Intel Pentium M Outline n n n History



 n Decomposes IA 32 instructions into")

")


 n n n Waiting micro-ops ready")
























")









")




 n n n Execution is out-of-order, but")












 The dielectric used since the 1960 s, silicon")











- Slides: 74
Intel Pentium M
Outline n n n History P 6 Pipeline in detail New features n n n Improved Branch Prediction Micro-ops fusion Speed Step technology Thermal Throttle 2 Power and Performance
Quick Review of x 86 n n n n n 8080 - 8 -bit 8086/8088 - 16 -bit (8088 had 8 -bit external data bus) - segmented memory model 286 - introduction of protected mode, which included: segment limit checking, privilege levels, read- and exe-only segment options 386 - 32 -bit - segmented and flat memory model - paging 486 - first pipeline - expanded the 386's ID and EX units into five-stage pipeline - first to include on-chip cache - integrated x 87 FPU (before it was a coprocessor) Pentium (586) - first superscalar - included two pipelines, u and v - virtual-8086 mode - MMX soon after Pentium Pro (686 or P 6) - three-way superscalar - dynamic execution - out-of-order execution, branch prediction, speculative execution - very successful micro-architecture Pentium 2 and 3 - both P 6 Pentium 4 - new Net. Burst architecture Pentium M - enhanced P 6
Pentium Pro Roots n Nex. Gen 586 (1994) n Decomposes IA 32 instructions into simpler RISC-like operations (R-ops or micro-ops) n Decoupled Approach n Nex. Gen bought by AMD n n AMD K 5 (1995) – also used micro-ops Intel Pentium Pro n Intel’s first use of decoupled architecture
Pentium-M Overview Introduced March 12, 2003 n Initially called Banias n Created by Israeli team n Missed deadline by less than 5 days n Marketed with Intel’s Centrino Initiative n Based on P 6 microarchitechture n
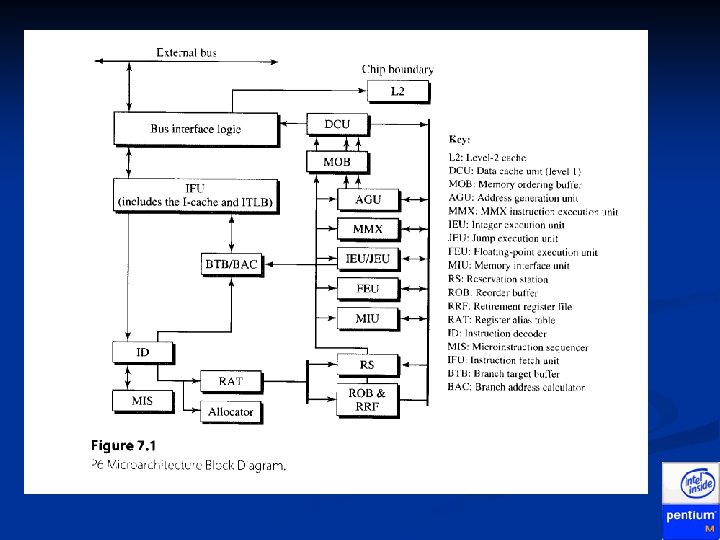
P 6 Pipeline in a Nutshell n Divided into three clusters (front, middle, back) In-order Front-End n Out-of-order Execution Core n Retirement n n Each cluster is independent n I. e. if a mispredicted branch is detected in the front -end, the front-end will flush and retch from the corrected branch target, all while the execution core continues working on previous instructions
P 6 Pipeline in a Nutshell
P 6 Front-End n n n Major units: IFU, ID, RAT, Allocator, BTB, BAC Fetching (IFU) n Includes I-cache, I-streaming cache, ITLB, ILD n No pre-decoding n Boundary markings by instruction-length decoder (ILD) Branch Prediction n n Decoding (ID) n n Predicted (speculative) instructions are marked Conversion of instructions (macro-ops) into micro-ops Allocation of Buffer Entries: RS, ROB, MOB
P 6 Execution Core n Reservation Station (RS) n n n Waiting micro-ops ready to go Scheduler Out-of-order Execution of micro-ops n n Independent execution units (EU) Must be careful about out-of-order memory access n n Memory ordering buffer (MOB) interfaces to the memory subsystem Requirements for execution n n Available operands, EU, and write-back bus Optimal performance
P 6 Retirement n In-order updating of architected machine state n n Micro-op retirement – “all or none” n n Re-order buffer (ROB) Architecturally illegal to retire only part of an IA-32 instruction In-ordering handling of exceptions n Legal to handle mid-execution, but illegal to handle mid-retirement
PM Changes to P 6 Most changes made in P 6 front-end n Added and expanded on P 4 branch predictor n Micro-ops fusion n Addition of dedicated stack engine n Pipeline length n Longer than P 3, shorter than P 4 n Accommodates extra features above n
PM Changes to P 6, cont. n n n Intel has not released the exact length of the pipeline. Known to be somewhere between the P 4 (20 stage) and the P 3 (10 stage). Rumored to be 12 stages. Trades off slightly lower clock frequencies (than P 4) for better performance per clock, less branch prediction penalties, …
Blue Man Group Commercial Break
Banias n n n n 1 st version 77 million transistors, 23 million more than P 4 1 MB on die Level 2 cache 400 MHz FSB (quad pumped 100 MHZ) 130 nm process Frequencies between 1. 3 – 1. 7 GHz Thermal Design Point of 24. 5 watts http: //www. intel. com/pressroom/archive/photos/centrino. htm
Dothan n n n Launched May 10, 2004 140 million transistors 2 MB Level 2 cache 400 or 533 MHz FSB Frequencies between 1. 0 to 2. 26 GHz Thermal Design Point of 21(400 MHz FSB) to 27 watts http: //www. intel. com/pressroom/archive/photos/centrino. htm
