Hoofdstuk 16 Het vermogen van een test Inleiding














 voor éénwegs ANOVA: waarbee Es")









 en we willen een medium-sized effect")






, a (kans op Type I fouten),")




. Statistical power analysis for the behavioral sciences. (2 nd")
- Slides: 40
Hoofdstuk 16 Het vermogen van een test • Inleiding • Type I en Type II fouten, vermogen • Bepalen benodigde steekproefgrootte • Bepalen vermogen in geval van niet significant resultaat • Effectgrootte • Berekening in Statistica • Statistisch significant ≠ biologisch relevant • Opmerkingen • Meta-analyse Tom Wenseleeers, 12 november 2009
16. 1 Inleiding • We hernemen het voorbeeld ivm. het vergelijken van de lengte van vrouwelijke en mannelijke Kamsalamanders (data set ‘Kam’). • Met behulp van de ongepaarde t-test hebben we vroeger reeds aangetoond dat mannelijke en vrouwelijke dieren een significant verschillende lengte hebben (p=0. 0007) • Grafisch:
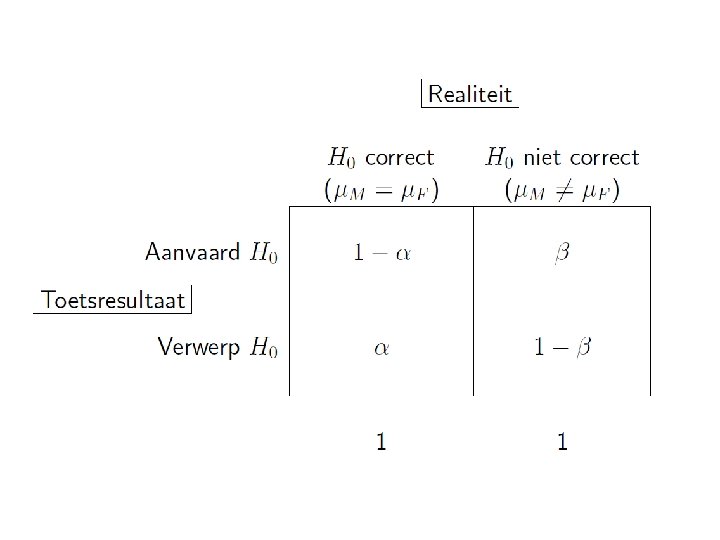
• Indien beide gemiddelden toch gelijk zouden zijn aan elkaar, dan kan men het verwerpen van H 0 aanzien als een foute beslissing. • Indien we H 0 aanvaard hadden, terwijl de gemiddelden μM en μF toch zouden verschillen, dan kan men dit ook interpreteren als een foute beslissing. • Dit zijn twee fundamenteel verschillende soorten fouten. • Een statistische procedure is in de praktijk slechts aanvaardbaar indien er weinig kans bestaat op één van beide fouten. • In dit hoofdstuk zullen we zien hoe men in de praktijk beide fouten onder controle kan houden.
16. 2 Type I en Type II fouten • Een type I fout valt voor als men de nulhypothese ten onrechte verwerpt = kans op vals positief resultaat. • Een type II fout valt voor als men de nulhypothese ten onrechte aanvaardt = kans op vals negatief resultaat.
16. 2. 1 Type I fouten • Men kan aantonen dat de kans op een type I fout steeds gelijk is aan het gebruikte significantie niveau a. • Deze kans kan dus onder controle gehouden worden via de keuze van a. • Een kleine/grote waarde voor a is dus equivalent met een kleine/grote kans op een type I fout.
