Teradata Dr Zhang Jian Senior Technical Consultant TD






 challengers leaders Teradata ability")













 Order AMP o_# c_# 7202 7415 2 1 AMP o_dt o_st o_#")


数据访问 Message Passing Layer Create USI CREATE UNIQUE INDEX (Cust) ON Customer; AMP")
 数据访问 Message Passing Layer Create NUSI AMP 1 CREATE INDEX (Name) ON")


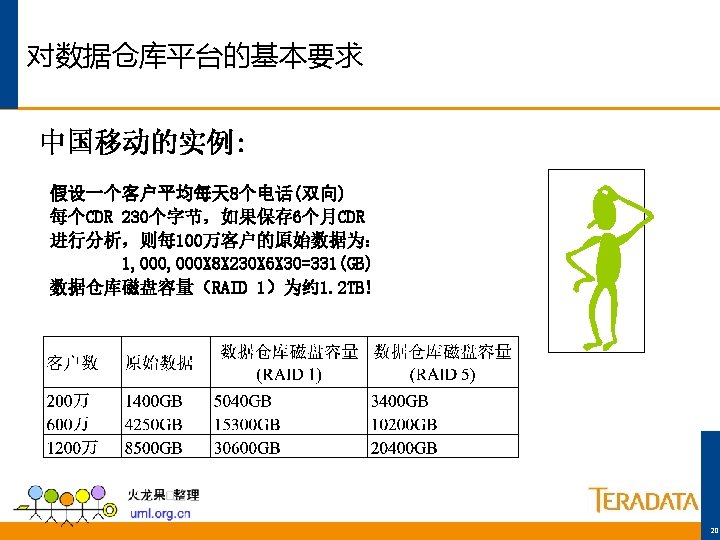
 • • • V 2 R 5的新的索引机制 在各个AMP上将数据组织为多个分区 作为Teradata的第三级数据组织和分布技术 对于分区字段上的查询,会大大的提高查询的效率")


- Slides: 42
Teradata数据仓库 Dr. Zhang Jian Senior Technical Consultant TD China
Teradata – A Brief History 1979 – – Teradata Corp founded in Los Angeles, California Development begins on a massively parallel computer 1982 – YNET technology is patented 1984 – – Teradata markets the first database computer DBC/1012 First system purchased by Wells Fargo Bank of California 1987 – First public offering of stock 1989 – Teradata and NCR partner on next generation of DBC. 1991 – NCR Corporation is acquired by AT&T; Teradata revenues at $280 million. 1992 – Teradata is merged into NCR. 1996 – AT&T spins off NCR Corp. with Teradata; Teradata Version 2 is released. 1997 – The Teradata Database becomes the industry leader in data warehousing. 2000 – The first 100+ Terabyte system is put into production. 2002 – Teradata V 2 R 5 released 12/2002; major release including features such as PPI, roles and profiles, multi-value compression, and more. 2006 – Teradata V 2 R 6. 2 is released; BYNET V 3 is available with NCR 5450/5500 systems. 2007 – NCR and Teradata become two separate corporations. Teradata 12. 0 is released in 4 th quarter. 2008 – Teradata's first full year as new corporation; 2500/5550 systems are introduced.
