CLUSTERING TECHNIQUE DATA MINING UNSUPERVISED LEARNING UNSUPERVISED LEARNING











 of similar records Used for segmenting")














 Keep joining")





 Also called single linkage Distance between two")
 Also called complete linkage Distance between two")


 1. Start with n clusters (each record")



 Random chance can often produce")



 One of 2 methods. library(readr) grades_km_input")


 Plot each WSS against the respective number of centroids")
![USE BEST K FOR ANALYSIS km=kmeans(kmdata, 3, nstart=25) km c(wss[3], sum(km$withinss))](https://slidetodoc.com/presentation_image_h2/faac1c0eceb041c1092aba0d9f60b991/image-51.jpg "USE BEST K FOR ANALYSIS km=kmeans(kmdata, 3, nstart=25) km c(wss[3], sum(km$withinss))")
- Slides: 51
CLUSTERING TECHNIQUE DATA MINING: UNSUPERVISED LEARNING
UNSUPERVISED LEARNING Goal: Segment data into meaningful segments; detect patterns There is no target (outcome) variable to predict or classify Methods: Association rules, data reduction / clustering &
ALGORITHMS Supervised learning Unsupervised learning 3
MACHINE LEARNING STRUCTURE Unsupervised learning
UNSUPERVISED: ASSOCIATION RULES Goal: Produce rules that define “what goes with what” Example: “If X was purchased, Y was also purchased” Rows are transactions Used in recommender systems – “Our records show you bought X, you may also like Y” Also called “affinity analysis”
LEARNING TECHNIQUES Unsupervised learning categories and techniques Clustering K-means clustering Spectral/Hierarchical clustering
VIDEO
OVERVIEW OF CLUSTERING Clustering is the grouping similar objects Supervised methods use labeled objects Unsupervised methods use unlabeled objects Clustering looks for hidden structure in the data, similarities based on attributes Often used for exploratory analysis No predictions are made
K-MEANS ALGORITHM Given a collection of objects each with n measurable attributes and a chosen value k of the number of clusters, the algorithm identifies the k clusters of objects based on the objects proximity to the centers of the k groups. The algorithm is iterative with the centers adjusted to the mean of each cluster’s n-dimensional vector of attributes
USE CASES Clustering is often used as a lead-in to classification, where labels are applied to the identified clusters Some applications Image processing With security images, successive frames are examined for change Medical Patients can be grouped to identify naturally occurring clusters Customer segmentation Marketing and sales groups identify customers having similar behaviors and spending patterns
Clustering is dividing data points into homogeneous classes or clusters: Points in the same group are as similar as possible Points in different group are as dissimilar as possible When a collection of objects is given, we put objects into a group based on similarity.
CLUSTERING: THE MAIN IDEA Goal: Form groups (clusters) of similar records Used for segmenting markets into groups of similar customers Is Unsupervised Learning
OTHER APPLICATIONS Classification of species Grouping securities in portfolios Grouping firms for structural analysis of economy
Clustering helps marketers improve their customer base and work on the target areas. It helps group people (according to different criteria’s such as willingness, purchasing power etc. ) based on their similarity in many ways related to the product under consideration.
Clustering helps in identification of groups of houses on the basis of their value, type and geographical locations.
Clustering is used to study earth-quake. Based on the areas hit by an earthquake in a region, clustering can help ANALYZE the next probable location where earthquake can occur.
