Lecture on High Performance Processor Architecture CS 05162
 Review of Memory Hierarchy An Hong")

 1000 Moore’s Law 100")


: CPU访问存储系统时, 在高层找到所需的信息 (e. g. : Block X) − Hit")
 − So high that usually talk about Miss rate")






: the information is")


 more than 30 years ago in the IBM")




 1 st session on caches 2021/9/25 USTC")





")



")





 is a cache of")








- Slides: 50
Lecture on High Performance Processor Architecture (CS 05162) Review of Memory Hierarchy An Hong han@ustc. edu. cn Fall 2009 School of Computer Science and Technology University of Science and Technology of China 2021/9/25 USTC CS AN Hong 1
Quick review of everything you should have learned 2021/9/25 USTC CS AN Hong 2
Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap (latency) 1000 Moore’s Law 100 10 1 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 Performance Proc 60%/yr. (2 X/1. 5 yr) Processor-Memory Performance Gap: (grows 50% / year) DRAM 9%/yr. (2 X/10 yrs) CPU 2021/9/25 Time USTC CS AN Hong 3
Levels of the Memory Hierarchy Upper Level Capacity Access Time Cost Staging Xfer Unit CPU Registers 100 s Bytes <10 s ns Registers Cache K Bytes 10 -100 ns 1 -0. 1 cents/bit Cache Instr. Operands Blocks Main Memory M Bytes 200 ns- 500 ns $. 0001 -. 00001 cents /bit Disk G Bytes, 10 ms (10, 000 ns) -5 -6 10 - 10 cents/bit Tape T Bytesor infinite sec-min 10 -8 cents/bit 2021/9/25 faster prog. /compiler 1 -8 bytes cache cntl 8 -128 bytes Memory Pages OS 512 -4 K bytes Files user/operator Mbytes Disk Tape USTC CS AN Hong Larger Lower Level 4
The Principle of Locality n The Principle of Locality: − Program access a relatively small portion of the address space at any instant of time. n Two Different Types of Locality: − Temporal Locality (Locality in Time): If an item is referenced, it will tend to be referenced again soon (e. g. , loops, reuse) − Spatial Locality (Locality in Space): If an item is referenced, items whose addresses are close by tend to be referenced soon (e. g. , straightline code, array access) n Last 20 years, HW relied on locality for speed and cost It is a property of programs which is exploited in machine design. 2021/9/25 USTC CS AN Hong 5
Memory Hierarchy: Terminology n Hit(命中): CPU访问存储系统时, 在高层找到所需的信息 (e. g. : Block X) − Hit Rate(命中率): CPU访问存储系统时, 在高层找到所需信息的概率 − Hit Time(命中时间): 在高层命中时的访问时间 RAM access time + Time to determine hit/miss n Miss(缺失): CPU访问存储系统时, 所需的信息 (e. g. : Block Y)需要从低层 传送到高层 − Miss Rate(缺失率) = 1 - (Hit Rate) − Miss Penalty(缺失开销): 在低层存储中找到一个信息块所需的时间 + 向高层传送一个信息块所需的时间 n Hit Time << Miss Penalty To Processor Upper Level Memory Lower Level Memory Blk X From Processor 2021/9/25 Blk Y USTC CS AN Hong 6
Cache Measures n Hit rate(命中率) − So high that usually talk about Miss rate − Miss rate fallacy: as MIPS to CPU performance, miss rate to average memory access time in memory n Miss penalty(缺失开销): time to replace a block from lower level, including time to replace in CPU − access time: 在低层存储中找到一个信息块所需的时间 = f(latency to access lower level) − transfer time: 向高层传送一个信息块所需的时间 =f(BW between upper & lower levels) n Average memory-access time(平均访问时间) = Hit time + Miss rate x Miss penalty (ns or clocks) 2021/9/25 USTC CS AN Hong 7
