Study on Deep Learning in Speaker Recognition Lantian


![Biometric recognition • Biometric refers to metrics related to human characteristics [wiki]. Term "biometrics"](https://slidetodoc.com/presentation_image/286dd16d7afc8a968d9eade58b179f31/image-3.jpg "Biometric recognition • Biometric refers to metrics related to human characteristics [wiki]. Term \"biometrics\"")















 higher-level phonetic")













 ² A contrastive triple ² Max-margin")
 • Hamming distance learning")







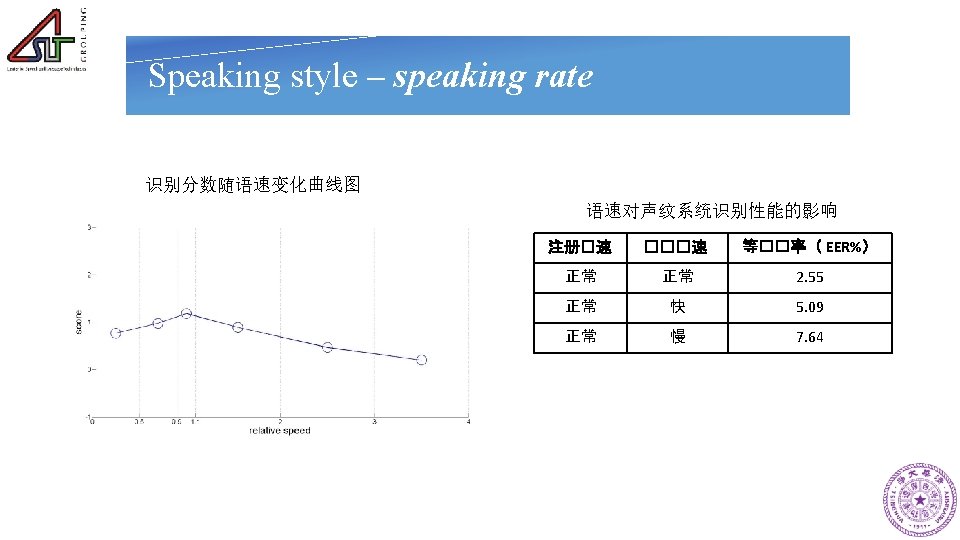
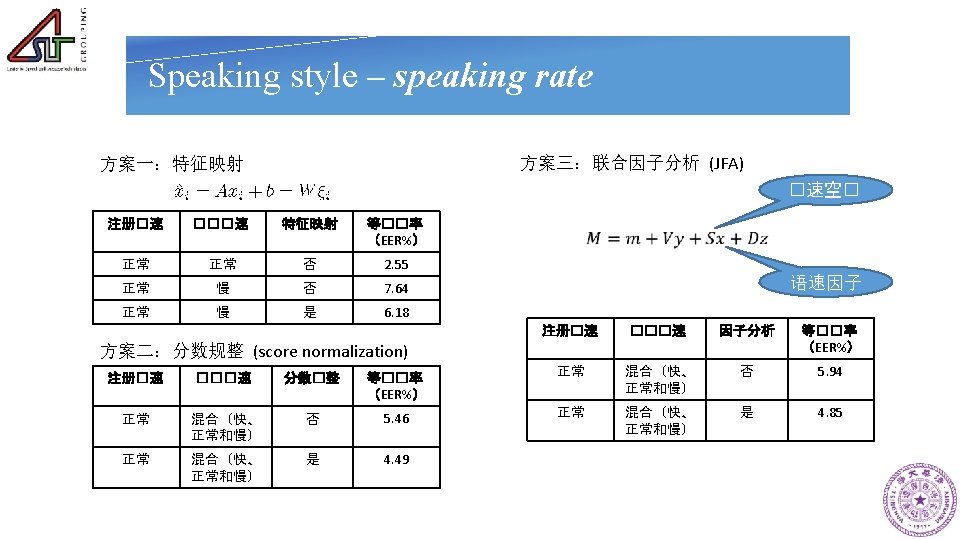
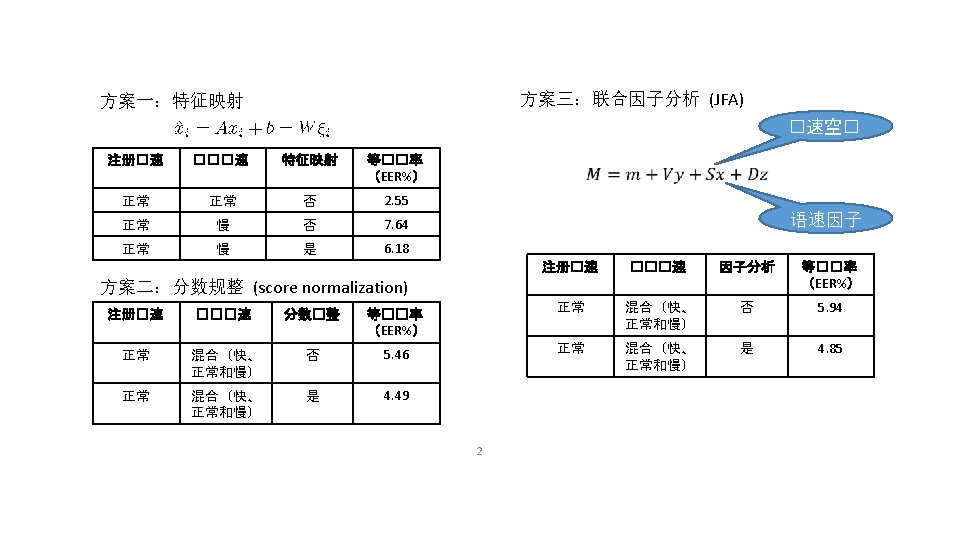



- Slides: 51
