What is page importance Page importance is hard




")
 Matrix representation of operations I and O. Let A")
 Example: Initialize all scores to 1. 1 st Iteration:")
 After 2 Iterations: a(q 1) = 0. 061, a(q")

 Does the procedure converge? x x 2 xk As we multiply repeatedly with")
 eigen vectors? • Yes—just find a")
 submit q to a search engine to obtain")




 • Transverse link: links between pages with different domain names.")
, let V(p, q) be the")
 query: game Rank")
 • Rank based on large authority score. query: game Rank")
 Sample experiments (continued) • Rank based on large authority")

 Suppose h 0 and a 0 are all initialized to")


")
 Query: House (second community)")


 Basic Idea: Think")
 Example: Suppose the Web graph is: D C A A")



 Project part 1")


 • Authorities/Hubs – Motivation for approach – Algorithm –")
 • Page. Rank (score = w*PR + (1")

 Z will have 1/N For sink pages And 0 otherwise")

 Example: Suppose the Web graph is: D C A B")
 Example (continued): Suppose c = 0. 8. All entries in")


 and Robustness (w. r. t. Adversarial Change) of")




 • A powerful way we avoid")







 o o Pick the pages with the")



![Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] =](https://slidetodoc.com/presentation_image_h/26d7aa6d452ca43a3dfa497fd1b70b1d/image-65.jpg "Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] =")


 (16 bit) Destination")





![10/16 “I’m canvassing for Obama. If this [race] issue comes up, even if obliquely,](https://slidetodoc.com/presentation_image_h/26d7aa6d452ca43a3dfa497fd1b70b1d/image-74.jpg "10/16 “I’m canvassing for Obama. If this [race] issue comes up, even if obliquely,")
 Slides from http: //www. cs. huji. ac. il/~sdbi/2000/google/index. htm")



 • Repository – tradeoff between speed & compression ratio –")
 • Document Index – keeps information about each document –")
 • Lexicon – can fit in memory for reasonable price")
 • Hit Lists – includes position font & capitalization –")
 • Hit Lists (2)")
 • Forward Index – – – partially ordered used 64")
 • Inverted Index – 64 Barrels (same as the Forward")
 • Crawling the Web – – – fast distributed crawling")
 • Indexing the Web – Parsing • should know to")
 • Indexing Documents into Barrels – turning words into word.")
 • Indexing the Web – Sorting • creating the inverted")


 • Each Hit type has it’s own weight – Counts")





