Question Answering over Linked Data Outline Question Answering

 Case Studies Challenges Trends")




 • Datasets: – Dbpedia 3. 6 (RDF) – Music. Brainz (RDF)")

![QALD-1 • [1]. The answers will be either a literal (a boolean, date ,](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-9.jpg "QALD-1 • [1]. The answers will be either a literal (a boolean, date ,")
 • Evaluation Measures Recall Precision F-Measures")

 • Datasets: – Dbpedia 3. 7 (RDF) – Music. Brainz (RDF)")

![QALD-2 • [1]. answertype: resource / string / number / date / boolean; •](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-14.jpg "QALD-2 • [1]. answertype: resource / string / number / date / boolean; •")


 • • Datasets: – Dbpedia 3. 8 (RDF) 100/100 – Spanish")

![QALD-4, CLEF (2014) • Task 1: multilingual QA over Dbpedia. [200, 50] • Task](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-19.jpg "QALD-4, CLEF (2014) • Task 1: multilingual QA over Dbpedia. [200, 50] • Task")






")
 Querying the Semantic Web")


![Main drawback • [1] Its main weakness is that due to limitation in GATE](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-30.jpg "Main drawback • [1] Its main weakness is that due to limitation in GATE")

 Template-based question answering")


![TBSL: Overview • [1] The input question is first processed by a POS tagger.](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-35.jpg "TBSL: Overview • [1] The input question is first processed by a POS tagger.")


![Evaluation: QALD • [1] Of the 50 training questions provided by the QALD benchmark](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-38.jpg "Evaluation: QALD • [1] Of the 50 training questions provided by the QALD benchmark")

![TBSL: Summary • Key contributions: [1]. The main contribution is a domain-independent question answering](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-40.jpg "TBSL: Summary • Key contributions: [1]. The main contribution is a domain-independent question answering")
 Schema-agnostic querying using distributional semantics")



![The Treo's query processing Through 3 major steps: • [1] Entity Search and Pivot](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-45.jpg "The Treo's query processing Through 3 major steps: • [1] Entity Search and Pivot")
![[1] Entity Search and Pivot Entity Determination • Consists in determining the key entities](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-47.jpg "[1] Entity Search and Pivot Entity Determination • Consists in determining the key entities")
![[2] Query Syntactic Analysis • Transform natural language queries into triple patterns. • The](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-48.jpg "[2] Query Syntactic Analysis • Transform natural language queries into triple patterns. • The")
![[3] Semantic Matching (Spreading Activation using Distributional Semantic. Relatedness) • Taking as inputs the](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-49.jpg "[3] Semantic Matching (Spreading Activation using Distributional Semantic. Relatedness) • Taking as inputs the")

![Evaluation: QALD-1 • [1]. The final approach achieved an mean reciprocal rank=0. 614, average](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-51.jpg "Evaluation: QALD-1 • [1]. The final approach achieved an mean reciprocal rank=0. 614, average")



![Treo: Summary • Key contributions: [1]. Distributional semantic relatedness matching model. [2]. Distributional model](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-55.jpg "Treo: Summary • Key contributions: [1]. Distributional semantic relatedness matching model. [2]. Distributional model")
 QA over RDF—A Graph Data Driven")


![Evaluation: QALD-3 • [1]. Test: 99 questions • [2]. Efectiveness Evaluation: • [3]. Efficiency](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-62.jpg "Evaluation: QALD-3 • [1]. Test: 99 questions • [2]. Efectiveness Evaluation: • [3]. Efficiency")

![g. Answer: summary • Key contributions: [1]. QA over RDF from subgraph matching perspective.](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-64.jpg "g. Answer: summary • Key contributions: [1]. QA over RDF from subgraph matching perspective.")



