Theories of Classical Conditioning Critical CSUS relationship Important

 things to note about classical conditioning: – the")




 – Only some components of UR")









 spent")

: Showed how 2 probabilities interact")
 Examined predictability 6 types of Groups • CS-alone – present CS")


 > p(US|NO cs): – CS =")

")
 model!!!!! Vi")
 model!!!!! Vi")

 model • Model developed to accurately predict and map learning")





 •")

 • Vi = change in associative strength that occurs")
 – CS = light; US= 1")

(0.")
(0. 5)(100 -50)")
(0. 5)(100 -75) = 0. 5(25)")
(0. 5)(100 -87. 5) = 0.")




(100 -(50+20)) = 6 – Vt")











 levels")














- Slides: 75
Theories of Classical Conditioning
Critical CS-US relationship • Important (critical) things to note about classical conditioning: – the CS MUST precede the US – the CS MUST predict the US – if the CS does not predict the US, no conditioning occurs – the CR does not have to be identical to the UR • E. g. , subtle differences even Pavlov noticed) • may even be opposite: Morphine studies • Any response is a classically conditioned response if it – occurs to a CS – after that CS has been paired with a US – but does NOT occur to a randomly presented CS-US pairing
Theories of Classical Conditioning: WHY do organisms respond to predictability? • Pavlov: Stimulus substitutability theory • Kamin: Surprise theory • Rescorla and Wagner: Computational Model • Current Attentional Models
Pavlov: Stimulus Substitution Theory – Basic premise of theory: CS substitutes for US • w/repeated pairings between CS and US, CS becomes substitute for the US • thus, the response initially elicited only by US is now also elicited by CS – sounds pretty good: • salivary conditioning: US and CS both elicit salivation • eyeblink conditioning: both elicit eyeblinks – Theory was doing well until we found compensatory CRs
Pavlov: Stimulus Substitution Theory – Criticisms and Flaws: • CR is almost never an exact replica of the UR • An eyeblink to UR of air puff = large, rapid closure • Eyeblink to CS of tone = smaller, more gradual closure • Defense of theory: Hilgard (1936): Why differences in CR and UR: – Intensity and stimulus modality of the CS and US are different – Thus: differences in Response magnitude and timing are to be expected – But still doesn’t explain OPPOSITE CR
Pavlov: Stimulus Substitution Theory • BIGGER PROBLEM: – Whereas many US's elicit several different R's, as a general rule not all of these R's are later elicited by the CS – CS seems to select for certain CRs • E. g. Zener (1937) – Dog presented w/food as US: • found that the dog elicited a number of UR responses to the food • E. g. , salivation, chewing, swallowing, etc. – CS not elicit all of those responses • NO CRs of chewing and swallowing • Just the CR of just salivation • On other hand: CR may contain some of responses that are not part of CR: – Zener found that dogs turned head to bell – But no head turns to presentation of food
Modifications of SST • MODIFICATIONS OF SST: (Hilgard) – Only some components of UR transferred to CR – CS such as a bell often elicits unconditioned responses of its own, and these may become part of CR • Remember SIGN TRACKING: Brown and Jenkins 1974 – Emphasized this change in form of CR vs. UR – Also Jenkins, Barrara, Ireland Woodside (1976) • Sign Tracking : animals tend to – Orient themselves toward the CS (not the US) – Approach – Explore any stimuli that are good predictors of important events such as the delivery of food
1 4 2 Set up: 1. Initial training: Light turns on above feeder releases pieces of hot dog 2. Test: a. Light turns on above feeder, then above each of the other walls b. Forms a sequence of 1 2 3 4 3. What is optimal response? 3 Jenkins, Barrara, Ireland Woodside (1976) 4. But: Dog “tracked the sign”
Modifications of SST • Strongest data against SST theory: Paradoxical conditioning – CR in opposite direction of UR • Black (1965): – heart rate decreases to CS paired w/shock – US of shock elicits UR of heart rate INCREASE – But CS of light or tone elicits CR of heart rate DECREASE • Seigel (1979): conditioned compensatory responses – – Morphine studies evidence of down regulation in addiction Actual cellular process in neurons (and other cells, too!) thus SST theory appears incorrect
