Learning with spikes and the Unresolved Question in

 Bliss & Lomo 1973 discovered")



 … membrane capacitance … conductance along dendrite …")
 etc ………. voltage: information from within")

. u HOW DOES ONE SPIKE TIMING")


 > ~ log |T| + ∑")
. A 9 x 9 network extracts independent point processes")


![Problems with this spikelihood model: -requires a non-lossy map [t, i] in -> [t,](https://slidetodoc.com/presentation_image_h/0002263877919a1cd80bfa138d99d483/image-23.jpg "Problems with this spikelihood model: -requires a non-lossy map [t, i] in -> [t,")

")
 integrates incoming spike information with global cell state. 2+")


 World modeling is not done")


 neurostatistical model, as articulated by Emo")
 y 2 Infomax between Levels.")



- Slides: 36
Learning with spikes, and the Unresolved Question in Neuroscience/Complex Systems Tony Bell Helen Wills Neuroscience Institute University of California at Berkeley
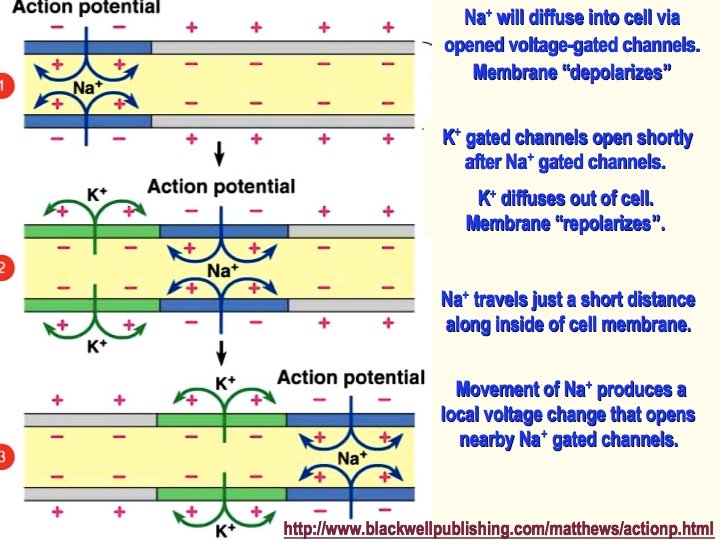
Learning in real neurons: Long-term potentiation and depression (LTP/LTD) Bliss & Lomo 1973 discovered associative and input specific (Hebbian) changes in sizes of EPSC’s: a potential memory mechanism (the memory trace). Found first in hippocampus: known to be implicated in learning and memory. LTP from high-frequency presynaptic stimulation, or low-frequency presynaptic stimulation and postsynaptic depolarisation. LTD from prolonged low-frequency stimulation. Levy & Steward (1983) played with timing of weak and strong input from entorhinal cortex to hippocampus, finding LTD when weak after strong, LTP when strong up to 20 ms after weak or simultaneous. Spike Timing-Dependent Plasticity (STDP) Markram et al (1997) find 10 ms window for time-dependence of plasticity, by manipulating pre- and post-synaptic timings.
Spike Timing Dependent Plasticity Experimenting with pre- and post-synaptic spike-timings at a synapse between a retinal ganglion cell and a tectal cell. (Zhang et al, 1998)
STDP is different in different neurons. Diverse mechanisms Common objective? ? Figure from Abbott and Nelson
STDP is different in different neurons. Diverse mechanisms Common objective? ? This may be true, but first we had better understand the mechanism, or we will most likely think up a bad theory based on our current prejudices and it won’t have any relevance to biology (which, like the rest of the world, is stranger than we can suppose…. )
Equation for membrane voltage (cable equation) … membrane capacitance … conductance along dendrite … maximum conductance for channel species k … time-varying fraction of those channels open … reversal potential for channel species k
Equation for ion channel kinetics (non-linear Markov model) etc ………. voltage: information from within the cell ………. extracellular ligand: information from other cells …intracellular calcium: information from other molecules
Can we connect the information-theoretic learning principles we studied yesterday to the biophysical and molecular reality of these processes? Let’s give it a go in a simplified model…. the Spike Response Model (a sophisticated variant of the ‘integrate-and-fire’ model).
. Wij Rkl (t k - tl ). u HOW DOES ONE SPIKE TIMING AFFECT ANOTHER? uk = ∑ Wij R kl (t k - tl ) l Gerstner’s SPIKE RESPONSE MODEL: Tkl = ∂ tk ∂ tl = k IMPLICIT DIFFERENTIATION
Assuming: a deterministic feedforward invertible network, The Idea is: output spikes to be as sensitive as possible to inputs. Maximum Likelihood: try to map inputs uniformly into unit hypercube: y Maximum Spikelihood: try to map inputs into independent Poisson processes: t' i' W W x p(y) ti p(t' i') 1 p(y) = p(x) | | p(t' i' ) = p(t i) | |