![Challenges [1]. The key challenge is to translate the user’s information needs into a](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-68.jpg "Challenges [1]. The key challenge is to translate the user’s information needs into a")


![References [1] Vanessa Lopez, M. Fernandez, E. Motta, N. Stieler. Power. Aqua: supporting users](https://slidetodoc.com/presentation_image_h/33f05f330a80dc8d9cefb57f83ff8cd5/image-71.jpg "References [1] Vanessa Lopez, M. Fernandez, E. Motta, N. Stieler. Power. Aqua: supporting users")

- Slides: 72
Question Answering over Linked Data
Outline • • Question Answering over Linked Data (QALD) Case Studies Challenges Trends
QALD
What is QALD • QALD is a series of evaluation campaigns on multilingual question answering over linked data. • This open challenge is aimed at all kinds of question answering system that mediates between a user, expressing his or her information need in natural language, and semantic data. • The goal is to evaluate and compare participating systems.
Why QALD——Motivations • The web of data continues to grow. • How to allow end users to profit from the expressive power of Linked Data while at the same time hiding their complexity behind an intuitive and easy-to-use interface ?
Why QALD——Motivations • The expressivity-usability trade-off for querying over structured data. • Ideally, a query mechanism for linked data must provide both high expressivity and high usability.
QALD-1, ESWC (2011) • Datasets: – Dbpedia 3. 6 (RDF) – Music. Brainz (RDF) • Tasks: – Training questions: 50 questions for each dataset – Test questions: 50 questions for each dataset
QALD-1
QALD-1 • [1]. The answers will be either a literal (a boolean, date , number, or string), or list of resources, for which both the URI as well as an English label or name (if it exists) is specified. • [2]. You are free to specify eithor a SPARQL query or the answers(or both), depending on which of them your system returns. • [3]. You are also allowed to change the query(insert quotes, reformulate, extract and use only keywords, use some structured input format, and the like). • [4]. You are free to use all resources (e. g. Word. Net, Geo. Names, dictionary tools, and so on). • [5]. All options count as correct answers, as long as the answer list contains all and only the correct resources.
Evaluation • Test Collection Questions Datasets Answers (Gold-standard) • Evaluation Measures Recall Precision F-Measures
QALD-1 Evaluation • The evaluation tool computes precision, recall and F-measure for every question: • The tool then also computes the overall precision, recall and F-measure along standard definitions:
QALD-2, ESWC (2012) • Datasets: – Dbpedia 3. 7 (RDF) – Music. Brainz (RDF) • Tasks: – Training questions: 100 questions for each dataset – Test questions: 50 questions for each dataset
QALD-2
QALD-2 • [1]. answertype: resource / string / number / date / boolean; • [2]. aggregation: whether any operations beyond triple pattern matching are required to answer the question (e. g. , counting, filters, ordering, etc. ). • [3]. onlydbo: only for DBpedia questions and reports whether the query relies solely on concepts from the DBpedia ontology. • [4]. You are also allowed to change the query(insert quotes, reformulate, extract and use only keywords, use some structured input format, and the like).
QALD-2 • As an additional challenge, a few of the training and test questions are out of scope
