Chapter 2 ARCHITECTURES ARCHITECTURES There are different ways












")





























 terminal-dependent part of the user interface on the client")








 • Data items or nodes are")



 • Each node has an associated region • Every data item")














, nodes may offer storage")








 • A. torrent file contains the information that is needed")
 • Once the nodes have been identified from where chunks")

























- Slides: 108
Chapter 2 ARCHITECTURES
ARCHITECTURES • There are different ways on how to view the organization of a distributed system, but an obvious one is to make a distinction between the logical organization of the collection of software components and on the other hand the actual physical realization • software architectures • system architecture
Software Architectures • The organization of distributed systems is mostly about the software components that constitute the system • These software architectures tell us how the various software components are to be organized and how they should interact • logical organization software architecture
Component • A modular unit with well-defined required and provided interfaces that is replaceable within its environment, provided we respect its interfaces
Connector • It is generally described as a mechanism that mediates communication, coordination, or cooperation among components • A connector can be formed by the facilities for (remote) procedure calls, message passing, or streaming data
System Architecture • The final instantiation of a software architecture is also referred to as a system architecture • centralized architectures – one server implements the software components – remote clients can access that server • Decentralized architectures – machines more or less play equal roles, as well as hybrid organizations
The Organization of the Middleware • A middleware layer separate applications from underlying platforms • Middleware is an important architectural decision – To separate applications from underlying platforms
Feedback Control • Adaptability in distributed systems can also be achieved by having the system monitor its own behavior and taking appropriate measures when needed. • This 'insight has led to a class of what are now referred to as autonomic systems • These distributed systems are frequently organized in the form of feedback control loops • which form an important architectural element during a system's design
Contents 2. 1 ARCHITECTURAL STYLES 2. 2 SYSTEM ARCHITECTURES 2. 3 ARCHITECTURES VERSUS MIDDLEWARE 2. 4 SELF-MANAGEMENT IN DISTRIBUTED SYSTEMS • 2. 5 SUMMARY • •
2. 1 ARCHITECTURAL STYLES • Designing or adopting an architecture is crucial for the successful development of large systems • Architectural style – It is formulated in terms of components, the way that components are connected to each other, the data exchanged between components. and finally how these elements are jointly configured into a system
Architectural Styles Using components and connectors, we can come to various configurations, which, in turn have been classified into architectural styles • • Layered architectures Object-based architectures Data-centered architectures Event-based architectures
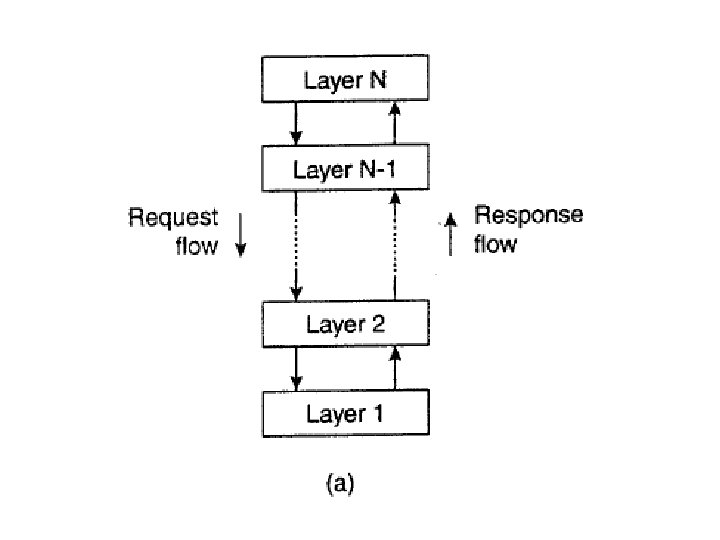
Layered architectures • Components are organized in a layered fashion where a component at layer L is allowed to call components at the underlying layer Li-1 • Control generally flows from layer to layer: requests go down the hierarchy whereas the results flow upward
Object-based Architectures • Each object corresponds a component, which are connected through a (remote) procedure call mechanism
Data-centered architectures • Evolve around the idea that processes communicate through a common (passive or active) repository
• A wealth of networked applications have been developed that rely on a shared distributed file system • Web-based distributed systems, are largely data-centric: proce-sses communicate through the use of shared Web-based data services.