ACTIVITY 1: RESEARCH Consider performing research on the Clustering Algorithm. Write a ½ page single spaced submission on two (2) applications of Clustering citing examples. Please submit your document to the link on Blackboard labeled Clustering Application Activity.
To carry out effective clustering, the algorithm evaluates the distance between each point from the centroid of the cluster.
These Cluster centers are the centroids of each cluster and are at a minimum distance from all the points of a particular cluster
DETERMINING NUMBER OF CLUSTERS Reasonable guess Predefined requirement Use heuristic – e. g. , Within Sum of Squares (WSS) WSS metric is the sum of the squares of the distances between each data point and the closest centroid The process of identifying the appropriate value of k is referred to as finding the “elbow” of the WSS curve
DIAGNOSTICS When the number of clusters is small, plotting the data helps refine the choice of k The following questions should be considered Are the clusters well separated from each other? Do any of the clusters have only a few points Do any of the centroids appear to be too close to each other?
REASONS TO CHOOSE AND CAUTIONS Decisions the practitioner must make What object attributes should be included in the analysis? What unit of measure should be used for each attribute? Do the attributes need to be rescaled? What other considerations might apply?
SUMMARY Clustering analysis groups similar objects based on the objects’ attributes To use k-means properly, it is important to Properly scale the attribute values to avoid domination Assure the concept of distance between the assigned values of an attribute is meaningful Carefully choose the number of clusters, k Once the clusters are identified, it is often useful to label them in a descriptive way
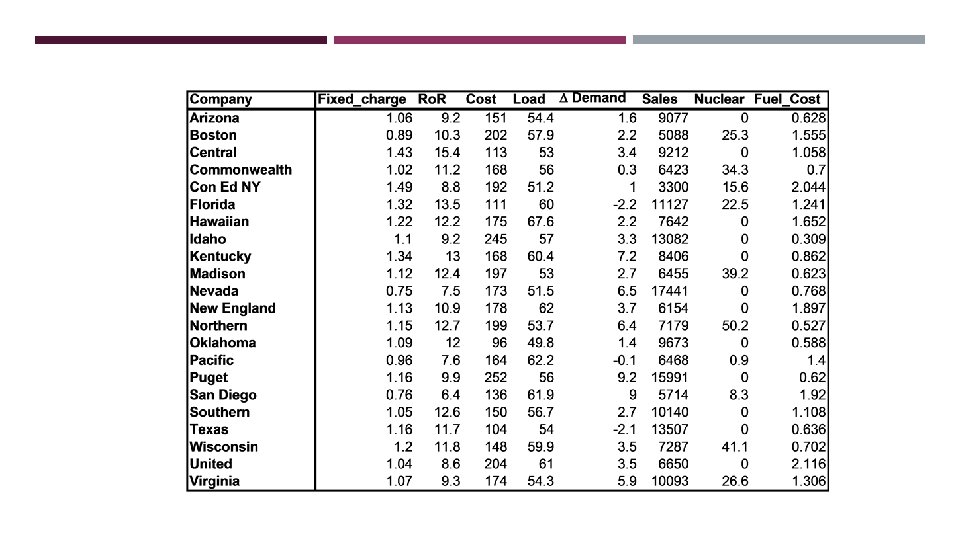
EXAMPLE: PUBLIC UTILITIES Goal: find clusters of similar utilities Data: 22 firms, 8 variables Fixed-charge covering ratio Rate of return on capital Cost per kilowatt capacity Annual load factor Growth in peak demand Sales % nuclear Fuel costs per kwh
Sales & Fuel Cost: 3 rough clusters can be seen High fuel cost, low sales Low fuel cost, high sales Low fuel cost, low sales
EXTENSION TO MORE THAN 2 DIMENSIONS In prior example, clustering was done by eye Multiple dimensions require formal algorithm with A distance measure A way to use the distance measure in forming clusters We will consider two algorithms: 1. hierarchical 2. non-hierarchical
HIERARCHICAL METHODS Agglomerative Methods Begin with n-clusters (each record its own cluster) Keep joining records into clusters until one cluster is left (the entire data set) Most popular Divisive Methods Start with one all-inclusive cluster Repeatedly divide into smaller clusters
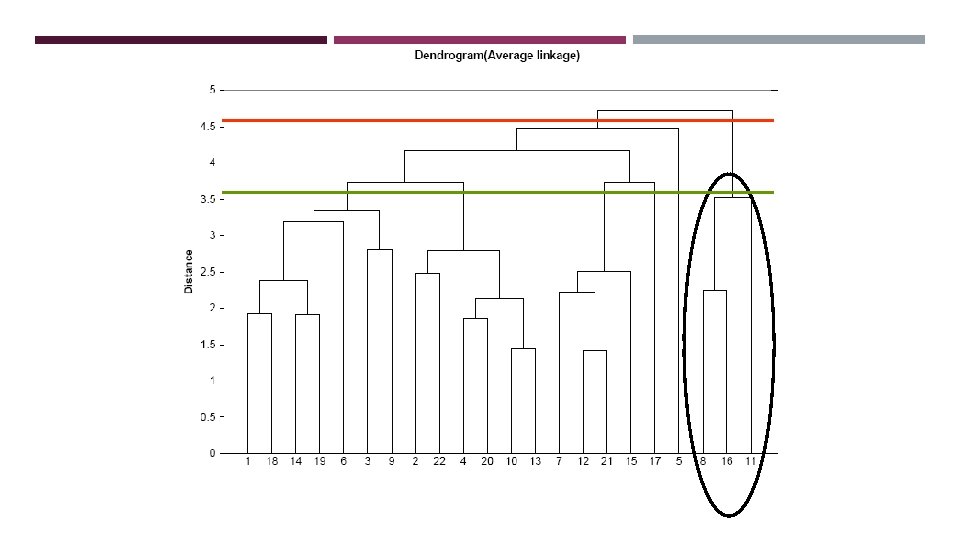
A DENDROGRAM SHOWS THE CLUSTER HIERARCHY At distance = 4, 4 clusters are formed At distance = 3, 9 clusters are formed At distance = 1. 75, 20 clusters are formed At distance =. 5, each point is a cluster
MEASURING DISTANCE 2 ways to measure distance. . . 1. Between 2 records 2. Between 2 clusters
DISTANCE BETWEEN TWO RECORDS Euclidean Distance is most popular:
NORMALIZING Problem: Raw distance measures are highly influenced by scale of measurements Solution: normalize (standardize) the data first Subtract mean, divide by std. deviation Also called z-scores (i. e. , from Normal Curve) Math Normalization is NOT the same thing as Database Normalization
EXAMPLE: NORMALIZATION For 22 utilities: Avg. sales = 8, 914 Std. dev. = 3, 550 Normalized score for Arizona sales: (9, 077 -8, 914)/3, 550 = 0. 046
MINIMUM DISTANCE (CLUSTER A TO CLUSTER B) Also called single linkage Distance between two clusters is the distance between the pair of records Ai and Bj that are closest Single Linkage Cluster A Cluster B