QALD-2 Evaluation • The evaluation tool computes precision, recall and F-measure for every question: • The tool then also computes the overall precision and recall taking the average mean of all single precision and recall values, as well as the overall F-measure.
QALD-3, CLEF (2013) • • Datasets: – Dbpedia 3. 8 (RDF) 100/100 – Spanish DBpedia 100/100 – Music. Brainz (RDF) 100/50 Tasks: – Multilingual QA: In order to achieve the goal that users from all countries have access to the same information. • Given a RDF dataset and a natural language question or set of keywords in one of six languages (English, Spanish, German, Italian, French, Dutch), either return the correct answers, or a SPARQL query that retrieves these answers. – Ontology Lexicalization: aimed at all methods that (semi-)automatically create lexicalizations for ontology concepts [CLEF: Conference and Labs of the Evaluation Forum]
QALD-3
QALD-4, CLEF (2014) • Task 1: multilingual QA over Dbpedia. [200, 50] • Task 2: Biomedical QA over interlinked data. • Task 3: hybrid approaches using information from both structured and unstructured data. • Datasets: – Dbpedia 3. 9 (RDF) – SIDER, Diseasome, Drugbank (RDF)
Task 2 “ 25, 25” • The focus of the task is on interlinked data. • Distributed among a large collection of interconnected datasets, and that answers to questions can often only be provided if information from several sources are combined.
Task 3 “ 25, 10” • The focus of the task is on hybrid QA, i. e. the integration of both structured data(RDF) and unstructured data(free text available in the Dbpedia abstracts). • A lot of information is still available only in textual form, both on the web and in the form of labels and abstracts in linked data sources. Therefore approaches are needed that can not only deal with the specific character of structured data but also with finding information in several sources, processing both structured and unstructured information, and combining such gathered information into one answer.
Task 3
Task 3 • The pseudo queries cannot be evaluated against the SPARQL endpoint. Therefore, when submitting results, provide answers.
Summary: QALD • QALD is a series of evaluation campaigns on question answering over linked data. QALD-1 (ESWC 2011) workshop QALD-2 (ESWC 2012) as part of a workshop QALD-3 (CLEF 2013) QALD-4 (CLEF 2014) • It is aimed at all kinds of systems that mediate between a user, expressing his or her information need in natural language, and semantic data. • Trends: 2个“单-->多”: 语言, 数据集; rdf+text.
Case studies The gap between natural language and Linked Data
Case studies • Aqualog & Power. Aqua (Vanessa Lopez et al. , 2006, 2012) Querying the Semantic Web [KMi] • TBSL (Chistina Unger et al. , 2012) Template-based question answering[CITEC] • Treo (Andre Freitas et al. , 2011, 2014) Schema-agnostic querying using distributional semantics[DERI] • g. Answer (Lei Zou et al. , 2014) QA over RDF——A Graph Data Driven Approach[pku] [Knowledge Media Institute(KMi), The Open University, United Kingdom] [The Center of Excellence Cognitive Interaction Technology(CITEC), Bielefeld University, German] [Digital Enterprise Research Institute (DERI), National University of Ireland, Galway] [Institute of Computer Science and Technology, Peking University, China]
Aqualog & Power. Aqua (Vanessa Lopez et al. ) Querying the Semantic Web
What is Power. Aqua • An ontology-based Question Answering system that is able to answer queries by locating and integrating information, which can be distributed across heterogeneous semantic resources. • The Power. Aqua supports query disambiguation , knowledge fusion ( to aggregate similar or partial answers), and ranking mechanisms, to identify the most accurate answers to queries. • Power. Aqua accepts users’ queries expressed in NL and retrieves precise answers by dynamically selecting and combining information massively distributed across highly heterogeneous semantic resources.
