • Understanding genome evolution. • Assisting in sequence assembly. • Finding relations between genes.
Issues in database searches • Speed. • Relevance of the search results (selectivity). • Recovering all information of interest (sensitivity). – The results depend on the search parameters, e. g. gap penalty, scoring matrix. – Sometimes searches with more than one matrix should be performed.
Main idea of BLAST • Homologous sequences are likely to contain a short high scoring similarity region, a hit. Each hit gives a seed that BLAST tries to extend on both sides.
Some BLAST terminology word – substring of a sequence word pair – pair of words of the same length score of a word pair – score of the gapless alignment of the two words: VALMR V A K N S score = 4 + 4 – 2 - 1 = 3 (BLOSUM 62) HSP – high scoring word pair
Main steps of BLAST • Parameters: w = length of a hit; T = min. score of a hit (for proteins: w = 3, T = 13 (BLOSUM 62)). • Step 1: Given query sequence Q, compile the list of possible words which form with words in Q high scoring word pairs. • Step 2: Scan database for exact matching with the list of words compiled in step 1. • Step 3: Extend the hits from step 2. • Step 4: Evaluate significance of extended hits from step 3.
Step 1: Find high scoring words • For every word x of length w in Q make a list of words that when aligned to x score at least T. • Example: Let x = AIV then the score for AIA is 4+4+0 (dropped) and for AII 4+4+3 (taken). • The number of words in the list depends on w and T, and is usually much less than 203 (typically about 50).
Step 2 – Finding hits • Scan database for exact matching with the list of words compiled in step 1 : • Two techniques. – Hash table. – Keyword tree (there is a finite-automaton based method for exact matching with a set of patterns represented as a tree).
Step 3: Extending hits • Parameter: X (controlled by a user). • Extend the hits in both ways along diagonal (ungapped alignment) until score drops more than X relative to the best score yet attained. • Return the score of the highest scoring segment pair (HSP). extensions
E-values, P-values • E-value, Expectation value; this is the expected number of hits of at least the given score, that you would expect by random chance for the search database. • P-value, Probability value; this is the probability that a hit would attain at least the given score, by random chance for the search database. • E-values are easier to interpret than P-values. • If the E-value is small enough, e. g. no more than 0. 10, then it is essentially a P-value.
Karlin-Altschul statistics • Expected number of HSPs with score ≥ S is: E = Km. Ne –λS • m = length of query sequence • N = database size in residues • K scales the search space size • λ a scale for the scoring system
The bit score • This formula “normalizes” a raw score: S’ = (λS – ln K)/ln 2 • The E-value is then given by: E = m. N 2 –S’ • Allows direct comparison of E-values, even with differing scoring matrices.
Karlin and Altschul provided a theory for computing statistical significance • Assumptions: – The scoring matrix M must be such that the score for a random alignment is negative. – n, m (lengths of the aligned sequences) are large. – The amino acid distribution p(x) is in the query sequence and the data base is the same. – Positive score is possible (i. e. M has at least one positive entry).
Score of high scoring sequence pairs follows extreme value distribution l – decay constant u – value of the peak normal P(S<x) = exp (-e –l(x-m) ) thus: P(S>=x) =1 - exp (-e –l(x-m)) ) Extreme values
Extreme value distribution for sequence alignment Property of extreme value distribution: P(S<x) = exp(-e –l(x-m)) P(S>=x) =1 - exp(-e –l(x-m)) m – location (zero in the fig from last slide), l scale; For random sequence alignment: m = ln Kmn/ l K- constant that depends on p(x) and scoring matrix M Since 1 -exp(-x) ~ x and substituting for m and s: P(S>=x) ~ e –l(x-m) = Kmn e –lx
E=value-expected number of random scores above x • E-value = KNme–lx (Expected number of sequences scoring at least x observed by chance, it is approximately same as p value for p value < 0. 1 )
Refinement of the basic algorithm-the two hit method • Observation: HSPs of interest are long and can contain multiple hits a relatively short distance apart. • Central idea: Look for non-overlapping pairs of hits that are of distance at most d on the same diagonal. • Benefits: – Can reduce word size w from 3 two 2 without losing sensitivity (actually sensitivity of two-hit BLAST is higher). – Since extending a hit requires a diagonal partner, many fewer hits are extended, resulting in increased speed.
Gapped BLAST • Find two non-overlapping hits of score at least T and distance at most d from one another. • Invoke ungapped extension. • If the HSP generated has normalized score at least Sg bits then start gapped extension. • Report resulting alignment if it has sufficiently significant (very small) E-value.
Gapped BLAST statistics • Theory does not work. • Simulations indicate that for the best hits scores for local alignments follow an extreme value distribution. • Method approximates l and m to match experimental distribution l and m can be computed from the median and variation of the experimental distribution. • BLAST approach – simulate the distribution for set of scoring matrices and a number of gap penalties. BLAST offers a choice of parameters from this pre-computed set.
Multiple Sequence Alignment • A multiple alignment of sequences from a protein family makes the conserved features much more apparent. • Much more difficult to compute than pairwise alignments. • The most commonly used and newer programs use the “progressive alignment strategy”. • There also important databases of multiple alignments for protein families.
Multiple alignment of globins from CDD
Progressive alignment • Determine an (approximate) phylogenetic tree for the sequences. • Construct the multiple alignment by merging pairwise alignments based on the phylogenetic tree, the most closely related sequences first, etc. • The idea is, if you are careless about the order and merge distantly related sequences too soon in the process, then errors in the alignment may occur and propagate.
Multiple sequence alignment programs • CLUSTALW, Thompson et al. NAR 1994. • T-Coffee (Tree-based Consistency Objective Function for alignment Evaluation), C. Notredame et al. JMB 2000. • MUSCLE (Multiple sequence comparison by log expectation), R. Edgar NAR 2004.
PSI-BLAST • Position Specific Iterated BLAST • As a first step runs a (regular) BLAST. • Hits that cross the threshold are used to construct a position specific score matrix (PSSM). • A new search is done using the PSSM to find more remotely related sequences. • The last two steps are iterated until convergence.
PSSM (Position Specific Score Matrix) • One column per residue in the query sequence. • Per-column residue frequencies are computed so that log-odds scores may be assigned to each residue type in each column. • There are difficulties; e. g. pseudo-counts are needed if there are not a lot of sequences, the sequences must be weighted to compensate for redundancy.
Exercise! • Go to the NCBI BLAST web site. • Click on the link to PHI- and PSI- BLAST. • Choose the search database to be “pdb”. • Enter the sequence for 1 h 1 b. A, Human Neutrophil Elastase. • How many iterations does it take before 1 dle. B (Factor B Serine Protease domain) shows up as a significant hit?
Modifying thresholds… • On occasion, it can prove useful to modify (increase) the inclusion threshold parameter. • The user can also manually select hits to include in the PSSM that do not meet the threshold, e. g. if one is certain they are homologs to the query. • Of course, one must always be extremely careful when doing so!
HMMs • Hidden Markov Models, a type of statistical model. • Have numerous applications (including outside of bioinformatics). • HMMs were used to construct Pfam, a database of multiple alignments for protein families (HMMer).
CDD Search • Conserved Domain Database (CDD) at NCBI. • Contains alignments from Smart, Pfam, COG, KOG, and LOAD databases. • Many multiple alignments are manually curated. • PSSMs derived from multiple alignments may be searched with RPS-BLAST (Reverse Position Specific BLAST).
Thank you to Dr. Teresa Przytycka for slides about dynamic programming and BLAST.