业界的领导企业 (Gartner Magic Quadrant for Data Warehouse Database Management Systems) challengers leaders Teradata ability to execute Oracle IBM Microsoft Sybase Netezza Greenplum My. SQL DATAllegro Kognitio Sand Technology niche players visionaries completeness of vision As of September 2007
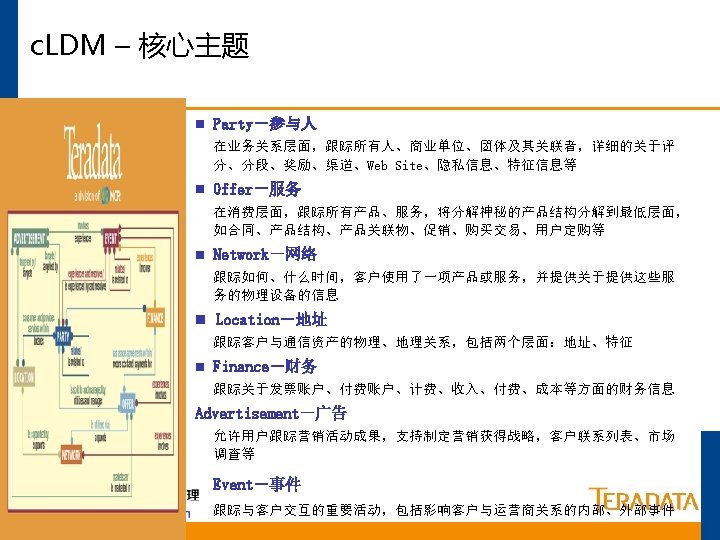
什么是数据仓库 § “A Data Warehouse is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management’s decision making process” --W. H. Inmon, 1992, Building The Data Warehouse § 四点特征 – 面向主题 – 集成的(一致性) – 时变性 – 不易失性(稳定性)
What is a Data Warehouse? A Data Warehouse is a central, enterprise-wide database that contains information extracted from Operational Data Stores (ODS). • • • Based on enterprise-wide model Can begin small but may grow large rapidly Populated by extraction/loading data from operational systems Responds to end-user “what if” queries Can store detailed as well as summary data ATM People. Soft ® Point of Service (POS) Operational Data Warehouse Teradata Database Teradata Warehouse Miner Cognos ® Micro. Strategy ® Examples of Access Tools End Users
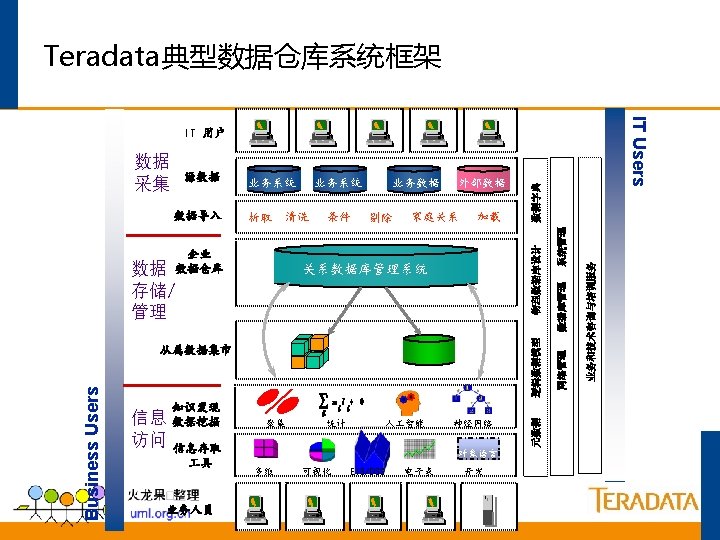
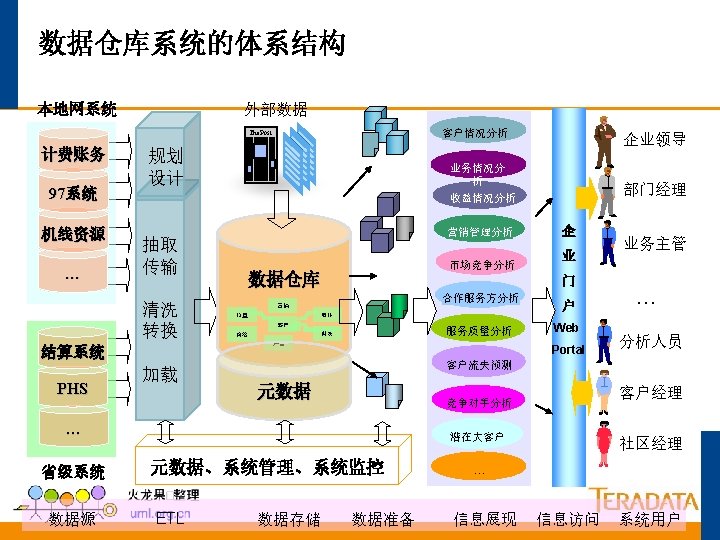
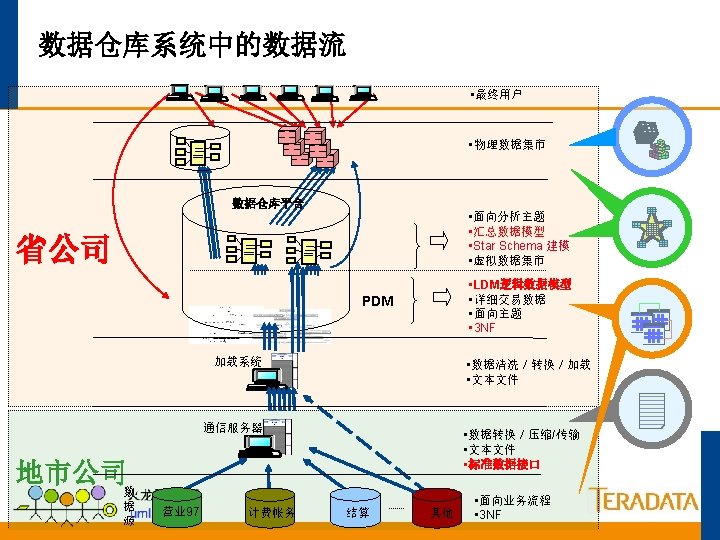
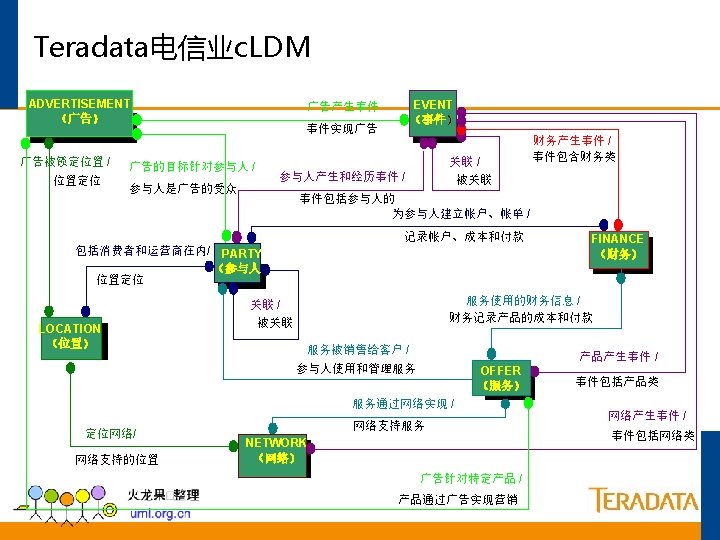