Power. Aqua:The architecture
Main drawback • [1] Its main weakness is that due to limitation in GATE it cannot cope with aggregation , comparisons, superlatives. • [2] Negations, comparatives, superlatives existential, or queries involving circumstantial (why) or temporal reasoning (last week , in the 80’s, between the year 94 and 95) are currently out of the scope of the linguistic component.
Power. Aqua: Summary The Power. Aqua’s main strength is that it locates and integrates information from different, heterogeneous semantic resources, relying on query disambiguation, ranking and fusion of answers. • Key contributions: Pioneer work on the QA over Semantic Web data. Semantic simliarity mapping. • Terminological Matching: Word. Net-based Ontology-based String similarity Sense-based similarity matcher • Evaluation: QALD (2011) recall: 0. 48, precision: 0. 52, f-measure: 0. 5.
TBSL (Chistina Unger et al. , 2012) Template-based question answering
What is TBSL • A prototype for An approach that combines both an analysis of the semantic structure and a mapping of words to URIs. • Two-step approach: [1]. Template generation Parse question to produce a SPARQL template that directly mirrors the structure of the question, including filters and aggregation opeations. [2]. Template instantiation Instantiate SPARQL template by matching natural language expressions with ontology concepts using statistical entity identificaiton and prediacate detection.
Example: Who produced the most films? • SPARQL template: select distinct ? x where{ ? y rdf: type ? c. ? y ? p ? x. } order by desc(count(? y)) limit 1 offset 0 ? c stands proxy for the URI of a class matching the input keyword films ? p stands proxy for a property matching the input keyword produced • Instantiations: By a matching class and a matching property: ? c=<http: //dbpedia. org/ontology/Film> ? p=<http: //dbpedia. org/ontology/producer>
TBSL: Overview • [1] The input question is first processed by a POS tagger. • [2] Lexical entries Pre-defined domain-independent lexical entries which leads to a semantic representation of the natural language query : convert into a SPARQL query termplate with slots that need to be filled with URIs. • [3] Entity Identification: obtain URIs. • [4] Entity and Query Ranking: this yields a range of different query candidates as potential translations of the input question. Ranking those query candidates.
TBSL: Overview
Main drawback • The created template structure does not always coincide with how the data is actually modelled. • Considering all possibilities of how the data could be modelled leads to a big amount of templates (and even more queries) for one question.
Evaluation: QALD • [1] Of the 50 training questions provided by the QALD benchmark , 11 questions rely on namespaces which they did not incorporate for predicate detection: FOAF and YAGO. They did not consider these question. [Predicate detection] • [2] Of 39 questions [50 -11] , 5 question cannot be parsed due to unknown syntactic constructions or uncoverd domain-independent expression. [Depending on POS tagger] • [3] Of 34 questions[39 -5] , 19 are answered exactly as required by the benchmark (i. e. with precision and recall 1. 0) and another two are answered almost correctly (with precision and recall > 0. 8). • [4] all precision scores : 0. 61; all recall scores: 0. 63; F-measure: 0. 62