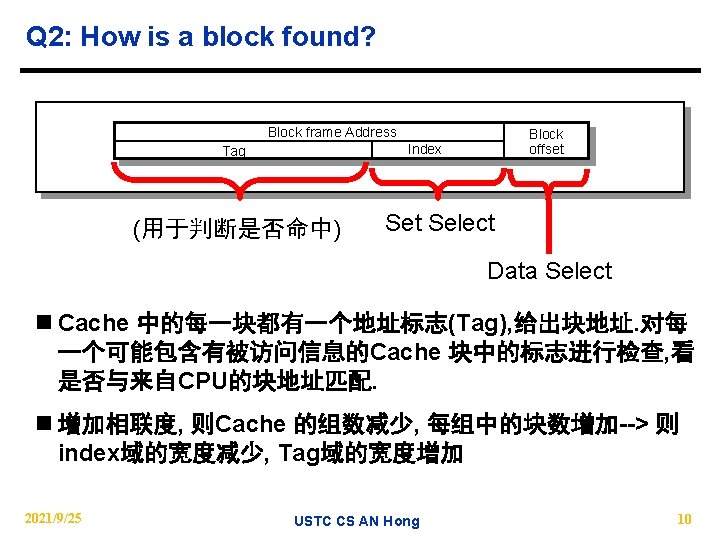
Four Questions for Memory Hierarchy Designers n Q 1: Where can a block be placed in the upper level? 块 的放置(Block placement) − Fully Associative, Set Associative, Direct Mapped n Q 2: How is a block found if it is in the upper level? 块的定位(Block identification) − Tag/Block n Q 3: Which block should be replaced on a miss? 块的替换(Block replacement) − Random, LRU n Q 4: What happens on a write? 写策略(Write strategy) − Write Through (with Write Buffer)(直写) or Write Back(回写) 2021/9/25 USTC CS AN Hong 8
Q 1: Where can a block be placed? n. Block 12 placed in 8 block cache: − Fully associative, direct mapped, 2 -way set associative − S. A. Mapping = Block Number Modulo Number Sets Direct mapped: block 12 can go only into block 4 (12 mod 8) Fully associative: block 12 can go anywhere Block no. 01234567 Set associative: block 12 can go anywhere in set 0 (12 mod 4) Block no. Set Set 0 1 2 3 Block-frame address Block no. 2021/9/25 01234567 111112222233 0123456789012345678901 USTC CS AN Hong 9
1 KB Direct Mapped Cache, 32 B blocks n For a 2 N byte cache: − The uppermost (32 - N) bits are always the Cache Tag − The lowest M bits are the Byte Select (Block Size = 2 31 Example: 0 x 50 ② Cache Tag Cache Data Byte 31 Byte 63 : : Valid Bit 0 x 50 : ① ③ Byte 1 Byte 0 0 Byte 33 Byte 32 1 2 3 : : Byte 1023 2021/9/25 ) 4 0 Byte Select Ex: 0 x 00 USTC CS AN Hong : Cache Tag 9 Cache Index Ex: 0 x 01 M Byte 992 31 11
Two-way Set Associative Cache n N-way set associative: N entries for each Cache Index − N direct mapped caches operates in parallel (N typically 2 to 4) n Example: Two-way set associative cache − Cache Index selects a set? from the cache − The two tags in the set are compared in parallel − Data is selected based on the tag result Valid Cache Tag : : Adr Tag Cache Index Cache Data Cache Block 0 ① : ② Compare ③ Sel 1 1 : ③ Mux 0 Sel 0 Cache Tag Valid : : ② Compare OR 2021/9/25 Hit Cache Block USTC CS AN Hong 12
N-way Set Associative Cache v. Direct Mapped Cache n 相联度越高, Cache空间的利用率就越高, 块冲突的概率越低, Cache 的缺 失率也就越低. 全相联的缺失率最低, 直接映射的缺失率最高 n 相联度越高, Cache 实现的复杂度和访问延迟就越大 n 大多数的处理器采用直接映射, 两路组相联, 或四路组相联 Valid Cache Tag : : Adr Tag Compare Cache Index Cache Data Cache Block 0 : : Sel 1 1 Mux 0 Sel 0 Cache Tag Valid : : Compare OR Hit 2021/9/25 Cache Block USTC CS AN Hong 13
Q 3: Which block should be replaced on a miss? n Easy for Direct Mapped n Set Associative or Fully Associative: − Random − LRU (Least Recently Used) Associativity: 2 -way 4 -way 8 -way Size LRU Random 16 KB 5. 2% 5. 7% 4. 7% 5. 3% 4. 4% 5. 0% 64 KB 1. 9% 2. 0% 1. 5% 1. 7% 1. 4% 1. 5% 256 KB 1. 15% 1. 17% 1. 13% 1. 12% 2021/9/25 USTC CS AN Hong 14
