Clustering by Passing Messages Between Data Points Brendan

“Clustering by Passing Messages Between Data Points” Brendan J. Frey and Delbert Dueck

The Problem - Clustering ● We want to assign our data points to categories, based on similarity ● Common approach - define clusters by “representative” points, assign each data point to best representative ● Most formulations are NP-hard, must be approximated heuristically

Affinity Propagation - Informal Description ● ● ● Our data points are nodes in a graph Each iteration, every node gets messages from all other nodes How similar is the candidate? How much do other nodes support it? Messages estimate the suitability of nodes to serve as exemplars for others Messages from previous rounds are used to compute new set of messages
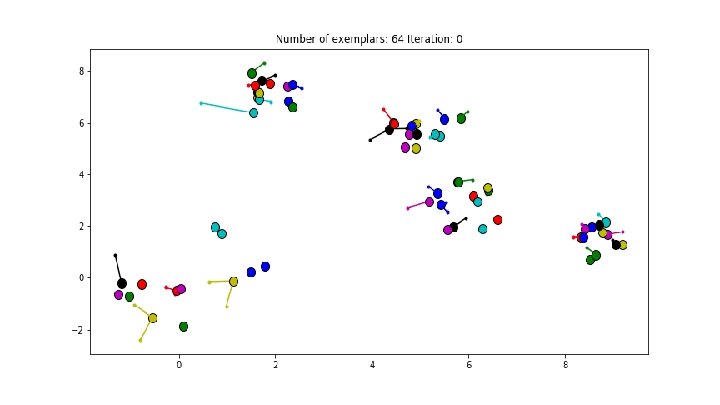

Affinity Propagation - Message Passing ● Input: similarity matrix S ● We will iteratively build “Responsibility” matrix R, “Availability” matrix A ● R(i, k) represents how much i favors k as an exemplar candidate ○ “I want to vote for you”, “I don’t want to vote for you” ● A(i, k) represents how much k favors being an exemplar for i ○ “You should vote for me”, “No, don’t vote for me”

Affinity Propagation - Complete Procedure ● Initialize A, R to all 0 ● Update responsibility: ○ R(i, k) = S(i, k) - max{ A(i, k’) + S(i, k’) }, where k’ =/= k ● Update availability: ○ ○ A(i, k) = min{ 0, R(k, k) + SUM(max{ 0, R(i’, k) }) }, where i’ =/= i =/= k A(k, k) = SUM(max{ 0, R(i’, k) }), where i’ =/= k ● Iterate until convergence ● E=A+R ● The exemplar for node i is node k with largest E(i, k)
 are called “preferences”")
Nuance - Diagonal of Similarity Matrix ● Diagonal values S(i, i) are called “preferences” ● Govern how much node i wants to vote for itself ● Parameter for the algorithm, will greatly affect clustering behavior ○ ○ Higher values - more, smaller clusters Lower values - fewer, larger clusters ● Typically set to median(S) ● Can be used to include/exclude candidates based on prior information
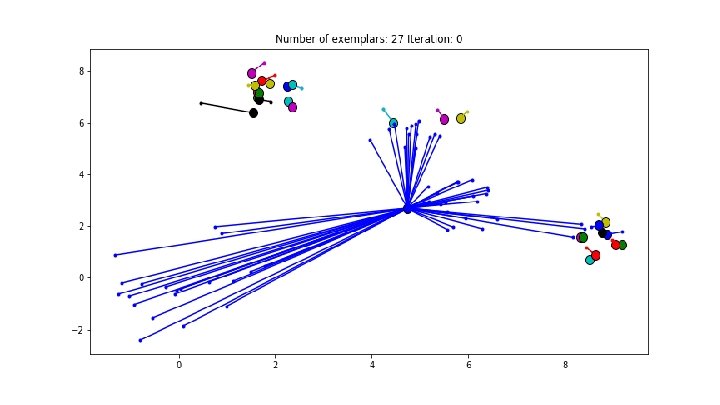

Advantages ● ● ● Doesn’t depend on geometric distances, symmetry, or centroids Doesn’t require any initial guesstimate of cluster exemplars Desired number of clusters doesn’t need to be fixed up front Similarity diagonal (a priori suitability of exemplars) can be flexibly tuned Easy to implement Matrix-based implementation yields good runtime

Disadvantages ● ● ● Quadratic space and runtime complexity Entire similarity matrix must be computed up front Desired number of clusters doesn’t need to be fixed up front Not always clear how to best tune the similarity diagonal Evident preference for many small clusters, not always desirable
. Clustering by")
Images stolen from ● Frey, B. J. , & Dueck, D. (2007). Clustering by passing messages between data points. science, 315(5814), 972 -976. ● https: //www. ritchievink. com/blog/2018/05/18/algorithm-breakdown-affinitypropagation/ ● https: //en. wikipedia. org/wiki/Cluster_analysis
- Slides: 11