Study on Deep Learning in Speaker Recognition Lantian Li CSLT / RIIT Tsinghua University lilt@cslt. riit. tsinghua. edu. cn April 24, 2017
Outline • Biometric Recognition • Speaker Recognition • Deep Learning in Speaker Recognition • Prospects
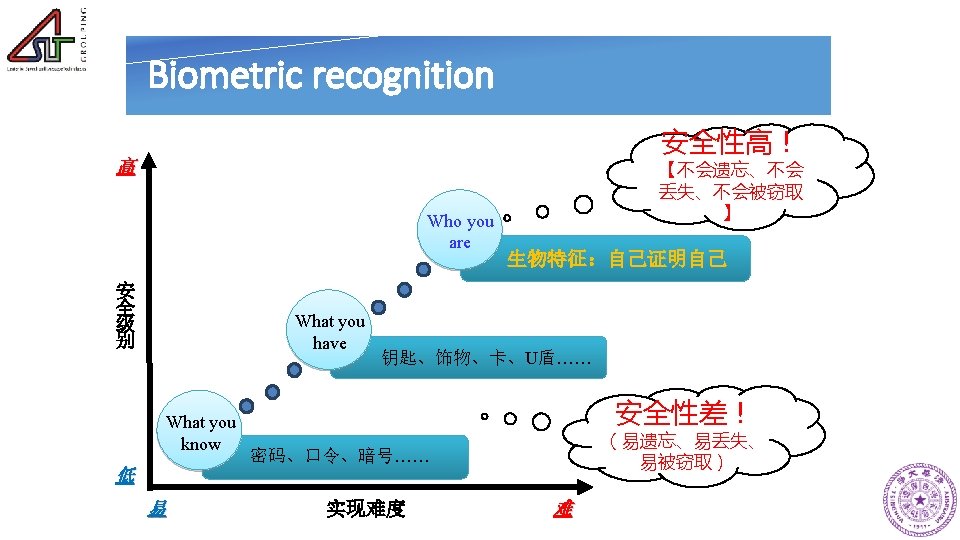
Biometric recognition • Biometric refers to metrics related to human characteristics [wiki]. Term "biometrics" is derived from Greek words bio (life) and metric (to measure). • Biometric recognition is a kind of automated technologies for measuring and analyzing an individual's physiological or behavioral characteristics, and can be used to verify or identify an individual.
