Lecture on High Performance Processor Architecture CS 05162
 Introduction on Thread-Level Parallel Architecture An")
 −")

 n ILP exploits implicit parallel operations within a loop or")
 Time (processor cycles) (a)")
 − a single")








 superscalar (b) cycle-by-cycle interleaving superscalar( Fine-Grained Multithreading")
 (b) N N N Context switch IMT vs. BMT (c) multi-threaded : (a)")

")


 n Simultaneous multithreading (SMT): insight that dynamically scheduled processor already has")

 simultaneous multithreading (SMT) (b) chip multiprocessor (CMP) 2021/2/23 CS of")
 Multithreaded Categories Superscalar Simultaneous Fine-Grained. Coarse-Grained. Multiprocessing. Multithreading Thread 1 Thread")

 − Strength l")
 Master/Slave 2021/2/23")






、 − 块交错多线程(Blocked Multi. Threading, 简称BMT) −")









 − increase overall processing throughput")



 seem to limit to")










- Slides: 59
Lecture on High Performance Processor Architecture (CS 05162) Introduction on Thread-Level Parallel Architecture An Hong han@ustc. edu. cn Fall 2007 University of Science and Technology of China Department of Computer Science and Technology CS of USTC AN Hong
Outline n Understand multithreaded and multiprocessing processors architecture − Thread Level Parallelism (TLP) − Compare some basic concepts n What are the requirements for multithreaded and multiprocessing processors architecture? 2021/2/23 CS of USTC AN Hong 2
Understand Multithreaded and Multiprocessing Processors Architecture 2021/2/23 CS of USTC AN Hong 3
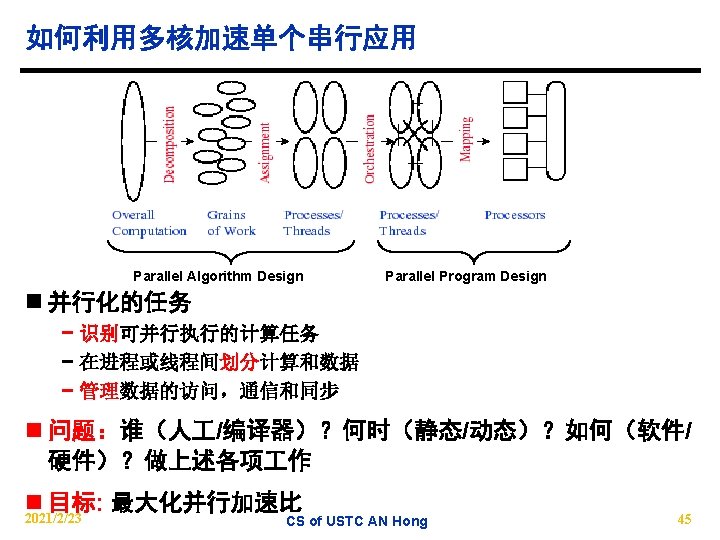
Thread Level Parallelism (TLP) n ILP exploits implicit parallel operations within a loop or straight-line code segment − Instruction multiple issue and out-of-order execution − Superscalar and VLIW n DLP expressively tells hardware that these N operations or N operation-sets are independent − use the same functional unit or same functional cluster − Vector, SIMD, SPMD n TLP explicitly represent parallelism inherent in an application and use multiple instruction streams to improve throughput of processors and execution time of multi-threaded programs − the concurrent execution of instruction from different sections of code on single processor or multiple processors − IMT/BMT/SMT, CMP 2021/2/23 CS of USTC AN Hong 4
Scalar vs. Superscalar vs. VLIW single-threaded : Time (process cycles) Time (processor cycles) (a) scalar (b) superscalar (c) VLIW N N N Issue slots (a) 2021/2/23 CS of USTC AN Hong (a) (c) 5
Single issue vs. multiple issue processor n von Neumann processor(Scalar processor) − a single program counter − really: IPC ≤ 1 n ILP processor(Superscalar, VILW) − a single program counter − really: IPC ≤ 2 (when 4~8 issue) 2021/2/23 CS of USTC AN Hong 6
Superscalar processor vs. VLIW processor n Superscalar processor − programming: by the sequential semantics − a single program counter point a single inst. stream execution l out-of-order issue l execution independent inst l in-order commit n VLIW processor − programming: by the sequential semantics − Independent instruction is compiled into VLIW of fixed length − a program counter point to the VLIW 2021/2/23 CS of USTC AN Hong 7
Superscalar processor vs. VLIW processor n Superscalar − Strength: l Multiple-issue per clock cycle l Accurate and effective runtime dependence check l Out-of-order execution for high ILP l HW supported instruction-level speculation on values, dependences, and branch outcomes − Limitations l Attempt to extract more and more parallelism from a single thread of code, limited to only instruction-level parallelism (not enough parallelism) l The number of independent inst. within a single basic block is limited, branch prediction: a misprediction exacts a large penalty l A single instruction window is not easy to scale (limited by wire delay) , additional hardware is likely to produce diminishing returns l Compilers exploit mostly innermost loops 2021/2/23 CS of USTC AN Hong 8
