Chapter 2 Structure and Function of Nucleic Acid

")





 guanine, G (2 -amino-6 oxy)")
 cytosine, C(2 -oxy-4 amino) thymine, T(2 -oxy-4 -oxy-5 methyl)")












 n Base nucleoside n guanine guanosine Cytosine cytidine Adenine adenosine Uracil uridine")
 n Base nucleoside nucleotide n n n n n guanine deoxyguanosine")






















 Negative supercoil: DNA in")






 transfer RNA (t. RNA) ribosomal RNA")





 5 -cap structure of m.")









 v Small nuclear RNA, or sn. RNA, are a")
 into m.")















- Slides: 88
Chapter 2 Structure and Function of Nucleic Acid
Interesting history n n n 1944: proved DNA is genetic materials (Avery et al) 1953: discovered DNA double helix (Watson and Crick) 1968: decoded the genetic codes (Nirenberg) 1975: discovered reverse transcriptase (Temin and Baltimone) 1981: invented DNA sequencing method (Gilbert and Sanger) 1985: invented PCR technique (Mullis) 1987: launched the human genome project 1994: HGP USA, UK, France, Germany, Japan and China 1997: Dolly sheep 2001: accomplished the draft map of human genome 2002: Draft Sequence of the Rice Genome (Jun Yu et al )
The central dogma of the biosciences RNA DNA Genetic Information Transmitter of genetic information Protein Biocatalyst Molecular machine Deoxyribonucleic acid and Ribonucleic acid----Macromolecules Linear polymers of nucleotides: Heterocyclic nitrogenous bases Essential Question n What are the structures of the nucleotides? n How are nucleotides joined together to form nucleic acids? n How is information stored in nucleic acids? n What are the biological functions of nucleotides and nucleic acids?
Nucleic acid is composed of polynucleotide chains n A nucleotide chain composed of nucleotides linked in a linear sequential order through 3`-5`phosphodiester bonds n Nucleic acid can be hydrolyzed into nucleotides by nuclease. The hydrolyzed nucleic acid has equal quantity of base, pentose and phosphate
Section 1 The monomeric units of Nucleic Acid---nucleotides Nucleic Acid Phosphate Nucleotide Pentose Nucleoside Base
1. 1 Nitrogenous Bases: purin e pyrimidi ne Adenine , A Guanine , G Cytosine , C Thymine , T Uracil , U
Nitrogenous bases: derivatives of pyrimidine or purine
base purine adenine, A (6 -amino) guanine, G (2 -amino-6 oxy)
pyrimidine uracil, U(2 -oxy-4 oxy) cytosine, C(2 -oxy-4 amino) thymine, T(2 -oxy-4 -oxy-5 methyl)
Three pyrimidines and two purines are commonly found in cells Purine derivatives
1. 2 The Pentoses of Nucleotide and Nucleic Acids Ribose D-2 -deoxyribose
General Components of Nucleic Acids
1. 3 Nucleosides Are Formed by Joining a Nitrogenous Base to a Sugar Ø Nucleoside = base + pentose Ø Connecting Bond:glycosidic bond Ø Purine N-9 or pyrimidine N-1 is connected to pentose (or deoxypentose) C-1 through a glycosidic bond v Nucleoside are named: v Purine: the root name + ending -osine v Pyrimidine: the root name + ending -idine
Adenosine 9 1 1 1 Deoxycytidine
Nucleosides are more water soluble than free bases
O NH 2 RNA N N HOCH 2 O DNA Guanosine NH 2 O N N HOCH 2 O OH H Deoxyadenosine HOCH 2 O NH 2 N N HOCH 2 O OH H Deoxyguanosine N O HOCH 2 OH OH OH Cytidine Uridine NH 2 N HN HN N O OH OH Adenosine O N N NH 2 N OH OH NH 2 N HN HN N O O N HOCH 2 O OH H Deoxycytidine N O HOCH 2 CH 3 O OH H Deoxythymidine
