EVALUATION CSC 576 Data Mining Today Evaluation Metrics




: + (positive class) - (negative class) Class imblanace:")

: fraction of positive")








 k separate evaluation")

")








 • Arithmetic means are susceptible to influence of large")





- Slides: 35
EVALUATION CSC 576: Data Mining
Today… Evaluation Metrics: � Misclassification Rate � Confusion Matrix � Precision, Recall, F 1 Evaluation Experiments: � Cross-Validation � Bootstrap � Out-of-time Sampling
Evaluation Metrics
Evaluation Metrics Issues with misclassification rate? � If Accuracy is used: Example: in CC fraud domain, there are many more legitimate transactions than fraudulent transactions Presume only 1% of transactions are fraudulent � Then: Classifier that predicts every transaction as GOOD would have 99% accuracy! Seems great, but it’s not…
Alternative Metrics Notation (for binary classification): + (positive class) - (negative class) Class imblanace: � rare class vs. majority class
For binary problems, there are 4 possible problems: Confusion Matrix: Counts Predicted Class Actual Class + - + f++ (True Positive) f+- (False Negative) - f-+ (False Positive) f-- (True Negative) True Positive (TP): number of positive examples correctly predicted by model False Negative (FN): number of positive examples wrongly predicted as negative False Positive (FP): number of negative examples wrongly predicted as positive
Confusion Matrix: Percentages Predicted Class Actual Class True Positive Rate (TPR): fraction of positive examples correctly predicted by model � + - + f++ (True Positive) f-+ (False Positive) f+- (False Negative) f-- (True Negative) Also referred to as sensitivity False Negative Rate (FNR): fraction of positive examples wrongly predicted as negative False Positive Rate (FPR): fraction of negative examples wrongly predicted as positive True Negative Rate (TNR): fraction of negative examples correctly predicted � TPR = TP/(TP+FN) Also referred to as specificity FNR = FN/(TP+FN) FPR = FP/(TN+FP) TNR = TN/(TN+FP)
Precision and Recall Widely used metrics when successful detection of one class is considered more significant than detection of the other classes
Precision Precision: fraction of records that are positive in the set of records that classifier predicted as positive Interpretation: higher the precision, the lower the number of false positive errors
Recall Recall: fraction of positive records that are correctly predicted by classifier Interpretation: higher the recall, the fewer number of positive records misclassified as negative class
Baseline Models Often naïve models Example #1: classify every instance as positive (the rare class) What is accuracy? Precision? Recall? � Precision = poor; Recall = 100% � Baseline models often maximize one metric (precision, recall) but not the other. Key challenge: building a model that performs well with both metrics
F 1 Measure F-measure: combines precision and recall into a single metric, using the harmonic mean � Harmonic Mean of two numbers tends to be closer to the smaller of two numbers… � …so the only way F 1 is high is for both precision and recall to be high.
Evaluation Experiments
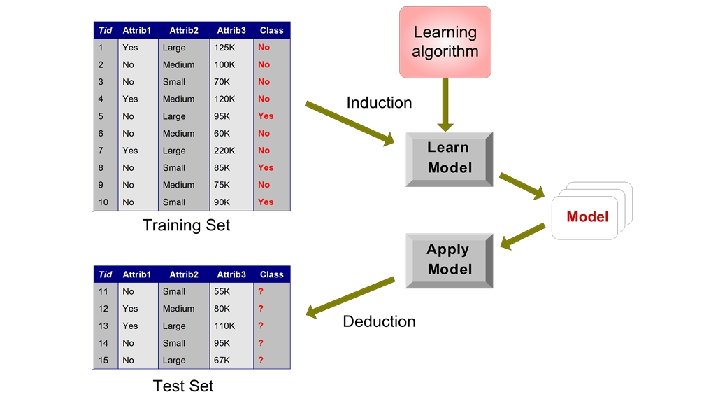
Evaluation How to divide dataset into Training set, Validation set, Testing set? � Sample (randomly partition) Problems? Requires enough data to create suitably large enough sets “Lucky split” is possible 1. 2. Difficult instances were chosen for the training set Easy instances put into the testing set
Cross Validation Widely used alternative to single Training Set + Validation Set Multiple evaluations using different portions of data for training and validating/testing k-fold Cross Validation �k = number of folds (integer)