Superscalar processor vs. VLIW processor n VLIW − Strength l Relatively simple HW support l Using compiler to resolve dependences at compile time and schedule instructions: • Trace scheduling • Software pipelining l Extensive use of profiling information in compiler − Limitation l Code not portable, may expand to a large size l Independent instructions are executed in locked steps l Limited to ILP only l Compiler exploits only innermost loop 2021/2/23 CS of USTC AN Hong 9
Single-thread processor vs. Multithreaded processor n Single-thread processor − a single program counter − parallelism from a single thread of instructions − the concurrent execution of instruction from different location in the code n Multithreaded processor − multiple program counters − parallelism from multiple thread of instructions − the concurrent execution of instruction from different sections of code 2021/2/23 CS of USTC AN Hong 10
Do both ILP and TLP? n TLP and ILP exploit two different kinds of parallel structure in a program n Could a processor oriented at ILP to exploit TLP? − functional units are often idle in data path designed for ILP because of either stalls or dependences in the code n Could the TLP be used as a source of independent instructions that might keep the processor busy during stalls? n Could TLP be used to employ the functional units that would otherwise lie idle when insufficient ILP exists? 2021/2/23 CS of USTC AN Hong 11
For most apps, most execution units lie idle For an 8 -way superscalar. 2021/2/23 From: Tullsen, Eggers, and Levy, “Simultaneous Multithreading: Maximizing On-chip Parallelism, ISCA CS of USTC AN Hong 1995. 12
Mulithreaded Execution on 1 processor n Multithreading: multiple threads to share the functional units of 1 processor via overlapping − processor must duplicate independent state of each thread for running independent programs, e. g. , l a separate PC l a separate copy of register file l a separate page table − memory shared through the virtual memory mechanisms, which already support multiple processes − HW for fast thread switch; much faster than full process switch 100 s to 1000 s of clocks n When switch? − Alternate instruction per thread (fine grain) − When a thread is stalled, perhaps for a cache miss, another thread can be executed (coarse grain) 2021/2/23 CS of USTC AN Hong 13
Multithreading vs. Non-Multithreading Approaches multi-threaded : (a) superscalar (b) cycle-by-cycle interleaving superscalar( Fine-Grained Multithreading ) (c) block interleaving superscalar( Course-Grained Multithreading ) 2021/2/23 CS of USTC AN Hong 15
(a) (b) N N N Context switch IMT vs. BMT (c) multi-threaded : (a) cycle-by-cycle interleaving superscalar( Fine-Grained Multithreading ) (b) block interleaving superscalar( Course-Grained Multithreading ) (c) cycle-by-cycle interleaving VLIW( Fine-Grained Multithreading ) 2021/2/23 CS of USTC AN Hong 16
Simultaneous Multi-threading. . . One thread, 8 units Cycle M M FX FX FP FP BR CC Two threads, 8 units Cycle M M FX FX FP FP BR CC 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 M = Load/Store, FX = Fixed Point, FP = Floating Point, BR = Branch, CC = Condition Codes 2021/2/23 17 CS of USTC AN Hong
Multithreading Processor Program Execution Model n Instruction-interleaving Multi. Threadig, IMT (Cycle-bycycle interleaving, Fine-Grained Multithreading) − An instruction of another thread is fetched and fed into the execution pipeline at each processor cycle, i. e. context switch at each processor cycle. n Block-interleaving Multi. Threading, BMT(Course-Grained Multithreading) − The instructions of a thread are executed successively until an event occurs that may cause latency. This event induces a context switch. n Simultaneous multithreading, SMT − Instructions are simultaneously issued from multiple threads to the FUs of a superscalar processor. − combines a wide issue superscalar instruction issue with multithreading. 2021/2/23 CS of USTC AN Hong 18