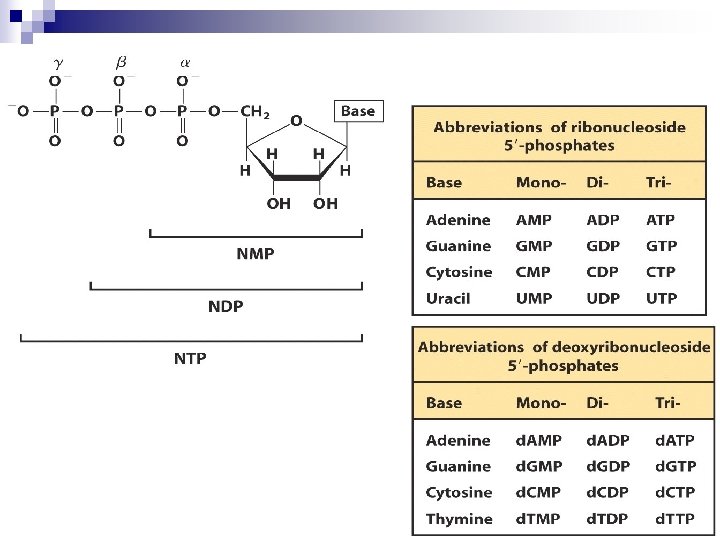
1. 4 Nucleotides Are Nucleoside Phosphate Ø Connecting bond: phosphoester bond Ø Monomeric nucleotides = Nucleosides + Phosphate Ø All the –OH groups are available for esterification at C-2 、 C-3 、C-5 of ribose and C-3 、C-5 of deoxyribose with phosphates 。
Phosphodiester linkages: repeating, sugarphosphate backbone of the polynucleotide chain NH 2 N Phosphate ester O O - N - P O N N OCH 2 O O OH OH Adenosine monophosphate AMP Phosphoryl group P N N O P OCH 2 O OH H Deoxycytidine monophosphate d. CMP
Structures of common ribonucleotides — AMP, GMP, CMP, and UMP uncommon
Nucleoside diphosphates and triphosphates are nucleotides with two or three phosphate groups Nucleoside 5’-diphosphates/triphosphates (NDPs/NTPs): strong polyprotic acids Form stable complexes with divalent cations: Mg 2+, Ca 2+
AMP ADP ATP
Nomenclature (RNA) n Base nucleoside n guanine guanosine Cytosine cytidine Adenine adenosine Uracil uridine n n n n nucleotide guanosine monophosphate (GMP) cytidine monophosphate (CMP) adenosine monophosphate (AMP) uridine monophosphate (UMP) (NMP)
Nomenclature ( DNA) n Base nucleoside nucleotide n n n n n guanine deoxyguanosine monophosphate (d. GMP) Cytosine deoxycytidine monophosphate (d. CMP) Adenine deoxyadenosine monophosphate (d. AMP) thymine deoxythymidine deoxythymine monophosphate (d. UMP) (d. NMP)
Some Important Nucleotides n n n Energetic materials: ATP etc Coenzymes :NAD+、 NADP +and FAD etc. Cyclic nucleotides: cyclic AMP, cyclic GMP, c. GMP) Some important intermediates: PAPS、 SAM、UDPGA 5 3 3 , 5 -c. AMP
Section 2 structure of Nucleic Acids --polynucleotides Nucleic acid are linear polymers of nucleotides linked 3` to 5` by phosphodiester bridges. They are formed as 5`- monophosphates are successively added to the 3`-OH group of the preceding nucleotide. n Polymers possess the polarity: one end has a 5`phosphate terminal while one end has a 3`-hydroxyl group terminal. n The convention in all notation of nucleic acid structure is to read the polynucleotide chain from the 5`-end of the polymer to the 3`-end n
Phosphoester bond formation: the -P atom of the triphosphate group of a d. NTP attacks the C-3 OH group of a nucleotide or an existing DNA chain, and forms a 3`-5`-phospho-diester bonds Nucleic acid chain extension
5`-end Alternative phosphodiester bonds and pentoses constitute the 5’- 3’- backone of nucleic acids. G The primary structure A 3`-5`-phosphodiester bonds A T T 3`-end OH
The base sequence of a nucleic acid is its distinctive characteristic Pi. Sugar-phosphate backbone Side chains: bases DNA: A, G, C, T RNA: A, G, C, U Two termini of Polynucleotides: 5’-Pi (5’- ) 3’- OH (3’- ) Direction of the polynucleotide chain 5’-end: p. Tp. Gp. Cp. Ap 3’-end: Ap. Cp. Gp. Tp 5’-TGCA…… -OH From 5’- to 3’-
G 5´ P C P A P T P OH 3´ 5 ´ p. Gp. Cp. Ap. T-OH 3´ 5´ G C A T T 3 ´ GCATT A nucleic acid chain, having a monophosphate group at 5 ´ end and –OH group at 3 ´end, can only be extended from 5 ´end.