Perceptual Gating Theory • Perceptual gating theory: – Idea that only if CS is biologically relevant will it get processed – If a CS doesn’t get processed it can be predictive/informative – Animals attend to biologically relevant stimuli • Problem: – Data show that under certain circumstances a stimulus is “attended to” or “processed”, but still does not serve as a CS with an accompanying CR – Issue remains: is the stimulus the most predictive? – Second issue: Defining “biologically relevant”
Kamin’s work: 1967 -1974 Blocking and overshadowing • Overshadowing: – – use one "weak" and one "strong" CS CS 1+CS 2 US reaction to weaker stimulus is blotted out by stronger CS Demonstrated by Pavlov • Blocking: – Train 1 CS, then add a second CS to it: • CS 1 US • CS 1+CS 2 US – test each individually after training – Find that only one supports a CR – One stimulus “blocks” learning to second CS – Demonstrated by Kamin
Kamin’s blocking experiment • Used multiple CS's and 4 groups of rats • The blocking group receives – series of L+ trials which produce strong CR – series of L+T+ trials – then tested to just the T • The Control groups receives – SAME TOTAL NUMBER OF TRIALS AS BLOCKING GROUP – no first phase – L+ only; Test T – T+ only; Test T – LT+ only: Test T
Kamin’s blocking experiment • Prediction: since both received same # of trials to the tone- should get equal conditioning to the tone • Results quite different: Blocking group shows no CR to the tonethe prior conditioning to the light "blocked" any more conditioning to the tone • Directly contradicts frequency principle (remember associationism!) Group Control Blocking Phase I ------L+ Phase II L+ T+ LT+ Test Phase Result T T elicits no CR T T elicits a CR T T elicits no CR
Things we know about blocking: • The animal does "detect" the stimulus: – can’t be perceptual gating issue – EXT of CR with either T alone or with LT – EXT occurred faster with compound LT • Appears to be independent of: – length of presentation of the CS – number of trials of conditioning to compound CS • Constancy of US from phase 1 to 2 important!!!! – US must remain identical between the two phases or no blocking • Influenced by: – Type of CR measure (used CER, not as stable as non fear CR) – nature of CS may be important- e. g. modality – intensity of CS or US stimuli important • Depends on amount of conditioning to blocking stimulus which already occurred
Change in either US or CS can prevent/ overcome blocking • Change the intensity of the CS from phase 1 to phase 2 – – – Overshadowing could be playing a role strong vs weak stimulus e. g. experiments when changed from 1 ma to 4 ma shock quickly condition to compound stimulus little or no overshadowing or blocking • Change in intensity of either CS stimulus– Change in context from Phase 1 to Phase 2 • l. T • Lt then T – presents a different learning situation and no blocking • Any ideas about what is happening?
Explanations of Blocking: • Poor Explanation: Perceptual gating theory: – tone never gets processed – tone not informative – data not really support this (evidence that do “hear” tone) • Good Explanation: Kamin's Surprise theory: – to condition requires some mental work on part of animal – animal only does mental work when surprised – bio genetic advantage: prevents having to carry around excess mental baggage – thus only learn with "surprise" – situation must be different from original learning situation • Better Explanation: Rescorla Wagner model: – particular US only supports a certain amount of conditioning – if one CS “hogs” all that conditioning- none is left over for another CS to be added – question- how do we show this?
A Brief Aside • Must determine how CS-US relationship works • Rescorla (1966) spent a lot of time on control groups – What exactly IS a control group in classical conditioning? – Why is this important? – Question of contiguity vs. predictability at play here.
