GRAPH PROCESSING Why Graph Processing Graphs are everywhere

















 A ∞")
 + (1 e M")






 E")




























 Write (MB/s) Random Sequential Speed up")






























 Read Bandwidth - SSD 1000 900 800 700 600 500 400 300")
 600 500 X-Stream Graphchi 400 300")





 Lower is better BFS (32 M vertices/256 M edges)")


- Slides: 96
GRAPH PROCESSING
Why Graph Processing? Graphs are everywhere!
Why Graph Processing?
Why Distributed Graph Processing? They are getting bigger!
Road Scale >24 million vertices >58 million edges *Route Planning in Road Networks - 2008
Social Scale >1 billion vertices ~1 trillion edges *Facebook Engineering Blog ~41 million vertices >1. 4 billion edges *Twitter Graph- 2010
Web Scale >50 billion vertices >1 trillion edges *NSA Big Graph Experiment- 2013
Brain Scale >100 billion vertices >100 trillion edges *NSA Big Graph Experiment- 2013
Lumsdaine, Andrew, et al. "Challenges in parallel graph processing. " Parallel Processing Letters 17. 01 -2007 CHALLENGES IN PARALLEL GRAPH PROCESSING
Challenges 1 Structure driven computation 2 Irregular Structure Data Transfer Issues Partitioning Issues *Concept borrowed from Cristina Abad’s Ph. D defense slides
Overcoming the challenges 1 Extend Existing Paradigms 2 BUILD NEW FRAMEWORKS!
Build New Graph Frameworks! Key Requirements from Graph Processing Frameworks
1 2 3 4 5 Less pre-processing Low and load-balanced computation Low and load-balanced communication Low memory footprint Scalable wrt cluster size and graph size
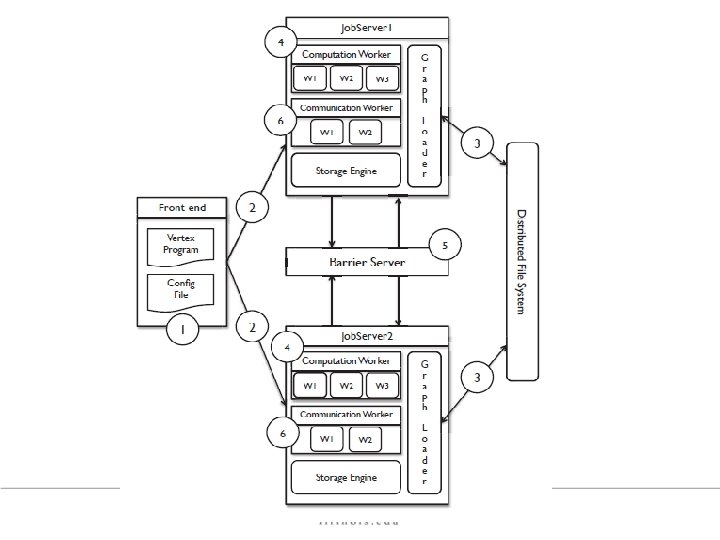
Malewicz, Grzegorz, et al. "Pregel: a system for large-scale graph processing. “ ACM SIGMOD -2010. PREGEL
Life of a Vertex Program Iteration 0 Placement Of Vertices Iteration 1 Computation Barrier Computation Communication Barrier Time *Concept borrowed from LFGraph Slides
Sample Graph B D A C E *Graph Borrowed from LFGraph Paper
Shortest Path Example B D A C E
Iteration 0 B 0 D ∞ M es sa ge (0+ 1) A ∞ C ∞ E ∞
Iteration 1 B 0 ge a ss D ∞ 1) + (1 e M A 1 C ∞ Me ssa ge (1+ 1) E ∞
Iteration 2 B 0 D 2 A 1 C ∞ E 2
Can we do better? GOAL PREGEL Computation 1 Pass Communication ∝ #Edge cuts Pre-processing Cheap (Hash) Memory High (out edges + buffered messages)
Hoque, Imranul, and Indranil Gupta. "LFGraph: Simple and Fast Distributed Graph Analytics”. TRIOS-2013 LFGRAPH – YES, WE CAN!
Features B D Cheap Vertex Placement: Hash Based A CLow graph initialization time. E
Features BPublish Subscribe fetch once D information flow A Low communication overhead C E
Subscribe B D A C Subscribing to vertex A E
Publish B D A C Publish List of Server 1: (Server 2, A) E
LFGraph Model B D A C Value of A E
Features B D Only stores in-neighbor vertices A C Reduces memory footprint. E
In-neighbor storage B Local in-neighbor – simply read the value C D A Remote in-neighbor – read locally available value E
Iteration 0 B 0 D ∞ A ∞ C ∞ E ∞
Iteration 1 B 0 C ∞ Re ad ad e R va lue e∞ u l va D ∞ 0 A ∞ 1 Value change in duplicate store Value of A E ∞
Iteration 2 B 0 D ∞ 2 Local read of A A 1 C ∞ Local read of A E ∞ 2
Features B Single Pass Computation D A C Low computation overhead. E
Life of a Vertex Program Iteration 0 Iteration 1 Placement Computation Communication Of Vertices Barrier Computation Communication Barrier Time *Concept Borrowed from LFGraph Slides
How everything Works
Low, Yucheng, et al. "Graphlab: A new framework for parallel machine learning”. Conference on Uncertainty in Artificial Intelligence (UAI) - 2010 GRAPHLAB
Graph. Lab Model B D A C D A E E
Can we do better? GOAL GRAPHLAB Computation 2 passes Communication ∝ #Vertex Ghosts Pre-processing Cheap (Hash) Memory High (in & out edges + ghost values)
Gonzalez, Joseph E. , et al. "Powergraph: Distributed graph-parallel computation on natural graphs. " USENIX OSDI - 2012. POWERGRAPH