Section 2. 1 The Structure and Function of DNA 2. 1. 1 DNA double helix 2. 1. 2 The tertiary structure of DNA 2. 1. 3 The function of DNA
Primary structure The primary structure of DNA and RNA is defined as the nucleotide sequence in the 5`3`direction n Since the difference among nucleotides is the base, the primary structure of DNA and RNA is actually the base sequence. n The nucleotide chain can be as long as thousands and even more, so that the base sequence variations create phenomenal genetic information. n
secondary structure n The secondary structure is defined as the relative spatial position of all the atoms of nucleotide residues.
The Secondary Structure of DNA — double helix Chargaff `s Rules: the base composition of DNA generally varies from one species to another. DNA isolated from different tissues of the same species have the same base composition The base composition of DNA in a given species does not change with its age, nutritional state, and environmental variations. The molarity of A equals to that of T, and the molarity of G is equal to that of C.
It symbolized the new era of modern biology The four bases commonly found in DNA (A, C, G and T) do not occur in equimolar amounts Ø The relative amounts of each base vary from species to species Ø [A]=[T],[G]=[C],[A]+[G]=[T]+[C] [purines] = [pyrimidines] Ø
Vary from species to species A = T ; G = C (in each Purine (A+G) = pyrimidine (T+C) X-ray diffraction studies (R Franklin and M Wilkins): Helix with two different loops in outside James Watson and Francis Crick at Cambrige University in 1953: DNA was a complementary double helix; Two strands of DNA are held together by the bonding interactions between unique base pairs. Size of DNA: ~bp; ~kb The genetic information in DNA is encoded in digital form
0. 34 nm 3. 4 nm Major Groove Minor groove 2 nm
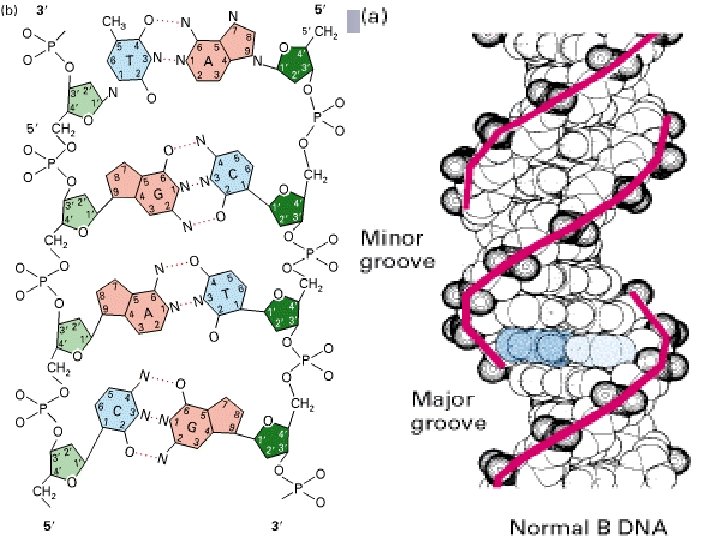
The Contents of Double Helix 1. DNA was a complementary double helix, and it consists of two antiparallel (run in opposite direction) polynucleotide strands. These two strands coil together around the same axis to form a right-handed double helix (also called duplex). Example: If sequence 5’-ATGTC-3’ on one chain, the opposite chain must have the complementary sequence 3’-TACAG-5’
2. The sugar-phosphates are served as the backbone while the base pairs are in the inner of the double – helix. Base pairing is very specific: A only pairs with T in 2 Hbonds; G pairs with C in 3 H-bonds.