Recorla: Which is more important? CS-US correlation vs. contiguity • CS-US contiguity: – CS and US are next to one another in time/space – In most cases, CS and US are continguous • CS-US correlation: CS followed by the US in a predictive correlation: • If perfect correlation (most predictive)- most conditioning • p(US/CS) = 1. 0 • p(US/no CS) = 0. 0 • But: life not always a perfect correlation
CS-US correlation is more critical • Rescorla (1966, 1968): Showed how 2 probabilities interact to determine size of the CS – CS = 2 min tone; presented at random intervals (M = 8 min) – Group 1: p(shock/CS) = 0. 4 during 2 min presentation – Group 2: p(shock/no CS) = 0. 2 • Which group should show more conditioning? • WHY?
Robert Rescorla (1966) Examined predictability 6 types of Groups • CS-alone – present CS alone with no US pairing – problem: not have same number of US trials as experimental animals do, may actually be extinction effect • Novel CS group: – looks at whether stimulus is truly "neutral" – may produce habituation- animal doesn't respond because it "gets used to it" • US-alone – present US alone with no CS pairing – problem: not have same number of CS trials
Rescorla: 6 types of control groups • Explicitly unpaired control – CS NEVER predicts US – that is- presence of CS is really CS-, predicts NO US – animal learns new rule: if CS, then no US • Backward conditioning: – US precedes CS – assumes temporal order is important (but not able to explain why) – again, animal learns that CS predicts no US • Discrimination conditioning (CS+ vs CS-) – use one CS as a plus; one CS as a minus – same problem as explicitly unpaired and backwardworks, but can work in certain circumstances (taste avoidance)
Rescorla: Results with 6 Groups • CS-alone: No conditioning, but habituation to CS • Novel CS group: novel worked better than CS with previous experience. • US-alone: habituation to CS • Explicitly unpaired control: – Got GREAT conditioning – Learned that the CS NEVER predicts the US! • Backward conditioning: – US preceded CS – assumed temporal order is important – It was: Animal learned that CS predicts NO US, but US predicted CS • Discrimination conditioning (CS+ vs CS-) – use one CS as a plus; one CS as a minus – Got discrimination – Animals paid attention to whatever stimulus was MOST PREDICTIVE!
CS-US correlation: Summary of Results • Whenever p(US|CS) > p(US|NO cs): – CS = EXCITATORY CS – that is, CS predicts US – Amount of learning depended on size difference between p(US/CS) and p(US/no CS) • Whenever p(US|CS) <p(US|NO CS): – CS = INHIBITORY CS – CS predicts ABSENCE of US – Amount of learning depended on size difference between p(US/CS) and p(US/no CS) • Whenever p(US|CS) = p(US|NO CS): – CS = NEUTRAL CS – CS doesn’t predict or not predict CS – No learning will occur because there is no predictability.
CS-US correlation vs. contiguity • Thus: appears to be the CORRELATION between the CS and US, not the contiguity (closeness in time) that is important • Can write this more succinctly: – correlation carries more information than contiguity – if r = + then excitatory CS – if r = - then inhibitory CS – if r = 0 then neutral CS (not really even a CS)
Classical condition is “cognitive” (oh the horror of that statement, I am in pain) • PREDICTABILITY is critical • Learning occurs slowly, trial by trial – Each time the CS predicts the US, the strength of the correlation is increased – The resulting learning curve is monotonically increasing: • Initial steep curve • Levels off as reaches asymptote – There is an asymptote to conditioning to the CS: • Maximum amount of learning that can occur • Maximum amount of responding that can occur to CS in anticipation of the upcoming US • We can explain this through an equation!