MAXIMUM DISTANCE (CLUSTER A TO CLUSTER B) Also called complete linkage Distance between two clusters is the distance between the pair of records Ai and Bj that are farthest from each other Complete Linkage Cluster A Cluster B
AVERAGE DISTANCE Also called average linkage Distance between two clusters is the average of all possible pair-wise distances
CENTROID DISTANCE Distance between two clusters is the distance between the two cluster centroids. Centroid is the vector of variable averages for all records in a cluster Centroid Distance Cluster A Cluster B
THE HIERARCHICAL CLUSTERING STEPS (USING AGGLOMERATIVE METHOD) 1. Start with n clusters (each record is its own cluster) 2. Merge two closest records into one cluster 3. At each successive step, the two clusters closest to each other are merged Dendrogram, from bottom up, illustrates the process
Records 12 & 21 are closest & form first cluster
READING THE DENDROGRAM See process of clustering: Lines connected lower down are merged earlier 10 and 13 will be merged next, after 12 & 21 Determining number of clusters: For a given “distance between clusters, ” a horizontal line intersects the clusters that are that far apart, to create clusters e. g. , at distance of 4. 6 (red line in next slide), data can be reduced to 2 clusters -- The smaller of the two is circled At distance of 3. 6 (green line) data can be reduced to 6 clusters, including the circled cluster
Comparing Scatterplots to Dendrograms Distance between records Distance between clusters
INTERPRETATION Goal: obtain meaningful and useful clusters Caveats: (1) Random chance can often produce apparent clusters (2) Different cluster methods produce different results Solutions: Obtain summary statistics Also, review clusters in terms of variables not used in clustering Label the cluster (e. g. , clustering of financial firms in 2008 might yield label like “midsize, sub-prime loser”)
DESIRABLE CLUSTER FEATURES Stability – are clusters and cluster assignments sensitive to slight changes in inputs? Are cluster assignments in partition B similar to partition A? Separation – check ratio of between-cluster variation to withincluster variation (higher is better) is h t nt a W NO Tt his
SUMMARY Cluster analysis is an exploratory tool. Useful only when it produces meaningful clusters Hierarchical clustering gives visual representation of different levels of clustering On other hand, due to non-iterative nature, it can be unstable, can vary highly depending on settings, is computationally expensive, and sensitive to outliers Non-hierarchical is computationally cheap and more stable; requires user to set k Can use both methods Be wary of chance results; data may not have definitive “real” clusters
EXERCISE We will use the WSS to determine an appropriate number of k and perform a k-means analysis. We want to group 620 high school seniors based on their grades
IMPORT FILE Import File (get file from Blackboard) One of 2 methods. library(readr) grades_km_input <- read_csv("C: /Users/igoche/Desktop/grades_km_input. csv")
EXCLUDE VARIABLES #We do not want Student ID number so exclude from input matrix kmdata_orig = as. matrix(grades_km_input[, c("Student", "English", "Math", "Science")]) kmdata<-kmdata_orig[, 2: 4] kmdata[1: 10, ]
FIND BEST K Let us determine an appropriate value for k. We will loop through several k-means analyses for the number of centroids k will vary from 1 to 15. wss<-numeric(15) for (k in 1: 15) wss[k] <- sum(kmeans(kmdata, centers=k, nstart=23)$withinss)
WSS AND CENTROIDS (FIND K) Plot each WSS against the respective number of centroids plot(1: 15, wss, type="b", xlab="Number of Clusters", ylab="Within Sum of Squares")
USE BEST K FOR ANALYSIS km=kmeans(kmdata, 3, nstart=25) km c(wss[3], sum(km$withinss))