- Slides: 97
What is page importance? • Page importance is hard to define unilaterally such that it satisfies everyone. There are however some desiderata: – It should be sensitive to • The link structure of the web – Who points to it; who does it point to (~ Authorities/Hubs computation) – How likely are people going to spend time on this page (~ Page Rank computation) » E. g. Casa Grande is an ideal advertisement place. . • The amount of accesses the page gets – Third-party sites have to maintain these statistics which tend to charge for the data. . (see nielson-netratings. com) – To the extent most accesses to a site are through a search engine—such as google—the stats kept by the search engine should do fine • The query – Or at least the topic of the query. . • The user – Or at least the user population – It should be stable w. r. t. small random changes in the network link structure – It shouldn’t be easy to subvert with intentional changes to link structure How about: “Eloquence” “informativeness” “Trust-worthiness” “Novelty”
Dependencies between different importance measures. . • The “number of page accesses” measure is not fully subsumed by link-based importance – Mostly because some page accesses may be due to topical news • (e. g. aliens landing in the Kalahari Desert would suddenly make a page about Kalahari Bushmen more important than White House for the query “Bush”) – But, notice that if the topicality continues for a long period, then the link-structure of the web might wind up reflecting it (so topicality will thus be a “leading” measure) • • Generally, eloquence/informativeness etc of a page get reflected indirectly in the link-based importance measures You would think that trust-worthiness will be related to link-based importance anyway (since after all, who will link to untrustworthy sites)? – But the fact that web is decentralized and often adversarial means that trustworthiness is not directly subsumed by link structure (think “page farms” where a bunch of untrustworthy pages point to each other increasing their link-based importance) • Novelty wouldn’t be much of an issue if web is not evolving; but since it is, an important page will not be discovered by purely link-based criteria – # of page accesses might sometimes catch novel pages (if they become topically sensitive). Otherwise, you may want to add an “exploration” factor to the link-based ranking (i. e. , with some small probability p also show low page-rank pages of high query similarity)
Link-based Importance using “who cites and who is citing” idea • A page that is referenced by lot of important pages (has more back links) is more important (Authority) – A page referenced by a single important page may be more important than that referenced by five unimportant pages • A page that references a lot of important pages is also important (Hub) • “Importance” can be propagated Different Notions of importance – Your importance is the weighted sum of the importance conferred on you by the pages that refer to you – The importance you confer on a page may be proportional to how many other pages you refer to (cite) • (Also what you say about them when you cite them!) Qn: Can we assign consistent authority/hub values to pages?
Authorities and Hubs as mutually reinforcing properties • Authorities and hubs related to the same query tend to form a bipartite subgraph of the web graph. hubs authorities • Suppose each page has an authority score a(p) and a hub score h(p)
Authority and Hub Pages I: Authority Computation: for each page p: q 1 a(p) = q: (q, p) E h(q) q 2 q 3 O: Hub Computation: for each page p: h(p) = q: (p, q) E a(q) p A set of simultaneous equations… Can we solve these? p q 1 q 2 q 3
Authority and Hub Pages (8) Matrix representation of operations I and O. Let A be the adjacency matrix of SG: entry (p, q) is 1 if p has a link to q, else the entry is 0. Let AT be the transpose of A. Let hi be vector of hub scores after i iterations. Let ai be the vector of authority scores after i iterations. Operation I: ai = AT hi-1 Operation O: hi = A ai Normalize after every multiplication
Authority and Hub Pages (11) Example: Initialize all scores to 1. 1 st Iteration: q 1 p 1 I operation: q 2 a(q 1) = 1, a(q 2) = a(q 3) = 0, p 2 a(p 1) = 3, a(p 2) = 2 q 3 O operation: h(q 1) = 5, h(q 2) = 3, h(q 3) = 5, h(p 1) = 1, h(p 2) = 0 Normalization: a(q 1) = 0. 267, a(q 2) = a(q 3) = 0, a(p 1) = 0. 802, a(p 2) = 0. 535, h(q 1) = 0. 645, h(q 2) = 0. 387, h(q 3) = 0. 645, h(p 1) = 0. 129, h(p 2) =0
Authority and Hub Pages (12) After 2 Iterations: a(q 1) = 0. 061, a(q 2) = a(q 3) = 0, a(p 1) = 0. 791, a(p 2) = 0. 609, h(q 1) = 0. 656, h(q 2) = 0. 371, h(q 3) = 0. 656, h(p 1) = 0. 029, h(p 2) = 0 After 5 Iterations: q 1 p 1 a(q 1) = a(q 2) = a(q 3) = 0, q 2 p 2 a(p 1) = 0. 788, a(p 2) = 0. 615 q 3 h(q 1) = 0. 657, h(q 2) = 0. 369, h(q 3) = 0. 657, h(p 1) = h(p 2) = 0