Dothan cont. 90 nm process technology on 300 mm wafer. n Provide twice the capacity of the 200 mm while the process dimensions double the transistor density n Gate dimensions are 50 nm or approx half the diameter if the influenza virus n P and n gate voltages are reduced by enhancing the carrier mobility of the Si lattice by 10 -20% n Draws less than 1 W average power n
Bus Utilizes a split transaction deferred reply protocol n 64 -bit width n Delivers up to 3. 2 Gbps (Banis) or 4. 2 Gbps (Dothan) in and out of the processor n Utilizes source synchronous transfer of addresses and data n Data transferred 4 times per bus clock n Addresses can be delivered times per bus clock n
n Bus update in Dothan n http: //www. intel. com/technology/itj/2005/volume 09 issue 01/art 05_perf_power
L 1 Cache n 64 KB total 32 K instruction n 32 K data (4 times P 4 M) n Write-back vs. write-through on P 4 n In write-through cache, data is written to both L 1 and main memory simultaneously n In write-back cache, data can be loaded without writing to main memory, increasing speed by reducing the number of slow memory writes n
L 2 cache n n n 1 – 2 MB 8 -way set associative Each set is divided into 4 separate power quadrants. Each individual power quadrant can be set to a sleep mode, shutting off power to those quadrants Allows for only 1/32 of cache to be powered at any time Increased latency vs. improved power consumption
Prefetch logic fetches data to the level 2 cache before L 1 cache requests occur n Reduces compulsory misses due to an increase of valid data in cache n Reduces bus cycle penalties n
Schedule n P 6 Pipeline in detail Front-End n Execution Core n Back-End n n Power Issues n n Intel Speed. Step Testing the Features x 86 system registers n Performance Testing n
P 6 Front-end: Instruction Fetching n IA-32 Memory Management n Classic segmented model (cannot be disabled in protected mode) n n Separation of code, data, and stack into "segments“ Optional paging n n Segments divided into pages (typically 4 KB) Additional protection to segment-protection n n I. e. provides read-write protection on a page-by-page basis Stage 11 (stage 1) - Selection of address for next I-cache access n n Speculation – address chosen from competing sources (i. e. BTB, BAC, loop detector, etc. ) Calculation of linear address from logical (segment selector + offset) n n Segment selector – index into a table of segment descriptors, which include base address, size, type, and access right of the segment Remember: only six segment selectors, so only six usable at a time n n 32 -bit code nowadays uses flat model, so OS can make do with only a few (typically four) segments IFU chooses address with highest priority and sends it to stage two
P 6 Front-end: Instruction Fetching n Stage 12 -13 - Accessing of caches n Accesses instruction caches with address calculated in stage one n n With paging, consults ITLB to determine physical page number (tag bits) n n n Without paging, linear address from stage one becomes physical address Obtains branch prediction from branch target buffer (BTB) n n Includes standard cache, victim cache, and streaming buffer BTB takes two cycles to complete one access Instruction boundary (ILD) and BTB markings Stage 14 - Completion of instruction cache access n Instructions and their marks are sent to instruction buffer or steered to ID
P 6 Front-end: Instruction Fetching
P 6 Front-end: Instruction Decoding n Stage 15 -16 - Decoding of IA 32 Instructions n n Alignment of instruction bytes Identification of the ends of up to three instructions Conversion of instructions into micro-ops Stage 17 - Branch Decoding n If the ID notices a branch that went unpredicted by the BTB (i. e. if the BTB had never seen the branch before), flushes the in-order pipe, and re-fetches from the branch target n n n Early catch saves speculative instructions from being sent through the pipeline Stage 21 - Register Allocation and Renaming n n n Synonymous with stage 17 (a reminder of independent working units) Allocator used to allocate required entries in ROB, RS, LB, and SB Register Alias Table (RAT) consulted n n Branch target calculated by BAC Maps logical sources/destinations to physical entries in the ROB (or sometimes RRF) Stage 22 – Completion of Front-End n Marked micro-ops are forwarded to RS and ROB, where they await execution and retirement, respectively.
