Introduction of Reinforcement Learning Deep Reinforcement Learning Reference















 Termination: all the aliens are")

 Usually there is some randomness in the")



























![[Sutton, v 2, Example 6. 4] MC v. s. TD • 0? 3/4? Monte-Carlo:](https://slidetodoc.com/presentation_image_h/734c00eeea83272dd49df061d427c9e4/image-47.jpg "[Sutton, v 2, Example 6. 4] MC v. s. TD • 0? 3/4? Monte-Carlo:")










- Slides: 57
Introduction of Reinforcement Learning
Deep Reinforcement Learning
Reference • Textbook: Reinforcement Learning: An Introduction • http: //incompleteideas. net/sutton/book/the-book. html • Lectures of David Silver • http: //www 0. cs. ucl. ac. uk/staff/D. Silver/web/Teaching. h tml (10 lectures, around 1: 30 each) • http: //videolectures. net/rldm 2015_silver_reinforcemen t_learning/ (Deep Reinforcement Learning ) • Lectures of John Schulman • https: //youtu. be/a. Ur. X-r. P_ss 4
Scenario of Reinforcement Learning Observation Action State Change the environment Agent Don’t do that Reward Environment
Scenario of Reinforcement Agent learns to take actions Learning maximizing expected reward. Observation Action State Change the environment Agent Thank you. https: //yoast. com/how-to -clean-site-structure/ Reward Environment
Machine Learning ≈ Looking for a Function Observation Function input Actor/Policy Action = π( Observation ) Used to pick the Reward best function Environment Action Function output
Learning to play Go Action Observation Reward Next Move Environment
Agent learns to take actions maximizing expected reward. Learning to play Go Action Observation Reward reward = 0 in most cases If win, reward = 1 If loss, reward = -1 Environment
Learning to play Go • Supervised: Learning from teacher Next move: “ 5 -5” • Reinforcement Learning First move Next move: “ 3 -3” Learning from experience …… many moves …… Win! (Two agents play with each other. ) Alpha Go is supervised learning + reinforcement learning.
Learning a chat-bot https: //image. freepik. com/free-vector/variety-of-human-avatars_232147506285. jpg http: //www. freepik. com/free-vector/variety-of-humanavatars_766615. htm • Machine obtains feedback from user How are you? Hello Bye bye Hi -10 3 • Chat-bot learns to maximize the expected reward
Learning a chat-bot • Let two agents talk to each other (sometimes generate good dialogue, sometimes bad) How old are you? See you. How old are you? I am 16. I though you were 12. What make you think so?
Learning a chat-bot • By this approach, we can generate a lot of dialogues. • Use some pre-defined rules to evaluate the goodness of a dialogue Dialogue 1 Dialogue 2 Dialogue 3 Dialogue 4 Dialogue 5 Dialogue 6 Dialogue 7 Dialogue 8 Machine learns from the evaluation Deep Reinforcement Learning for Dialogue Generation https: //arxiv. org/pdf/1606. 01541 v 3. pdf
Learning a chat-bot • Supervised “Hello” Say “Hi” “Bye bye” Say “Good bye” • Reinforcement ……. …… ……. Hello Agent …… Agent Bad
More applications • Flying Helicopter • https: //www. youtube. com/watch? v=0 JL 04 JJjocc • Driving • https: //www. youtube. com/watch? v=0 xo 1 Ldx 3 L 5 Q • Robot • https: //www. youtube. com/watch? v=370 c. T-OAzz. M • Google Cuts Its Giant Electricity Bill With Deep. Mind. Powered AI • http: //www. bloomberg. com/news/articles/2016 -07 -19/google-cuts-itsgiant-electricity-bill-with-deepmind-powered-ai • Text generation • https: //www. youtube. com/watch? v=pb. Q 4 qe 8 Ew. Lo
Example: Playing Video Game • Widely studies: • Gym: https: //gym. openai. com/ • Universe: https: //openai. com/blog/universe/ Machine learns to play video games as human players Ø What machine observes is pixels Ø Machine learns to take proper action itself
Example: Playing Video Game • Space invader Score (reward) Termination: all the aliens are killed, or your spaceship is destroyed. Kill the aliens shield fire
Example: Playing Video Game • Space invader • Play yourself: http: //www. 2600 online. com/spaceinvaders. html • How about machine: https: //gym. openai. com/evaluations/eval_Eduozx 4 H Ryqg. TCVk 9 ltw