Q 4: What happens on a write? n Write through(WT, 直写): the information is written to both the block in the cache and to the block in the lowerlevel memory. − WT always combined with write buffers so that don’t wait for lower level memory n Write back(WB, 后写): the information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced. − is block clean or dirty? 2021/9/25 USTC CS AN Hong 15
Write Buffer for Write Through Processor Cache DRAM Write Buffer n A Write Buffer is needed between the Cache and Memory − Processor: writes data into the cache and the write buffer − Memory controller: write contents of the buffer to memory n Write buffer is just a FIFO: − Typical number of entries: 4 − Works fine if: Store frequency (w. r. t. time) << 1 / DRAM write cycle n Memory system designer’s nightmare: − Store frequency (w. r. t. time) -> 1 / DRAM write cycle − Write buffer saturation 2021/9/25 USTC CS AN Hong 16
Cache history n Caches introduced (commercially) more than 30 years ago in the IBM 360/85 − already a processor-memory gap n Oblivious to the ISA − caches were organization, not architecture n Many different organizations − direct-mapped, set-associative, skewed-associative, sector, decoupled sector etc. n Caches are ubiquitous − On-chip, off-chip − But also, disk caches, web caches, trace caches etc. n Multilevel cache hierarchy − With inclusion or exclusion − 4+ level 2021/9/25 USTC CS AN Hong 18
Cache history n Cache exposed to the ISA − Prefetch, Fence, Purge etc. n Cache exposed to the compiler − Code and data placement n Cache exposed to the O. S. − Page coloring n Many different write policies − copy-back, write-through, fetch-on-write, write-around, writeallocate etc. 2021/9/25 USTC CS AN Hong 19
Cache history n Numerous cache assists, for example: − For storage: write-buffers, victim caches, temporal/spatial caches − For overlap: lock-up free caches − For latency reduction: prefetch − For better cache utilization: bypass mechanisms, dynamic line sizes − etc. . . 2021/9/25 USTC CS AN Hong 20
Caches and Parallelism n Cache coherence − Directory schemes − Snoopy protocols n Synchronization − Test-and-test-and-set − load linked -- store conditional n Models of memory consistency − TCC, Log. TM 2021/9/25 USTC CS AN Hong 21
When were the 2 K papers being written? n A few facts: − 1980 textbook: < 10 pages on caches (2%) − 1996 textbook: > 120 pages on caches (20%) n Smith survey (1982) − About 40 references on caches n Uhlig and Mudge survey on trace-driven simulation (1997) − About 25 references specific to cache performance only − Many more on tools for performance etc. 2021/9/25 USTC CS AN Hong 22
Cache research vs. time Largest number (14) 1 st session on caches 2021/9/25 USTC CS AN Hong 23