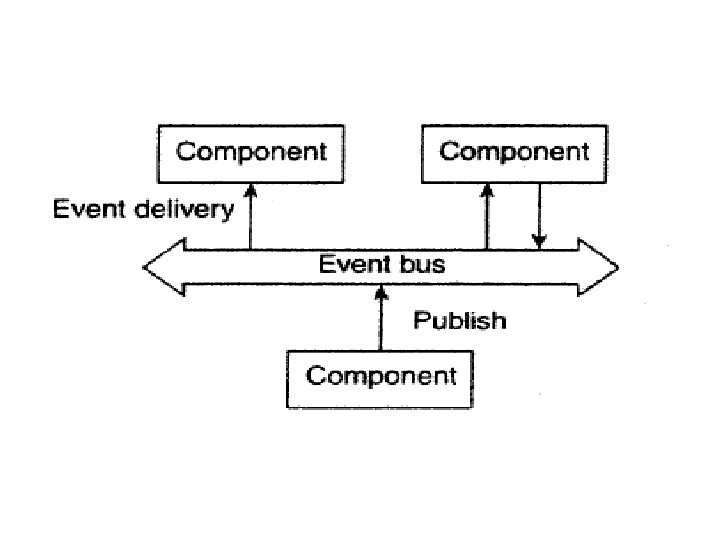
Event-based Architectures • Processes publish events, the middleware ensures that only those processes that subscribed to those events will receive them • The main advantage of event-based systems is that processes are loosely coupled ( decoupled ). In principle, they need not explicitly refer to each other
Data space • Event-based architectures can be combined with data-centered architectures, yielding what is also known as shared data spaces • Data space – processes are now also decoupled in time – data can be accessed using a description rather than an explicit reference (events)
Data space • Its aim is to reduce the effort required to set up a data integration system by relying on existing matching and mapping generation techniques, and to improve the system in "pay-as-you-go" fashion as it is used. Labor-intensive aspects of data integration are postponed until they are absolutely needed
Various architecture styles • What makes these software architectures important for distributed systems is that they all aim at achieving (at a reasonable level) distribution transparency • no single solution will meet the requirements for all possible distributed applications, researchers have abandoned the idea that a single distributed system can be used to cover 90% of all possible cases So we must consider various architecture styles
2. 2 SYSTEM ARCHITECTURES We have briefly discussed some common architectural styles, let us take a look at how many distributed systems are actually organized by considering where software components are placed Deciding on software components, their interaction, and their placement leads to an instance of a software architecture, also called a system architecture
2. 2 SYSTEM ARCHITECTURES • 2. 2. 1 Centralized Architectures • 2. 2. 2 Decentralized Architectures • 2. 2. 3 Hybrid Architectures
2. 2. 1 Centralized Architectures thinking in terms of clients that request services from servers helps us understand manage the complexity of distributed systems and that is a good thing. • Application Layering • Multitiered Architectures
General interaction between a client and a server In the basic client-server model, processes in a distributed system are divided into two (possibly overlapping) groups. A server is a process implementing a specific service. A client is a process that requests a service from a server by sending it a request and subsequently waiting for the server's reply
Connectionless • a data transmission method used in packet switching networks by which each data unit is individually addressed and routed based on information carried in each unit, rather than in the setup information of a prearranged, fixed data channel as in connection-oriented communication
Connection-oriented • a network communication mode in telecommunications and computer networking, where a communication session or a semi-permanent connection is established before any useful data can be transferred, and where a stream of data is delivered in the same order as it was sent
connectionless protocol • Network is fairly reliable • local-area networks • Process • Request , send , wait , receive, send back • Problem • Client cannot detect whether the original request message was lost, or that transmission of the reply failed • Report an error • Resend • idempotent
reliable connection-oriented protocol • reliable connection-oriented protocol – sets up a connection to the server – sending the request – Uses that same connection, to send the reply message – The connection is torn down • setting up and tearing down a connection is relatively costly, especially when the request and reply messages are sma. Il. • not entirely appropriate in a local-area network due to relatively low performance, it works perfectly time in wide-area
Distinction client and server • There is often no clear distinction • For example, a server for a distributed database may continuously act as a client because it is forwarding requests to different file servers responsible for implementing the database tables. In such a case, the database server itself essentially does no more than process queries • Method: layering
Application Layering • The user-interface level – terminal-oriented – handles interaction with a user. Client • The processing level – there are not many aspects common. client or server • The data level – operates on a database or file system. server
The user-interface level • The simplest user-interface program – nothing more than a character-based screen – used in mainframe environments – the mainframe controls all interaction • the user's terminal does some local processing – echoing typed keystrokes – supporting form-like interfaces in which a complete entry is to be edited before sending it to the main computer • Nowadays – Windows, mouse, graphics
The processing level • There are not many aspects common • Three examples – Internet search engine – A decision support system for a stock brokerage – A typical desktop package
Internet search engine
Functions for three tiers • a user types in a string of keywords and is subsequently presented with a list of titles of Web pages • The core of the search engine is a program that transforms the user's string of keywords into one or more database queries. It subsequently ranks the results into a list, and transforms that list into a series of HTML pages • A huge database of Web pages that have been prefetched and indexed