典型的数据仓库体系架构 其他业务系统 核心业务系统 NT/Oracle OS 390/DB 2 Win 2 K/UNIX Tera. Builder ETL Auto Services ETL服务器 Fload Mload Fexport TPump Access Module 管理 作站 MPP Server Teradata V 2 R 5 中央数据库 数据挖掘服务器 Win 2 K SAS Enterprise Miner SAS EM Client TD Manager DBQM MDS ETL Auto Admin ETL Auto Monitor OLAP服务器 应用服务器 WEB服务器 W 2 K IIS Brio Portal. One MS AS/ Cognos 数据挖掘 客户端 W 2 K Query. Man Brio Designer W 2 K/UNIX Brio ODS 前端展现 具 Brio BDS 胖客户端 W 2 K Browser 浏览器用户 瘦客户端
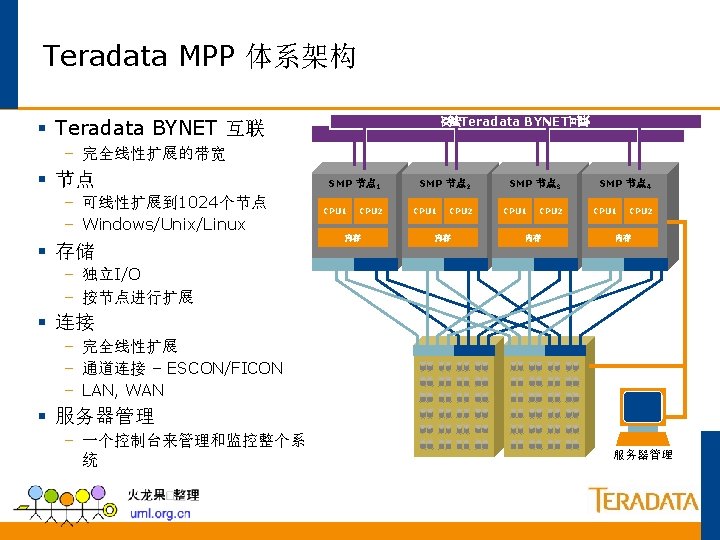
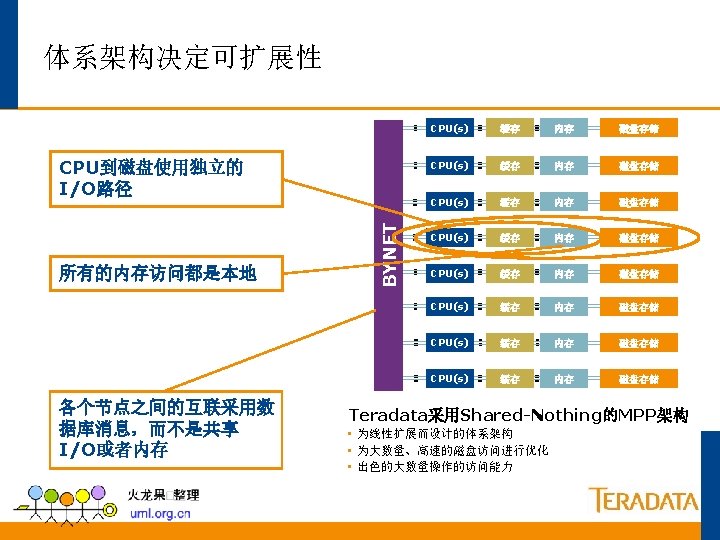
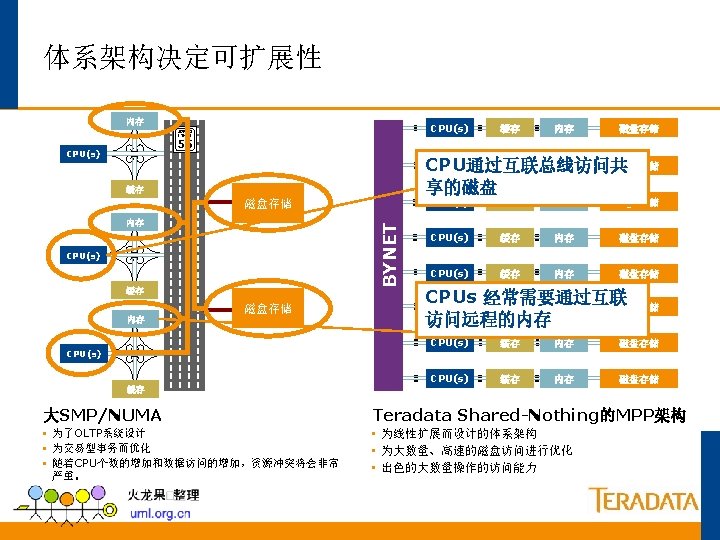
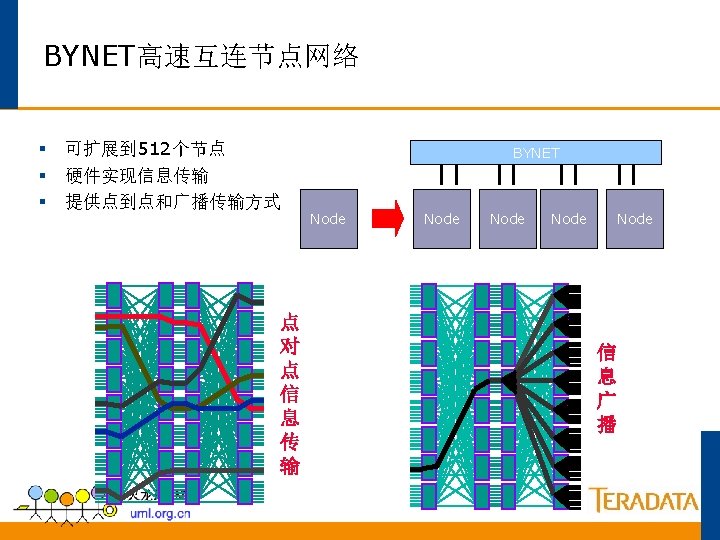
Teradata并行的基础 每 个 并 行 单 元 只 管 理 自 己 的 数 据 ET N Y B x 40 10, 000 条记录 AMP AMP 1 x 40 Reading Writing Building Indexes Loading Sorting 250, 000条记录 AMP 4的数据 Aggregating Row Locking Transaction AMP 3的数据 Journalizing AMP 2的数据 AMP 1的数据 250, 000条记录 Backup & Recovery 250, 000条记录
Teradata的并行机制 所有任务都并行执行 每个PE可以处理120个并 发连接. 每个连接可以处理同多个 查询请求. BYNET可以并行处理多种 信息. 每个AMP可以并行处理80 个任务. 所有AMP可以并行处理任 何数据库操作. PE PE PE Session A Session C Session E Session B Session D Session F BYNET AMP 1 Task 2 Task 3. 80 AMP 2 Task 1 Task 2 Task 3. 80 AMP 3 Task 1 Task 2 Task 3. 80 AMP(Access Module Processor):存取模块处理器 PE (Parsing Engine): 分解引擎 AMP 4 Task 1 Task 2 Task 3. 80
Teradata 数据库机制
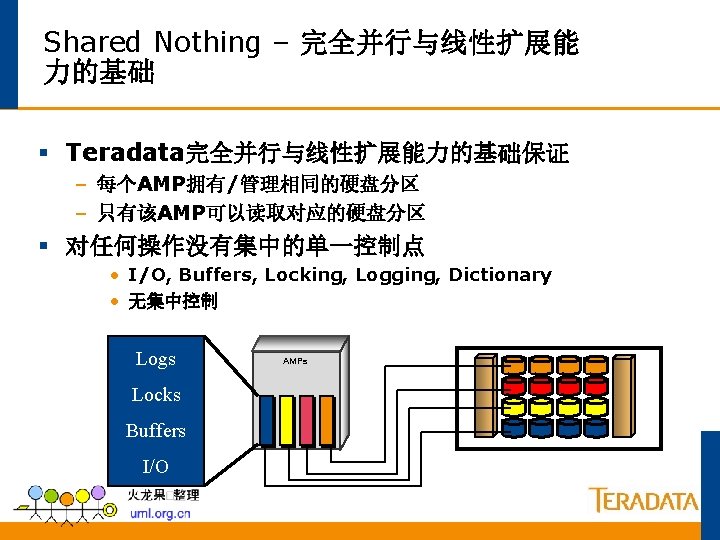
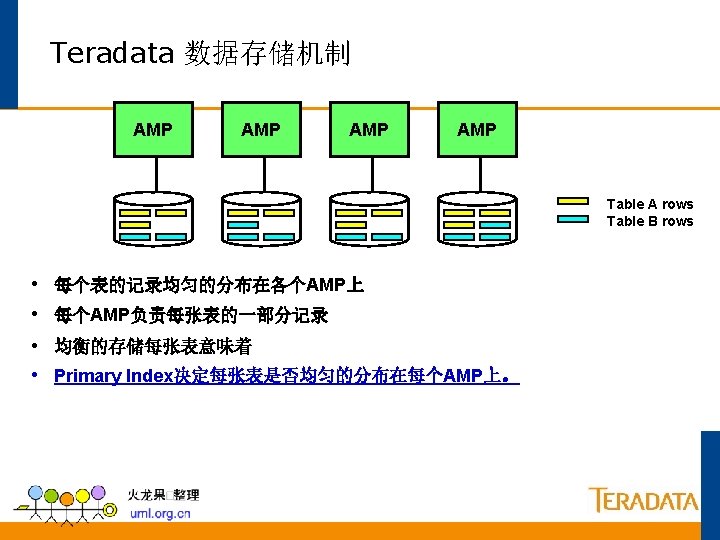