What happens if you multiply a vector by a matrix? • In general, when you multiply a vector by a matrix, the vector gets “scaled” as well as “rotated” –. . except when the vector happens to be in the direction of one of the eigen vectors of the matrix –. . in which case it only gets scaled (stretched) • A (symmetric square) matrix has all real eigen values, and the values give an indication of the amount of stretching that is done for vectors in that direction • The eigen vectors of the matrix define a new ortho-normal space – You can model the multiplication of a general vector by the matrix in terms of • First decompose the general vector into its projections in the eigen vector directions –. . which means just take the dot product of the vector with the (unit) eigen vector • Then multiply the projections by the corresponding eigen values—to get the new vector. – This explains why power method converges to principal eigen vector. . • . . since if a vector has a non-zero projection in the principal eigen vector direction, then repeated multiplication will keep stretching the vector in that direction, so that eventually all other directions vanish by comparison. . Optional
(why) Does the procedure converge? x x 2 xk As we multiply repeatedly with M, the component of x in the direction of principal eigen vector gets stretched wrt to other directions. . So we converge finally to the direction of principal eigenvector Necessary condition: x must have a component in the direction of principal eigen vector (c 1 must be non-zero) The rate of convergence depends on the “eigen gap”
Can we power iterate to get other (secondary) eigen vectors? • Yes—just find a matrix M 2 such that M 2 has the same eigen vectors as M, but the eigen value corresponding to the first eigen vector e 1 is zeroed out. . Why? 1. M 2 e 1 = 0 2. If e 2 is the second eigen vector of M, then it is also an eigen vector of M 2 • Now do power iteration on M 2 • Alternately start with a random vector v, and find a new vector v’ = v – (v. e 1)e 1 and do power iteration on M with v’
Authority and Hub Pages Algorithm (summary) submit q to a search engine to obtain the root set S; expand S into the base set T; obtain the induced subgraph SG(V, E) using T; initialize a(p) = h(p) = 1 for all p in V; for each p in V until the scores converge { apply Operation I; apply Operation O; normalize a(p) and h(p); } return pages with top authority & hub scores;
10/7 Homework 2 due next class Mid-term 10/16
Base set computation can be made easy by storing the link structure of the Web in advance Link structure table (during crawling) --Most search engines serve this information now. (e. g. Google’s link: search) parent_url 1 child_url 2 url 3
Handling “spam” links Should all links be equally treated? Two considerations: • Some links may be more meaningful/important than other links. • Web site creators may trick the system to make their pages more authoritative by adding dummy pages pointing to their cover pages (spamming).
Handling Spam Links (contd) • Transverse link: links between pages with different domain names. Domain name: the first level of the URL of a page. • Intrinsic link: links between pages with the same domain name. Transverse links are more important than intrinsic links. Two ways to incorporate this: 1. Use only transverse links and discard intrinsic links. 2. Give lower weights to intrinsic links.
Considering link “context” For a given link (p, q), let V(p, q) be the vicinity (e. g. , 50 characters) of the link. • If V(p, q) contains terms in the user query (topic), then the link should be more useful for identifying authoritative pages. • To incorporate this: In adjacency matrix A, make the weight associated with link (p, q) to be 1+n(p, q), • • where n(p, q) is the number of terms in V(p, q) that appear in the query. Alternately, consider the “vector similarity” between V(p, q) and the query Q
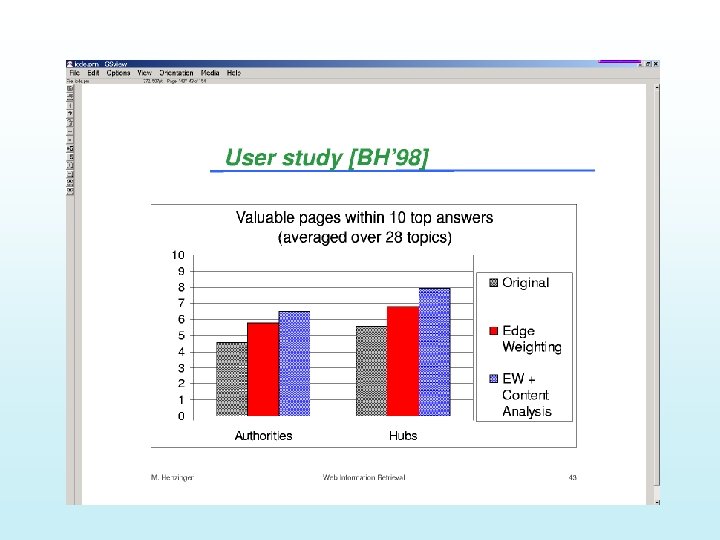
Evaluation Sample experiments: • Rank based on large in-degree (or backlinks) query: game Rank in-degree URL 1 13 http: //www. gotm. org 2 12 http: //www. gamezero. com/team-0/ 3 12 http: //ngp. ngpc. state. ne. us/gp. html 4 12 http: //www. ben 2. ucla. edu/~permadi/ gamelink/gamelink. html 5 11 http: //igolfto. net/ 6 11 http: //www. eduplace. com/geo/indexhi. html • Only pages 1, 2 and 4 are authoritative game pages.
Evaluation Sample experiments (continued) • Rank based on large authority score. query: game Rank Authority 1 0. 613 2 0. 390 3 4 5 6 0. 342 0. 324 0. 306 URL http: //www. gotm. org http: //ad/doubleclick/net/jump/ gamefan-network. com/ http: //www. d 2 realm. com/ http: //www. counter-strike. net http: //tech-base. com/ http: //www. e 3 zone. com • All pages are authoritative game pages.
Authority and Hub Pages (19) Sample experiments (continued) • Rank based on large authority score. query: free email Rank Authority URL 1 0. 525 http: //mail. chek. com/ 2 0. 345 http: //www. hotmail/com/ 3 0. 309 http: //www. naplesnews. net/ 4 0. 261 http: //www. 11 mail. com/ 5 0. 254 http: //www. dwp. net/ 6 0. 246 http: //www. wptamail. com/ • All pages are authoritative free email pages.