A decision support system • A front end – implementing the user interface • The processing level – the analysis programs – Analysis of financial data may require sophisticated methods and techniques from statistics and artificial intelligence. In some cases, the core of a financial decision support system may even need to be executed on highperformance computers in order to achieve throughput and responsiveness • A back end – accessing a database with the financial data
A typical desktop package • consisting of a word processor, a spreadsheet application, communication facilities, and so on • The user-interface level – a common user interface that supports compound documents – home directory is often placed on a remote file server • The processing level – a relatively large collection of programs, each having rather simple processing capabilities • The data level – operates on files from the user's home directory
The data level • Storing data – file systems – databases • keeping data consistent across different applications – metadata such as table descriptions, entry constraints and application-specific metadata are also stored at this level
An example • in the case of a bank, we may want to generate a notification when a customer's credit card debt reaches a certain value. This type of information can be maintained through a database trigger that activates a handler for that trigger at the appropriate moment
Data independence • The data are organized independent of the applications in such a way that changes in that organization do not affect applications, and neither do the applications affect the data organization • For example – In most business-oriented environments, the data level is organized as a relational database – In CAD system, data operations are more easily expressed in terms of object manipulations
2. 2. 1. 2 Mululti-tiered Architectures The distinction into three logical levels as discussed so far, suggests a number of possibilities for physically distributing a client-server application across several machines
Only two types of machines • 1. A client machine containing only the programs implementing (part of) the userinterface level • 2. A server machine containing the rest, that is the programs implementing the processing and data level
Alternative client-server organizations
Alternative client-server organizations • a) terminal-dependent part of the user interface on the client machine, and give the applications remote control over the presentation of their data • c) The front end can then check the correctness and consistency of the form • e) client's local disk contains part of the data. a client can gradually build a huge cache on local disk of most recent inspected Web pages. • thin clients
a server acting as client • a single server is being replaced by multiple servers running on different machines. • a separate process, called the transaction processing monitor, coordinates all transactions across possibly different data servers.
2. 2. 2 Decentralized Architectures • Multi-tiered client-server architectures are a direct consequence of dividing applications into a user-interface, processing components, and a data level • The different tiers correspond directly with the logical organization of applications
Vertical Distribution • Distributed processing is equivalent to organizing a client-server application as a multi-tiered architecture • achieved by placing logically different components on different machines • each machine is tailored to a specific group of functions
Horizontal Distribution • a client or server may be physically split up into logically equivalent parts, but each part is operating on its own share of the complete data set • thus balancing the load • system architectures that support horizontal distribution, known as peer-to-peer systems
peer-to-peer architectures • each process will act as a client and a server at the same time • symmetric behavior • Given this symmetric behavior, peer-to-peer architectures evolve around the how to organize the processes in an overlay network – a network in which the nodes are formed by the processes and the links represent the possible communication channels
Overlay Network • An overlay network is a computer network which is built on the top of another network • Nodes in the overlay can be thought of as being connected by virtual or logical links, each of which corresponds to a path, perhaps through many physical links, in the underlying network • For example, distributed systems such as cloud computing, peer-to-peer networks, and clientserver applications are overlay networks because their nodes run on top of the Internet • The Internet was originally built as an overlay upon the telephone network while today the telephone network is increasingly turning into an overlay network built on top of the Internet
Overlay network • An overlay network is a virtual network of nodes and logical links that is built on top of an existing network with the purpose to implement a network service that is not available in the existing network.