Teradata 数据存储机制 记录以随机的次序从客户端送过来 2 32 67 12 90 6 54 75 18 25 80 41 说明: Teradata Parsing Engine 分发插入数据的请求. Parsing Engine(s) Message Passing Layer 保证记录到 相应的 AMP (Access Module Processor)去. Message Passing Layer AMP 1 2 18 AMP 2 AMP 3 12 80 54 41 90 75 32 AMP 4 67 25 6 AMP 存储相应的记录到相应的行 AMP 管理一个逻辑的(虚拟的)磁盘, 这些磁盘被映射到相应的物理磁盘去。
Primary Index 主索引数据访问 UPI 访问一个AMP,读取一条记录 CREATE TABLE sample_1 (col_a INTEGER , col_b INTEGER , col_c INTEGER) UNIQUE PRIMARY INDEX (col_b); PE SELECT col_a , col_b , col_c FROM sample_1 WHERE col_b = 345; UPI = 345 Hashing Algorithm AMP col_a col_b 123 234 AMP col_c col_a col_b 345 456 AMP col_c col_a col_b 567 678 col_c
数据分布 (UPI) Order AMP o_# c_# 7202 7415 2 1 AMP o_dt o_st o_# c_# 4/09 4/13 7325 7103 7402 2 1 3 C C AMP o_dt o_st o_# c_# 4/13 4/10 4/16 7188 7225 1 2 O O C AMP o_dt o_st o_# c_# 4/13 4/15 7324 7384 3 1 C C o_dt o_st 4/13 4/12 O C
多张表在多个AMP上的分布 EMPLOYEE Table DEPARTMENT Table JOB Table 说明: 每个AMP上都可以找到每个表的的 一部分记录 Parsing Engine 理想情况下,每个AMP保存基本相 等的记录条数 Message Passing Layer AMP #1 AMP #2 EMPLOYEE Rows DEPARTMENT Rows JOB Rows AMP #3 EMPLOYEE Rows DEPARTMENT Rows JOB Rows AMP #4 EMPLOYEE Rows DEPARTMENT Rows JOB Rows
线性增长和可扩展性 Parsing Engine • Teradata 线性增长的RDBMS. • 组件可以依照需要来增加. NS SESSIO AMP • 线性增长保证了在负载增加的时 AMP Notes: 候性能并不降低。 G ESSIN ROC LLEL P PARA Disk DATA USERS Same Double Same AMPs Same Double DATA Same Double Same Performance Same Double
