Data Mining What Is Data Mining Data mining






 Process n Data mining—core of knowledge discovery process Pattern Evaluation Data")

 � Data Mining deals with what kind of data to be")











 � Evolution Analysis")




 � Regression is a data mining function that predicts a")





 of the")








- Slides: 42
Data Mining
What Is Data Mining? Data mining is the principle of extracting the information from large amounts of data. In other words… � Data mining (knowledge discovery from data) ◦ Extraction of interesting patterns or knowledge from huge amount of data � Other names ◦ Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis etc.
Data Mining � Data Mining is principle of extracting the information from the large amount of data. � In other words, we can say that data mining is mining the knowledge from data.
Need of Data Mining � There is huge amount of data available in Information Industry. � Analysing this huge amount of data and extracting useful information from it is necessary. � In other words, In field of Information technology, we have huge amount of data available that need to be turned into useful information.
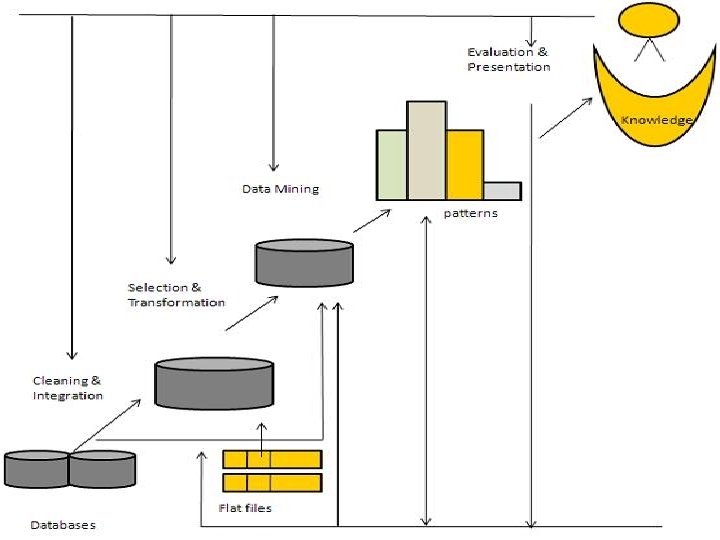
Knowledge Discovery/Data Mining Process � Here is the list of steps involved in knowledge discovery process: � Data Cleaning - In this step the noise and inconsistent data is removed. � Data Integration - In this step multiple data sources are combined. ( It merges the data from multiple heterogeneous data sources into a coherent data store. ) � Data Selection - In this step relevant to the analysis task are retrieved from the database.
� Data Transformation - In this step data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations. � Data Mining - In this step intelligent methods are applied in order to extract data patterns. � Pattern Evaluation - In this step, data patterns are evaluated. � Knowledge Presentation - In this step, knowledge is represented
Knowledge Discovery (KDD) Process n Data mining—core of knowledge discovery process Pattern Evaluation Data Mining Task-relevant Data Warehouse Data Cleaning Data Integration Databases Selection
Introduction � Data mining is the process of analyzing large databases to find useful patterns (data or info. )
Data Mining Tasks(Techniques) � Data Mining deals with what kind of data to be mined. � There are two kind of functions involved in Data Mining, that are : � Descriptive � Classification and Prediction
Data Mining Models and Tasks
Descriptive � The descriptive function deals with general properties of data in the database. � Here is the list of descriptive functions: � Class/Concept � Mining of Description Frequent Patterns Associations Correlations Clusters
§ Class/Concepts Description � Class/Concepts refers the data to be associated with classes or concepts. � For example, in a company classes of items for sale include computer and printers, and concepts of customers include big spenders and budget spenders. Such descriptions of a class or a concept are called class/concept descriptions.
Ways of Class/Concepts Description ◦ Characterization: provides a concise and succinct summarization of the given collection of data ◦ Example: The characteristics of customers who spend more than $1000 a year at All Electronics. The result can be a general profile such as age, employment status or credit ratings.
Ways of Class/Concepts Description � Characterization: provides a concise and succinct summarization of the given collection of data � Comparison: provides descriptions comparing two or more collections of data. � Example: The user may like to compare the general features of software products whose sales increased by 10% in the last year with those whose sales decreased by about 30% in the same duration.
§ Mining of Frequent Patterns � Frequent Patterns : � As the name suggests patterns that occur frequently in data. � It describes the specific pattern within the data.
Mining of Association/ co-relations • Association Analysis: from marketing perspective, determining which items are frequently purchased together within the same transaction. • Example: An example is mined from the (some store) All Electronic transactional database. buys (X, “Computers”) buys (X, “software”) [Support = 1%, confidence = 90% ] ◦ X represents customer ◦ confidence = 90% , if a customer buys a computer there is a 50% chance that he/she will buy software as well. ◦ Support = 1%, means that 1% of all the transactions under analysis showed that computer and software were purchased together.
Cont. . � Confidence indicates the number of times the if/then statements have been found to be true. � Support is an indication of how frequently the items appear in the database.
§ Association rules � Association is a data mining function that discovers the probability of the co-occurrence of items in a collection. � The relationships between co-occurring items are expressed as association rules or corelations. � Note: In data mining, association rules are useful for analysing and predicting customer behavior.
§ Mining of Clusters � Cluster refers to a group of similar kind of objects. � Cluster analysis refers to forming group of objects that are very similar to each other but are highly different from the objects in other clusters. � The goal is to place records into groups where the records in a group are highly similar to each other and dissimilar to records in other groups.