Biometric recognition £ Fingerprint £ Face Physiological Characteristic £ Palmprint £ Iris £ Retina Scan £ DNA £ Signatures Behavioral Characteristic £ Gait/gesture £ Keystroke £ Voiceprint
Face recognition
Rich information contained in speech signal Where is he/she from? What language was spoken? Accent Recognition Language Recognition Speech Recognition Emotion Recognition Gender Recognition Speaker Recognition Positive? Negative? Happy? Sad? Male or Female? Who spoke? What was spoken?
Speaker recognition • Speaker recognition is the identification of a person from characteristics of voices (voice biometrics). It is also called voiceprint recognition. [wiki]
Speaker recognition categories • Speaker Identification ² Determining which identity in a specified speaker set is speaking during a given speech segment. • Speaker Verification ² Determining whether a claimed identity is speaking during a speech segment. It is a binary decision task. • Speaker Detection ² Determining whether a specified target speaker is speaking during a given speech segment. • Speaker Tracking (Speaker Diarization = Who Spoke When) ² Performing speaker detection as a function of time, giving the timing index of the specified speaker.
Speaker recognition categories • Text-dependent • Text-independent • Text-prompted
Speaker recognition • Advantages of Speaker recognition ² Speech signal more accessible ² The use more acceptable by users ² Remote authentication more convenient • Application scenarios ² Access control (e. g. voice lock) ² Transaction authentication (e. g. remote payment) ² Forensic analysis (e. g. police criminal detection)
Speaker recognition history , tion a m for n i tor e c n e o v ph p spkdee 2010 Keep pace with times Work together to develop PLP grm re u t a Fe ch spee form e wav Time el d o M 1930 C, C P L LPC, AR PL tro spec 1960 te a l p Tem hing c mat C MFC DT 1990 1980 1970 2000 MM Q, H V , W an e l c and ta l l a Sm ech da spe BM, U GMM -SVM GMM JFA, i- or vect ing De arn e l p e ical t c a d pr ata n a Big eech d sp
Speaker recognition history 高斯混合模型 基于 GMM-UBM 的说话人识别系统
Speaker recognition history 基于 GMM-HMM 的说话人识别系统
Speaker recognition history i-vector 模型 基于 i-vector 的说话人识别系统
Deep learning in speaker recognition • Machine learning is a subfield of compute science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence [wiki]. • Deep learning is a branch of machine learning methods based on learning representations of data. • Neural networks is a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data.
Deep learning in speaker recognition • DNN i-vector framework • End-to-end speaker recognition with DNNs • Deep speaker feature learning
DNN/i-vector Framework • Motivation: ² Low-level acoustic events (short-term spectral feature, MFCC/PLP) higher-level phonetic events. ² The collection of sufficient statistics (Baum-Welch). ² DNNs is superior over GMMs for ASR. üLonger segments of speech as inputs. üThe feed-forward neural networks is much Larger and deeper. üBP algorithm and stochastic gradient descent.
The zero and first order B-W statistics Baseline UBM: DNN alignment:
Supervised UBM
End-to-end Text-Dep. speaker recognition
End-to-end Text-Indep. speaker recognition The objective function
Deep speaker feature learning
Deep speaker feature learning
Deep speaker feature learning
Deep speaker feature learning
Deep speaker feature learning • Multi-task Recurrent Model for Speech and Speaker Recognition
Deep speaker feature learning
Deep speaker feature learning
Deep speaker feature learning
Max-margin metric learning • Max-margin metric learning ² Metric learning: to learn a projection M. ² Distance metric: ² Goal: to discriminate true speakers and imposters.
Max-margin metric learning • MMML (Max-margin metric learning) ² A contrastive triple ² Max-margin objective function ² SGD algorithm
Binary Speaker Embedding -- Computation • Local sensitive hashing (LSH) • Hamming distance learning
Short utterance speaker recognition • Less coverage, less confidence • Small speech classes overlooked by unsupervised training • How about if they met with each other?