OBJECTIVE FUNCTIONS FOR RATE AND SPIKING MODELS: BE NON-LOSSY USE THE BANDWIDTH use all firing rates equally LIKELIHOOD y W L(x) = log |W| + ∑ log q(u i) i x make the spikecount Poisson SPIKELIHOOD t' i' W ti L(t i) > ~ log |T| + ∑ log q(n'i ) i
THE LEARNING RULE for the objective: L(t i) > ~ log |T| + ∑ log q(n'i ) i is mean rate sum over spikes from neuron j when T is a single rate at input synapse
Simulation results: Coincidence detection (Demultiplexing). A 9 x 9 network extracts independent point processes from correlated ones unmixing matrix (learned) demultiplexed spike trains time (ms) multiplexed spike trains mixing matrix original spike trains
Mixing Unmixing × demultiplexed original Identity =
Compare with STDP: The Spike Response Model is causal. It only takes into account how output spikes talk about past input spikes: Froemke& Dan, Nature 2002 Bell & Parra (NIPS 17) But real STDP has a predictive component: (spikes also talk about future spikes) OUT causal predictive IN ? Postsynaptic calcium integrates this information (Zucker 98), both causal (NMDA channels -> CAM-K) and predictive (L-channels -> calcineurin)
Problems with this spikelihood model: -requires a non-lossy map [t, i] in -> [t, i]out (which we enforced…) -learning is (horrendously) non-local -model does not match STDP curves -model ignores predictive information -information only flows from synapse to soma, and not back down
By infomaxing from input spikes to output spikes, we are ignoring the information that flows from output spikes (and elsewhere in the dendrites) back down to where the input information came from - the site of learning: the protein/calcium machinery at postsynaptic densities, where the plasticity calculation actually takes place. What happens if you include this in your Jacobian? Then the Jacobian between all spike-timings becomes the sum total of all intradendritic causalities. And spikes are talking to synapses, not other spikes. This is a massively overcomplete interlevel information flow (1000 times as many synaptic events as neural events). What kind of density estimation scheme do we then have?
The Within models and creates the Between: ie: inside the cells: (timings voltage calcium) models and creates between the cell: (spikes)
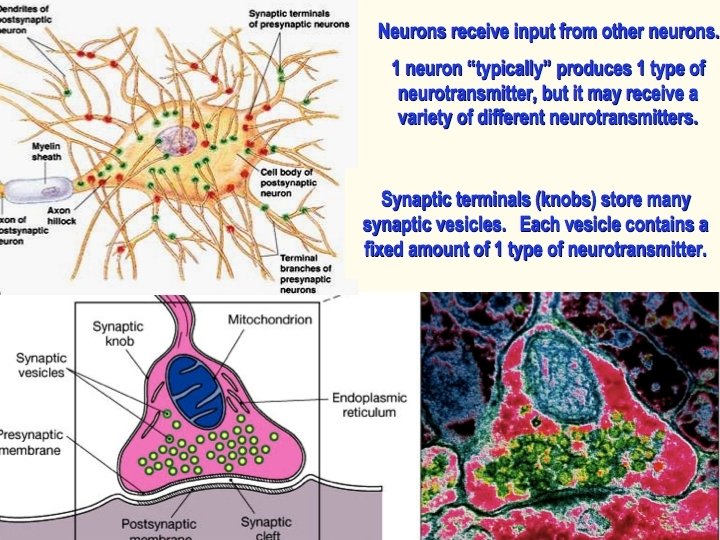
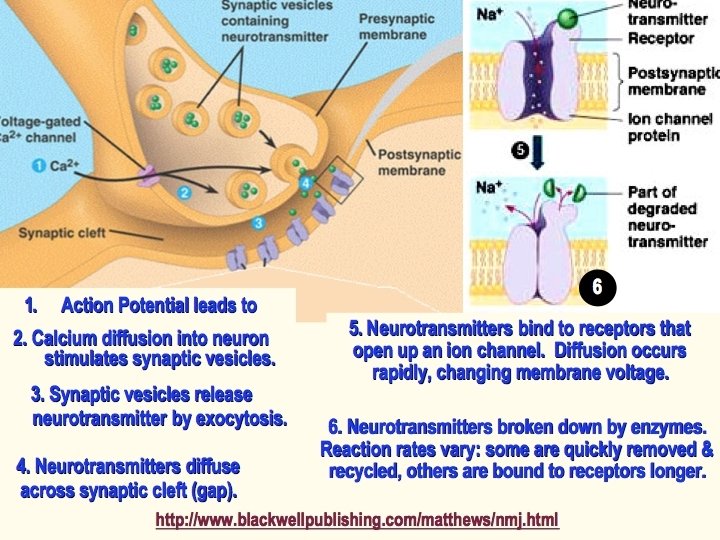
Post-synaptic machinery (site of learning) integrates incoming spike information with global cell state. 2+ Ca converts timing and voltage information into molecular change vesicle with glu receptors is trafficked to plasma membrane Ca 2+ endoplasmic reticulum dendrite Ca 2+ protein machinery AMPA channel neurotransmitter (glutamate) NMDA channel synapse voltagedependent L-channel
Networks within networks: network of neurons network of 2 agents 1 brain network of protein complexes (eg: synapses) 1 cell network of macromolecules
A Multi-Level View of Learning LEVEL UNIT INTERACTIONS LEARNING ecology society predation, symbiosis natural selection society organism behaviour sensory-motor learning organism cell synapse protein amino acid spikes voltage, Ca direct, V, Ca molecular forces synaptic plasticity ( = STDP) bulk molecular changes gene expression, protein recycling Increasing Timescale LEARNING at a LEVEL is CHANGE IN INTERACTIONS between its UNITS, implemented by INTERACTIONS at the LEVEL beneath, and by extension resulting in CHANGE IN LEARNING at the LEVEL above. Separation of timescales allows INTERACTIONS at one LEVEL to be LEARNING at the LEVEL above. Interactions=fast Learning=slow