P 6 Front-end: Instruction Decoding
Register Alias Table Introduction n n Provides register renaming of integer and floatingpoint registers and flags Maps logical (architected) entries to physical entries usually in the re-order buffer (ROB) Physical entries are actually allocated by the Allocator The physical entry pointers become a part of the micro-op’s overall state as it travels through the pipeline
RAT Details n n P 6 is 3 -way super-scalar, so the RAT must be able to rename up to six logical sources per cycle Any data dependences must be handled n n Ex: op 1) ADD EAX, EBX, ECX (dest. = EAX) op 2) ADD EAX, EDX op 3) ADD EDX, EAX, EDX Instead of making op 2 wait for op 1 to retire, the RAT provides data forwarding n Same case for op 3, but RAT must make sure that it gets the result from op 2 and not op 1
RAT Implementation Difficulties n Speculative Renaming n n Since speculative micro-ops flow by, the RAT must be able to undo its mappings in the case of a branch misprediction Partial-width register reads and writes n Consider a partial-width write followed by a larger-width read n n Retirement Overrides n n Data required by the read is an assimilation of multiple previous writes to the register – to make sure, RAT must stall the pipeline Common interaction between RAT and ROB When a micro-op retires, its ROB entry is removed and its result may be latched into an architected destination register If any active micro-ops source the retired op’s destination, they must not reference the outdated ROB entry Mismatch stalls n Associated with flag renaming
The Allocator n n Works in conjunction with RAT to allocate required entries In each cycle, assumes three ROB, RS, and LB and two SB entries n n ROB Allocation n n Once micro-ops arrive, it determines how many entries are really needed If three entries aren’t available the allocator will stall RS Allocation n n A bitmap is used to determine which entries are free If the RS is full, pipeline is stalled n n RS must make sure valid entries are not overwritten MOB Allocation n Allocation of LB and SB entries also done by allocator
PM Changes to P 6 Front-End Micro-op fusion n Dedicated Stack Engine n Enhanced branch prediction n Additional stages n Intel’s secret n Most likely required for extra functionality above n
Micro-ops Fusion n Fusion of multiple micro-ops into one micro-op n n n Similarity to SIMD data packing Two examples of fusion from Intel documentation: n n n Less contention for buffer entries IA 32 load-and-operate and store instructions Not known for certain whether these are the only cases of fusion Possibly inspired by Macro. Ops used in K 7 (Athlon)
Dedicated Stack Engine n n Traditional out-of-order implementations update the Stack Pointer Register (ESP) by sending a µop to update the ESP register with every stack related instruction Pentium M implementation n A delta register (ESPD) is maintained in the front end A historic ESP (ESPO) is then kept in the out-of-order execution core Dedicated logic was added to update the ESP by adding the ESPO with the ESPD
Improvements n n The ESPO value kept in the out-of-order machine is not changed during a sequence of stack operations, this allows for more parallelism opportunities to be realized Since ESPD updates are now done by a dedicated adder, the execution unit is now free to work on other µops and the ALU’s are freed to work on more complex operations Decreased power consumption since large adders are not used for small operations and the eliminated µops do not toggle through the machine Approximately 5% of the µops have been eliminated
Complications Since the new adder lives in the front end all of its calculations are speculative. This necessitates the addition of recovery table for all values of ESPO and ESPD n If the architectural value of ESP is needed inside of the out-of-order machine the decode logic then needs to insert a µop that will carry out the ESP calculation n
Branch Prediction Longer pipelines mean higher penalties for mispredicted branches n Improvements result in added performance and hence less energy spent per instruction retired n
Branch Prediction in Pentium M Enhanced version of Pentium 4 predictor n Two branch predictors added that run in tandem with P 4 predictor: n Loop detector n Indirect branch detector n n 20% lower misprediction rate than PIII resulting in up to 7% gain in real performance
Branch Prediction Based on diagram found here: http: //www. cpuid. org/reviews/Pentium. M/index. php