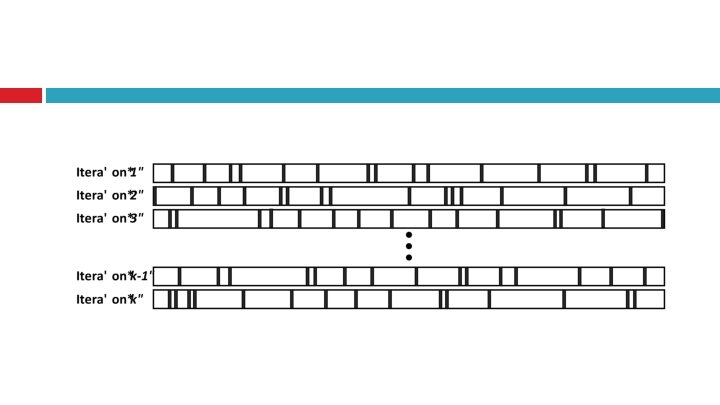
k-Fold Cross Validation Available data is divided into equal-sized folds (partitions) k separate evaluation experiments: � Training set: k-1 folds � Test set: 1 fold Repeat k-1 more times, each using a different fold for the test set
10 -fold Cross Validation 1/10 th of training data X 9 = 90% used for training 10% used for testing • Repeat k times • Average results • Each instance will be used once in testing
Cross-Validation More computationally expensive k-fold Cross-Validation � � k = number of folds (integer) k = 10 is common Leave-One-Out Cross-Validation � � � Extreme: k = n, where there are n-1 observations in training+validation set Useful when the amount of data available is too small to have big enough training sets in a k-fold cross-validation. Significantly more computationally expensive
Leave-One-Out Cross-Validation n folds Training set: n-1 instances Testing set: 1 single instance n instances
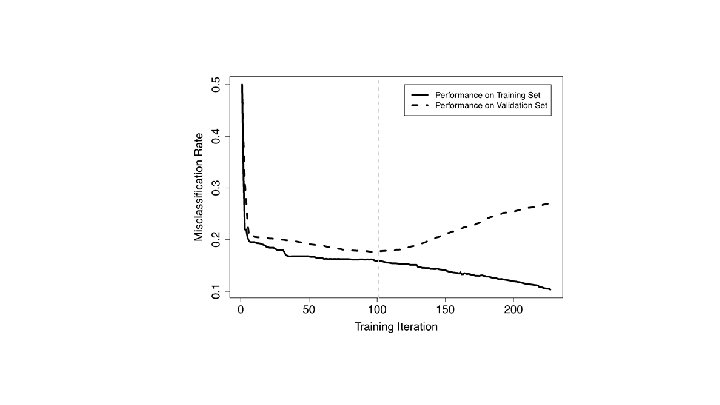
Cross-Validation Error Estimate Average the error rate for each fold. In leave-one-out cross-validation, since each test contains only one record, the variance of the estimated performance will be high. (Usually either 100% or 0%. )
ε 0 Bootstrapping Also called. 632 bootstrap Preferred over cross-validation approaches in contexts with very small datasets � < 300 instances Performs multiple evaluation experiments using slightly different training and testing sets Repeat k times Typically, k is set greater than 200 � Many more folds than with k-fold cross-validation
Out-of-time Sampling Some domains have a time dimension � chronological structure in data One time span used for training set � another time span for the test set
Out-of-time Sampling Important that out-of-time sample uses time spans large enough to take into account any cyclical behavior patterns
Average Class Accuracy Two models. Which is better? We’re really interested in identifying the churn customers. Model 1 Accuracy: 91% Model 2 Accuracy: 78% Note the imblanaced test set.
Average Class Accuracy
Two models. Which is better? We’re really interested in identifying the churn customers. Average Class Accuracy Model 1 Accuracy: 91% Model 2 Accuracy: 78% Model 1: Average Class Accuracy: 55% Model 2: Average Class Accuracy: 79%
Average Class Accuracy (Harmonic Mean) • Arithmetic means are susceptible to influence of large outliers. • The harmonic mean results in a more pessimistic view of model performance than the arithmetic mean.
Measuring Profit and Loss Should all cells in a confusion matrix have the same weight? Predicted Class Actual Class + - + f++ (True Positive) f+- (False Negative) - f-+ (False Positive) f-- (True Negative) Not always correct to treat all outcomes equa
Measuring Profit and Loss Small cost incurred by company on false positives. Large cost incurred by company on false negatives. No cost on true positives and true negatives.
Measuring Profit and Loss Calculate a profit matrix, profit or loss from each outcome in the confusion matrix. � Used in overall model evaluation. Example:
Average class accuracy. HM = 83. 824% Average class accuracy. HM = 80. 761% Measuring Profit and Loss
References Fundamentals of Machine Learning for Predictive Data Analytics, 1 st Edition, Kelleher et al. Data Science from Scratch, 1 st Edition, Grus Data Mining and Business Analytics in R, 1 st edition, Ledolter An Introduction to Statistical Learning, 1 st edition, James et al. Discovering Knowledge in Data, 2 nd edition, Larose et al. Introduction to Data Mining, 1 st edition, Tam et al.