The Rescorla Wagner Equation!: • Yields an equation: THE Rescorla Wagner (1974) model!!!!! Vi =αißj(Λj-Vsum) – Vi = amount learned (conditioned) on a given trial – Αi = the salience of the CS – ßj = the salience of the US – (Λj-Vsum) = total amount of conditioning that can occur to a particular CS-US pairing
The Rescorla Wagner Equation!: • Yields an equation: THE Rescorla Wagner (1974) model!!!!! Vi =αißj(Λj-Vsum) • What does this equation say? • The amount of conditioning that will occur on a given trial is a function of: • The size of the salience of the CS multiplied by • The size of the salience of the US multiplied by • (The maximum amount of learning) - (the amount of learning that has already occurred).
Can say this easier! • How much you will learn on a given trial (Vi) is a function of: – αi or how good a stimulus the CS is (how well it grabs your attention) – ßj or how good a stimulus the US is (how well it grabs your attention – Λj or how much can learning can be learned about the CS-US relationship – AND Vsum or how much you have learned ALREADY!
Assumptions of Rescorla-Wagner (1974) model • Model developed to accurately predict and map learning as it occurs trial by trial • Assumes a bunch of givens: – Assume animal can perceive CS and US, and can exhibit UR and CR – Helpful for the animal to know 2 things about conditioning: • what TYPE of event is coming • the SIZE of the upcoming event • Thus, classical conditioning is really learning about: – signals (CS's) which are PREDICTORS for – important events (US's)
Assumptions of R-W model • Assumes that with each CS-US pairing 1 of 3 things can happen: – The CS might become more INHIBITORY – The CS might become more EXCITATORY – There is no change in the CS • How do these 3 rules work? – If US is larger than expected: CS = excitatory – If US is smaller than expected: CS= inhibitory – If US = expectations: No change in CS • The effect of reinforcers or nonreinforcers on the change of associative strength depends upon: – The existing associative strength of THAT CS – AND on the associative strength of other stimuli concurrently present
More assumptions • Explanation of how an animal anticipates what type of CS is coming: – Direct link is assumed between "CS center" and "US center": • E. g. between a tone center and food center • In 1970’s: other researchers thought R and W were crazy with this idea • Now: neuroscience shows formation of neural circuits! – Assumes that STRENGTH of an event is given • The conditioning situation is predicted by the strength of the learned connection – THUS: when learning is complete: • The strength of the association relates directly to the size or intensity of the CS • Asymptote of learning = max learning that can occur to that size or intensity of a CS • Maximum amount of learning that a given CS can support
More assumptions • The change in associative strength of a CS as the result of any given trial can be predicted from the composite strength resulting from all stimuli presented on that trial: – Composite strength = summation of conditioning that occurs to all stimuli present during a conditioning trial – If composite strength is LOW: • the ability of reinforcer to produce increments in the strength of component stimuli is HIGH • More can be learned for this trial – If the composite strength is HIGH: • reinforcement is relatively less effective (LOW) • Less can be learned for this trial- approaching max of learning
More assumptions: • Can expand to extinction, or nonreinforced trials: – if composite associative strength of a stimulus compound is high, then the degree to which a nonreinforced presentation will produce a decrease in associative strength of the components is LARGE – if composite associative strength is lownonreinforcement effects reduced
WHY is this equation important? • We can use three rules to make predictions about amount and direction of classical conditioning • λ j > Vsum = excitatory conditioning – The degree to which the CS predicted the size of the US was GREATER than expected, so you react MORE to the CS next trial • λ j < Vsum = inhibitory conditioning – The degree to which the CS predicted the size of the US was LESS than expected, so you react LESS to the CS next trial • λ j = Vsum = no change: – The CS predicted the size of the US exactly as you expected
The Equation: Let’s USE it to Explain Learning, Overshadowing and Blocking!: Vi =αißj(Λj-Vsum) • Vi = amount learned (conditioned) on a given trial • Αi = the salience of the CS • ßj = the salience of the US • (Λj-Vsum) = total amount of conditioning that can occur to a particular CS-US pairing
Okay, you got all that? Let’s put this baby to work……. we will try a few examples
The equation: Vi =αißj(λ j-Vsum) • Vi = change in associative strength that occurs for any CS, i, on a single trial • αi = stimulus salience (assumes that different stimuli may acquire associative strength at different rates, despite equal reinforcement) • ßj = learning rate parameters associated with the US (assumes that different beta values may depend upon the particular US employed) • Vsum = associative strength of the sum of the CS's (strength of CS-US pairing) • λ j= associative strength that some CS, i, can support at asymptote • In English: How much you learn on a given trial is a function of the value of the stimulus x value of the reinforcer x (the absolute amount you can learn minus the amount you have already learned).