次索引 (USI)数据访问 Message Passing Layer Create USI CREATE UNIQUE INDEX (Cust) ON Customer; AMP 1 AMP 2 USI Subtable Access via USI Row. ID 244, 1 505, 1 744, 4 757, 1 SELECT * FROM Customer WHERE Cust = 56; Cust 74 77 51 27 Row. ID 884, 1 639, 1 915, 9 388, 1 USI Subtable Row. ID 135, 1 296, 1 602, 1 969, 1 Cust 98 84 56 49 Table ID PE AMP 3 AMP 1 100 Cust 31 40 45 95 Row. ID 638, 1 640, 1 471, 1 778, 3 778 to MPL 56 Cust 37 72 12 62 Row. ID 107, 1 717, 2 147, 2 822, 1 7 AMP 3 Base Table AMP 4 Base Table Row Hash USI Value 602 Row. ID 175, 1 489, 1 838, 4 919, 1 Row Hash Unique Val AMP 2 Base Table ID Row. ID 288, 1 339, 1 372, 2 588, 1 USI Subtable Message Passing Layer USI Value = 56 Hashing Algorithm USI Subtable Row. ID 555, 6 536, 5 778, 7 147, 1 100 Customer Table ID = 100 AMP 4 Row. ID Cust Name USI 107, 1 37 White 536, 5 84 Rice 638, 1 31 Adams 640, 1 40 Smith Phone NUPI 555 -4444 666 -5555 111 -2222 222 -3333 Row. ID Cust Name USI 471, 1 45 Adams 555, 6 98 Brown 717, 2 72 Adams 884, 1 74 Smith Phone NUPI 444 -6666 333 -9999 666 -7777 555 -6666 Row. ID Cust Name USI 147, 1 49 Smith 147, 2 12 Young 388, 1 27 Jones 822, 1 62 Black Phone NUPI 111 -6666 777 -4444 222 -8888 444 -5555 Base Table Row. ID Cust Name USI 639, 1 77 Jones 778, 3 95 Peters 778, 7 56 Smith 915, 9 51 Marsh Phone NUPI 777 -6666 555 -7777 888 -2222