Tyranny of Majority Which do you think are Authoritative pages? Which are good hubs? -intutively, we would say that 4, 8, 5 will be authoritative pages and 1, 2, 3, 6, 7 will be hub pages. 1 2 3 4 5 6 7 8 ass m hub letely as d an omp ent, y xt t i e c n r n e o The power iteration will show that autho trat omp (See en rst c ase. e c h n T l co Only 4 and 5 have non-zero authorities e fi incre l i h t W ong ns o i [. 923. 382] t Am itera And only 1, 2 and 3 have non-zero hubs The e) [. 5. 7. 5] slid BUT
Tyranny of Majority (explained) Suppose h 0 and a 0 are all initialized to 1 m p 1 p 2 pm p n m>n q 1 qn q
Impact of Bridges. . 9 1 When the graph is disconnected, only 4 and 5 have non-zero authorities [. 923. 382] And only 1, 2 and 3 have non-zero hubs [. 5. 7. 5]CV 2 3 When the components are bridged by adding one page (9) the authorities change only 4, 5 and 8 have non-zero authorities [. 853. 224. 47] And o 1, 2, 3, 6, 7 and 9 will have non-zero hubs [. 39. 49. 39. 21. 6] 4 5 6 7 8 ew ting i m v ro t of put any f ws oin by een e n y p ed tw n i d x t a i e i g B bil e f k b yin pect sta an b k lin. (sa u ex ched. a C wea ages at yo e re age) a o p th o b p tw ence age t ther ess ry p ery o eve m ev fro
Finding minority Communities • How to retrieve pages from smaller communities? A method for finding pages in nth largest community: – Identify the next largest community using the existing algorithm. – Destroy this community by removing links associated with pages having large authorities. – Reset all authority and hub values back to 1 and calculate all authority and hub values again. – Repeat the above n 1 times and the next largest community will be the nth largest community.
Multiple Clusters on “House” Query: House (first community)
Authority and Hub Pages (26) Query: House (second community)
Page. Rank
The importance of publishing. . • A/H algorithm was published in SODA as well as JACM – Kleinberg became very famous in the scientific community (and got a Mc. Arthur Genius award) • Pagerank algorithm was rejected from SIGIR and was never explicitly published – Larry Page never got a genius award or even a Ph. D • `(and had to be content with being a mere billionaire)
Page. Rank (Importance as Stationary Visit Probability on a Markov Chain) Basic Idea: Think of Web as a big graph. A random surfer keeps randomly clicking on the links. The importance of a page is the probability that the surfer finds herself on that tor page c e nv ary e g --Talk of transition matrix instead of adjacency matrix ei tion l a ip e sta c n Transition matrix M derived from adjacency matrix A Pri es th ion! t --If there are F(u) forward links from a page u, Giv tribu dis then the probability that the surfer clicks on any of those is 1/F(u) (Columns sum to 1. Stochastic matrix) [M is the normalized version of At] --But even a dumb user may once in a while do something other than follow URLs on the current page. . --Idea: Put a small probability that the user goes off to a page not pointed to by the current page.
Computing Page. Rank (10) Example: Suppose the Web graph is: D C A A A= B C D A 0 0 0 1 B 0 0 0 1 C 1 1 0 0 B D 0 0 1 0 A B M =C D A 0 0 1 0 B 0 0 1 0 C 0 0 0 1 D ½ ½ 0 0
Computing Page. Rank If the ranks converge, i. e. , there is a rank vector R such that R = M R, for e u l a v n l eige R is the eigenvector of matrix Principa Mmawith ix is 1 r t c i t s A stocha eigenvalue being 1.
Computing Page. Rank Matrix representation Let M be an N N matrix and muv be the entry at the u-th row and v-th column. muv = 1/Nv if page v has a link to page u muv = 0 if there is no link from v to u Let Ri be the N 1 rank vector for I-th iteration and R 0 be the initial rank vector. Then Ri = M Ri-1
Computing Page. Rank If the ranks converge, i. e. , there is a rank vector R such that R = M R, R is the eigenvector of matrix M with eigenvalue being 1. for e u l a v n l eige Principa ix is 1 r t a m c i t s A stocha Convergence is guaranteed only if • M is aperiodic (the Web graph is not a big cycle). This is practically guaranteed for Web. • M is irreducible (the Web graph is strongly connected). This is usually not true .
10/9 Happy Dasara! Class Survey (return by the end of class) Project part 1 returned; Part 2 assigned
Project A – Stats Project 1 Stats 20 18 16 # of Students 14 12 10 8 6 4 2 0 0 -5 6 -10 11 -15 16 -20 21 -25 Score • Max: • Min: • Avg: 40 26 34. 6 26 -30 31 -35 36 -40
Project B – What’s Due When? • Date Today: • Due Date: 2008 -10 -09 2008 -10 -30 • What’s Due? – Commented Source Code (Printout) – Results of Example Queries for A/H and Page. Rank (Printout of at least the score and URL) – Report • More than just an algorithm…
Project B – Report (Auth/Hub) • Authorities/Hubs – Motivation for approach – Algorithm – Experiment by varying the size of root set (start with k=10) – Compare/analyze results of A/H with those given by Vector Space – Which results are more relevant: Authorities or Hubs? Comments?
Project B – Report (Page. Rank) • Page. Rank (score = w*PR + (1 -w)*VS) – Motivation for approach – Algorithm – Compare/analyze results of Page. Rank+VS with those given by A/H – What are the effects of varying “w” from 0 to 1? – What are the effects of varying “c” in the Page. Rank calculations? – Does the Page. Rank computation converge?