Short utterance speaker recognition Solution by Phonetic-aware • Phonetic-aware approach Unsupervised training ²Acoustic clusters are based on phones ²Phone ID known for each frame on test • Resort to Speech Recognition! Phonetic-aware training • Convert to text-dependent tasks. Supervised training
Short utterance speaker recognition Table I. The Finals set of standard Chinese
Short utterance speaker recognition DNN i-vector model • Frame posteriors are computed from GMM. • Each Gaussian component represents a region / class for stats computation. • Unsupervised clustering. • Phone posteriors are derived from DNN. • Each sub-phonetic categories (senones) of DNN represents a region / class. • Supervised discriminative training. Fig. 2. Diagram of the (a) GMM- and (b) DNN-based statistics computation. [Daniel 2015]
Anti-spoofing • Impersonation ² Mimicking of prosodic or stylistic cues rather than the vocal tract • Speech synthesis: unit selection and statistical parametric. ² Acoustic differences: dynamic ranges of spectra, variance of higher order mel-cepstral coefficients, phase spectra ² F 0 statistics (‘F 0 jumps’) • Voice conversion: to synthesis speech signals closer to the target speaker. ² Cos-phase and MGDF-phase ² Short-term variability
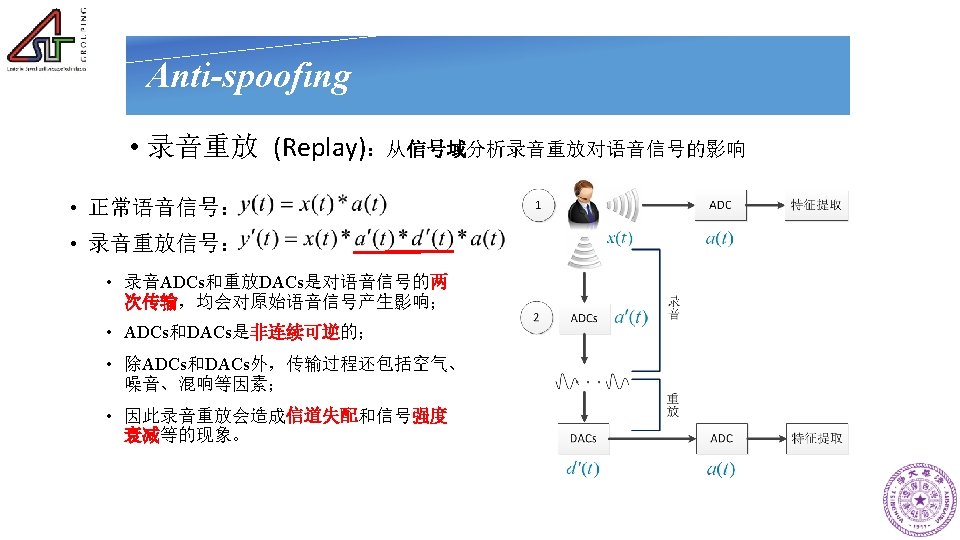
Anti-spoofing • Replay: ‘replay spoofing’ and ‘cut and paste spoofing’ ² Easier attack and harder anti-spoofing. Spectral distribution Prosodic features Other high-level features ² Channel / noise detection, Signal frequency analysis, Deep feature learning
Anti-spoofing • Replay: ² Variations : Speaker Phrase Device ² F-ratio:
Open research issues 1. How can human beings correctly recognize speakers? 2. Is it useful to study the mechanism of speaker recognition by human beings? 3. Is it useful to study the physiological mechanism of speech production to get new ideas for speaker recognition? 4. What feature parameters are appropriate for speaker recognition? 5. How can we fully exploit the clearly evident encoding of identity in prosody and other supra-segmental features of speech? 6. Is there any feature that can separate speakers whose voices sound identical, such as twins or imitators? 7. How do we deal with long term variability in people's voices (ageing)? 8. How do we deal with short term alteration due to illness, emotion, fatigue, …? 9. What are the conditions that speaker recognition must satisfy to be practical? 10. What about combing speech and speaker recognition? Furui, S. , "Recent advances in speaker recognition, " Pattern Recognition Letters 18 (1997) 859 -872
Requirements by applications • Anti-spoofing ² Impersonation / Speech synthesis / Voice conversion / Replay • Physical condition change robustness ² Cold / nasal congestion / laryngitis • Real intention detection ² Emotion recognition • Time varying robustness ² Ageing (long-term variability) All Theoretical Problems!
Thank you http: //lilt. cslt. org/