非唯一次索引 (NUSI) 数据访问 Message Passing Layer Create NUSI AMP 1 CREATE INDEX (Name) ON Customer; AMP 2 NUSI Subtable Access via NUSI SELECT * FROM Customer WHERE Name = 'Adams'; Row. ID 432, 8 448, 1 567, 3 656, 1 Name Smith White Adams Rice Row. ID 640, 1 107, 1 638, 1 536, 5 AMP 3 NUSI Subtable Row. ID Name 432, 3 Smith 567, 2 Adams 852, 1 Brown Row. ID 884, 1 471, 1 717, 2 555, 6 AMP 4 NUSI Subtable Row. ID 432, 1 448, 4 567, 6 770, 1 Name Smith Black Jones Young Row. ID 147, 1 822, 1 338, 1 147, 2 NUSI Subtable Row. ID 155, 1 396, 1 432, 5 567, 1 Name Marsh Peters Smith Jones Row. ID 915, 9 778, 3 778, 7 639, 1 PE Customer NUSI Value = 'Adams' Table ID = 100 Hashing Algorithm Table ID 100 to MPL AMP 2 Base Table Row Hash NUSI Value 567 AMP 1 Adams Row. ID Cust Name NUSI 107, 1 37 White 536, 5 84 Rice 638, 1 31 Adams 640, 1 40 Smith Phone NUPI 555 -4444 666 -5555 111 -2222 222 -3333 AMP 3 Base Table Row. ID Cust Name NUSI 471, 1 45 Adams 555, 6 98 Brown 717, 2 72 Adams 884, 1 74 Smith Phone NUPI 444 -6666 333 -9999 666 -7777 555 -6666 AMP 4 Base Table Row. ID Cust Name NUSI 147, 1 49 Smith 147, 2 12 Young 388, 1 27 Jones 822, 1 62 Black Phone NUPI 111 -6666 777 -4444 222 -8888 444 -5555 Base Table Row. ID Cust Name NUSI 639, 1 77 Jones 778, 3 95 Peters 778, 7 56 Smith 915, 9 51 Marsh Phone NUPI 777 -6666 555 -7777 888 -2222