Project B – Coding Tips • Download new link manipulation classes – Link. Extract. java – extracts links from Hashed. Links file – Link. Gen. java – generates the Hashed. Links file • Only need to consider terms where – term. field() == “contents” • Increase JVM Heap Size – “java –Xmx 512 m program. Name”
Computing Page. Rank (8) Z will have 1/N For sink pages And 0 otherwise (RESET Matrix) K will have 1/N For all entries M*= c (M + Z) + (1 – c) x K • M* is irreducible. • M* is stochastic, the sum of all entries of each column is 1 and there are no negative entries. Therefore, if M is replaced by M* as in Ri = M* Ri-1 then the convergence is guaranteed and there will be no loss of the total rank (which is 1).
• Markov Chains & Random Surfer Model Markov Chains & Stationary distribution – Necessary conditions for existence of unique steady state distribution: Aperiodicity and Irreducibility – Aperiodicity it is not a big cycle – Irreducibility: Each node can be reached from every other node with non-zero probability • Must not have sink nodes (which have no out links) » – • Because we can have several different steady state distributions based on which sink we get stuck in If there are sink nodes, change them so that you can transition from them to every other node with low probability Must not have disconnected components » – – Because we can have several different steady state distributions depending on which disconnected component we get stuck in Sufficient to put a low probability link from every node to every other node (in addition to the normal weight links corresponding to actual hyperlinks) This can be used as the “reset” distribution—the probability that the surfer gives up navigation and jumps to a new page • The parameters of random surfer model – c the probability that surfer follows the page • The larger it is, the more the surfer sticks to what the page says – M the way link matrix is converted to markov chain • Can make the links have differing transition probability – E. g. query specific links have higher prob. Links in bold have higher prop etc – K the reset distribution of the surfer (great thing to tweak) • • It is quite feasible to have m different reset distributions corresponding to m different populations of users (or m possible topic-oriented searches) It is also possible to make the reset distribution depend on other things such as – – trust of the page [Trust. Rank] Recency of the page [Recencysensitive rank]
Computing Page. Rank (10) Example: Suppose the Web graph is: D C A B M =C D A 0 0 1 0 B 0 0 1 0 C 0 0 0 1 D ½ ½ 0 0
Computing Page. Rank (11) Example (continued): Suppose c = 0. 8. All entries in Z are 0 and all entries in K are ¼. 0. 05 0. 45 0. 85 0. 05 M* = 0. 8 (M+Z) + 0. 2 K = 0. 05 0. 85 0. 05 Compute rank by iterating MATLAB says: R : = M*x. R R(A)=. 338 R(B)=. 338 R(C)=. 6367 R(D)=. 6052
Combining PR & Content similarity Incorporate the ranks of pages into the ranking function of a search engine. • The ranking score of a web page can be a weighted sum of its regular similarity with a query and its importance. ranking_score(q, d) = w sim(q, d) + (1 -w) R(d), if sim(q, d) > 0 = 0, otherwise ? w s set o where 0 < w < 1. Wh – Both sim(q, d) and R(d) need to be normalized to between [0, 1].
We can pick and choose • Two alternate ways of computing page importance – I 1. As authorities/hubs – I 2. As stationary distribution over the underlying markov chain • Two alternate ways of combining importance with similarity – C 1. Compute importance over a set derived from the top-100 similar pages – C 2. Combine apples & organges • a*importance + b*similarity We can pick any pair of alternatives (even though I 1 was originally proposed with C 1 and I 2 with C 2)
Stability (w. r. t. random change) and Robustness (w. r. t. Adversarial Change) of Link Importance measures • For random changes (e. g. a randomly added link etc. ), we know that stability depends on ensuring that there are no disconnected components in the graph to begin with (e. g. the “standard” A/H computation is unstable w. r. t. bridges if there are disconnected componets—but become more stable if we add lowweight links from every page to every other page—to capture transitions by impatient user) • For adversarial changes (where someone with an adversarial intent makes changes to link structure of the web, to artificially boost the importance of certain pages), – It is clear that query specific importance measures (e. g. computed w. r. t. a base set) will be harder to sabotage. – In contrast query (and user-) independent similarity measures are easier (since they provide a more stationary target).
Effect of collusion on Page. Rank C A B B Assuming a=0. 8 and K=[1/3] Rank(A)=Rank(B)=Rank(C)= 0. 5774 Rank(A)=0. 37 Rank(B)=0. 6672 Rank(C)=0. 6461 Moral: By referring to each other, a cluster of pages can artificially boost their rank (although the cluster has to be big enough to make an appreciable difference. Solution: Put a threshold on the number of intra-domain links that will count Counter: Buy two domains, and generate a cluster among those. . Solution: Google dance manually change the page rank once in a while… Counter: Sue Google!