Cluster Analysis
Predictive functions: � Classification � Regression � Outlier Analysis (Deviation Detection) � Evolution Analysis
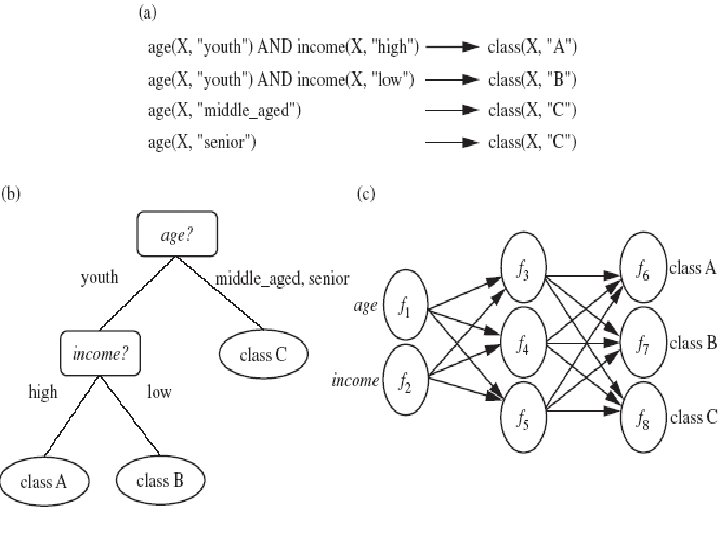
• Classification � Classification is the process of learning a model that is able to describe different classes of data. � Classification model can be represented in various forms such as �A decision tree
Tree Structure:
Cont. . Customer renting property> 2 years? ? ? Customer age> 25 years? ? ? Rent property Buy property
Age? Class C Income? ? Class A Class B
• Regression (Prediction) � Regression is a data mining function that predicts a number. � Age, weight, distance, temperature, income, or sales could all be predicted using regression techniques. � For example, a regression model could be used to predict children's height, given their age, weight, and other factors.
Cont. . � Regression modeling has many applications in � business planning, � financial forecasting, � time series prediction, � environmental modeling
Outlier Analysis � Outlier Analysis - The Outliers may be defined as the data objects that do not comply with general behaviour or model of the data available. � Such data objects, which are grossly different from or inconsistent with the remaining set of data, are called outliers. � The outliers may be of particular interest, such as in the case of fraud detection, where outliers may indicate fraudulent activity. � Thus, outlier detection and analysis is an interesting data mining task, referred to as outlier mining or outlier analysis.
Deviation detection Ø Discovering the most significant changes in data Ø A data object that deviates significantly from the normal objects as if it were generated by a different mechanism Ø Deviation detection are different from the noise data ◦ Noise is random error or variance in a measured variable ◦ Noise should be removed before outlier detection � Applications: ◦ Credit card fraud detection
Data visualization � Data visualization: using graphical methods to show patterns in data. � Data visualization systems help users examine large volumes of data and detect patterns visually ◦ Can visually encode large amounts of information on a single screen
Evolution Analysis � Evolution Analysis - Evolution Analysis refers to description and model regularities or trends for objects whose behaviour changes over time. � Example ◦ Stock market predictions: future stock prices
Cont. . � Example: Time-series data. If the stock market data (time-series) of the last several years available from the New York Stock exchange and one would like to invest in shares of high tech industrial companies. A data mining study of stock exchange data may identify stock evolution regularities for overall stocks and for the stocks of particular companies. Such regularities may help predict future trends in stock market prices, contributing to one’s decision making regarding stock investments.
Ex: Time Series Analysis � Example: Stock Market � Predict future values � Determine similar patterns over time � Classify behavior © Prentice Hall 36
Applications � This information further can be used for various applications such as � market analysis, � fraud detection, � customer retention, � production control, � science exploration etc.
Market Analysis and Management � Customer Profiling - Data Mining helps to determine what kind of people buy what kind of products. � Identifying Customer Requirements - Data Mining helps in identifying the best products for different customers. It uses prediction to find the factors that may attract new customers. � Cross Market Analysis - Data Mining performs Association/correlations between product sales.
Fraud Detection � Data Mining is also used in fields of credit card services and telecommunication to detect fraud. � In fraud telephone call it helps to find destination of call, duration of call, time of day or week.
Corporate Analysis & Risk Management � Finance Planning and Asset Evaluation - It involves cash flow analysis and prediction, contingent claim analysis to evaluate assets. � Resource Planning - Resource Planning It involves summarizing and comparing the resources and spending. � Competition - It involves monitoring competitors and market directions.
ADVANTAGES OF DATA MINING � Marketing/Retailing: Data mining can aid direct marketers by providing them with useful and accurate trends about their customers’ purchasing behavior. � Banking/Crediting: Data mining can assist financial institutions in areas such as credit reporting and loan information. � Researchers: Data mining can assist researchers by speeding up their data analyzing process; thus, allowing them more time to work on other projects.
DISADVANTAGES OF DATA MINING � Security issues: Although companies have a lot of personal information about us available online, they do not have sufficient security systems in place to protect that information. � Misuse of information: Some of the company will answer your phone based on your purchase history. If you have spent a lot of money or buying a lot of product from one company, your call will be answered really soon. So you should not think that your call is really being answer in the order in which it was receive.
Thanks……