Google Implementation Crawling Indexing Searching The problem of

Google Implementation Crawling Indexing Searching

The problem of information retrieval on the web The amount of information on the web is growing rapidly. Hard to remember the “link graph” User inexperienced in the art of web search
 - expensive to build")
The problem of some methods Human maintained indices (old Yahoo!) - expensive to build and maintain - slow to improve - can not cover all topics Some Automated search engines - too many low quality matches - long response time - misled by some advertisers
 Based on HTML")
Design goals of Google Scaling with web (40% pages are volatile) Based on HTML Rank the list order of information as needed by user Efficient index to provide short response time Academic research

System Features Two important features other than other search engines 1. Page. Rank – used for information ranking 2. Anchor Text – show the important information used for ranking

Page. Rank In the system, each Web pages on the Web has a rank Calculated by use of the link structure of the Web Keep static once all pages crawled

Page. Rank Define: We assume page A has pages T 1…Tn which point to it. The parameter d is a damping factor which can be set between 0 and 1(usually set to 0. 85). C(A) is defined as the number of links going out of page A. The Page. Rank of page A is: R(A) = (1 -d) + d * [R(T 1)/C(T 1)+…+R(Tn)/C(Tn)] Intuitive Justification

Anchor Text Most search engines associate the text of a link with page that the link is on In google, it is associated with the page it points to An example Advantage - more interests on the anchors - providing non-text based results

Web Crawling How do the web search engines get all of the items they index? Main idea: Start with known sites Record information for these sites Follow the links from each site Record information found at new sites Repeat

Web crawling Algorithm Put a set of known sites on a queue Repeat the following until the queue is empty Take the first page off of the queue If this page has not yet been processed Record the information on this page Add each link on the current page to the queue Record that this page has been processed

Standard Web Search Engine Architecture crawl the web Check for duplicates, store the documents Doc. Ids create an inverted index user query Show results To user Search engine servers Inverted index

Architecture
 by distributed crawlers, fetched web pages are compressed and stored")
Architecture Web downloading (crawl) by distributed crawlers, fetched web pages are compressed and stored into a repository Each web page has a unique doc. ID Indexer and Sorter perform the index function URLresolver

Architecture - indexer Reads the repository, uncompresses the web pages, and parses them Converts each web page into a set of word occurrences called hits Distributes hits into a set of barrels, creating a partially sorted forward index Parses out all links in every web pages and stores them in an anchors file

Architecture – URLresolver Reads the anchors file and converts relative URLs into absolute URLs and in turn into doc. IDs. Puts the Anchor Text into the forward index, associated with the doc. ID that the anchor points to Generates a links database containing pairs of doc. IDs used by Page. Rank calculating

Architecture – Sorter, lexicon, searcher Resorts hits in barrels to generate the inverted index Produces a list of word. IDs and offsets into the inverted index These lists + lexicon produced by indexer = a new lexicon Searcher is run by a web server, taking lexicon + inverted index + Page. Rank to answer queries

Data Structures Repository repository: || sync || length || compressed packet || packet: || docid || ecode || urllen || pagelen || url || page ||

Data Structure Hits, Forward index, Lexicon and Inverted index

Data Structure Hits - Two types of hits, fancy and plain, fancy means text occurs in URL, title, anchor text, or meta tag. - each type is represented in the table

Data Structure Forward index Falling into barrels, each barrel has a range of word. ID. If a document contains words that fall into a particular barrel, the doc. ID is recorded into the barrel, followed by a list of word. ID’s with hit lists which correspond to those words. Furthermore, instead of storing actual word. ID’s, it store each word. ID as a relative difference from the minimum word. ID.

Data structure Inverted Index The inverted index consists of the same barrels as the forward index, except that they have been processed by the sorter. For every valid word. ID, the lexicon contains a pointer into the barrel that word. ID falls into. It points to a doclist of doc. ID’s together with their corresponding hit lists. This doclist represents all the occurrences of that word in all documents. Important: what order the doc. IDs should appear in the doclist. Two ways.
 one by the doc. ID the other by a")
Data Structure Inverted Index (continue) one by the doc. ID the other by a ranking of the occurrence of the word in each document

Crawling the web Using A fast distributed crawling system. A single URLserver serves lists of URLs to a number of crawlers (typically 3). Each crawler keeps roughly 300 connections open at once. At peak speeds, the system can crawl over 100 web pages per second using four crawlers. Each crawler maintains a its own DNS cache so it does not need to do a DNS lookup before crawling each document. These factors make the crawler a complex component of the system. It uses asynchronous IO to manage events, and a number of queues to move page fetches from state to state.