Fine-Grained Multithreading Processor n Switches between threads on each instruction, causing the execution of multiples threads to be interleaved. I. e. , CPU must be able to switch threads every clock n Usually done in a round-robin fashion, skipping any stalled threads n Advantage is it can hide both short and long stalls, since instructions from other threads executed when one thread stalls n Disadvantage is it slows down execution of individual threads, since a thready to execute without stalls will be delayed by instructions from other threads n Used on Sun’s Niagara (will see later) 2021/2/23 CS of USTC AN Hong 19
Course-Grained Multithreading Processor n Switches threads only on costly stalls, such as L 2 cache misses n Advantages − Relieves need to have very fast thread-switching − Doesn’t slow down thread, since instructions from other threads issued only when the thread encounters a costly stall n Disadvantage is hard to overcome throughput losses from shorter stalls, due to pipeline start-up costs − Since CPU issues instructions from 1 thread, when a stall occurs, the pipeline must be emptied or frozen − New thread must fill pipeline before instructions can complete − Because of this start-up overhead, coarse-grained multithreading is better for reducing penalty of high cost stalls, where pipeline refill << stall time n Used in IBM AS/400 and Intel IXP 1200/2400 2021/2/23 CS of USTC AN Hong 20
Simultaneous Multithreading (SMT) n Simultaneous multithreading (SMT): insight that dynamically scheduled processor already has many HW mechanisms to support multithreading − Large set of virtual registers that can be used to hold the register sets of independent threads − Register renaming provides unique register identifiers, so instructions from multiple threads can be mixed in datapath without confusing sources and destinations across threads − Out-of-order completion allows the threads to execute out of order, and get better utilization of the HW n Just adding a per thread renaming table and keeping separate PCs − Independent commitment can be supported by logically keeping a separate reorder buffer for each thread n Used in Intel Pentium IV and IBM Power 5 2021/2/23 CS of USTC AN Hong 21
SMT vs. Superscalar n Hardware resource usage with SMT − Added 10% to chip size, to get 125 -175% speedup − Functional resources shared by multiple threads − Shared L 2 caches, added L 1 per thread − Hardware support of multiple threads n Advantage − dispatches instructions from multiple data streams, allowing efficient execution and latency tolerance l Vertical sharing issue slots =>TLP and block multi-threading l Horizontal sharing issue slots => ILP and simultaneous multiple thread instruction dispatch − Highest utilization with multi-program or parallel workload n Disadvantages − Expected high resource contention 2021/2/23 CS of USTC AN Hong 22
SMT vs. CMP (a) simultaneous multithreading (SMT) (b) chip multiprocessor (CMP) 2021/2/23 CS of USTC AN Hong 23
Time (processor cycle) Multithreaded Categories Superscalar Simultaneous Fine-Grained. Coarse-Grained. Multiprocessing. Multithreading Thread 1 Thread 2 2021/2/23 Thread 4 CS of USTC AN Hong Thread 5 Idle slot 24
MT and CMP Processor Architecture Model n Uniprocessor − Single-thread core: scalar, superscalar, VLIW − Multi-thread core: IMT, BMT, SMT n Multiprocessor(must be multi-threaded) − − ST core-based CMP MT core-based CMP PIM-based CMP Morph CMP n Multicore vs. manycore − Multicore: 2~64 cores(bigger) − Manycore: 100 s~1000 s cores(smaller) 2021/2/23 CS of USTC AN Hong 25
Strength & Limitation of CMP n Multiprocessor on a Chip (CMP) − Strength l More scalable (allow shorter wires) l More flexible (various interconnect schemes) l Exploit primarily loop-level parallelism l Very good parallelizing compiler technology available − Limitations l Communication and sync through memory • Higher overhead • Need larger granularity • Exploit parallel loops (Doall) only l May need a coherence cache l Primarily for scientific, not general-purpose applications 2021/2/23 CS of USTC AN Hong 26
Traditional Multiprocessor System Overview Multi. Processor SIMD MIMD Shared Memory (tightly coupled) Master/Slave 2021/2/23 Distributed Memory (loosely coupled) Symmetric (SMP) CS of USTC AN Hong Clusters 27