Structured Peer-to-Peer Architectures • In a structured peer-to-peer architecture, the overlay network is constructed using a deterministic procedure • The most-used procedure is to organize the processes through a distributed hash table (DHT).
Structured Peer-to-Peer Architectures • distributed hash table (DHT) • Data items or nodes are assigned a random key from a large identifier space, such as a 128 -bit or 160 -bit identifier • The crux: uniquely maps the key of a data item to the identifier of a node based on some distance metric • Routing – when looking up a data item, the network address of the node responsible for that data item is returned
The mapping of data items onto nodes in Chord
Lookup a data item • membership management – how nodes organize themselves into an overlay network • succ(k) – a data item with key k is mapped to the node with the smallest identifier id >= k. This node is referred to as the successor of key k and denoted as succ(k) • LOOKUP(k) – return the network address of succ(k) – lookups can generally be done in O(log (N) number of steps
A node joins or leaves the system • joining – generating a random identifier id – the node can simply do a lookup on id – insert itself in the ring • each node also stores information on its predecessor – each data item whose key is now associated with node id, is transferred from succ(id) • Leaving – node id informs its departure to its predecessor and successor – transfers its data items to succ(id)
CAN(Content Addressable Network) • Each node has an associated region • Every data item in CAN will be assigned a unique point in this space • A node is responsible for the data in its region
CAN: join or leave • node P joins – picks an arbitrary point – looks up the node Q in whose region that point falls. – Q splits, and one half is assigned to the node P. – Nodes keep track of their neighbors – the data items for which node P is from node Q. • node P leaves – a bit more problematic
Unstructured Peer-to- Peer Architectures • Unstructured peer-to-peer systems largely rely on randomized algorithms for constructing an overlay network • main idea – each node maintains a list of neighbors – this list is constructed in a more or less random way – data items are assumed to be randomly placed on nodes – when a node needs to locate a specific data item, the only thing it can effectively do is flood the network with a search query
overlay construction • One of the goals of many unstructured peer-topeer systems is to construct an overlay network that resembles a random graph. • Each node maintains a list of c neighbors • each of these neighbors represents a randomly chosen live node • a partial view of a node: a list of neighbors • nodes regularly exchange entries from their partial view • Each entry identifies another node in the network, and has an associated age that indicates how old the reference to that node is
active thread and passive thread • The active thread takes the initiative to communicate with another node. It selects that node from its current partial view. • passive thread shown in Fig. 2 -9(b), whose activities strongly resemble that of the active thread
observations • A groups of nodes may become isolated • leaving the network turns out to be a very simple operation – when a node P selects node Q, and discovers that Q no longer responds, it simply removes it
Topology Management of Overlay Networks • Although it would seem that structured and unstructured peer-to-peer systems form strict independent classes, this 'need actually not be case • One key observation is that by carefully exchanging and selecting entries from partial views, it is possible to construct and maintain specific topologies of overlay networks
A specific topologies of overlay networks
The lowest layer • The lowest layer constitutes an unstructured peer-to-peer system in which nodes periodically exchange entries of their partial views with the aim to maintain an accurate random graph. • Accuracy in this case refers to the fact that the partial view should be filled with entries referring to randomly selected live nodes
The nearest neighbors • The lowest layer passes its partial view to the higher layer • Use a ranking function, nodes are ordered according to some criterion relative to a given node • node P will gradually build up a list of its nearest neighbors, provided the lowest layer continues to pass randomly selected nodes
Generating a specific overlay network using a two-layered unstructured peer -to-peer system