Power. Graph Model B D A 1 C A 2 E
Can we do better? GOAL POWERGRAPH Computation 2 passes Communication ∝ #Vertex Mirrors Pre-processing Expensive (Intelligent) Memory High (in & out edges + mirror values)
Communication Analysis External on edge cuts Ghost vertices in and out neighbors Mirrors in and out neighbors External in neighbors
Computation Balance Analysis • Power Law graphs have substantial load imbalance. • Power law graphs have degree d with probability proportional to d-α. • Lower α means a denser graph with more high degree vertices.
Computation Balance Analysis
Computation Balance Analysis
Real World vs Power Law
Communication Balance Analysis
Page. Rank – Runtime w/o partition
Page. Rank – Runtime with partition
Page. Rank – Memory footprint
Page. Rank – Network Communication
Scalability
X-Stream: Edge-centric Graph Processing using Streaming Partitions * Some figures adopted from author’s presentation
Motivation • Can sequential access be used instead of random access? ! • Can large graph processing be done on a single machine? ! X-Stream
Sequential Access: Key to Performance! Medium Read (MB/s) Write (MB/s) Random Sequential Speed up RAM (1 core) 567 2605 4. 6 1057 2248 2. 2 RAM (16 core) 14198 25658 1. 9 10044 13384 1. 4 SSD 22. 5 667. 69 29. 7 48. 6 576. 5 11. 9 Magnetic Disk 0. 6 328 546. 7 2 316. 3 158. 2 Speed up of sequential access over random access in different media Test bed: 64 GB RAM + 200 GB SSD + 3 TB drive
How to Use Sequential Access? Edge-Centric Processing Sequential access …
Vertex-Centric Scatter U {state} Upda te u 1 U e at pd u 2 e un Updat for each vertex v if state has updated for each output edge e of v scatter update on e
Vertex-Centric Gather Upda pd at e Update v n te v 1 U v 2 V {state} {state 2} for each vertex v for each input edge e of v if e has an update apply update on state
Vertex-Centric x e d 1 5 In p 6 3 V 8 BFS 7 4 2 1 2 3 4 5 6 7 8 L ku o o SOURCE DEST 1 1 2 2 3 3 4 4 4 3 5 7 4 2 8 3 7 8 5 6 8 8 6 1 5 6
Edge-Centric Scatter Update u 1 A for each edge e if e. source has updated scatter update on e B Update un C = Updated Vertex
Edge-Centric Gather Update u 1 X Update u 2 for each update u on edge e apply update u to e. destination Y Update un Z = Updated Vertex
Sequential Access via Edge-Centric! In Slow Storage In Fast Storage In Slow Storage
Fast and Slow Storage
Edge-Centric 1 Lots 6 of wasted reads! 3 V 1 5 SOURCE DEST 1 1 2 2 3 3 4 4 4 3 5 7 4 2 8 3 7 8 5 6 8 8 6 1 5 6 Large makes 2 2 7 Diameter 3 X-Stream slow and wasteful 8 4 4 5 6 7 8 Most real world graphs have small diameter BFS
Order is not important SOURCE No DEST 1 3 1 5 2 7 2 4 3 2 pre-processing 3 8 4 3 4 7 4 8 5 6 8 8 6 1 5 6 SOURCE = (sorting and DEST 1 3 8 6 5 6 2 4 3 2 indexing) 4 7 4 3 3 8 4 8 2 6 8 1 needed! 7 1 5 5 66
But, still … • Random access for vertices • Vertices may not fit into fast storage n i m a e Str s n o i t g Par
Streaming Partitions V=Subset of vertices Mutually disjoint E=Outgoing edges of V Constant set U=Incoming updates to V Changing in each scatter phase
Scatter and Shuffle Fast Memory V 1 Load E 1 U 1 v 2 v 3 … Read source Stream e 1 e 2 e 3 … Vn En Un Input buffer Add update u 1 u 2 u 3 … … Vertex set Update buffer Shuffle u'1 u'2 u'3 … Append to updates Output buffer
Shuffle Stream Buffer with k partitions
Gather Fast Memory V 1 Load E 1 U 1 v 2 v 3 … Vertex set Apply update Stream u 1 u 2 u 3 … Update buffer No output!
Parallelism • State stored in vertices • Disjoint vertex set in partitions Compute partitions in parallel Parallel scatter and gather
Experimental Results
X-Stream Speedup over Graphchi RMAT 27/WCC Twitter/Belief Propagation Mean Speedup = 2. 3 Twitter/Pagerank Netflix/ALS 0 1 2 3 4 5 Speedup without considering the pre-process time of Graphchi 6