Page. Rank Variants • Topic-specific page rank – Think of this as a middle-ground between one-size-fits-all page rank and query-specific page rank • Trust rank – Think of this as a middle-ground between one-size-fits-all page rank and user-specific page rank • Recency Rank – Allow recently generated (but probably high-quality) pages to break-through. . • ALL of these play with the reset distribution (i. e. , the distribution that tells what the random surfer does when she gets bored following links)
Topic Specific Pagerank • • For each page compute k different page ranks – K= number of top level hierarchies in the Open Directory Project – When computing Page. Rank w. r. t. to a topic, say that with e probability we transition to one of the pages of the topick When a query q is issued, – Compute similarity between q (+ its context) to each of the topics – Take the weighted combination of the topic specific page ranks of q, weighted by the similarity to different topics la, a iw 002 l e v 2 Ha W W W
Spam is a serious problem… • We have Spam Spam with Eggs and Spam – in Email • Most mail transmitted is junk – web pages • Many different ways of fooling search engines • This is an open arms race – Annual conference on Email and Anti-Spam • Started 2004 – Intl. workshop on AIR-Web (Adversarial Info Retrieval on Web) • Started in 2005 at WWW
Trust & Spam (Knock-Knock. Who is there? ) • A powerful way we avoid spam in our physical world is by preferring interactions only with “trusted” parties – Trust is propagated over social networks • When knocking on the doors of strangers, the first thing we do is to identify ourselves as a friend of friend … – So they won’t train their dogs/guns on us. . • We can do it in cyber world too • Accept product recommendations only from trusted parties – E. g. Epinions • Accept mails only from individuals who you trust above a certain threshold • Bias page importance computation so that it counts only links from “trusted” sites. . – Sort of like discounting links that are “off topic” Knock Who’s there? Aardvark. Okay. (Open Door) Not Funny Aardvark WHO? Aardvark a million miles to see you smile!
Trust. Rank idea o Tweak the “default” distribution used in page rank computation (the distribution that a bored user uses when she doesn’t want to follow the links) n n From uniform To “Trust based” o Very similar in spirit to the Topic-sensitive or Usersensitive page rank n o o o Where too you fiddle with the default distribution Sample a set of “seed pages” from the web Have an oracle (human) identify the good pages and the spam pages in the seed set n o [Gyongyi et al, VLDB 2004] Expensive task, so must make seed set as small as possible Propagate Trust (one pass) Use the normalized trust to set the initial distribution Slides modified from Anand Rajaraman’s lecture at Stanfor
Example 1 2 3 good 4 5 6 bad 7 Assumption: Bad pages are “isolated” from “good” pages. . (and vice versa)
10/14 Everything upto & including social networks Probably open-book Typically long Agenda: Trust rank Efficient computation of page rank Discussion of google architecture as a whole
Trust Propagation • Trust is “transitive” so easy to propagate –. . but attenuates as it traverses as a social network • If I trust you, I trust your friend (but a little less than I do you), and I trust your friend’s friend even less • Trust may not be symmetric. . • Trust is normally additive – If you are friend of two of my friends, may be I trust you more. . • Distrust is difficult to propagate – If my friend distrusts you, then I probably distrust you – …but if my enemy distrusts you? • …is the enemy of my enemy automatically my friend? • Trust vs. Reputation – “Trust” is a user-specific metric • Your trust in an individual may be different from someone else’s – “Reputation” can be thought of as an “aggregate” or one-size-fits-all version of Trust • Most systems such as EBay tend to use Reputation rather than Trust – Sort of the difference between User-specific vs. Global page rank
Rules for trust propagation o Trust attenuation n o Trust splitting n n o The larger the number of outlinks from a page, the less scrutiny the page author gives each outlink Trust is “split” across outlinks Combining splitting and damping, each out link of a node p gets a propagated trust of: b*t(p)/|O(p)| n o The degree of trust conferred by a trusted page decreases with distance 0<b<1; O(p) is the out degree and t(p) is the trust of p Trust additivity n Propagated trust from different directions is added up
Picking the seed set o Two conflicting considerations n n Human has to inspect each seed page, so seed set must be as small as possible Must ensure every “good page” gets adequate trust rank, so need make all good pages reachable from seed set by short paths