global memory shared address space Processor distributed address spaces Organizational principles of multiprocessors . . . physically distributed memory Processor Interconnection Processor (SMP) symmetric multiprocessor Local Memory Shared Memory Interconnection (DSM) distributed-shared-memory multiprocessor Processor empty Processor . . . Local Memory send Processor Local Memory receive Interconnection 2021/2/23 CS of USTC AN Hong message-passing (shared-nothing) multiprocessor 28
Typical SMP Processor Primary Cache Secondary Cache Bus Global Memory 2021/2/23 CS of USTC AN Hong 29
Shared memory candidates for CMPs Shared-main memory Processor Primary Cache Secondary Cache Global Memory 2021/2/23 CS of USTC AN Hong 30
Shared memory candidates for CMPs Shared-secondary cache Processor Primary Cache Secondary Cache Global Memory 2021/2/23 CS of USTC AN Hong 31
Shared memory candidates for CMPs Shared-primary cache Processor Primary Cache Secondary Cache Global Memory 2021/2/23 CS of USTC AN Hong 32
多线程处理器的体系结构分类 n 基于计算模型 Non-dataflow based CDC 6600 1964 Dataflow model inspired Static Dataflow Dennis 74 MIT 2021/2/23 Alwife Agarwal 1989 -96 MASA Halstead 1986 HEP B. Smith 1978 Tera B. Smith 1990 -97 J-Machine Cosmic Cube Dally Seiltz 1988 -93 1985 Others: Multiscalar (1994), SMT (1995), CMP, etc. Monsoon P-RISC Papadopoulos MIT TTDA Nikhil & & Culler Arvind 1988 1980 1989 Iannuci’s 1988 -1992 Manchester SIGMA-I Gurd & Watson Shimada 1982 1988 SAM MDFA Hum. Gao Dennis. Gao 92 87 -88 Gao. Hum. Mon 91 CS of USTC AN Hong M-Machine Dally 1994 - MTA Hum. Theobald Gao 94 *T/Start-NG MIT/Motorolo 1991 - EM-5/4/X RWC-1 1992 -97 EARTH (PACT 95’, ICS 95’ EURO-PAR 95’ 33
多线程处理器的体系结构分类 n 基于指令的调度执行方式 − 指令交错多线程(Interleaved Multi. Threading, 简称IMT)、 − 块交错多线程(Blocked Multi. Threading, 简称BMT) − 同时多线程(Simultaneous Multi. Threading, 简称SMT) 2021/2/23 CS of USTC AN Hong 34
Future Processor Architecture: Possible Solutions n Speed-up of a single-threaded application by aggressive ILP − single sequencer, with speculation (control then data) − Trace cache/Superspeculative/Advanced superscalar n Speed-up of a single-threaded application by TLP − multiple (implicit) sequencers, aggressive speculation − Trace/Multiscalar processor n Speed-up of multi-threaded applications by TLP − Simultaneous multithreading(SMT): multiple (explicit) sequencers, no speculation l Intel Pentium IV, Alpha 21464 => IBM Power 5 − Chip multiprocessors (CMPs): multiple (explicit) sequencers, no speculation l IBM Power 4 => Intel Pentium IV(第三代) n Exotics − Processor-in-memory (PIM) or intelligent RAM (IRAM) − Reconfigurable 2021/2/23 CS of USTC AN Hong 36
What are the requirements for multithreaded and multiprocessing processors Architecture 2021/2/23 CS of USTC AN Hong 37
What are the requirements for multithreaded and multiprocessing processors architecture? n Tolerant long latency in contemporary microprocessor architecture − Long memory latency l (local)Memory access latency in uniprocessor l (globle)Communication latency(remote memory access ) in multiprocessors − Branches delay or misprediction squash − floating-point division − non-determinism: the need for synchronisation between operations n Extract more parallelism − Many applications have less ILP, and hard to parallelize or not parallelizable 2021/2/23 CS of USTC AN Hong 38
Approaches for hiding latency n Avoid it − Register renaming l For latency due to WAR and WAW data dependence − Dynamic branch prediction and control speculation l For latency due to control dependence − Cache and Prefetching l For latency due to long memory access n Tolerate it − Out-of-order execution(tomasulo algorithm) l For latency due to RAW data dependence − Using Multithreading l For Any latency 2021/2/23 CS of USTC AN Hong 39
