Reproducible computational social science Allen Lee Center for

Reproducible computational social science Allen Lee Center for Behavior, Institutions, and the Environment https: //cbie. asu. edu

Computational Social Science • Wicked collective action problems • Innovation -> Problems -> Innovation • Mitigate transaction costs for information transfer

Methodologies • Case study analysis • Controlled experiments • Computational modeling • Integrative data analysis / natural experiments

Case Study Analysis • seshatdatabank. info “Our goal is to test rival social scientific hypotheses with historical and archaeological data … treating history as a predictive, analytic science. ”

SES Library • Descriptions of social ecological systems from around the world • Embeds mathematical models relating to specific cases where relevant to specific social-ecological dynamics via xppaut

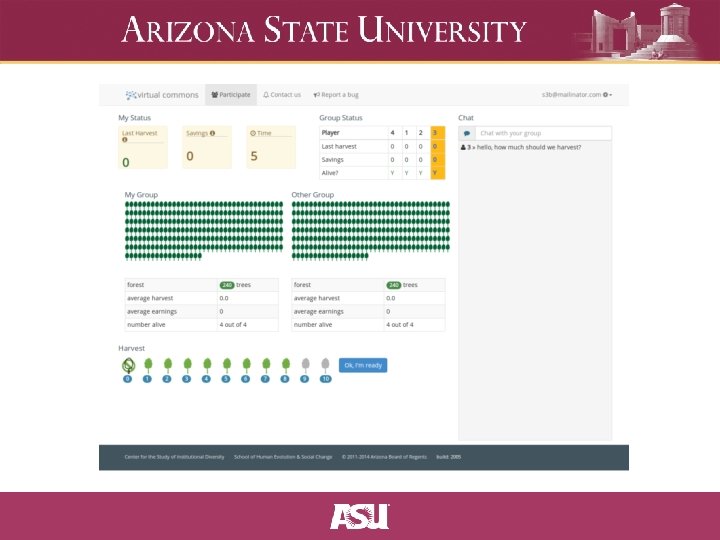
Controlled Behavioral Experiments • Web-based experiments: Mechanical Turk, o. Tree, node. Game, vcweb • Desktop experiments: z. Tree, Co. NG, foraging, irrigation • Diversity in software platforms is valuable but also presents challenges • General issues summarized in Experimental platforms for behavioral experiments on social-ecological systems (Janssen, Lee, Waring, 2014)


Computational Modeling • • Extrapolate potential future scenarios for complex systems with many interacting actors Computational modeling makes the processes underlying complex phemonema explicit, sharable, & reproducible. Assumptions are laid bare, and alternative assumptions / parameterizations can be explored via sensitivity analysis George Box – “All models are wrong, but some are useful”

Multiple methods • Convergent validity • Multiple methods complement each other, e. g. , experiments, case study analysis, formal modeling (Poteete, et al. , 2010)

Reproducibility • Victoria Stodden: how do we know inference is reliable, and why should we believe "Big Data" findings? • Need new standards for conducting “Data and Computational Science” and communicating results: sound workflows, sharing specifications, guides to good practice • Distinguishing between empirical, statistical, and computational reproducibility

Replicable Research Workflows • Planning, organizing, and documenting your research protocols • Developing code for data analysis or experiments • Running your analyses (generating visualizations) or conducting experiments (generating data) • Presenting / publishing findings • Cleaning and documenting your code and data • Archival and documentation with contextual metadata that preserves provenance • https: //osf. io is a good example of a full-stack system
 Current Biology DOI: 10. 1016/j. cub. 2013.")
Archiving data Vines TH et al. (2013) Current Biology DOI: 10. 1016/j. cub. 2013. 11. 014

Co. MSES Net • Computational Model Library for archiving model code, next generation in active development and planning stages • Provide suite of microservices for transparency and reproducibility in computational modeling

