machine learning Supervised Learning Unsupervised Learning Reinforcement Learning

 • 통계적 원리로 데이터의 패턴을 발견하는 방법 • 분류 • Supervised")





")
 데이터")
 예측할 변수")


 분석 모형")





")
 Negative")
")


















")































- Slides: 73
머신 러닝(machine learning) • 통계적 원리로 데이터의 패턴을 발견하는 방법 • 분류 • Supervised Learning • Unsupervised Learning • Reinforcement Learning
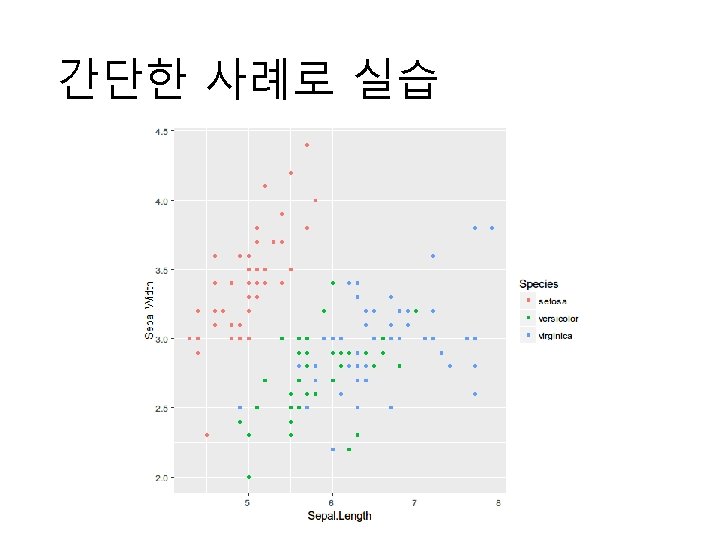
간단히 해보기 train(Species ~. , data = iris, method = ‘lda’)
간단히 해보기 train(Species ~. , data = iris, method = ‘lda’) 데이터
간단히 해보기 train(Species ~. , data = iris, method = ‘lda’) 예측할 변수
간단히 해보기 train(Species ~. , data = iris, method = ‘lda’) 분석 모형
Linear Discriminant Analysis
Linear Discriminant Analysis
Linear Discriminant Analysis
LDA 결과 Linear Discriminant Analysis 150 samples 4 predictor 3 classes: 'setosa', 'versicolor', 'virginica' No pre-processing Resampling: Bootstrapped (25 reps) Summary of sample sizes: 150, 150, . . . Resampling results: Accuracy Kappa 0. 9820793 0. 9728876
Confusion Matrix 실제 예측 Positive Negative Positive True Postive False Positive (Type I error) Negative False Negative (Type II error) True Negative
Accuracy 실제 예측 Positive Negative Positive True Postive False Positive (Type I error) Negative False Negative (Type II error) True Negative 21
Confusion Matrix lda. model = train(Species ~. , data = iris, method = ‘lda’) p = predict(lda. model, iris) confusion. Matrix(p, iris$Species)
Confusion Matrix 실제 예측 setosa versicolor virginica setosa 50 0 0 versicolor 0 48 1 virginica 0 2 49
실제 예측 setosa versicolor setosa 50 0 versicolor 0 48 virginica 0 2 Virginica로 예측 실제로는 versicolor Confusion Matrix virginica 0 1 49
실제 예측 setosa versicolor virginica setosa 50 0 0 versicolor 0 48 1 0 Versicolor로 예측 2 49 virginica 실제로는 virginica Confusion Matrix
Accuracy 실제 예측 setosa versicolor virginica setosa 50 0 0 versicolor 0 48 1 virginica 0 2 49
Accuracy • 찍어서 맞출 확률 = 0. 3 • Accuracy = 0. 98 • Kappa = 0. 97 실제 예측 setosa versicolor virginica setosa 50 0 0 versicolor 0 48 1 virginica 0 2 49
Precision • 예측이 얼마나 정확한가? 실제 예측 Positive Negative Positive True Postive False Positive (Type I error) Negative False Negative (Type II error) True Negative
Precision • Accuracy = 97. 9% • Precision = 80. 0% 실제 암 건강 양성 8 2 음성 19 971 예측
Precision • Accuracy = 97. 9% • Precision = 100. 0% 실제 암 건강 양성 6 0 음성 21 973 예측
Recall • 전체 중에 얼마나 예측해낼 수 있는가? 실제 예측 Positive Negative Positive True Postive False Positive (Type I error) Negative False Negative (Type II error) True Negative
Recall • Accuracy = 97. 9% • Precision = 80. 0% • Recall = 29. 6% 실제 암 건강 양성 8 2 음성 19 971 예측
Recall • Accuracy = 97. 9% • Precision = 100. 0% • Recall = 22. 2% 실제 암 건강 양성 6 0 음성 21 973 예측
F 1 • Accuracy = 97. 9% • Precision = 80. 0% • Recall = 29. 6% F 1 = 43. 2% 실제 암 건강 양성 8 2 음성 19 971 예측
F 1 • Accuracy = 97. 9% • Precision = 100. 0% • Recall = 22. 2% F 1 = 36. 3% 실제 암 건강 양성 6 0 음성 21 973 예측
K-Nearest Neighbor train(Species ~. , data = iris, method = ‘knn’)
K=1
K=2
K=3
K=5
K를 정하는 방법 #1 수동으로 정한다 train(Species ~. , data = iris, method = 'knn', tune. Grid = data. frame(. k = 3)) But, 근거가 없음
CV를 하는 방법 train(Species ~. , data = iris, method = 'knn', tune. Grid = data. frame(. k = 1: 5), tr. Control = train. Control( method = “cv”, number = 3))
모형 • LDA • K-Nearest Neighbor • Elastic Net. • SVM • Neural Network • Decision Tree
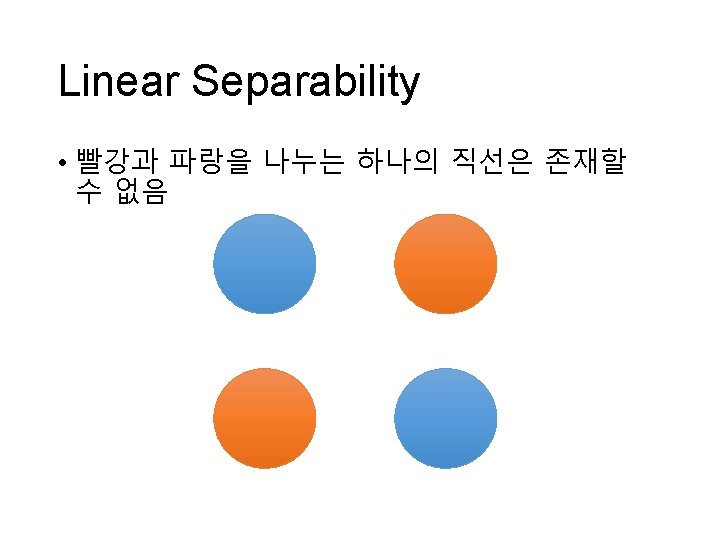
Elastic Net • Linear Model: y = ax + b • y의 오차가 최소화되도록 a와 b를 조정 • 문제점: overfitting
Overfitting
Decision Tree
Decision Tree
Decision Tree