Evaluation: QALD
TBSL: Summary • Key contributions: [1]. The main contribution is a domain-independent question answering approach that first converts natural language questions into queries that faithfully capture the semantic structure of the question then identifies domain-specific entities combining NLP methods and statistical information.
Treo (Andre Freitas et al. , 2011, 2014) Schema-agnostic querying using distributional semantics
Treo: Motivation • How to provide a query mechanism which allows users to expressively query linked datasets without a previous understanding of the vocabularies behind tha data? • Linked Data brings the vision of exposing and interlinking datasets on the Web by using Semantic Web standards. Consuming Linked Data today can be challenging. Linked Data brings a scenario where users may need to query/search over potentially thousands of highly heterogeneous datasets.
The critical problem • The critical problem is that the structure and terms used in the users' queries typically differ from the representation of the information in the datasets. In order to address this problem a query/search mechanism needs to cope with a robust semantic matching approach.
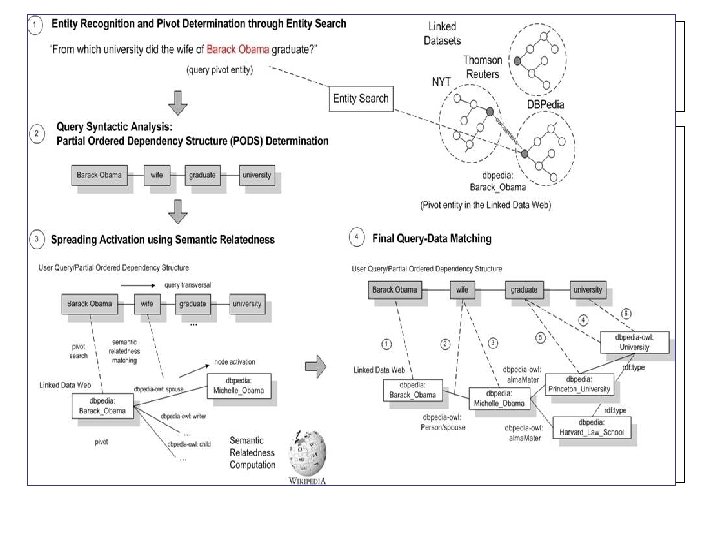
What is Treo • Treo is a natural language based semantic search engine for Linked Data. That focuses on the semantic matching behind user queries and Linked Datasets. • The main goal behind Treo is to abstract data consumers from the representation of the datasets, allowing expressive natural language queries over Linked Dataset. • Treo's query processing approach combines entity search, spreading activation search, and distributional semantic relatedness as the key elements to address the semantic matching problem. [video]
The Treo's query processing Through 3 major steps: • [1] Entity Search and Pivot Entity Determination. • [2] Query Syntactic Analysis. • [3] Semantic Matching (Spreading Achivation using Distributional Semantic Relatedness)
[1] Entity Search and Pivot Entity Determination • Consists in determining the key entities in the user query (what is the query is about? ) and mapping the entities in the query to entities on datasets. • The mapping from the natural language terms representing the entities to the URIs representing these entities in the datasets is done through entity search step. The URIs define the pivot entities in the datasets, which are the entry points for the semantic search process.
[2] Query Syntactic Analysis • Transform natural language queries into triple patterns. • The user natural language query is pre-processed into a partial ordered dependency structure (PODS), a format which is closer from the triple-like (subject, predicate and object) structure of RDF. • The construction of the PODS demands the previous entity recognition step. The partial ordered dependency structure is built by taking into account the dependency structrue of the query, the position of the key entity and a set of transformation rules.
[3] Semantic Matching (Spreading Activation using Distributional Semantic. Relatedness) • Taking as inputs the pivot entities URIs and the PODS query representation, the semantic matching process starts by fetching all the relations associated with the top ranked pivot entity. • Starting from the pivot entity, the labels of each relation associated with the pivot node have their semantic relatedness measured against the next term in the PODS representation of the query. • The query processing approach return a set of triple paths, which are a connected set fo triples defined by spreading activation search path, starting from the pivot entities over the RDF graph.