16. 2. 2 Type II fouten • Voor een bepaalde steekproef-situatie kan men de kans op een type I fout en de kans op een type II fout niet beide willekeurig klein krijgen. • Om dit in te zien nemen we een extreem voorbeeld : - We nemen als toetsings strategie : steeds H 0 aanvaarden - De kans op een type I fout is 0 - De kans op een type II fout is 1 • In het algmeen geldt dat de kans op een type II fout toeneemt indien de kans op een type I fout afneemt • Notatie : b = P(type II fout) = P(H 0 aanvaard | HA)
16. 2. 3 Het vermogen of "power" van een test • 1−b wordt het vermogen of de "power" van de toets genoemd. Het is de kans dat men de nulhypothese terecht verwerpt. • In de praktijk wil men het vermogen zo groot mogelijk hebben. Immers, als de nulhypothese niet correct is wil men een zo groot mogelijke kans dat dit ontdekt zal worden. • Wanneer zal het vermogen groot of klein zijn ? • Het vermogen hangt af van : - Het echte verschil |μM − μF| tussen beide groepen - De variabiliteit s 2 van de gegevens (verondersteld gelijk in beide groepen) - De steekproefgroottes n. M en n. F
Vermogen in functie van |μM − μF| • Kleine afwijkingen tov. de nulhypothese zijn moeilijk detecteerbaar • Grote afwijkingen tov. de nulhypothese zijn gemakkelijk detecteerbaar • Het echte verschil tussen μM en μF kent men uiteraard niet, men kan het enkel schatten. Indien men het vermogen van een toets berekent op basis van het geschatte verschil tussen de groepen dan spreekt men van het geobserveerde vermogen (in de GLM module wordt dit gegeven onder "Effect sizes"). • Men kan echter ook de power berekenen voor de situatie waarbij men een vooropgesteld verschil had willen kunnen detecteren (zie verder, Effectgrootte).
Vermogen in functie van s 2 • Bij grote variabiliteit in de gegevens zijn de groeps gemiddelden μM en μF weinig nauwkeurig geschat, en heeft men weinig kracht om afwijkingen t. o. v. de nulhypothese te ontdekken. • Bij kleine variabiliteit in de gegevens zijn de groeps gemiddelden μM en μF wel nauwkeurig geschat, en heeft men meer kracht om afwijkingen t. o. v. de nulhypothese te ontdekken. • s 2 kan men schatten op basis van een steekproef of pilootexperiment.
Vermogen in functie van nm en nf • Op basis van grote steekproeven zal men meer kans hebben afwijkingen t. o. v. de nulhypothese te ontdekken. • Op basis van kleine steekproeven zal men minder kans hebben afwijkingen t. o. v. de nulhypothese te ontdekken. • De steekproefgrootte verhogen is de enige manier om het vermogen van een toets te verhogen.
Besluit • Het vermogen van een test hangt dus af van : - De afwijking tov de nulhypothese die men wenst te ontdekken - De spreiding in de data - De steekproefgrootte • Vermits er een inverse relatie bestaat tussen het begaan van een type I en een type II fout, zal een kleinere a (kleinere kans op Type I fout) een grotere b geven (grotere kans op Type II fout) voor een bepaalde steekproefgrootte n. • Als we de kans op het maken van beide fouten willen reduceren, dan moeten we de steekproefgrootte n dus vergroten. • Twee grote toepassingen van power analyse: 1. Bepalen minimale staalnamegrootte om een gegeven verschil in gemiddelden (effectgrootte) te kunnen detecteren met een bepaald vermogen 2. In geval van een niet significant resultaat berekenen wat het vermogen van je test was om een bepaald verschil in gemiddelden (effectgrootte) te ontdekken
16. 3 Bepalen benodigde steekproefgrootte • Via de Power analysis. . . Sample Size Calculation module kan men voor een gegeven test (t-test, ANOVA, correlatie, . . . ) de benodigde steekproefgrootte berekenen om een bepaald vermogen te bereiken. In geval van een t-test dient men hierbij de volgende parameters in te geven: 1. Het gebruikte significantie niveau (a), waarmee men de kans op een Type I fout controleert (een toevallig verschil als reëel bestempelen). 2. De variabiliteit s 2 in de gegevens. Deze kan bepaald worden op basis van een pilootexperiment, een vroeger experiment of literatuurgegevens 3. Het minimale verschil in gemiddelde |μM − μF| tussen de twee groepen dat men wenst te kunnen ontdekken met kans 1−b. Het minimaal te detecteren verschil relatief t. o. v. de variabiliteit van de gegevens worden soms gecombineerd in een effectgrootte (zie verder). 4. Het gewenste vermogen 1−b, m. a. w. de maximaal toegelaten kans op een Type II fout (geen verschil detecteren indien er in realiteit wel een is). Meestal zal men trachten een vermogen van 0. 90 te bereiken (of minimaal 0. 80).