Present Latency Solutions and Limitations Solution Larger Caches § Slow § Works well only if working set fits cache and there is temporal locality Hardware Prefetching § Cannot be tailored for each application § Behavior based on past and present execution-time behavior Software Prefetching § Ensure overheads of prefetching do not outweigh the benefits> conservative prefetching § Adaptive software prefetching is required to change prefetch distance during run-time § Hard to insert prefetches for irregular access patterns Multithreading 2021/9/25 § focus on solving the throughput problem, not the memory latency problem USTC CS AN Hong 24
The Memory Bandwidth Problem n It’s expensive! n Often ignored n Processor-centric optimization to bridge the gap but lead to memory-bandwidth problems − Prefetching − Speculation − Multithreading hide latency Can we always just trade bandwidth for latency? 2021/9/25 USTC CS AN Hong 25
Present Bandwidth Solutions n Wider/faster connections to memory − Rambus DRAM − Use higher signaling rates on existing pins − Use more pins for the memory interface n Larger on-chip caches − Fewer requests to DRAM − Only effective if larger caches improve hit rate n Traffic-efficient requests − Only request what you need − Caches are “guessing” that you might need adjacent data − Compression? 2021/9/25 USTC CS AN Hong 26
Present Bandwidth Solutions n More efficient on-chip caches − Only 1/20 – 1/3 of the data in a cache is live − Again, caches are “guessing” what will be used again − Spatial vs. temporal vs. no locality n Logic/DRAM integration − Put the memory on the processor − On-chip bandwidth is cheaper than pin bandwidth − You will still probably have external DRAM as well n Memory-centric architectures − “Smart” memory (PIM) − Put processing elements wherever there is memory 2021/9/25 USTC CS AN Hong 27
评测存储系统性能的指标 A. M. A. T : Average Memory Access time IC: Instruction Count CCT: Clock cycle time (1) 平均访存时间 A. M. A. T= (Hit Rate x Hit Time) +(Miss Rate x Miss Time ) = (Hit Rate x Hit Time) +(1–Hit Rate ) x (Hit Time + Miss Penalty) = Hit Time + (Miss Rate x Miss Penalty) (2) CPU性能公式(带存储器层次结构的CPU性能公式) 复习: 不考虑访存造成的CPU暂停周期时的CPU性能公式 CPU时间 = 执行一个程序所需的时钟周期数× 时钟周期 = IC ×CPI × Clock Cycle time 2021/9/25 USTC CS AN Hong 28
评测存储系统性能的指标 第一种扩展形式: CPU time = (CPU execution clock cycles + Memory stall clock cycles) x CCT Memory stall clock cycles = (Reads x Read miss rate x Read miss penalty + Writes x Write miss rate x Write miss penalty) = Memory accesses x Miss rate x Miss penalty 第二种扩展形式: CPU time = ICx (CPIexecution + Mem accesses per instruction x Miss rate x Miss penalty) x CCT = IC x (CPIexecution + Misses per instruction x Miss penalty) x CCT 2021/9/25 USTC CS AN Hong 29
Improving Cache Performance: 3 general options Average Memory Access time = Hit Time + (Miss Rate x Miss Penalty) = (Hit Rate x Hit Time) + (Miss Rate x Miss Time) 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the cache. 2021/9/25 USTC CS AN Hong 30