T-Space • In order to define a scalable solution, a Vector Space Model was proposed based on the Treo principles. • The elements of the Treo construction of a semantic space based on the principles behind Treo define a search/index generalization which can be applied to different problem spaces, where data is represented as labeled data graphs, including graph databases and semantic-level representations of unstructured text.
Evaluation: QALD-1 • [1]. The final approach achieved an mean reciprocal rank=0. 614, average precision=0. 487, average recall=0. 57, % of answered queries=70%.
Evaluation: QALD-1
Evaluation: queries with errors were classified according to 5 different categories. • • • [1]. PODS error, cantains errors which were determined by a difference between the structure of the PODS and data representation which led the algorithm to an incorrect search path(Q 35). [2]. Pivot Error, includes errors in the determination of the correct pivot. (Q 5, Q 27, Q 30, Q 44). Some of the dificulty in the pivot deremination process: overloading classes with complex type. (e. g. Q 30 the pivot is a class yago: Host. Cities. Of. The. Summer. Olympic. Games) [3]. Relatedness Error, include queries which were not addressed due to errors in the relatedness computation process, leading to an incorrect matching the elimination of the correct answer(Q 11, Q 12). [4]. Excessive Deferenciation Timeout Error, some queries which demanded a large number of dereferenciations to be answerd(Q 31, Q 40). [the most challenging category] [5]. Combined error in one query(Q 32, Q 39, Q 43)
Evaluation: QALD-1 • The approach was able to answer 70% of the queries. • The removal of the queries with errors that are considerd addressable in the short term(PODS Error, Privot Error, Relatedness Error) leads to precision=0. 64, recall=0. 75 and mrr=0. 81.
Treo: Summary • Key contributions: [1]. Distributional semantic relatedness matching model. [2]. Distributional model for QA. • Terminological Matching: Explicit Semantic Analysis (ESA) String similarity
g. Answer (Lei Zou et al. , 2014) QA over RDF—A Graph Data Driven Approach
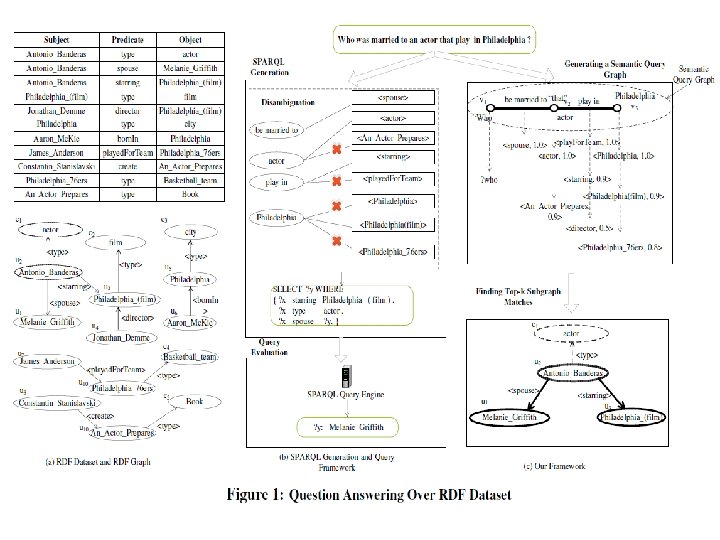
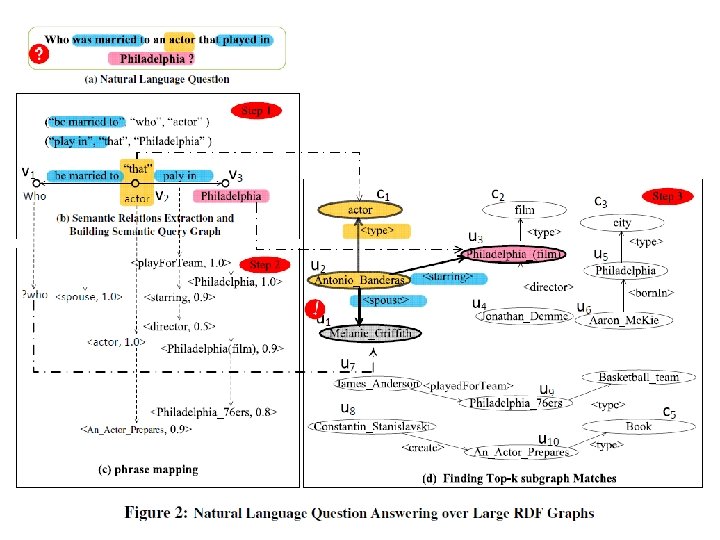
What is g. Answer • A systematic framework to answer natural language questions over RDF repository from a graph data-driven perspective. • [1]. Two-stage approach: (a). Query understanding: take a lazy approach and push down the disambiguation to the query evaluation stage; (b). Query evaluation: disambiguation process is intergrated. • [2]. A semantic query graph to model the query intention in the natural question in a structural way, based on which, RDF Q/A is reduced to subgraph matching problem. • [3]. The key problem is how to define a "match" of question N in RDF graph G and how to find matches efficiently.
Overvierw • Question understanding stage: Step 1: A natural language question N and RDF graph G; Step 2: Interpret the N as a semantic query graph Qs; [represent the user's query intention] Step 3: The phrases in edges and vertices of Qs can map to multiple semantic items (such as entities, classes and predicates) in RDF graph G. [allow the ambiguity] • Query evaluation stage: find subgraph matches of Qs over RDF G Step 4: Find the top-k subgraph matches with the larges scores. [Deal with disambiguation in query evaluation based on the matching result]