Base pairing: A = T; G C
The stability of the double-helix is maintained by the hydrogen bonds mainly while the base-stacking forces exist also. (the paired bases are nearly planar and perpendicular to helical axis. Two adjacent base pairs have basestacking interactions to further enhance the stability of the duplex) 4. The diameter of the double helix in B-form DNA is 2 nm; the distance spanned by one turn of DNA is 3. 4 nm; and so the distance between each base-pairing plane is 0. 34(There are 10 base pairs each ). 5. There are major grooves and minor grooves in doublehelix strands 3.
n Small molecules like drugs bind in the minor groove, whereas particular protein motifs can interact with the major grooves n The hydrophilic backbone is on the outside of the duplex, and the bases lie in the inner portion of the duplex.
Polymorphisms of DNA can resume different forms depending upon their chemical microenvironment, such as ionic strength and relative humidity. n B-form DNA is the predominant structure in the aqueous environment of the cells. n A-form and Z-form are also native structures found in biological systems. n
A-DNA B-DNA Z-DNA Comparison of the structural properties of A-, B-, and Z-DNA Helix rotation Bp numbers Right-handed ~11 bp/turn Right-handed ~10 bp/turn Base pair tilt +19° -1. 2° Major groove very narrow, deep Wide, middle deep Minor groove Broad but shallow Helix diameter 2. 55 nm narrow, middle deep 2. 37 nm Left-handed 12 bp/turn -9° Flattened very narrow, deep 1. 84 nm
The Tertiary Structure of DNA v. The tertiary structure of DNA in prokaryote v. The tertiary structure of DNA in eukaryote
The tertiary structure of DNA in prokaryote: Supercoil For example: plasmid , virus , mitrochondria plasmids: naturally occurring, self-replicating, extrachromosomal circle ds. DNA found in bacteria.
Positive supercoil: overwind DNA double helix (direction same as helix) Negative supercoil: DNA in cells is negatively supercoiled (direction opposite the helix)
The tertiary structure of DNA in eukaryote: Nucleosome DNA:about 200 bp Histone:H 1∶H 2 A∶H 2 B∶H 3∶H 4 =1∶ 2∶ 2
nucleosome
The Function of DNA Ø The carrier of hereditary information and the foundation of gene Ø The forming of genome SV 40 virus 5100 bp E. coli 5700 kbp Human 3 109 bp
Section 3 The Structure and Function of RNA molecules are typically single-stranded. Each basic unit (nucleotide) has many single bonds in backbone and a glycosidic bond, are freedom in rotation Limited by intramolecular interactions and other stabilizing influences RNA molecules often fold into stem-loop structure by intrastrand base pairing between partial complementary sequences.
Biological roles of RNA n n n RNA is the genetic material of some viruses RNA functions as the intermediate (m. RNA) between the gene and the protein-synthesizing machinery. RNA functions as an adaptor (t. RNA) between the codons in the m. RNA and amino acids. RNA serves as a regulatory molecule, which through sequence complementarity binds to, and interferes with the translation of certain m. RNAs. Some RNAs are enzymes that catalyze essential reactions in the cell (RNase P ribozyme, large r. RNA, self-splicing introns, etc).