Advantages: A closed system can model itself (sleep, thought…) World modeling is not done directly. Rather, it occurs as a side-effect of self-modeling. The world is a ‘boundary-condition’ on this modeling, imposed by the level above - by the social level. The variables which form the probability model are explicitly located at the level beneath the level being modeled. Generalising to molecular and social networks suggests that gene expression and reward-based social agency may just be other forms of inter-level density estimation.
Does the ‘standard model’ really suffice? Decision Reinforcement Eh. . somewhere else Action V whatever V 1 Thalamus Retina
Does the ‘standard model’ really suffice? Decision Reinforcement Eh. . somewhere else Action V whatever V 1 Thalamus Retina Or is it ‘levels-chauvinism’?
The standard (or rather the slightly more emerged) neurostatistical model, as articulated by Emo Todorov: The emerging computational theory of perception is Bayesian inference. It postulates that the sensory system combines a prior probability over possible states of the world, with a likelihood that observed sensory data was caused by each possible state, and computes a posterior probability over the states of the world given the sensory data. The emerging computational theory of movement is stochastic optimal control. It postulates that the motor system combines a utility function quantifying the goodness of each possible outcome, with a dynamics model of how outcomes are caused by control sequences, and computes a control law (state-control mapping) which optimizes expected utility. But we haven’t seen yet what unsupervised models may do when they are involved in sensory-motor loops. They may sidestep common criticisms of feedforward unsupervised theories ……
1 Infomax between Layers. (eg: V 1 density-estimates Retina) y 2 Infomax between Levels. (eg: synapses density-estimate spikes) t V 1 all neural spikes synapses, dendites synaptic weights x retina y • within-level • feedforward • molecular sublevel is ‘implementation’ • social superlevel is ‘reward’ • predicts independent activity • only models outside input all synaptic readout • between-level • includes all feedback • molecular net models/creates • social net is boundary condition • permits arbitrary activity dependencies • models input and intrinsic together pdf of all synaptic ‘readouts’ This SHIFT in looking at the problem alters the question so that if it is answered, we have an unsupervised theory of ‘whole brain learning’. pdf of all spike times If we can make this pdf uniform then we have a model constructed from all synaptic and dendritic causality
What about the mathematics? Is it tractable? Not yet. A new, in many ways satisfactory, objective is defined, but the gradient calculation seems very difficult. But this is still progress.
Density Estimation when the input is affected: Make the model like the reality by minimising the Kullback-Leibler Divergence: by gradient descent in a parameter It is easier to live in a world where one can of the model change the world to fit the model, as well as : changing one’s model to fit the world
Conclusion: This should be easier, but it isn’t yet. I’m open to suggestions… What have we learned from other complex self-organising systems? Is there a simpler model which captures the essence of the problem?