Evaluation: QALD-3 • [1]. Test: 99 questions • [2]. Efectiveness Evaluation: • [3]. Efficiency Evaluation:
Main drawback
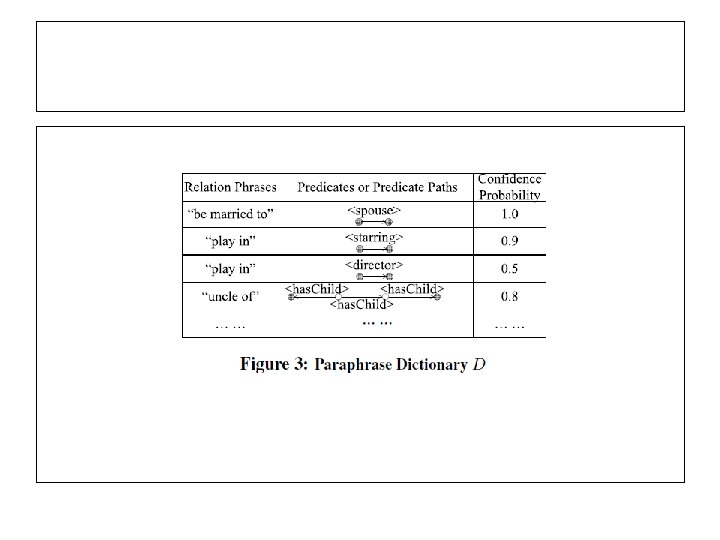
g. Answer: summary • Key contributions: [1]. QA over RDF from subgraph matching perspective. [2]. Reslove the ambiguity of natural language question at the time when matches of query are found. The cost of disambiguation is saved if there are no matching found. [3]. They propose a graph mining algorithm to map natural language phrases to top-k possible predicates (in a RDF) to form a paraphrase dictionary D. [offline] [4]. The graph data-driven framework not only improves the precision but also speeds up the whole performance of RDF Q/A system.
Case studies: summary • Powerqua: Pioneer work on the QA over linked data; Semantic simliarity mapping. • TBSL: Template-based, then instantiate. • Treo: Entity Search+Spreading Activation+Semantic Relatedness. • go. Aanser: A Graph Data Driven Approach.
Case studies: High-level Components
Challenges
Challenges [1]. The key challenge is to translate the user’s information needs into a form such that they can be evaluated using standard Semantic Web query processing. [Bridge the gap between natural languages and data] [2]. Handling meaning variations (e. g. ambiguous or vague expressions, anaphoric expressions). [3]. Mapping natural language expressions to vocabulary elements (accounting for lexical and structural differences) [Lexical gap, Lexical ambiguities, Light expressions, Complex queries, Aggregating function, comparisons, Temproal reasoning] [4]. Deal with incomplete, noisy and heterogeneous datasets. [5]. The whole performance of RDF Q/A system.
Trends
Research Topics/Opportunities • • • NLP Query anlaysis Querying distributed linked data Multilinguality Integration of structured and unstructured data Integration of reasoning (deductive, inductive, counterfactual, abductive) on QA approaches and test collections User interaction and context mechanisms: dialogue-based interaction; allow system to ask for feedback. Measuring confidence and answer uncertainty Reproducibility and resource integration in QA research: extend new datasets and questions. Performance and usability Machine Learning
References [1] Vanessa Lopez, M. Fernandez, E. Motta, N. Stieler. Power. Aqua: supporting users in querying and exploring the Semantic Web, The Semantic Web Journal -Interoperability, Usability, Applicability(2011) (http: //www. semantic-web-journal. net/) [2] Christna Unger, Bühmann, L. , Lehmann, Axel-Cyrille Ngonga Ngomo et al. : Template-based question answering over RDF data. In: Proceedings of the 21 st International Conference on World Wide Web, pp. 639– 648. ACM (2012) [3] André Freitas, João Gabriel Oliveira, Sean O'Riain, Edward Curry, João Carlos Pereira da Silva, Querying Linked Data using Semantic Relatedness: A Vocabulary Independent Approach. In Proceedings of the 16 th International Conference on Applications of Natural Language to Information Systems (NLDB), (2011) [4] Lei Zou, Ruizhe Huang, Haixun Wang, Jeffrey Xu Yu, Wenqiang He, and Dongyan Zhao. Natural langauge question answering over RDF — a graph data driven approach. In Proceedings of SIGMOD 2014, (2014) [5] Christna Unger, Freitas, A. , Cimiano P. : An Introduction to Question Answering over Linked Data. Reasoning Web. Reasoning on the Web in the Big Data Era, LNCS, pp. 100 -140 (2014) [6] Vanessa Lopez, Christna Unger, Philipp Cimiano, and Enrico Motta. Evaluation question answering over linked data. Journal of Web Semantics, in press.
Thank You