每种访问技术的比较 One AMP Operation Primary Index Value Hashing Algorithm Two AMP Operation Unique Secondary Index Value Hashing Algorithm Base Table USI Subtable Base Table All AMP Operation Non-Unique Secondary Index Value Hashing Algorithm NUSI Subtable Base Table
无索引技术的数据访问 全表扫描 并行的读取每个AMP上的数据 全表扫描出现在下列情况下: Customer Cust_ID USI Cust_Name Cust_Phone NUPI SELECT * FROM Customer WHERE Cust_Phone LIKE '524 -_ _ _ _'; SELECT * FROM Customer WHERE Cust_Name = 'Davis'; SELECT * FROM Customer WHERE Cust_ID > 1000;
分区索引Partitioned Primary Indexes (PPI) • • • V 2 R 5的新的索引机制 在各个AMP上将数据组织为多个分区 作为Teradata的第三级数据组织和分布技术 对于分区字段上的查询,会大大的提高查询的效率 避免了全表扫描 CREATE SET TABLE Employee (Order_Number INTEGER , O_Date …) PRIMARY INDEX (Order_Number) PARTITION BY O_Date ;
PPI的例子 4 AMPs 无PPI 4 AMPs,在O_Date上 定义了 PPI SELECT … WHERE O_Date BETWEEN '2002 -11 -01' AND '2002 -11 -30'; RH O_# O_Date RH O_# '01' 1028 02/11 '06' 1009 02/09 '04' '03' 1016 02/10 '07' 1017 02/10 '12' 1031 02/11 '10' 1034 '14' 1001 02/09 '13' '17' 1013 02/10 '23' 1040 '28' 1008 02/09 '02' 1024 02/10 '05' 1048 02/12 '08' 1006 02/09 02/11 '09' 1018 02/10 '11' 1019 02/10 1037 