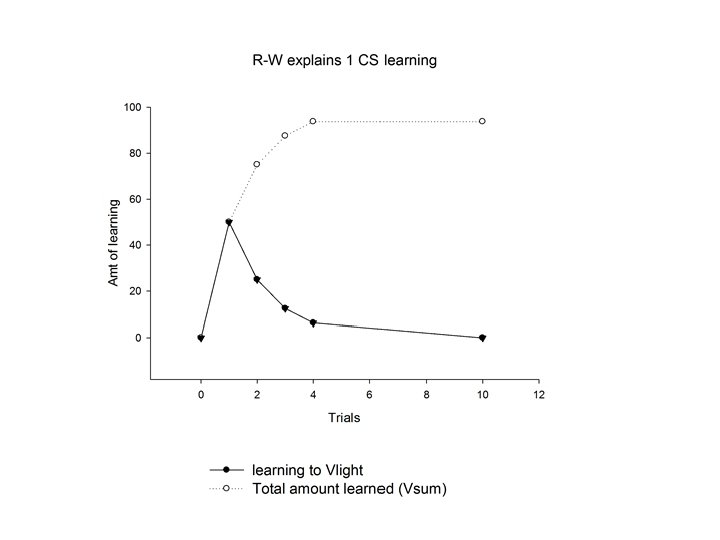
Acquisition • first conditioning trial: Assume (our givens) – CS = light; US= 1 ma Shock – Vsum = Vl; no trials so Vl = 0 – thus: λ j-Vsum = 100 -0 = 100 – -first trial must be EXCITATORY • BUT: must consider the salience of the light: – αi = 1. 0 – ßj = 0. 5
Acquisition • first conditioning trial: CS = light; US= 1 ma Shock – Vsum = Vl; no trials so Vl = 0 – thus: λ j-Vsum = 100 -0 = 100 – -first trial must be EXCITATORY • BUT: must consider the salience of the light: αi = 1. 0 and learning rate: ßj = 0. 5 • Plug into the equation: for TRIAL 1 – VL = (1. 0)(0. )(100 -0) = 0. 5(100) = 50 – thus: V only equals 50% of the discrepancy between Aj an Vsum for the first trial
Acquisition • Plug into the equation: – for TRIAL 1 –VL = (1. 0)(0. )(100 -0) = 0. 5(100) = 50 –thus: VL only approaches 50% of the discrepancy between Aj and Vsum is learned for the first trial
Acquisition • TRIAL 2: – Same assumptions! – VL = (1. 0)(0. 5)(100 -50) = 0. 5(50) = 25 – Vsum = (50+25) = 75
Acquisition • TRIAL 3: – VL = (1. 0)(0. 5)(100 -75) = 0. 5(25) = 12. 5 – Vsum = (50+25+12. 5) = 87. 5
Acquisition • TRIAL 4: – VL = (1. 0)(0. 5)(100 -87. 5) = 0. 5(12. 5) = 6. 25 – Vsum = (50+25+12. 5+6. 25) = 93. 75 • TRIAL 10: Vsum = 99. 81, etc. , until reach ~100 on approx. trial 14 • When will you reach asymptote?