Indexing the web Parsing For maximum speed, instead of using YACC to generate a CFG parser, it uses flex to generate a lexical analyzer. Indexing document into Barrels Every word is converted into a word. ID by using an inmemory hash table -- the lexicon. Extra words are stored in a small log file other than the base lexicon. Sorting In order to generate the inverted index, the sorter takes each of the forward barrels and sorts it by word. ID to produce an inverted barrel for title and anchor hits and a full text inverted barrel.

Searching Goal is providing quality search results efficiently, and focusing more on quality of search. 1. Parse the query. 2. Convert words into word. IDs. 3. Seek to the start of the doclist in the short barrel for every word. 4. Scan through the doclists until there is a document that matches all the search terms. 5. Compute the rank of that document for the query. 6. If in the short barrels and at the end of any doclist, it seeks to the start of the doclist in the full barrel for every word and go to step 4. 7. If not at the end of any doclist go to step 4. It sorts the documents that have matched by rank and return the top k.

Searching The ranking system For a single word query, Google looks at that document’s hit list for that word. Google considers each hit to be one of several different types (title, anchor, URL, plain text large font, plain text small font, . . . ), each of which has its own type-weight. The type-weights make up a vector indexed by type.

Searching The ranking system Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help. We take the dot product of the vector of count-weights with the vector of type-weights to compute an IR score for the document. Finally, the IR score is combined with Page. Rank to give a final rank to the document.

Searching The ranking system For a multi-word search, the multiple hit lists are scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together. For every matched set of hits, a proximity is computed. The proximity is based on how far apart the hits are in the document (or anchor) but is classified into 10 different value "bins" ranging from a phrase match to "not even close".

Searching The ranking system Counts are computed not only for every type of hit but for every type and proximity. Every type and proximity pair has a typeprox-weight. The counts are converted into count-weights. The dot product of the count-weights and the type-prox-weights are taken to compute an IR score.

Searching User feedback The ranking function has many parameters like the type-weights and the type-prox-weights. Figuring out the right values for these parameters is something of a black art. In order to do this, a user feedback mechanism is taken in Google. A trusted user may optionally evaluate all of the results that are returned. This feedback is saved. Then the ranking function is modified.

Results

Conclusions Google is designed to be a scalable search engine. The primary goal is to provide high quality search results over a rapidly growing World Wide Web. Google employs a number of techniques to improve search quality including page rank, anchor text, and proximity information. Furthermore, Google is a complete architecture for gathering web pages, indexing them, and performing search queries over them.

Directions of improvement Query caching, smart disk allocation, and sub-indices Efficient way of updating old web pages Adding Boolean operators User context and result summarization Relevance feedback and clustering
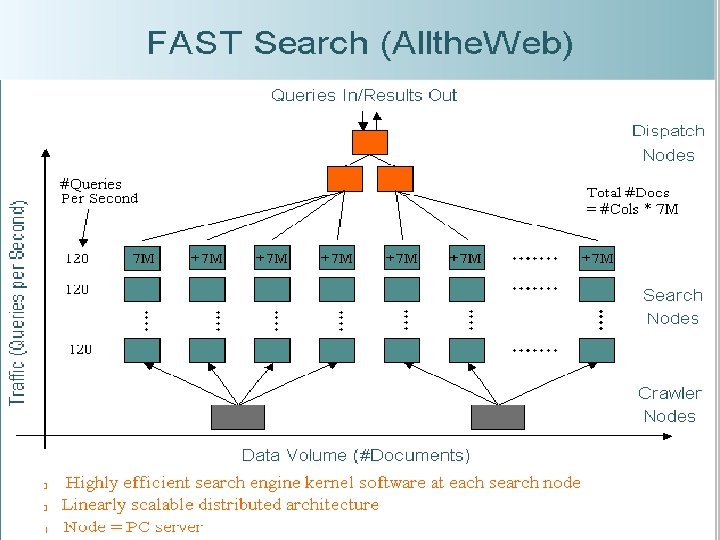

Example In this example, the data for the pages is partitioned across machines. Additionally, each partition is allocated multiple machines to handle the queries. Each row can handle 120 queries per second Each column can handle 7 M pages To handle more queries, add another row.
- Slides: 35