A Modern Memory Hierarchy n By taking advantage of the principle of locality: − Present the user with as much memory as is available in the cheapest technology. − Provide access at the speed offered by the fastest technology. Processor Control Speed (ns): 1 s Size (bytes): 100 s 2021/9/25 On-Chip Cache Registers Datapath Second Level Cache (SRAM) Main Memory (DRAM) 10 s 100 s Ks Ms USTC CS AN Hong Tertiary Secondary Storage (Disk/Tape) (Disk) 10, 000 s 10, 000, 000 s (10 s ms) (10 s sec) Gs Ts 31
Recall: Levels of the Memory Hierarchy Upper Level Capacity Access Time Cost Staging Xfer Unit CPU Registers 100 s Bytes <10 s ns Registers Cache K Bytes 10 -100 ns $. 01 -. 001/bit Cache Instr. Operands Blocks Main Memory M Bytes 100 ns-1 us $. 01 -. 001 Disk G Bytes ms -4 -3 10 - 10 cents Tape infinite sec-min 10 -6 2021/9/25 faster prog. /compiler 1 -8 bytes cache cntl 8 -128 bytes Memory Pages OS 512 -4 K bytes Files user/operator Mbytes Disk Tape USTC CS AN Hong Larger Lower Level 32
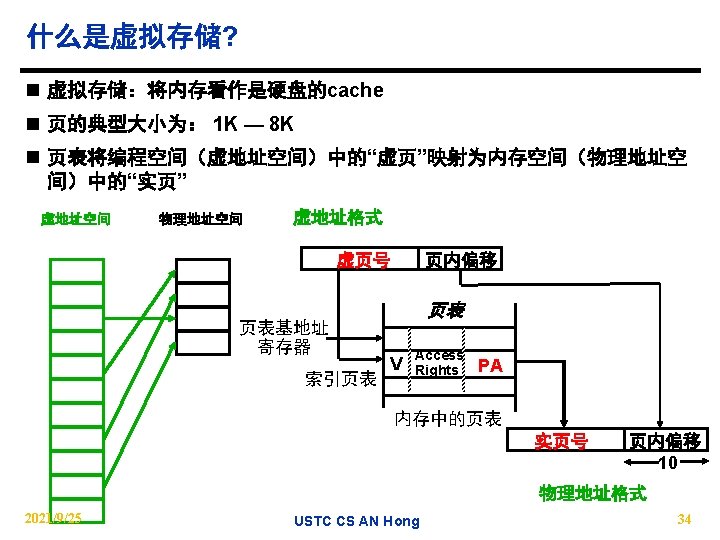
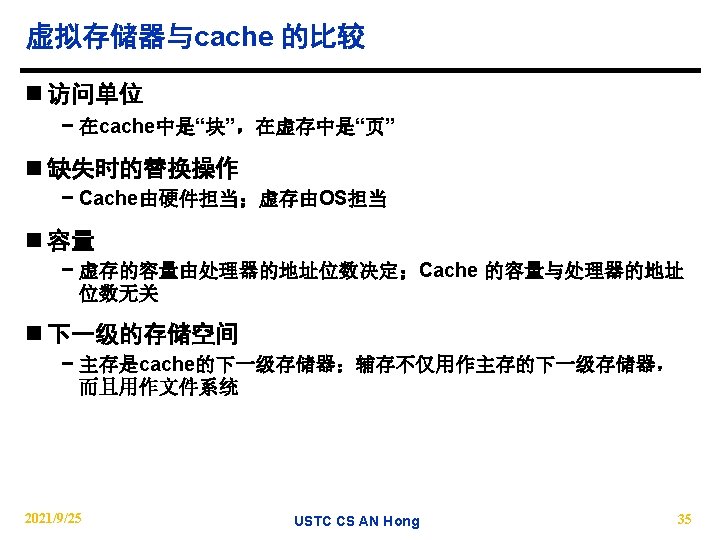
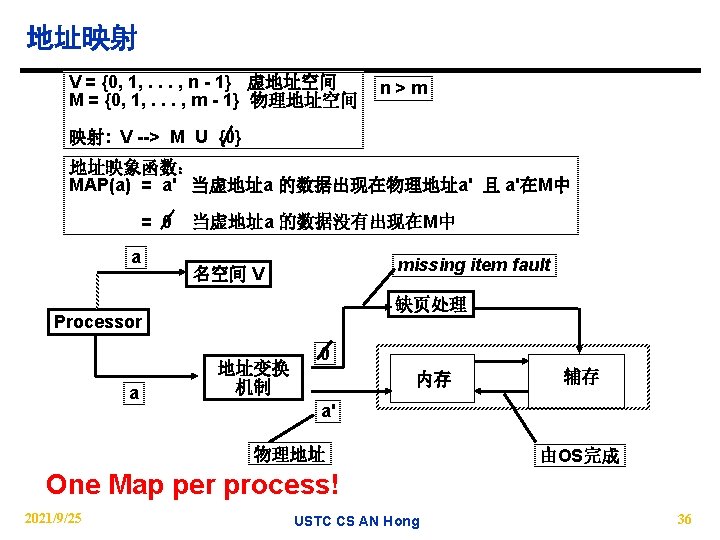
How is the hierarchy managed? n Registers <-> Memory − by compiler (programmer? ) n Cache <-> Memory − by the hardware n Memory <-> Disks − by the hardware and operating system (virtual memory) − by the programmer (files) 2021/9/25 USTC CS AN Hong 33
分页 V. A. P. A. 0 1024 frame 0 1 1 K 1 K 7 7168 Addr Trans MAP 1 K Physical Memory 0 1024 2021/9/25 1 K 1 K also unit of transfer from virtual to physical 1 K memory Virtual Memory 10 disp page no. Page Table Base Reg index into page table 31 31744 Address Mapping VA page 0 1 unit of mapping Page Table V Access Rights PA table located in physical memory + actually, concatenation is more likely physical memory USTC address CS AN Hong 39
大地址空间 两级页表 1 K PTEs 32 -bit 地址: 10 P 1 index 10 P 2 index 4 KB 12 page offest 4 bytes ° 4 GB virtual address space 一级页表 ° 4 MB of PTE 2 ° 4 KB of PTE 1 What about a 48 -64 bit address space? 2021/9/25 4 bytes 二级页表 USTC CS AN Hong 40
Virtual Address and a Cache: Step backward? ? ? VA CPU miss PA Translation Cache Main Memory hit data n Virtual memory seems to be really slow: − we have to access memory on every access -- even cache hits! − Worse, if translation not completely in memory, may need to go to disk before hitting in cache! n Solution: Caching page table! − Keep track of most common translations and place them in a “Translation Lookaside Buffer” (TLB, 快表) 2021/9/25 USTC CS AN Hong 41
Making address translation practical: TLB n Translation Look-aside Buffer (TLB) is a cache of recent translations virtual address Virtual Address Space Physical Memory Space page off Page Table 2 0 在内存 1 3 TLB frame page 2 2 0 5 2021/9/25 USTC CS AN Hong physical address page off 在片内 42
TLB organization: include protection Virtual Address Physical Address Dirty Ref Valid Access ASID 0 x. FA 00 0 x 0041 0 x 0003 0 x 0010 0 x 0011 Y N N N Y Y Y R/W R R 34 0 0 n. TLB usually organized as fully-associative cache − Lookup is by Virtual Address − Returns Physical Address + other info n. Dirty => Page modified (Y/N)? Ref => Page touched (Y/N)? Valid => TLB entry valid (Y/N)? Access => Read? Write? ASID => Which User? 2021/9/25 USTC CS AN Hong 43