Now: Back to Explaining Blocking and Overshadowing • Overshadowing: – use one "weak" and one "strong" CS – reaction to weaker stimulus: less CR – Reaction to stronger stimulus: more CR • Blocking: 1 st CS blocks learning to 2 nd CS – At issue: What is predicting what? – Does LT give any more information/predictability than L alone? – If not, then L “blocks” learning to LT
How to explain overshadowing? Yep, it is good old Rescorla-Wagner to the rescue!
Remember Overshadowing • Pavlov: compound CS with 1 intense CS, 1 weak – after a number of trials found: strong CS elicits strong CR – Weak CS elicits weak or no CR • Note: BOTH CSs are presented at same time – Why would one over shadow or overpower the other? – Why did animal not attend equally to both?
Overshadowing • Rescorla-Wagner model helps to explain why: • Assume – αL = light = 0. 2; αT = tone = 0. 5 – ßL = light = 1. 0 ; ßt = tone = 1. 0 • Plug into equation: – Vsum = Vl + Vt = 0 on trial 1 – VL = 0. 2(1)(100 -0) = 20 – Vt = 0. 5(1)(100 -0) = 50 – after trial 1: Vsum = 70
Overshadowing • TRIAL 2: – VL = 0. 2(1)(100 -(50+20)) = 6 – Vt = 0. 5(1)(100 -(50+20)) = 15 – Vsum = (70+(6+15)) = 91 • TRIAL 3: – – VL = 0. 2(1)(100 -(91)) = 1. 8 Vt = 0. 5(1)(100 -(91)) = 4. 5 Vsum = (91+(1. 8+4. 5)) = 97. 3 and so on thus: reaches asymptote (by trial 6) MUCH faster w/2 CS's • NOTE: CSt takes up over 70 units of assoc. strength CSl takes up only 30 units of assoc. strength
Overshadowing
Blocking • Similar explanation to overshadowing: – Does not matter whether VL has more or less saliency than Vt, – CS has basically absorbed all the associative strength that the CS can support • Why?
Blocking • give trials of A-alone to asymptote: – reach asymptote: VL = λ j =100 =Vsum • NOW add trials to compound stimuli: – CS of the light has salience: αL =. 5465 – CS of tone has salience of: ßt =0. 464 – Note that CStone has higher salience! – Eh, oh, the math is going to be TOO HARD to do!!!!!
Blocking • Or IS the math to hard to do? • First compound V 1 Trial: • Vt= αß(Λj-Vsum) • What is Vsum after the training to the CS light? • That’s right Vsum = ______ • Vt=0. *1. 0*(100 -100)= _______ • No learning!
How could one eliminate blocking effect? • increase the intensity of the US to 2 m. A with λ j now equals = 160 – Learning so far: Vsum still equals 100 (learned to 1 m. A shock) – But now: TOTAL learning is increased to 160!
How could one eliminate blocking effect? • plug into the equation: • (assume Vl and Vt equally salient) – Vt = 0. 2(1)(160 -100) = 0. 2(60) = 12 – Vl = 0. 2(1)(160 -100) = 0. 2(60) = 12 – Vsum = 100+12+12 =124
How could one eliminate blocking effect? • on trial 2: – Vsum = 124 – Vt = 0. 2(1)(160 -124) = 0. 2(36) = 7. 2 – Vl = 0. 2(1)(160 -124) = 0. 2(36) = 7. 2 – Vsum now = (124+14. 4) = 138. – Again, monotonically increasing curve. • Thus, altering the salience of the US alters the learning • Does altering the CS make the same change?
Can also explain why probability of reward given CS vs no CS makes a difference: • π = probability of US given the CS or No US given No CS • can make up three rules: – if πax > πa then Vx should be POSITIVE – if πax < πa then Vx should be NEGATIVE – if πax = πa then Vx should be ZERO • modified formula: (assume λ 1 =1. 0; λ 2 =0; ß 1 =. 10; ß 2=. 05; α 1=. 10; α 2=. 5) • Πa = probability of reward.