New applications in Distributed/Multithreaded Processor n Throughput-oriented workloads − Executing multiple, independent programs on underlying parallel microarchitecture l Similar to traditional throughput-oriented multiprocessor(e. g. SMP) l Significant engineering challenges, but little in ways of architectural / microarchitectural innovation n Coarse-grain multithreaded applications − Parallel Processing of Single Program? l Will the promise of explicit / automatic parallelism come true? l Will new (parallel) programming languages take over the world? − Speculative Parallelization ! l Sequential languages aren’t going away�� l Use speculation to overcome inhibitors to “automatic” parallelization�� • Ambiguous dependences l New models of speculation (e. g. , thread-level speculation) will be needed to extract more parallelism • Divide program into “speculatively parallel” portions or “speculative threads” 2021/2/23 CS of USTC AN Hong 40
Threads grain-levels for CMPs n Multiple processes in parallel − implies a different address space for all processes n Multiple threads statically from a single application − implies a common address space for all threads n Extracting threads (may dynamically )from a single instruction stream − implies a common address space for a thread (such as in multiscalar, trace processors, …) 2021/2/23 CS of USTC AN Hong 41
Challenges in General-Purpose Applications n Mostly Do-while loops − Need thread-level speculation l not available(N/A) in current multiprocessors n Parallelism exists in outer loops − Need thread-level support l N/A in superscalar l Good in multiprocessors n Pointers/aliases complicate dependence analysis − Need runtime dependence check both within and between threads, or use data speculation l N/A in multiprocessor and superscalar 2021/2/23 CS of USTC AN Hong 42
Challenges in General-Purpose Applications n Small basic blocks in straight-line code − Need instruction-level speculative/predicated execution, branch prediction, profiling-based compilation, out-of-order execution l very well developed in superscalars n Many small loops, Do across loops and parallel sections − Need fast, low overhead communication/synchronization support − Communication directly between register files, or special memory buffers without going through memory l N/A in current MOAC(Multiprocessor on a Chip ) 2021/2/23 CS of USTC AN Hong 43
Work for Distributed/Multithreaded Processor n Independent programs(in Multiprogramming System) − increase overall processing throughput − works well in server environment n Independent threads of multithreaded application(in Parallel programming System) − increase overall throughput − compatible with software trends? n Related threads − e. g. , for reliability n But what about speeding up single program execution? − single program speed will continue to be important − how to ‘‘‘parallelize’’ or ‘‘multithread’’ single program? Can we use underlying “multiprocessor” to speed up 2021/2/23 execution of single program? CS of USTC AN Hong 44
Commentary n Limits to ILP (power efficiency, compilers, dependencies …) seem to limit to 3 to 6 issue for practical options n Explicitly parallel (Data level parallelism or Thread level parallelism) is next step to performance n Coarse grain vs. Fine grained multihreading − Only on big stall vs. every clock cycle n Simultaneous Multithreading if fine grained multithreading based on OOO superscalar microarchitecture − Instead of replicating registers, reuse rename registers n Itanium/EPIC/VLIW is not a breakthrough in ILP n Balance of ILP and TLP decided in marketplace 2021/2/23 CS of USTC AN Hong 49
Issues n How Much Potential Thread-Level Parallelism in SPEC Benchmarks? − Identify thread-level parallelism n How to get that many threads? − Normal C/Fortran code with slight modifications ? − Compiler extracts some parallelism automatically ? − Programmer points out other parallelism manually ? − When in doubt, run more programs ? − Can we treat different thread types uniformly? 2021/2/23 CS of USTC AN Hong 50