RNA Structure: RNA chains fold back on themselves to form local regions of double helix similar to A-form DNA STRUCTURE RNA helix are the basepaired segments between short stretches of complementary sequences, which adopt one of the various stem-loop structures hairpin bulge loop
1. 2. 3. 4. messenger RNA (m. RNA) transfer RNA (t. RNA) ribosomal RNA (r. RNA) small nuclear RNA (sn. RNA)
The Structure and Function of m. RNA Ø Only the genetic units of DNA sequence that encode proteins are transcribed into m. RNA molecules. Ø In prokaryotes, a single m. RNA may contain the information for the synthesis of several polypeptide chains within its nucleotide sequence. Ø In eukaryote, m. RNA encode only one polypeptide, but are more complex because they are synthesized in the nucleus in the form of much larger precursor molecules called heterogeneous nuclear RNA (hn. RNA)
Ø hn. RNA molecules contain stretches of nucleotide sequence that have no protein-coding capacity. These non-coding regions are called intervening sequence or intron. In contrast, the proteincoding regions are called exon. Ø Introns interrupt the continuity of the information specifying the amino acid sequence of a protein and must be spliced out before the message can be translated.
Eukaryotes Heterogeneous nuclear RNA, hn. RNA Gene expression
Ø In eukaryote , hn. RNA and m. RNA molecules have a run of 100 to 200 adenylic acid residues attached at their 3`-end, so-called poly. A tails. This polyadenyly-lation occurs after transcription has completed and is believes to contribute to m. RNA stability. Ø After transcription a special structure, 7 MGppp should be added to the 5`-end of hn. RNA so-called cap structure
m. RNA of eukaryote 5 ´-cap 5´ m 7 Gppp 5 ´noncoding regions 3 ´-poly A codon AUG GUG ……………… coding regions UAA 3´ AAAA ……An noncoding regions
5 5 (m 6 A. A. G. C. U) 5 -cap structure of m. RNA—m 7 Gppp. Nm
The Structure and Function of t. RNA Transfer RNA serves as a carrier of amino acid residues for protein synthesis. The t. RNA are the smallest RNAs and contain 73 to 94 residues, a substantial number of which are methylated or otherwise unusually modified. n t. RNA derives its name from its role as the carrier of amino acids during the process of protein synthesis. n Each of the 20 amino acids of proteins has at least one unique t. RNA to dedicated to delivery, and some amino acids are served by several t. RNAs. n
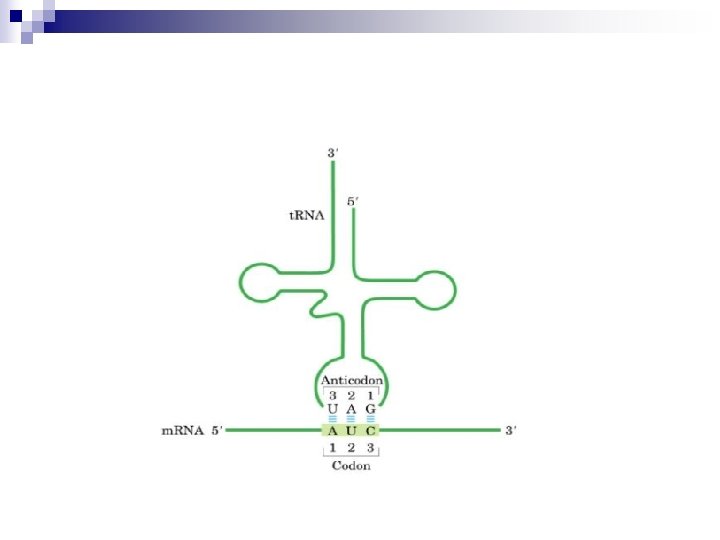
t. RNA molecules are base-paired internally to show a cloverleaf structure. Each cloverleaf consists of four H-bonded segments ---- three loops and the stem where the 3`-end 5`end of the molecule meet. These 4 segments are designated the acceptor or amino acid stem/arm , the DHU loop , the anticodon loop and T C loop. A loop varies from t. RNA to t. RNA so-called extra loop or variable loop. The amino acid is attached as an aminoacyl ester to the 3`-terminus of the t. RNA. Aminoacyl-t. RNAs are the substrates for protein biosynthesis.