Explaining loss of Associate Value despite pairings with the US: • Is an unusual prediction: Associative value of a CS can decrease despite continued pairings with the US • Show this with three-phase experiment: – Phase 1: A and B stimuli US (1 food pellet) on separate trials (equal #) – Phase 2: A and B paired together 1 food pellet • Same US, so same amount of conditioning, right? ? • RW model predicts that conditional properties of A and B individually will DECREASE in phase 2. – Why: VA= λ ; VB= λ for phase 1; so VA+B = VA+B=2 λ • This is an over-expectation • Not get 2 pellets, so Phase 2 = decremental conditioning – When test A and B alone: do indeed get decremental responding or Conditioned Inhibition
Conditioned Inhibition • RW model also predicts Conditioned inhibition • Can test for Conditioned inhibition – 2 kinds of trials • CS+ US trials • CS- no US trials – Consider 2 kinds of trials separately • Reinforced trials: CS+ gains excitatory properties • Unreinforced trials: CS- gains inhibitory properties • When presented together: cancel one another out (assuming equal conditioning) • Is a SUMMATIVE effect
Extinction of excitation and inhibition • During extinction: EXT: CS+ no US – Initially: animal expects CS-US and is excitatory – This excitatory expectation is quickly diminished with repeated trials of no US • Decreases the excitatory conditioning incrementally, just like the excitatory conditioning was increased incrementally during learning
Dopamine and Rescorla Wagner Model • Turns out that changes in dopamine (DA) levels in dorsal striatal limbic cortical pathway vary as we learn • And guess what: these levels can be predicted by the RW model! • But, once a CS-US pairing (or an operant R-SR pairing) become well learned, the circuit begins to involve lower parts of the brain – – Circuit begins to involve basal striatal areas Becomes an “automated” or mastered behavior No longer involves being “surprised” Only returns to this pathway if the CS-US relation change!!!!!
Critique of the Rescorla-Wagner Model: • R-W model really a theory about the US effectiveness: – Says little about CS effectiveness – How WELL a CS predicts as a combo of salience and probability but doesn’t really evaluate this – States that an unpredicted US is effective in promoting learning, whereas a well-predicted US is ineffective because nothing is left to learn.
Critique of the Rescorla-Wagner Model: • Fails to predict the CS-pre-exposure effect: – Two groups of subjects • Grp II CS-US pairings CS alone Control CS-US pairings PRE-Expos • Bob and Tom effect – Bob always hangs with Tom – You are dating Tom – You have a BAAAAAD breakup with Tom – Now you hate Bob…. why? • Original model didn’t address how exposure could change salience/learning to CS
Critique of the Rescorla-Wagner Model: • In pre-exposure effect, simply being around a neutral stimulus alters its ability to become conditioned • Original R-W model doesn't predict any difference, – Assumes no conditioning trials occur when CSs presented in absence of US so Vsum = 0 – This appears to be wrong • Conditioning likely occurring any time 2 stimuli are together – Form an incidental association – Need to modify the equation to account for this – They have, but we won’t!