16. 4 Bepalen vermogen in geval van niet significant resultaat • Indien men in een test een niet significant resultaat uitkomt dan is de vraag dikwijls of er effectief geen verschil is, of dat het niet significant resultaat het gevolg is van een laag vermogen en een kleine staalnamegrootte. • Via de Power analysis. . . Power Calculation module kan men voor een gegeven test (t-test, ANOVA, correlatie, . . . ) en staalnamegrootte het vermogen berekenen. Het vermogen gegeven een bepaald geobserveerd verschil wordt ook gegeven in de GLM module onder "Effect sizes". In geval van een t-test dient men hierbij de volgende parameters in te geven: 1. Het gebruikte significantie niveau (a), waarmee men de kans op een Type I fout controleert (een toevallig verschil als reëel bestempelen). 2. De staalnamegroottes. 3. De variabiliteit s 2 in de gegevens en het gewenste minimale verschil |μM − μF| dat men had willen kunnen ontdekken met kans 1−b. Het minimaal te detecteren verschil relatief t. o. v. de variabiliteit van de gegevens worden soms gecombineerd in een effectgrootte (zie verder).
16. 5 Effectgrootte • Het minimale verschil dat men wenst te kunnen detecteren met kans 1 -b wordt soms aangegeven aan de hand van een effectgrootte. • Verschillende maten, afhankelijk van de statistische test, bv. - t-test: Cohen's d = gestandardiseerd verschil in gemiddelde Es = |μgroep 1 − μgroep 2| /s s is de gepoolde standaarddeviatie - correlatie, multipele regressie, ANOVA: Cohen's f met R 2=gekwadrateerde correlatiecoëfficient of partiële correlatie coëfficient in geval van multipele regressie of partiële eta 2 voor ANOVA of GLM (zie "Effect sizes" in GLM module) voor ANOVA wordt Cohen's f wordt soms ook geschreven als waarbee Es het gestandaardiseerde effect is per groep en J het aantal groepen in de ANOVA
- ANOVA, GLM: RMSSE (root mean square standardized effect) voor éénwegs ANOVA: waarbee Es het gestandaardiseerde effect is per groep en J het aantal groepen in de ANOVA bv. J=4, f=0. 25 RMSSE=0. 29 f en RMSSE kan in Statistica berekend worden met de Power analysis module (1/2 way ANOVA. . . Calc. effects)
• Je kan de power van je test berekenen gegeven een bepaalde staalnamegrootte en gegeven een bepaalde minimaal te detecteren effectgrootte. • Dit zijn ruwe richtlijnen die soms gegeven worden i. v. m. effectgroottes: small effect medium effect large effect Cohen's d / Es 0. 20 0. 50 0. 80 Cohen's f 0. 10 0. 25 0. 40 RMSSE 0. 15 0. 30 0. 50 1% 5% 15% variantie verklaard door factor ca. • Dit zijn slechts richtlijnen! Wat aanzien wordt als een groot of een klein effect is sterk afhankelijk van de context of het domein waarin je werkt.
16. 6 Berekening in Statistica • Het vermogen van een test alsook de staalnamegrootte nodig om een bepaald vermogen te bereiken kan in Statistica berekend worden met de module Power Analysis. Effectgrootte en het geobserveerde vermogen van een test worden ook gegeven in de GLM module onder Effect sizes.
16. 6. 1 Voorbeeld 1: ongepaarde t-test • Dataset 'Kam'. In de finale dataset was de lengte van mannetjes en vrouwtjes significant verschillend (ongepaarde t-test, p=0. 0007). • Het is echter mogelijk dat je initieel over een kleinere dataset beschikte waarin het verschil door de beperkte staalname niet significant was. • In dat geval zouden we graag berekenen welke staalnamegrootte we zouden moeten nemen om een bepaald vermogen te bereiken. • De gemiddelden en standaard deviaties zouden gelijkaardig zijn aan deze in de finale dataset. • Gepoolde standaarddeviatie
• Es = Cohen's d = difference in mean in standard deviation units = -0. 6 (medium effect, Abs waarde > 0. 5) • Minstens 59 observaties per groep nodig om een vermogen van 0. 90 te bereiken.