Loop Detector A predictor that always branches in a loop will always incorrectly branch on the last iteration n Detector analyzes branches for loop behavior n Benefits a wide variety of program types n http: //www. intel. com/technology/itj/2003/volume 07 i ssue 02/art 03_pentiumm/p 05_branch. htm
Indirect Branch Predictor Picks targets based on global flow control history n Benefits programs compiled to branch to calculated addresses n http: //www. intel. com/technology/itj/2003/volume 07 iss ue 02/art 03_pentiumm/p 05_branch. htm
Reservation Station n n Used as a store for µops to wait for their operands and execution units to become available Consists of 20 entries Control portion of the entry can be written to from one of three ports Data portion can be written to from one of 6 available ports n n 3 for ROB 3 for EU write backs Scheduler then uses this to schedule up to 5 µops at a time During pipeline stage 31 entries that are ready for dispatch are then sent to stage 32
Cancellation Reservation Station assumes that all cache accesses will be hits n In the case of a cache miss micro-ops that are dependant on the write-back data need to be cancelled and rescheduled at a later time n Can also occur due to a future resource conflict n
Retirement n n n Takes 2 clock cycles to complete Utilizes reorder buffer (ROB) to control retirement or completion of μops ROB is a multi-ported register file with separate ports for n n n Allocation time writes of µop fields needed at retirement Execution Unit write-backs ROB reads of sources for the Reservation Station Retirement logic reads of speculative result data Consists of 40 entries with each entry 157 bits wide The ROB participates in n Speculative execution Register renaming Out-of-order execution
Speculative Execution n Buffers results of the execution unit before commit Allows maximum rate for fetch and execute by assuming that branch prediction is perfect and no exceptions have occurred If a misprediction occurs: n n Speculative results stored in the ROB are immediately discarded Microengine will restart by examining the committed state in the ROB
Register Renaming Entries in the ROB that will hold the results of speculative µops are allocated during stage 21 of the pipeline n In stage 22 the sources for the µops are delivered based upon the allocation in stage 21. n Data is written to the ROB by the Execution Unit into the renamed register during stage 83 n
Out-of-order Execution n Allows µops to complete and write back their results without concern for other µops executing simultaneously The ROB reorders the completed µops into the original sequence and updates the architectural state Entries in ROB are treated as FIFO during retirement n n µops are originally allocated in sequential order so the retirement will also follow the original program order Happens during pipeline stage 92 and 93
Exception Handling n n n n Events are sent to the ROB by the EU during stage 83 Results sent to the ROB from the Execution Unit are speculative results, therefore any exceptions encountered may not be real If the ROB determines that branch prediction was incorrect it inserts a clear signal at the point just before the retirement of this operation and then flushes all the speculative operations from the machine If speculation is correct, the ROB will invoke the correct microcode exception handler All event records are saved to allow the handler to repair the result or invoke the correct macro handler Pointers for the macro and micro instructions are also needed to allow the program to resume after completion by the event handler If the ROB retires an operation that faults, both the in-order and out-oforder sections are cleared. This happens during pipeline stages 93 and 94
Memory Subsystem n Memory Ordering Buffer (MOB) n n n Execution is out-of-order, but memory accesses cannot just be done in any order Contains mainly the LB and the SB Speculative loads and stores n Not all loads can be speculative n n I. e. a memory-mapped I/O ld could have unrecoverable side effects Stores are never speculative (can’t get back overwritten bits) n But to improve performance, stores are queued in the store buffer (SB) to allow pending loads to proceed n Similar to a write-back cache
Schedule n P 6 Pipeline in detail Front-End n Execution Core n Back-End n n Power Issues n n Intel Speed. Step Testing the Features x 86 system registers n Performance Testing n
Power Issues n Power use = α * C * V 2 * F α = activity factor n C = effective capacitance n V = voltage n F = operating frequency n n Power use can be reduced linearly by lowering frequency and capacitance and quadratically by scaling voltage