Transfer RNA adopts higher-order structure through intrastrand base pairing t. RNA: 73~94 nucleotides Accept aa Diagram for the structure of t. RNA
The Character of t. RNA Ø Unusual bases are rich: n n n DHU 、T、 、m. G and m. A etc; Modified bases: pseudouridine, 4 -thiouridine 4, 1 -methylguanosine 1, dihydrouridine Ø Cloverleaf ------ secondary structure of t. RNA: Ø DHU loop、anticodon loop(anticodon)、T C loop and CCA- 3`- OH amino acid stem/arm 、extra loop Ø Inverted L-shaped conformation ------- tertiary structure of t. RNA n n Function: to transfer amino acid when protein synthesis. Specific to amino acid.
1 9 1 1 inosine, I 7 -methylguanosine, m. G 1 5 1 pseudouridine, 1 dihydrouridine, DHU
3´ OH A C CCA end C A C- G 5´P U- A DHU C- G U G loop C- G G-C U C Am C C C G C U D GA A C m D C CG A G G G C Tφ Gm Cm G G GC D DA A G A C GAG TψC A U loop A U G C A φ C A U A Anticoding G U A Tψ DHU loop anticodon secondary structure of t. RNA tertiary sructure of t. RNA
3. The Structure and Function of r. RNA Ø Ribosomal RNA molecules fold into characteristic secondary structure as a consequence of intramolecular hydrogen bond interaction. The different species of r. RNA are generally referred to according to their sedimentation coefficient, which are a rough measure of their relative size. Ø Ribosomes are composed of two subunits of different size. The central role of ribosomes are providing a place for protein synthesis
n Ribosomes are cytoplasmic structures that synthesize protein. Because they are composed of both proteins and r. RNA, they are sometimes described as ribonucleoprotein bodies. n The ribosomes of prokaryotes and eukaryotes are similar in shape and function. The difference between them is the size and chemical composition.
Ribosomal RNA provides the structural and functional foundation for ribosomes
4. Small Nuclear RNAs(sn. RNA) v Small nuclear RNA, or sn. RNA, are a class of RNA molecules found in eukaryotic cells, principally in the nucleus. They contain from 100 to about 200 nucleotides, some of which, like t. RNA and r. RNA, are methylated or modified. v sn. RNA are important in the processing of eukaryotic gene transcripts (hn. RNA) into mature messenger RNA for export from the nucleus to the cytoplasm.
Small nuclear RNAs mediate the splicing of Eukaryotic gene transcripts (hn. RNA) into m. RNA Contain 100~200 nucleotides, found in stable complexes with specific proteins forming small nuclear ribonucleoprotein particles, or sn. RNPs, are important in the processing of hn. RNA. Small RNAs serve a number of roles, including post-transcriptional gene silencing Small interfering RNA (si. RNA): disrupt gene expression by binding m. RNA complementally to form double-stranded RNA, which is easily degraded and eliminating the m. RNA. Only 21~28 nucleotides, can target DNA or RNA through complementary base pairing—direct readout.
Section 4 The properties of DNA 1. Denaturation and Renaturation of DNA The double –stranded structure of DNA can be separated into two component strands in solution by increasing the temperature or decreasing the salt concentration. That is , when duplex DNA molecules are subjected to condition of p. H, temperature, or ionic strength that disrupt H-bonds, the strands are no longer held together-----the double helix is denatured and the strands separate as individual random coil. If temperature is the denaturing agent, the double helix is said to melt.
Concomitant with this dissociation a phenomenon can be followed spectrophotometrically because the relative absorbance of the DNA solution at 260 nm increases as much as 40% when the bases unstack. That is , there is an increase in the optical absorbance of purine and pyrimidine bases. We referred to this phenomenon as hyperchromicity. Because of the stacking of the bases and the H-bonding between the stacks, the double-stranded DNA molecule exhibits properties of a rigid rod and in solution it is a viscous material.
Unstacking alleviates the suppression of UV absorbance. The rise in absorbance coincides with strand separation, and the midpoint of the absorbance increase is termed the melting temperature, Tm. The temperature at which the DNA strands are half denatured is called the Tm. v The higher the G+C content of a DNA, the higher its melting temperature. v Tm is dependent on the ionic strength of the solution. At high concentration of ions, Tm is raised and the transition between helix and coil is sharp.