Super-peers • locating relevant data items can become problematic as the network grows – there is no deterministic way of routing a lookup request to a specific data item – the only technique a node can resort to is flooding the request – There are various ways in which flooding can be dammed • There are other situations in which abandoning the symmetric nature of peer to peer systems is sensible
Super-peers • Super-peers – Nodes such as those maintaining an index or acting as a broker • Super-peers are often also organized in a peer -to-peer network, leading to a hierarchical organization • All communication from and to a regular peer proceeds through that peer's associated superpeer
An example • in a collaborative content delivery network (CDN), nodes may offer storage for hosting copies of Web pages allowing Web clients to access pages nearby, and thus to access them quickly • In this case a node P may need to seek for resources in a specific part of the network • Making use of a broker that collects resource usage for a number of nodes that are in each other's proximity will allow to quickly select a node with sufficient resources
Super-peers
Super-peers • A regular peer joins the network, it attaches to one of the superpeers • Superpeers are long-lived processes with a high availability • To compensate for potential unstable behavior of a superpeer, backup schemes can be deployed – requiring clients to attach to both • The client-superpeer relation can change as clients discover better superpeers to associate with • How to select the nodes that are eligible to become superpeer
2. 2. 3 Hybrid Architectures • Edge-Server • Collaborative Distributed Systems
Edge-Server Systems • servers are placed "at the edge" of the network • This edge is formed by the boundary between enterprise networks and the actual Internet – For example, Internet Service Provider (ISP) • end users at home connect to the Internet through their ISP • the ISP can be considered as residing at the edge of the Internet
Edge-Server Systems
Edge-Server • An edge server, in a system administration context, is any server that resides on the "edge" between two networks, typically a private network and the Internet. Edge servers can serve different purposes depending on the context of the functionality in question.
Bit. Torrent • Bit. Torrent is a peer-to-peer file downloading system • The basic idea – an end user is looking for a file, he downloads chunks of the file from other users until the downloaded chunks can be assembled together yielding the complete file.
Collaborative Distributed Systems
Collaborative Distributed Systems(cont. ) • A. torrent file contains the information that is needed to download a specific file. In particular, it refers to what is known as a tracker • tracker – a server that is keeping an accurate account of active nodes that have the requested file • Once the nodes have been identified from where chunks can be downloaded, the downloading node effectively becomes active. At that point, it will be forced to help others • Bit. Torrent combines centralized with decentralized solutions. As it turns out, the bottleneck of the system is, not surprisingly, formed by the trackers.
Collaborative Distributed Systems(cont. ) • Once the nodes have been identified from where chunks can be downloaded, the downloading node effectively becomes active. At that point, it will be forced to help others • Bit. Torrent combines centralized with decentralized solutions. the bottleneck of the system is formed by the trackers • This enforcement comes from a very simple rule – if node P notices that node Q is downloading more than it is uploading, P can decide to decrease the rate at which it sends data to Q
2. 3 ARCHITECTURES VERSUS MIDDLEWARE • where middleware fits in • middleware systems actually follow a specific architectural style – May no longer be optimal – adding new features to middlewares can easily lead to bloated middleware solutions – e. g. messaging • specific solutions of Middleware should be adaptable to application requirements – make several versions of a middleware system, where each version is tailored to a specific class of applications
2. 3. 1 Interceptors • an interceptor is a software construct that will break the usual flow of control and allow other (application specific) code to be executed.
A calls a method of B • Object A is offered a local interface that is exactly the same as the interface offered by object B. A simply calls the method available in that interface. • The call by A is transformed into a generic object invocation, made possible through a general objectinvocation interface offered by the middleware at the machine where A resides. • Finally, the generic object invocation is transformed into a message that is sent through the transportlevel network interface as offered by A's local operating system.
