EE 368 Soft Computing Dr Unnikrishnan P C






 The perceptron is the simplest form of a neural network.")



























- Slides: 38
EE 368 Soft Computing Dr. Unnikrishnan P. C. Professor, EEE
Module I q Perceptrons
The topology of a neural network
Neurons: The building blocks of neural networks Biology Vs technology
Inside an artificial neuron 1. Each input gets scaled up or down 2. All signals are summed up 3. Activation
The Perceptron Most basic form of an activation function is a simple binary function, A neuron whose activation function is a function like this is called a perceptron.
Single-layer two-input Perceptron (Rosenblatt) The perceptron is the simplest form of a neural network. It consists of a single neuron with adjustable synaptic weights and a hard limiter.
Rosenblatt’s Perceptron The operation of Rosenblatt’s perceptron is based on the Mc. Culloch and Pitts neuron model. The model consists of a linear combiner followed by a hard limiter. The weighted sum of the inputs is applied to the hard limiter, which produces an output equal to +1 if its input is positive and 1 if it is negative.
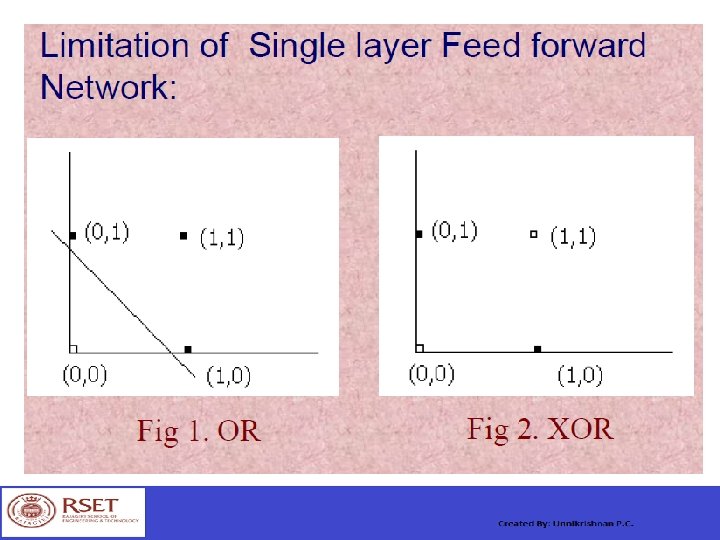
Rosenblatt’s Perceptron …… The aim of the perceptron is to classify inputs, x 1, x 2, . . . , xn, into one of two classes, say A 1 and A 2. In the case of an elementary perceptron, the ndimensional space is divided by a hyperplane into two decision regions. The hyperplane is defined by the linearly separable function: n xiwi 0 i 1
Linear separability in the Perceptrons
How does the Perceptron learn its classification tasks? This is done by making small adjustments in the weights to reduce the difference between the actual and desired outputs of the perceptron. The initial weights are randomly assigned, usually in the range [ 0. 5, 0. 5], and then updated to obtain the output consistent with the training examples.
Perceptron’s training algorithm Step 1: Initialisation : Set initial weights w 1, w 2, …, wn and threshold to random numbers in the range [-0. 5, 0. 5]. Step 2: Activation Activate the perceptron by applying inputs x 1(p), x 2(p), …, xn(p) for which the desired output Yd (p). Calculate actual output for iteration p=1. where n is the number of the perceptron inputs, and step is a step activation function.
Perceptron’s training algorithm Step 3: Weight Training Update the weights of the perceptron wi ( p 1) wi( p) wi ( p) where wi(p) is the weight correction at iteration p. The weight correction is computed by the delta rule: wi ( p) xi ( p). e( p) Step 4: Iteration Increase iteration p by one, go back to Step 2 and repeat the process until convergence.
Example: Logical AND
Linearly separable data
Linearly separable data
Linearly Non-Separable data
Non-Linearly separable data
3 dimensional dataset that is linearly separable In n dimensions, the separator is a (n-1) dimensional hyperplane.
Cover's theorem • The theorem states that given a set of training data that is not linearly separable, one can with high probability transform it into a training set that is linearly separable by projecting it into a higher-dimensional space via some non-linear transformation. • A complex pattern-classification problem, cast in a high-dimensional space nonlinearly, is more likely to be linearly separable than in a low-dimensional space, provided that the space is not densely populated.