X-Stream Speedup over Graphchi RMAT 27/WCC Twitter/Belief Propagation Mean Speedup = 3. 7 Twitter/Pagerank Netflix/ALS 0 1 2 3 4 Speedup considering the pre-process time of Graphchi 5 6
3000 2500 2000 1500 1000 500 0 W 27 / AT el /B er itt Tw CC . . ie f. P ag /P er itt RM an er ix/ AL Tw ro p. k S Graphchi Sharding X-Stream runtime Ne tfl Time (sec) X-Stream Runtime vs Graphchi Sharding
Disk Transfer Rates Metric X-Stream Graphchi Data moved 224 GB 322 GB Time taken 398 seconds 2613 seconds Transfer rate 578 MB/s 126 MB/s Data transfer rates on Page Rank algorithm on Twitter workload SSD sustain reads = 667 MB/s, writes = 576 MB/s 77
Scalability on Input Data size 256 Million V, 4 Billion E, 33 mins 4 Billion V, 64 Billion E, 26 hours 8 Million V, 128 Million E, 8 sec RAM SSD Disk 4 M 76 B 8 M 15 B 36 M B 3 G B 6 G B 12 GB 24 GB 48 GB 96 GB 19 2 G 38 B 4 G 76 B 8 G B 1. 5 T B : 00: 01 : 30: 01 : 22: 31 : 05: 38 : 01: 25 : 00: 22 : 00: 06 : 00: 02 38 Time (HH: MM: SS) Weakly Connected Components
Discussion • Features like global values, aggregation functions, asynchronous computation missing from LFGraph. Will the overhead of adding these features slow it down? • LFGraph assumes that all edge values are same. If the edge values are not, either the receiving vertices or the server will have to incorporate that value. Overheads? • LFGraph has one pass computation but then it executes the vertex program at each vertex (active or inactive). Trade-off?
Discussion • Independent computation and communication rounds may not always be preferred. Use bandwidth when available. • Faul Tolerance is another feature missing from LFGraph. Overheads? • Three benchmarks for experiments. Enough evaluation? • Scalability comparison with Pregel with different experiment settings. Memory comparison with Power. Graph based on heap values from logs. Fair experiments?
Discussion • Could the system become asynchronous? • Could the scatter and gather phase be combined into one phase? • Does not support iterating over the edges/updates of a vertex. Can this be added? • How good do they determine number of partitions? • Can shuffle be optimized by counting the updates of each partition during scatter?
Thank you for listening! Questions?
Backup Slides
Reason for Improvement
Qualitative Comparison GOAL PREGEL GRAPHLAB POWERGRAPH LFGRAPH Computation 2 passes, Combiners 2 passes 1 pass Communication ∝ #Edge cuts ∝ #Vertex Ghosts ∝ #Vertex Mirrors ∝ #External inneighbors Pre-processing Cheap (Hash) Expensive (Intelligent) Cheap (Hash) Memory High (out edges + buffered messages) High (in & out edges + ghost values) High (in & out edges + mirror values) Low (in edges + remote values)
Backup Slides
Read (MB/s) Read Bandwidth - SSD 1000 900 800 700 600 500 400 300 200 100 0 X-Stream Graphchi 5 minute window
Write Bandwidth - SSD 800 700 Write (MB/s) 600 500 X-Stream Graphchi 400 300 200 100 0 5 minute window
Scalability on Thread Count
Scalability on Number of I/O Devices
Sharding-Computing Breakdown in Graphchi 1 0. 9 0. 8 0. 7 0. 6 0. 5 0. 4 0. 3 0. 2 0. 1 0 CC . . . Benchmark /W AT 27 RM ro ie f. P /B el er itt Tw Tw itt er /P tfl i ag e x/ ra pa nk AL S Compute + I/O Ne Fraction of Runtime Graphchi Runtime Breakdown Re-sort shard
X-Stream not Always Perfect
Large Diameter makes X-stream Slow!
In-Memory X-Stream Performance Runtime (s) Lower is better BFS (32 M vertices/256 M edges) 100 80 60 40 20 0 1 2 4 8 Threads 16 BFS-1 [HPC 2010] BFS-2 [PACT 2011] X-Stream
Ligra vs. X-Stream
Discussion • The current implementation is on a single machine, can it be extended to clusters? – Would it still perform good – How to provide fault tolerance and synchronization? • The waste rate is high (~65%). Could this be improved? • Can the partition be more intelligent? Dynamic partitioning? • Could all vertex-centric programs be converted to edge-centric? • When does streaming outperform random access?