Using interceptors to handle remote-object invocations
object B is replicated • Now imagine that object B is replicated. In that case, each replica should actually be invoked • What the request-level interceptor will do is simply call invoke(B, &do_something, value) for each of the replicas • the object A and middleware need not be aware of the replication of B, only requestlevel interceptor
message-level interceptor • a message-level interceptor may assist in transferring the invocation to the target object • A fragmentation may improve performance or reliability. • the middleware need not be aware of this fragmentation
2. 3. 2 General Approaches to Adaptive Software • The environment in which distributed applications are executed changes continuously • Rather than making applications responsible for reacting to changes, this task is placed in the middleware. • What interceptors actually offer is a means to adapt the middleware
adaptive software • an important aspect of modern distributed systems • Has not been as successful as anticipated • three basic techniques of software adaptation – Separation of concerns – Computational reflection – Component-based design
Separating concerns • Modularizing – separate the parts that implement functionality from those that take care of other things (known as extra functionalities) such as reliability, performance, security, etc. • main problem – cannot easily separate these extra functionalities – Example: how fault tolerance can be isolated into a separate box and sold as an independent service
Computational reflection • the ability of a program to inspect itself and, if necessary, adapt its behavior • Reflection has been built into programming languages, including Java, and offers a powerful facility for runtime modifications • applying reflection to a broad domain of applications is yet to be done. reflection is the ability of a computer program to examine (see type introspection) and modify the structure and behavior (specifically the values, meta-data, properties and functions) of an object at runtime
When a reflective program operates, it does so in the same manner as a person. It takes variables, such as its own conditions, and contextual information into account. As an analogy, think of the operations involved in getting from your car to your house. If you see an obstacle in your path, you take in that information and adapt to it by either stepping around or over the object, or picking it up. When you get to your door, if you find it locked, usually you don't stop and stand there, continue to turn the knob, or turn around and walk away; usually you take out your key and unlock the door. In the same way, a reflective program has the ability to think about what is happening and to alter itself to address the circumstances
component-based design • A system may either be configured statically at design time, or dynamically at runtime • Language: DLL • Operating systems – LKM: modules can be loaded and unloaded at will • allow automatically selection of the best implementation of a component during runtime • It remains complex for distributed systems
2. 3. 3 Discussion • bulky and complex – From the transparency needs, 80 -20 • Applications’ specific extra-functional requirements conflict with transparency middleware • Goals: – Transparency – Openness – Flexibility – simplicity
2. 4 SELF-MANAGEMENT IN DISTRIBUTED SYSTEMS • reason, distributed systems should be adaptive – full distribution transparency is not what most applications actually want • autonomic computing – organizing distributed systems as high-level feedbackcontrol systems allowing automatic adaptations to changes • self-managing – self-healing, – self-configuring – self-optimizing
system architectures and software architectures • adaptation needs to be done automatically • a strong interplay between system architectures and software architectures – On the one hand, we need to organize the components of a distributed system such that monitoring and adjustments can be done – on the other hand we need to decide where the processes are to be executed that handle the adaptation
2. 4. 1 The Feedback Control Model • self-managing systems – Adaptations take place by means of one or more feedback control loops – Systems that are organized by means of such loops are referred to as feedback control systems. • The core of a feedback control system is formed by the components that need to be managed
The logical organization of a feedback control system
the feedback control loop • three elements – Measuring – Analyzes – adjustment
2. 4. 2 Systems Monitoring:Astrolabe • General tool for observing systems behavior • Orgnization of Astrolable – The lowest-level zones consist of just a single host, which are subsequently grouped into zones of increasing size. Astrolabe organizes a large collection of hosts into a hierarchy of zones. – The top-level zone covers all hosts. – Every host runs an Astrolabe process, called an agent, that collects information on the zones – The agent also communicates each other. – Each host maintains a set of attributes for collecting local information. – collect the average number of processes for the zone
Data collection and information aggregation in Astrolabe
2. 5 SUMMARY • Distributed systems can be organized in many different ways. • software architecture vs system architecture. – The latter considers where the components are placed across the various machines. – The former is more concerned about the logical organization of the software: how do components interact, what ways can they be structured, how can they be made independent, and so on
architectures • A style reflects the basic principle that is followed in organizing the interaction between the software components comprising a distributed system • Important styles – Layering – object orientation – event orientation – data-space orientation
client-server • traditional way of modularizing software • By placing different components on different machines, we obtain a natural physical distribution • Client-server architectures are often highly centralized.
peer-to-peer systems • The processes are organized into an overlay network, which is a logical network in which every process has a local list of other peers that it can communicate with. The overlay network can be structured, in which case deterministic schemes can be deployed for routing messages between processes.
self-managing distributed systems • These systems, to an extent, merge ideas from system and software architectures. Self-managing systems can be generally organized as feedback-control loops. Such loops contain a monitoring component by the behavior of the distributed system is measured, an analysis component to see whether anything needs to be adjusted, and a collection of various instruments for changing the behavior. Feedback -control loops can be integrated into distributed systems at numerous places. Much research is still needed before a common understanding how such loops such be developed and deployedis reached.