NEAREST NEIGHBORS CSC 576 Data Mining Today kNearest

NEAREST NEIGHBORS CSC 576: Data Mining

Today… k-Nearest Neighbors Predicting Continuous Targets Similarity Indexes for Binary Descriptive Features k-d Trees

Final Thoughts on Nearest Neighbors Nearest-neighbors classification is part of a more general technique called instance-based learning � Use specific instances for prediction, rather than a model Nearest-neighbors is a lazy learner � Performing the classification can be relatively computationally expensive � No model is learned up-front

Query / test instance to classify: • Salary = 56000 • Age = 35

Full example in KND text. Continuous Targets

• Use normalized values for determining proximity. • Use original values for prediction once neighbors are identified.

Continuous Targets: Weighted

Similarity Indexes for Binary Descriptive Features Motivation: � The Minkowski-based Euclidean and Manhattan distance metrics computed similarity between two instance based on continuous features � What about binary features? • Many alternative measures of similarity. • Appropriateness of them depends on the dataset.
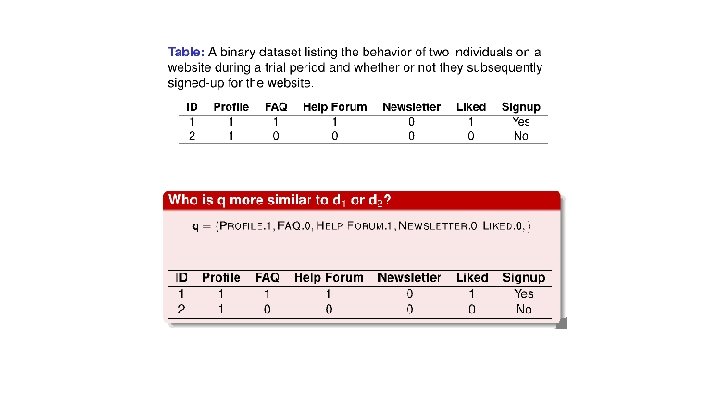

Similarity Indexes for Binary Descriptive Features Similarity index - defines similarity between two instances (q and i) in terms of: � � co-presence (CP): how often a true value occurred for the same feature in both the query q and for the other instance i co-absence (CA): how often a false value occurred for the same feature in both the query q and for the other instance i presence-absence (PA): how often a true value occurred in the query q while a false value occurred for the other instance i for the same feature absence-presence (AP): how often a false value occurred in the query q while a true value occurred for the other instance i for the same feature
 and the two")
Pairwise analysis of similarity between the current trial user (query q) and the two customers in the dataset. • Pairwise analysis between query and against each customer.

Different Similarity Indexes 1. 2. 3. Russel-Rao: ratio between the number of copresences and the total number of binary features considered Sokal-Michener: ratio between the total number of co-presences and co-absences and the total number of binary features considered Jaccard: ratio between the total number of copresences and the total number of binary features considered excluding co-absences

Russel-Rao

Sokal-Michener

Jaccard

References Fundamentals of Machine Learning for Predictive Data Analytics, 1 st Edition, Kelleher et al.
- Slides: 16