Reducing translation time further n As described, TLB lookup is in serial with cache lookup: Virtual Address 10 offset V page no. TLB Lookup V Access Rights PA P page no. offset 10 Physical Address n Machines with TLBs go one step further: they overlap TLB lookup with cache access. − Works because lower bits of result (offset) available early 2021/9/25 USTC CS AN Hong 45
Summary #1/5: Control and Pipelining n Control VIA State Machines and Microprogramming n Just overlap tasks; easy if tasks are independent n Speed Up Pipeline Depth; if ideal CPI is 1, then: n Hazards limit performance on computers: − Structural: need more HW resources − Data (RAW, WAR, WAW): need forwarding, compiler scheduling − Control: delayed branch, prediction 2021/9/25 USTC CS AN Hong 46
Summary #2/5: Caches n The Principle of Locality: − Program access a relatively small portion of the address space at any instant of time. l Temporal Locality: Locality in Time l Spatial Locality: Locality in Space n Three Major Categories of Cache Misses: − Compulsory Misses: sad facts of life. Example: cold start misses. − Capacity Misses: increase cache size − Conflict Misses: increase cache size and/or associativity. Nightmare Scenario: ping pong effect! n Write Policy: − Write Through: needs a write buffer. Nightmare: WB saturation − Write Back: control can be complex 2021/9/25 USTC CS AN Hong 47
Summary #3/5: The Cache Design Space n Several interacting dimensions Cache Size − cache size − block size − associativity − replacement policy − write-through vs write-back − write allocation Associativity Block Size n The optimal choice is a compromise − depends on access characteristics l workload l use (I-cache, D-cache, TLB) − depends on technology / cost n Simplicity often wins 2021/9/25 USTC CS AN Hong Bad Good Factor A Less Factor B More 48
Summary #4/5: TLB, Virtual Memory n Caches, TLBs, Virtual Memory all understood by examining how they deal with 4 questions: − 1) Where can block be placed? − 2) How is block found? − 3) What block is repalced on miss? − 4) How are writes handled? n Page tables map virtual address to physical address n TLBs are important for fast translation n TLB misses are significant in processor performance − funny times, as most systems can’t access all of 2 nd level cache without TLB misses! 2021/9/25 USTC CS AN Hong 49
Summary #5/5: Memory Hierachy n Virtual memory was controversial at the time: can SW automatically manage 64 KB across many programs? − 1000 X DRAM growth removed the controversy n Today VM allows many processes to share single memory without having to swap all processes to disk; today VM protection is more important than memory hierarchy n Today CPU time is a function of (ops, cache misses) vs. just f(ops): What does this mean to Compilers, Data structures, Algorithms? 2021/9/25 USTC CS AN Hong 50