Approaches to picking seed set o o Suppose we want to pick a seed set of k pages The best idea would be to pick them from the top-k hub pages. n Note that “trustworthiness” is subjective o o Al jazeera may be considered more trustworthy than NY Times by some (and the reverse by others) Page. Rank n n n Pick the top k pages by page rank Assume high page rank pages are close to other highly ranked pages We care more about high page rank “good” pages
Inverse page rank (= Hub? ? ) o o Pick the pages with the maximum number of outlinks Can make it recursive n o Formalize as “inverse page rank” n n o Pick pages that link to pages with many outlinks Construct graph G’ by reversing each edge in web graph G Page Rank in G’ is inverse page rank in G Pick top k pages by inverse page rank
Efficient Computation of Pagerank How to power-iterate on the webscale matrix?
Efficient Computation: Preprocess • Remove ‘dangling’ nodes – Pages w/ no children • Then repeat process – Since now more danglers • Stanford Web. Base – 25 M pages – 81 M URLs in the link graph – After two prune iterations: 19 M nodes
Representing ‘Links’ Table • Stored on disk in binary format Source node (32 bit int) Outdegree (16 bit int) Destination nodes (32 bit int) 0 4 12, 26, 58, 94 1 3 5, 56, 69 2 5 1, 9, 10, 36, 78 • Size for Stanford Web. Base: 1. 01 GB – Assumed to exceed main memory
Algorithm 1 = Dest dest node source node Links (sparse) Source s Source[s] = 1/N while residual > { d Dest[d] = 0 while not Links. eof() { Links. read(source, n, dest 1, … destn) for j = 1… n Dest[destj] = Dest[destj]+Source[source]/n } d Dest[d] = c * Dest[d] + (1 -c)/N /* dampening */ residual = Source – Dest /* recompute every few iterations */ Source = Dest }
Analysis of Algorithm 1 • If memory is big enough to hold Source & Dest – IO cost per iteration is | Links| – Fine for a crawl of 24 M pages – But web ~ 800 M pages in 2/99 [NEC study] – Increase from 320 M pages in 1997 [same authors] • If memory is big enough to hold just Dest – Sort Links on source field – Read Source sequentially during rank propagation step – Write Dest to disk to serve as Source for next iteration – IO cost per iteration is | Source| + | Dest| + | Links| • If memory can’t hold Dest – Random access pattern will make working set = | Dest| – Thrash!!!
Block-Based Algorithm • Partition Dest into B blocks of D pages each – If memory = P physical pages – D < P-2 since need input buffers for Source & Links • Partition Links into B files – Linksi only has some of the dest nodes for each source – Linksi only has dest nodes such that • DD*i <= dest < DD*(i+1) • Where DD = number of 32 bit integers that fit in D pages = Dest dest node source node Links (sparse) Source
Partitioned Link File Source node Outdegr Num out (32 bit int) (16 bit) Destination nodes (32 bit int) 0 1 2 4 3 5 2 1 3 12, 26 5 1, 9, 10 0 1 2 4 3 5 1 1 1 58 56 36 0 1 2 4 3 5 1 1 1 94 69 78 Buckets 0 -31 Buckets 32 -63 Buckets 64 -95
Block-based Page Rank algorithm
Analysis of Block Algorithm • IO Cost per iteration = – B*| Source| + | Dest| + | Links|*(1+e) – e is factor by which Links increased in size • Typically 0. 1 -0. 3 • Depends on number of blocks • Algorithm ~ nested-loops join
Comparing the Algorithms
Efficient computation: Prioritized Sweeping We can use asynchronous iterations where the iteration uses some of the values updated in the current iteration
Summary of Key Points • Page. Rank Iterative Algorithm • Rank Sinks • Efficiency of computation – Memory! – Single precision Numbers. – Don’t represent M* explicitly. – Break arrays into Blocks. – Minimize IO Cost. • Number of iterations of Page. Rank. • Weighting of Page. Rank vs. doc similarity.
10/16 “I’m canvassing for Obama. If this [race] issue comes up, even if obliquely, I emphasize that Obama is from a multiracial background and that his father was an African intellectual, not an American from the inner city. ” --NY Times quoting an Obama Campaign Worker 10/14/08
Anatomy of Google (circa 1999) Slides from http: //www. cs. huji. ac. il/~sdbi/2000/google/index. htm
Some points… • Fancy hits? • Why two types of barrels? • How is indexing parallelized? • How does Google show that it doesn’t quite care about recall? • How does Google avoid crawling the same URL multiple times? • What are some of the memory saving things they do? • Do they use TF/IDF? • Do they normalize? (why not? ) • Can they support proximity queries? • How are “page synopses” made?
Google Search Engine Architecture SOURCE: BRIN & PAGE URL Server- Provides URLs to be fetched Crawler is distributed Store Server - compresses and stores pages for indexing Repository - holds pages for indexing (full HTML of every page) Indexer - parses documents, records words, positions, font size, and capitalization Lexicon - list of unique words found Hit. List – efficient record of word locs+attribs Barrels hold (doc. ID, (word. ID, hit. List*)*)* sorted: each barrel has range of words Anchors - keep information about links found in web pages URL Resolver - converts relative URLs to absolute Sorter - generates Doc Index - inverted index of all words in all documents (except stop words) Links - stores info about links to each page (used for Pagerank) Pagerank - computes a rank for each page retrieved Searcher - answers queries