The MIRACLE project: Cyberinfrastructure for visualizing model outputs Dawn Parker, Michael Barton, Terence Dawson, Tatiana Filatova, Xiongbing Jin, Allen Lee, Ju-Sung Lee, Lorenzo Milazzo, Calvin Pritchard, J. Gary Polhill, Kirsten Robinson, and Alexey Voinov

Background and motivation • Growing interest in analyzing highly detailed “big data” • Concurrent development of a new generation of simulation models including ABMS, which themselves produce “big data” as outputs • Need for tools and methods to analyze and compare these two data sources

Motivation • Sharing model code is great—but there are large barriers to entry to getting someone else’s model running (Collberg, et al 2015) • Sharing model output data can accomplish many of the goals of code sharing • It also lets other researcher explore new parameter spaces, or use different algorithms • Sharing of analysis algorithms may jump start development of complex-systems specific output analysis methods

Objectives • Collect, extend, and share methods for statistical analysis and visualization of output from computational agent-based models of coupled human and natural systems (ABM-CHANS). • Provide interactive visualization and analysis of archived model output data for ABM-CHANS models

Objectives, cont. • Conduct meta-analyses of our own projects, and invite the ABM-CHANS community to conduct further metaanalyses using the new tools. • Apply the statistical analysis algorithms we develop to empirical datasets to validate their applicability to large scale data from complex social systems.

Metadata for ABM output data • Goals – User needs to understand the data (what’s inside the files, what are the relationships between the files, project and owners…) – User needs to know how the data were generated (input data, analysis scripts, parameters, computer environment, workflows that chain several scripts…) • Two types of metadata – Metadata that describe the current state of data (data structure, file and data table content Fine Grain Metadata) – Metadata that describe the provenance of data (how the data were generated Coarse Grain Metadata)

Capturing metadata • Goal: Automated metadata extraction with minimum user input • Fine grain metadata – Automatically extracting metadata from files (CSV columns, Arc. GIS Shapefile metadata and attribute table columns, etc. ) • Coarse grain metadata – Workflow describes how a script could produce a certain file type, while provenance describes how script A produces file B – Provenance can be automatically captured when user runs scripts and workflows using the MIRACLE system (computer environment, user name, application name, process, input files and parameters, output files. ) – Workflows can be constructed based on captured provenance

MIRACLE platform use cases • Within a research group: – Efficiently share and discuss new model results – Let group member explore new parameter spaces – Create accessible archives for publications • Across groups: – Provide prototypes to new researchers, or those looking for new analysis methods – Provide examples for teaching and labs – Facilitate additional “after-market” research and publication

MIRACLE project goals • Develop, share, test, and compare new statistical methods appropriate for analysis of complex systems data; • Improve communication and assessment within the modeling community; • Reduce barriers to entry for use of models; • Improve the ability of policy makers and stakeholders to understand interact with model output

Co. MSES Net: Catalog • Track the state of archival • Provide collectiveaction tools to incentivize model sharing

Co. MSES Net: Catalog

Co. MSES Net Future Goals • Provide one-stop shop for computational modeling • containerized execution with bundled dependencies • integration with Jupyter and Cy. Verse and modeling platforms like Re. Past, Net. Logo • Reparameterizable data analysis and exploration via the Miracle project • Bibliometric tracking • Collective action tools to incentivize prosocial behavior among scientists

From http: //stanford. edu/~vcs/talks/UIUCData. Summit-Feb 5 -2016 -STODDEN. pdf

Guide to good practice • Learn to use a source control system (git, mercurial, SVN) • Use it with discipline: – commit early, commit often – write meaningful log messages – create tags and releases at important checkpoints during the research process • List versioned dependencies (e. g. , packrat, Maven/gradle, pip)

Guide to good practice • Plan for reproducibility • Use version control efficiently • Archive everything – data, code, and contextual / provenance metadata • Prefer open, durable, formats (plaintext, CSV, open file formats) • Use cloud backups • Automate where possible • Learn the basics of “software carpentry”

Guides to good practice

Computational Social Science

Comments / Questions?
- Slides: 33