Example: Playing Video Game (kill an alien) Usually there is some randomness in the environment
Example: Playing Video Game After many turns This is an episode. Game Over (spaceship destroyed) Learn to maximize the expected cumulative reward per episode
Properties of Reinforcement Learning • Reward delay • In space invader, only “fire” obtains reward • Although the moving before “fire” is important • In Go playing, it may be better to sacrifice immediate reward to gain more long-term reward • Agent’s actions affect the subsequent data it receives • E. g. Exploration
Outline Alpha Go: policy-based + value-based + model-based Model-free Approach Policy-based Learning an Actor Value-based Actor + Critic Model-based Approach Learning a Critic
Policy-based Approach Learning an Actor
Three Steps for Deep Learning Step 1: Step 2: define a set goodness of Neural Network of function function as Actor Deep Learning is so simple …… Step 3: pick the best function
Neural network as Actor • Input of neural network: the observation of machine represented as a vector or a matrix • Output neural network : each action corresponds to a neuron in output layer NN as actor … … left 0. 7 right 0. 2 fire 0. 1 Probability of taking the action pixels What is the benefit of using network instead of lookup table? generalization
Three Steps for Deep Learning Step 1: Step 2: define a set goodness of Neural Network of function function as Actor Deep Learning is so simple …… Step 3: pick the best function
Goodness of Actor Total Loss: • Review: Supervised learning Training Example “ 1” …… y 2 possible 0 …… target …… …… …… Softmax …… y 1 As close as 1 y 10 0
Goodness of Actor • Randomness in the actor and the game END
Goodness of Actor • left not related to your actor right fire 0. 1 0. 2 0. 7
Goodness of Actor • Sum over all possible trajectory
Three Steps for Deep Learning Step 1: Step 2: define a set goodness of Neural Network of function function as Actor Deep Learning is so simple …… Step 3: pick the best function
Gradient Ascent •
Policy Gradient It can even be a black box.
Policy Gradient •
Policy Gradient
Policy Gradient Update Model …… …… Data Collection
Policy Gradient Considered as Classification Problem s … … Minimize: left 1 right 0 fire 0 Maximize:
Policy Gradient …… …… left NN right fire 1 0 0 … …… …… left NN right fire 0 0 1
Policy Gradient 2 2 …… …… 1 1 NN NN … …… …… NN
Add a Baseline It is probability … Ideal case Sampling …… a b Not sampled a b c The probability of the actions not sampled will decrease. c a b c
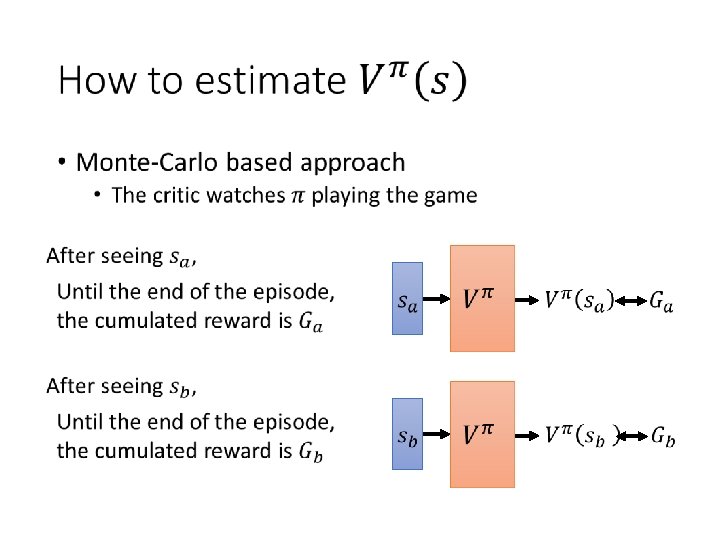
Value-based Approach Learning a Critic
Critic • An actor can be found from a critic. e. g. Q-learning http: //combiboilersleeds. com/picaso/critics-4. html
Critic • s scalar
Critic
• Temporal-difference approach - Some applications have very long episodes, so that delaying all learning until an episode's end is too slow.
MC v. s. TD … Larger variance unbiased Smaller variance May be biased
[Sutton, v 2, Example 6. 4] MC v. s. TD • 0? 3/4? Monte-Carlo: Temporal-difference: 3/4 (The actions are ignored here. ) 0 3/4
Another Critic • s a scalar s for discrete action only
Q-Learning TD or MC ?
Q-Learning • Ø Not suitable for continuous action a
Deep Reinforcement Learning Actor-Critic
Actor-Critic TD or MC
Actor-Critic • left Network right fire Network
Asynchronous Source of image: https: //medium. com/emergent -future/simple-reinforcement-learning-withtensorflow-part-8 -asynchronous-actor-criticagents-a 3 c-c 88 f 72 a 5 e 9 f 2#. 68 x 6 na 7 o 9 1. Copy global parameters 2. Sampling some data 3. Compute gradients 4. Update global models (other workers also update models)
Demo of A 3 C https: //www. youtube. com/watch? v=0 xo 1 Ldx 3 L 5 Q • Racing Car (Deep. Mind)
Demo of A 3 C • Visual Doom AI Competition @ CIG 2016 • https: //www. youtube. com/watch? v=94 EPSj. QH 38 Y
Concluding Remarks Model-free Approach Policy-based Learning an Actor Value-based Actor + Critic Model-based Approach Learning a Critic