Major Data Structures • Big Files – virtual files spanning multiple file systems – addressable by 64 bit integers – handles allocation & deallocation of File Descriptions since the OS’s is not enough – supports rudimentary compression
Major Data Structures (2) • Repository – tradeoff between speed & compression ratio – choose zlib (3 to 1) over bzip (4 to 1) – requires no other data structure to access it
Major Data Structures (3) • Document Index – keeps information about each document – fixed width ISAM (index sequential access mode) index – includes various statistics • pointer to repository, if crawled, pointer to info lists – compact data structure – we can fetch a record in 1 disk seek during search
Major Data Structures (4) • Lexicon – can fit in memory for reasonable price • currently 256 MB • contains 14 million words • 2 parts – a list of words – a hash table
Major Data Structures (4) • Hit Lists – includes position font & capitalization – account for most of the space used in the indexes – 3 alternatives: simple, Huffman , handoptimized – hand encoding uses 2 bytes for every hit
Major Data Structures (4) • Hit Lists (2)
Major Data Structures (5) • Forward Index – – – partially ordered used 64 Barrels each Barrel holds a range of word. IDs requires slightly more storage each word. ID is stored as a relative difference from the minimum word. ID of the Barrel – saves considerable time in the sorting
Major Data Structures (6) • Inverted Index – 64 Barrels (same as the Forward Index) – for each word. ID the Lexicon contains a pointer to the Barrel that word. ID falls into – the pointer points to a doclist with their hit list – the order of the doc. IDs is important • by doc. ID or doc word-ranking – Two inverted barrels—the short barrel/full barrel
Major Data Structures (7) • Crawling the Web – – – fast distributed crawling system URLserver & Crawlers are implemented in phyton each Crawler keeps about 300 connection open at peek time the rate - 100 pages, 600 K per second uses: internal cached DNS lookup – synchronized IO to handle events – number of queues – Robust & Carefully tested
Major Data Structures (8) • Indexing the Web – Parsing • should know to handle errors – – HTML typos kb of zeros in a middle of a TAG non-ASCII characters HTML Tags nested hundreds deep • Developed their own Parser – involved a fair amount of work – did not cause a bottleneck
Major Data Structures (9) • Indexing Documents into Barrels – turning words into word. IDs – in-memory hash table - the Lexicon – new additions are logged to a file – parallelization • shared lexicon of 14 million pages • log of all the extra words
Major Data Structures (10) • Indexing the Web – Sorting • creating the inverted index • produces two types of barrels at s – for titles and anchor (Short barrels) ok irst s o l g els f rrel n i – for full text (full barrels) nk barr ll ba a R rt fu o n sorts every barrel separately Sh d the n A running sorters at parallel • • • the sorting is done in main memory
Searching • Algorithm – – –. 5 Compute the rank of that 1. Parse the query document 2. Convert word into – 6. If we’re at the end of the word. IDs short barrels start at the doclists of the full barrel, 3. Seek to the start of unless we have enough the doclist in the short barrel for every word – 7. If were not at the end of any doclist goto step 4 4. Scan through the doclists until there is a – 8. Sort the documents by rank document that return the top K matches all of the • (May jump here after 40 k pages) search terms
The Ranking System • The information – Position, Font Size, Capitalization – Anchor Text – Page. Rank • Hits Types – title , anchor , URL etc. . – small font, large font etc. .
The Ranking System (2) • Each Hit type has it’s own weight – Counts weights increase linearly with counts at first but quickly taper off this is the IR score of the doc – (IDF weighting? ? ) • the IR is combined with Page. Rank to give the final Rank • For multi-word query – A proximity score for every set of hits with a proximity type weight • 10 grades of proximity
Feedback • A trusted user may optionally evaluate the results • The feedback is saved • When modifying the ranking function we can see the impact of this change on all previous searches that were ranked
Results • Produce better results than major commercial search engines for most searches • Example: query “bill clinton” – – – return results from the “Whitehouse. gov” email addresses of the president all the results are high quality pages no broken links no bill without clinton & no clinton without bill
Storage Requirements • Using Compression on the repository • about 55 GB for all the data used by the SE • most of the queries can be answered by just the short inverted index • with better compression, a high quality SE can fit onto a 7 GB drive of a new PC
Storage Statistics Web Page Statistics
System Performance • • • It took 9 days to download 26 million pages 48. 5 pages per second The Indexer & Crawler ran simultaneously The Indexer runs at 54 pages per second The sorters run in parallel using 4 machines, the whole process took 24 hours