• In Statistica kan je grafisch de evolutie van de bekomen power i. f. v. de staalnamegrootte onderzoeken via de N vs. Power button:
• Men kan de power funktie ook tekenen voor verschillende steekproef grootten n. M = n. V = n. Men kan dan aflezen hoe groot n moet genomen worden opdat men een vereist vermogen zou bereiken: Vermogen 1 -b Power functie, a = 0. 05, s = 4. 86, n. V = n. M = n Gemiddeld verschil µM-µV
• Dit soort power curves kan je voor een gegeven staalnamegrootte plotten in Statistica via Power Analysis. . . Power Calculation. . . Power vs. Es :
• Het geobserveerde vermogen van de test gegeven een bepaalde staalnamegrootte en de geobserveerde verschillen in gemiddelden en variantie in de gegevens kan het gemakkelijkste berekend worden in de GLM module (. . . Effect sizes): • De partiële eta-squared kan omgerekend worden naar Cohen's f = medium effect (> 0. 25)
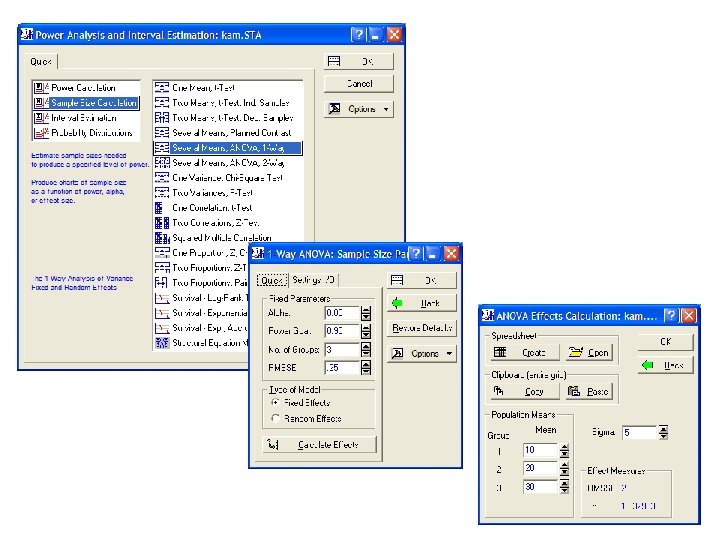
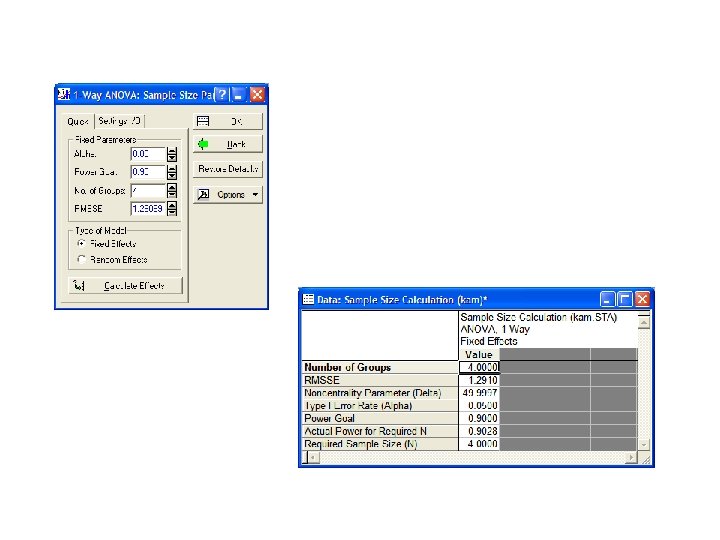
16. 6. 2 Voorbeeld 2: éénwegs ANOVA • Welke staalnamegrootte is er nodig om een gegeven verschil met kans 1 - b te kunnen detecteren?
• Stel je hebt 4 groepen (J=4) en we willen een medium-sized effect (f=0. 25) kunnen detecteren met een vermogen van 0. 90 • Geef ook op of je factor fixed of random is: • We hebben dan minimum 58 stalen per groep nodig
• Je kan ook de benodigde sample size plotten i. f. v. de te detecteren effectgrootte (N vs. RMSSE):
• Of de benodigde sample size plotten i. f. v. het te bereiken vermogen (N vs. power):
• Of gegeven een zekere sample size en een bepaalde te detecteren effectgrootte kijken wat je vermogen zou zijn (Power vs. RMSSE):
• Een andere manier om je te detecteren RMSSE in te geven is via het opgeven van minimale verschillen in gemiddelden via de Calculate Effects button: • Merk op dat je van de gemiddelden een constante waarde mag optellen of aftrekken en dat je dan dezelfde RMSS en Cohen's f waarde krijgt.
• Merk op dat je van de gemiddelden een constante waarde mag optellen of aftrekken en dat je dan dezelfde RMSS en f waarde krijgt. Of je kan standaard deviatie op 1 zetten en denken in termen van deviaties in eenheden van standaarddeviatie:
16. 6. 3 Voorbeeld 3: correlatie • Welke staalnamegrootte is er nodig om een gegeven correlatie met kans 1 -b te kunnen detecteren?