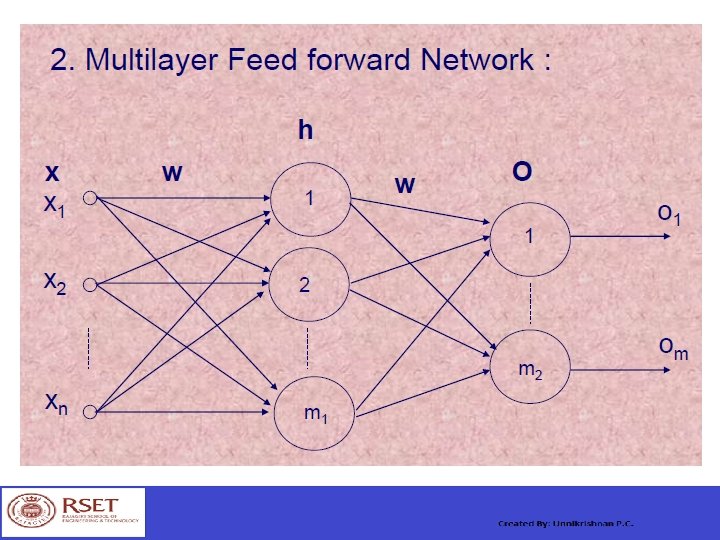
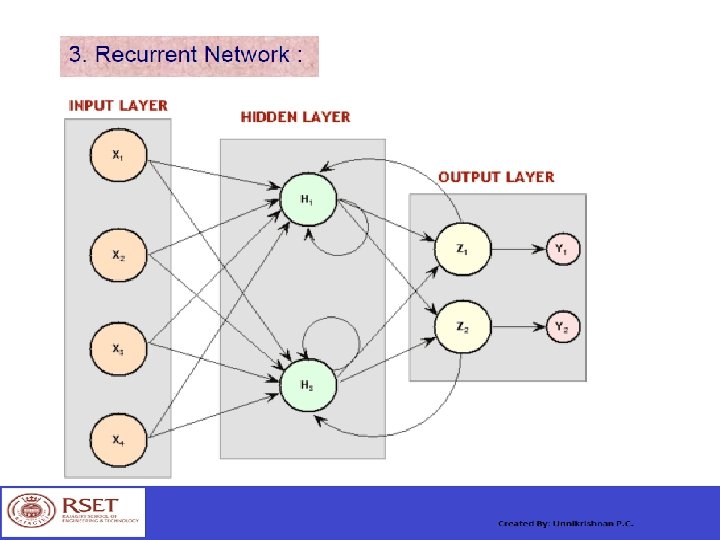
Artificial Neural Networks Architectures:
Learning • The procedure that consists in estimating the parameters of neurons so that the whole network can perform a specific task • 2 types of learning – The supervised learning – The unsupervised learning • The Learning process (supervised) – Present the network a number of inputs and their corresponding outputs – See how closely the actual outputs match the desired ones – Modify the parameters to better approximate the desired outputs
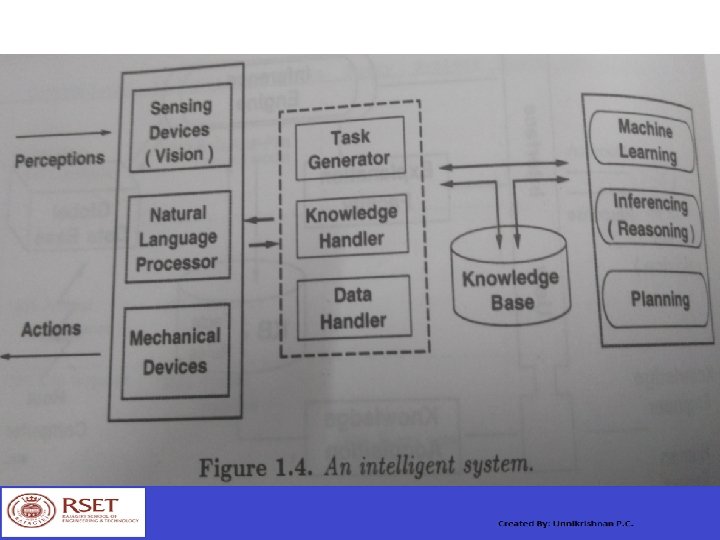
An Expert System
An Expert System
Thank You