Melting curve and melting temperature The midpoint of the melting curve is defined as the melting temperature, Tm A 260 0. 70 0. 65 0. 60 0. 55 0. 50 80 Tm 0. 2 M Na+: Tm = 69. 3 + 0. 41(% G + C) 100 o. C
Denaturation and renaturation of DNA secondary structure Denaturation of DNA can be observed by changes in UV absorbance Denaturation Increase temperature individual random coil Disrupt H-bonds: • High temperature • p. H extremes • Low ionic strength • Small organic compounds (formamide, urea) Melt Hyperchromic shift: absorbance of the DNA solution at 260 nm increases, stacked = 40% unstacked
DNA Renaturation Denatured DNA will renaturate to re-form the duplex structure if the denaturing condition are removed (that is, if the solution is cooled, the p. H is returned to neutrality, or the denaturants are diluted out). Renaturation requires reassociation of the DNA strands into a double helix, a process termed reannealing. n Renaturation is dependent on DNA concentration, temperature, ionic concentration and time. and many of the realignments are imperfect. n
The denaturation and renaturation of double-stranded DNA molecules
Nucleic Acid Hybridization If DNA from two different species are mixed, denatured, and allowed to cool slowly so that reannealing can occur, artificial hybrid duplexes may form, provided the DNA from one species is similar in nucleotide sequence to the DNA of the other. The degree of hybridization is a measure of the sequence similarity or relatedness.
Nucleic acid hybridization is a commonly employed procedure in molecular biology. n First, it can reveal evolutionary relationship. Second, it gives researchers the power to identify specific genes selectively against a vast background of irrelevant genetic material. n An appropriately labeled oligo- or polynucleotide, referred to as a probe, is constructed so that its sequence is complementary to a target gene n
Hybridization: DNA, RNA: RNA, DNA: RNA Nucleic acid hybridization is very useful in molecular biology. human mouse • Evolutionary relationships • Identify specific gene (by probe) • Quantitative investigation of gene expression 25% hybrids
Section 5 catalytic RNA and DNA ribozyme n n n It was assumed that all enzymes are proteins until 1982 when Thomas Cech and Sydney Altman discovered catalytic RNAs (Nobel, 1989 in Chemistry); Catalytic RNA, or, ribozymes, satisfy several enzymatic criteria: substrate specificity, enhance reaction rate, and emerge from reaction unchanged; Several known ribozymes: ¨ RNase P: catalyzes cleavage of precursor t. RNA molecules into mature t. RNAs; ¨ Group I, II introns: catalyze their own splicing (cleaving and ligating); ¨ Ribosome: catalyzes peptidyl transfer reaction
n n n n 1. Ribozymes Are RNA molecular with catalytic activity. Altered our concept of biochemical evolution RNA can serve as both a catalyst and a carrier of genetic information Ribozymes have the ability to self-cleave. They are highly conservative, an indication of the biological evolution and the primary enzyme. 2. deoxyribozymes Special DNA sequence with catalytic capability
Section 6 genomics and human genome project 1. characteristics of eukaryotic genome DNA n Intron: noncoding sequence n exon: coding (expressed )sequence n splicing: tailoring of the original transcript. n 2. HGP n Sequence and analyze all the genes in human n 3 billon bp, 23 books. n
Human genome project One of the greatest projects of human being. n 15 years, 6 countries, 25 research centers, and thousands of scientists. n Laid a solid foundation for understanding about human evolution, the origination, progression and treatment of diseases, other genomics, … n Human is genetically remarkably close to the lab mouse. n 35, 000 genes_____>1, 000 proteins n
Key points: n Structures of purine and pyrimidine bases, nucleosides and nucleotides. n Structure of polynucleotide strand. n Difference between DNA and RNA (structure and function). ¨ The ¨ secondary structure of DNA — properties of Double Helix (B-DNA) ¨ secondary and tertiary structure of RNA: t. RNA ¨ Denaturation, renaturation of DNA, hybridization of NA