02/12 '15' 1042 02/12 '18' 1041 02/12 '16' 1021 02/10 '19' 1025 02/11 '20' 1005 02/09 02/12 '21' 1045 02/12 '24' 1004 02/09 '22' 1020 02/10 1032 02/11 '26' 1002 02/09 '27' 1014 02/10 '25' 1036 02/11 '30' 1038 02/12 '29' 1033 02/11 '32' 1003 02/09 '31' 1026 02/11 '35' 1007 02/09 '34' 1029 02/11 '33' 1039 02/12 '38' 1046 02/12 '39' 1011 02/09 '36' 1012 02/09 '40' 1035 02/11 '41' 1044 02/12 '42' 1047 02/12 '36' 1043 02/12 '44' 1022 02/10 '43' 1010 02/09 '48' 1023 02/10 '45' 1015 02/10 '47' 1027 02/11 '46' 1030 02/11 RH O_# O_Date '14' 1001 02/09 '06' 1009 02/09 '04' 1008 02/09 '08' 1006 02/09 '35' 1007 02/09 '26' 1002 02/09 '24' 1004 02/09 '20' 1005 02/09 '39' 1011 02/09 '36' 1012 02/09 '32' 1003 02/09 '43' 1010 02/09 '03' 1016 02/10 '07' 1017 02/10 '09' 1018 02/10 '02' 1024 02/10 '17' 1013 02/10 '16' 1021 02/10 '27' 1014 02/10 '11' 1019 02/10 '48' 1023 02/10 '45' 1015 02/10 '44' 1022 02/10 '22' 1020 02/10 '01' 1028 02/11 '10' 1034 02/11 '19' 1025 02/11 '25' 1036 02/11 '12' 1031 02/11 '29' 1033 02/11 '40' 1035 02/11 '31' 1026 02/11 '28' 1032 02/11 '34' 1029 02/11 '47' 1027 02/11 '46' 1030 02/11 '23' 1040 02/12 '13' 1037 02/12 '05' 1048 02/12 '18' 1041 02/12 '30' 1038 02/12 '21' 1045 02/12 '15' 1042 02/12 '38' 1046 02/12 '42' 1047 02/12 '36' 1043 02/12 '33' 1039 02/12 '41' 1044 02/12 O_Date