Critique of the Rescorla-Wagner Model: • Original R-W model implies that salience is fixed for any given CS – R-W assume CS salience doesn't change w/experience – More recent data strongly suggest CS salience DOES change w/experience • Why changes in CS salience? – Data suggest that Salience to a CS DECREASES when CS is repeatedly presented without consequence – CS that is accidentally paired with another CS INCREASES in salience – Thus: ppears that CS and US effectiveness are both highly important • Model has stood test of time, now widely used in neuroscience • Given birth to attentional models of CC
Extensions and Alternatives to RW theory • Attentional models • Timing and Information models • Comparator hypothesis
Attentional Models of CC • How well does the CS command attention – Assumes that increased attention facilitates learning about a stimulus – Procedures that disrupt attention to CS disrupt learning • Different attentional models differ in assumptions about what determines how much attention a CS commands on any given trial – Single attentional mechanisms: Kamin’s surprise – Multiple attentional mechanisms:
Multiple attentional mechanisms: • Three attentions: – Looking for action: attention a CS commands after it has become a good predictor of the CS – Looking for learning: how well the organism processes cues that are not yet good predictors of the US, and thus have to be “learned about” – Looking for liking: the emotional/affective properties of the CS • Assume that the outcome of a given trial alters the degree of attention commanded by the CS on future trials – Surprise? Then an increase in looking for learning on next trial – Pleasant outcome? Increases emotional value of CS on next trial
Timing/Information Theory Models • Recognized that time is important factor in CC – Focal search responses become conditioned when CS-US interval is short – General search responses become conditioned when CS-US interval is long – Suggests that organisms learn both • WHAT is predicted • WHEN what is predicted will occur
Temporal coding hypothesis • Organisms learn when the US occurs in relation to the CS • Use this information in blocking, second-order conditioning, etc. • What is learned in one phase of training influences what is learned in subsequent phase • Large literature supports this
Importance of Inter-trial interval • More conditioned responding observed with a longer inter-trial interval – Intertrial interval and CS duration (CS-US interval) act in combination to determine responding – Critical factor: Relative duration of these two temporal intervals rather than absolute value of either one by itself • Holland (2000) – Conditioned rats to an auditory cue that was presented just before delivery to food – CR to CS: nosing of food cup (goal tracking) – Each group conditioned with • 1 of 2 CS durations: 10 or 20 sec • 1 of 6 intertrial intervals: 15 to 960 sec – Characterized responses in terms of theratio of the intertrial interval (I) and the CS duration (T). • Time spent nosing the food cup during CS plotted as function of relative value of I/T – Results: as IT ratio increases, the percentage of time the rats spend with the nose in the food cup increases
Importance of Inter-trial interval • Relative Waiting Time Hypothesis – Organism making comparison between events during the Intertrial interval (I) and Trial interval (T) – How long one has to wait for the US during the CS vs. how long one has to wait for the US during the intertrial interval • When US waiting time during CS is shorter than intertrial interval: – I/T ratio is high – CS is highly informative about the next occurrence of the US – Lots of responding • When US waiting time during CS is same/longer than intertrial interval wait: – I/T ratio is low – CS is not highly informative – Less responding
Comparitor Hypothesis • Ralph Miller, et al. : organism compares across learning situations • Assumes: Conditional responding depends on – What happens during CS – ALSO what happens in other aspects of experimental situation (when CS is not presented) – That is, animal compares presence of CS to absence of CS • Revaluation effects: Can better explain blocking – What is blocked is RESPONDING to CSAB, not learning of CSAB – Can unmask blocking to CSAB by presented CSA alone without US (EXT CSA). • Changes conditional value of CSA • Now CSAB has different, predictive value • Animal “revalues” CSAB and now responds as it is predictive, whereas CSA is not.
Comparator Hypothesis • Note: this is a theory of PERFORMANCE, not learning! – Assumes conditioned responding depends on BOTH associations between CS-US and between US and other stimuli when CS not there – These other stimuli form the “comparator” cues • Also assumes formation of excitatory associations with US ONLY – Instead of forming inhibitory associations with CS, form stronger excitatory associations with “not CS” – Animal compares the relative associative value of “CS vs. “not CS” – Whatever is stronger is what you respond to
Why are these theories important? • Helps explain the PROCESS of classical conditioning • Describes conditions and allows predictions of – – – Who is likely to form associations between stimuli To What kinds of stimuli it will occur When classical conditioning will occur Where associations form: what settings/conditions are important How well: how fast/slow, what quality of associations are formed. • Important for predicting/controlling in applied settings – – Understanding and treatment of pedophilia, sexual fetishes, etc. Phobia treatment Commercials and advertising Social behaviors