Mobile Use Mobile is bursty – full power is only necessary for brief periods n Intel developed Speed. Step technology to take advantage of this fact and reduce power consumption during periods of inactivity n http: //www. intel. com/technology/itj/2003/volume 07 issue 02/art 05_power/p 05_thermal. htm
Speed. Step I and II n Speed. Step I and II used in previous generations n Only two states: n High performance (High frequency mode) n Lower power use (Low frequency mode) n Problems Slow transition times n Limited opportunity for optimization n
Pentium M Goals n n Optimize for performance when plugged in Optimize for long battery-life when unplugged Model Frequency (max / min) Vcore (max / min) Pentium M 1, 6 GHz / 600 MHz 1, 484 v / 0, 956 v Pentium M 1, 5 GHz / 600 MHz 1, 484 v / 0, 956 v Pentium M 1, 4 GHz / 600 MHz 1, 484 v / 0, 956 v Pentium M 1, 3 GHz / 600 MHz 1, 388 v / 0, 956 v Pentium M 1, 1 GHz Low Voltage 1, 1 GHz / 600 MHz 1, 180 v / 0, 956 v Pentium M 900 MHz Ultra Low Voltage 1, 6 GHz / 600 MHz 1, 004 v / 0, 844 v
Speed. Step III Optimized to fix limitations of Freq. Volt. 1. 6 GHz 1. 484 V previous generations n Three innovations: 1. 4 GHz 1. 42 V n n Voltage-Frequency switching separation n Clock partitioning and recovery n Event blocking 1. 2 GHz 1. 276 V 1 GHz 1. 164 V 800 MHz 1. 036 V 600 MHz 0. 956 V The 6 states of the Pentium M 1, 6 GHz
Voltage-Frequency switching separation Voltage scaling is stepped up and down incrementally n This prevents clock noise and allows the processor to remain responsive during transition n Once voltage target is reached, frequency is throttled n http: //www. intel. com/technology/itj/2003/volume 07 iss ue 02/art 03_pentiumm/p 10_speedstep. htm
Clock partitioning and recovery During transition, only the core clock and phaselocked-loop are stopped n This keeps logic active even while the clock is stopped n http: //www. intel. com/technology/itj/2003/volume 07 iss ue 02/art 03_pentiumm/p 10_speedstep. htm
Event blocking n n To prevent loss of events during frequency and voltage scaling when the core clock is stopped, interrupts, pin events, and snoop requests are sampled and saved These events are retransmitted once the core clock becomes available http: //www. intel. com/technology/itj/2003/volume 07 iss ue 02/art 03_pentiumm/p 10_speedstep. htm
Leakage Transistors in off state still draw current n As transistors shrink and clock speed increases, transistors leak more current causing higher temperatures and more power use n
Strained Silicon http: //www. research. ibm. com/resources/press/strainedsilicon/
Benefits of Strained Silicon Electrons flow up to 70% faster due to reduced resistance n This leads to chips which are up to 35% faster, without decrease in chip size n Intel’s "uni-axial" strained silicon process reduces leakage by at least five times without reducing performance – the 65 nm process will realize another reduction of at least four times n
High-K Transistor Gate Dielectric (coming soon) The dielectric used since the 1960 s, silicon dioxide, is so thin now that leakage is a significant problem n A high-k (high dielectric constant) material has been developed by Intel to replace silicon dioxide n This high-k material reduces leakage by a factor of 100 below silicon dioxide n
More Advances to Expect Continued lowering of capacitance has helped reduce power consumption n Tri-gate transistors decreases leakage by increasing the amount of surface area for electrons to flow through n
Schedule n P 6 Pipeline in detail Front-End n Execution Core n Back-End n n Power Issues n n Intel Speed. Step Testing the Features x 86 system registers n Performance Testing n
x 86 System Registers n EFLAGS n n CPUID n n Various system flags Exposes type and available features of processor Model Specific Registers (MSRs) n n rdmsr and wrmsr Examples n n n Enabling/Disabling Speed. Step Determining and changing voltage/frequency points More
Performance Testing n P 4 2. 2 GHz vs. PM 1. 6 GHz
Benchmark
Battery Life
Pentium M vs AMD Turion
Gaming
Battery Life
Future Processors n Yonah n n n Dual-core processor Manufactured on a 65 nm process Starting at 2. 16 GHz with a 667 MHz FSB (166 MHz quad-pumped) Shared 2 MB L 2 cache Increased floating point performance with SSE 3 instructions Merom n n n Based on EM 64 T ISA Consume ~0. 5 W of power, half of what the Dothan consumes Possibility of laptops with 10 hours of battery life