• Specifieer Rho (minimaal te detecteren correlatie), a (kans op Type I fouten), 1 -b (vermogen, kans op Type II fouten) en of je een 1 of 2 zijdige test wil doen. • Benodigde staalnamegrootte: 258 • Correlaties en regressies kunnen met een groter vermogen getest worden indien je een maximale spreiding hebt in je 2 variabelen.
16. 7 Statistisch significant ≠ biologisch relevant • Het vermogen van een statistische toets stijgt met de steekproef grootte n • De kleinste afwijking tov. de nulhypothese zal dus significant zijn als men de steekproef groot genoeg neemt • Dit toont aan, dat bij (zeer) grote steekproeven, ook biologisch irrelevante verschillen significant gaan zijn en dat het gebruik van enkel de p-waarde niet aangewezen is. • Het is dan relevanter hypothese toetsen te vervangen door betrouwbaarheids intervallen van de parameters waarin men specifiek geïnteresseerd is en ook van effectgroottes te rapporteren. • 95% confidentielimieten worden in sommige Statistica modules standaard gerapporteerd. Indien ze niet gegeven worden dan kan de bootstrap methode gebruikt worden om ze op een niet-parametrische manier te berekenen.
16. 8 Opmerkingen • In theorie kan men dus, op basis van een statistisch model, berekenen hoe groot de steekproef genomen moet worden om een vereist vermogen te bekomen. • In de praktijk echter, vereisen dergelijke berekeningen input over - de minimale afwijkingen t. o. v. de nulhypothese die men wenst te ontdekken (effectgrootte) - variabiliteit van de gegevens - lineariteitsassumpties - algemene model assumpties • Power analyse is niet altijd mogelijk voor complexe designs. • Indien je in zo'n designs een niet significant resultaat uitkomt en je wil weten hoe groot je sample size zou moeten zijn om gegeven de geobserveerde effectgroottes wel een significant resultaat uit te komen dan is eenvoudige manier om random gesampelde metingen toe te voegen uit je dataset.
16. 9 Meta-analyse • Een andere manier om het vermogen om een bepaalde hypothese te kunnen toetsen te verhogen is door eigen gegevens te combineren met eerdere literatuurgegevens. • Een eenvoudige manier is de zgn. Fisher methode: hierbij worden de p-waarden van de verschillende testen log getransformeerd en gesommeerd. De test statistiek volgt dan een chi-kwadraat verdeling met 2 k vrijheidsgraden waarbij k=het aantal te combineren p-waarden is en pi=de p-waarde van de ide test • Veronderstelt dat de verschillende testen onafhankelijk zijn. • Alternatieve manier: testen of de gemiddelde gestandardiseerde effectgrootte significant verschilt van 0 (bv. Cohen's d, correlatiecoëfficiënt)
16. 9. 1 Voorbeeld in Excel • Voorbeeld 1. Stel de p-waarden van 2 testen waren 0. 01 en 0. 1. Teststatistiek X 2 = -2*(LN(0. 01)+LN(0. 1)) = 13. 8 Fisher p-waarde = CHIDIST(13. 8, 2*2) = 0. 008 • Voorbeeld 2. Stel de p-waarden van 3 testen waren 0. 06, 0. 07 en 0. 08. Teststatistiek X 2 = -2*(LN(0. 06)+LN(0. 07)+LN(0. 08)) = 16. 0 Fisher p-waarde = CHIDIST(13. 8, 2*3) = 0. 01 • Er bestaan ook nog complexere methoden die o. a. rekening houden met verschillen in staalnamegrootte van de verschillende analyses e. d. (en dus de verschillende nauwkeurigheid van de p-waarden of effectgroottes), bv. de Mantel Haenszel en de Peto methode. We zullen hier niet op ingaan. • Wel mogelijke biases, bv. doordat in de literatuur niet significante resultaten minder frequent gerapporteerd worden dan wel significante ("file drawer probleem"). Er bestaan methoden om zulke publication biases op te sporen.
Meer weten? Cohen, J. (1983). Statistical power analysis for the behavioral sciences. (2 nd Ed. ). Mahwah, NJ: Lawrence Erlbaum Associates. Sutton, A. J. , Jones, D. R. , Abrams, K. R. , Sheldon, T. A. , & Song, F. (2000) Methods for Meta-analysis in Medical Research. London: John Wiley.