Issues n How to parallelize a single program? − What does it mean to parallelize? l how to divide program into multiple portions − What constrains parallelization? l dependences (especially ambiguous) • • Control Dependences Artificial (Name) Dependences True Data Dependences Ambiguous Dependences − How to “breaking” dependences in a practical and efficient manner? l within single chip? l in a larger-scale system? − What is the impact on other aspects of computing (e. g. . , algorithms, compilers)? 2021/2/23 CS of USTC AN Hong 51
Issues n How to implement hardware mechanisms cheaply? n How many threads are needed on an giving multithreaded architecture − e. g. SMT, CMP, POSM, MTA, ……? − Study various thread execution model using real benchmarks l How to represent threads in executable? l How to initiate threads efficiently? l How to deal with variable context availability? l How to synchronize efficiently? l How to emulate performance optimizations for single sequencers with multiple sequencers? n Single, merging or combining these(e. g. SMT, CMP, POSM, MTA) architectures, which will win? − In the end, compiler advances may decide which wins? n Can CMP expose more parallelism (for sparse numerical applications/nonnumerical applications)? − How do that ? 2021/2/23 CS of USTC AN Hong 52
Issues n What software/hardware support mechanisms are required for multithreaded architecture? 2021/2/23 CS of USTC AN Hong 53
重要的前驱 作 n 学术界的代表性研究 作 − − − Wisconsin-Madison Multiscalar/Trace Washington SMT Stanford CMP MIT RAW, Stanford Smart. Memory, University of Texas at Austin TRIPS Notre Dame PIM/Berkeley IRAM Gao EARTH n 主流商用处理器开发 作 − Intel Pentium IV(技术来自Alpha 21464) l 第一代超线程:增加系统(多个应用程序)吞吐量 l 第二代超线程:增加单一应用程序的性能 l 第三代超线程:多线程+多核心(微内核); 非对称型超线程+自动线程化 编译器 − IBM Power 4,Power 5: l Power 4:CMP l Power 5:CMP + SMT − Sun Ultra. SPARC T 1(Niagara) − Sun MAJC: ILP, DLP, TLP,支持Java加速 2021/2/23 CS of USTC AN Hong 54
重要的前驱 作 n Super-Speculative − These processors aim to break the dataflow limit by relying on value locality, the fact that many values can be reliably predicted during execution, by aggressively speculating at every part of the execution pipeline. n Multi. Scalar − The compiler partitions program segments from the control flow graph, and cooperating scalar processors execute them in parallel (speculatively) using multiple sequencers (PCs) under the control of a central task sequencer. Complex hardware is required to deal with proper resolution of inter-task dependences. n Trace − A Trace Processor is composed of multiple subsystems similar in complexity to today’s superscalar processors. The code is broken up into multiple traces that are captured in hardware trace caches. One core executes the current trace while the rest execute future traces speculatively. 2021/2/23 CS of USTC AN Hong 55
重要的前驱 作 n Data. Scalar − Data. Scalar processors run the same sequential program on multiple cores with different data sets. Each core broadcasts operands that it loads from its local memory; a core waiting on an operand will not request it but rather wait for its broadcast. In fact these operands could actually be computed by other cores rather than simply loaded. n Dynamic Multithreading − Dynamic Multithreading Processors execute existing uniprocessor binaries by creating implicit threads, without programmer indication, at places such as procedure calls, after loops, and loop bodies. Simulations have shown that Dynamic Multithreading has a performance advantage of 20 -40% over outof-order superscalar execution. 2021/2/23 CS of USTC AN Hong 56
重要的前驱 作 n Super-threaded − A static compiler parallelizes the code and creates threads that may contain data or control dependences. The processor provides hardware dependence tracking and a bus to exchange data that arise from loop carried dependences. This is similar to the Multi. Scalar design. n Multithreaded − The principal novelty of multithreaded processors is that there may be instructions from several threads that are all candidates for execution in the pipeline the processor will need to contain the register and control states of several threads at once. The main advantage of this architecture is the latency tolerance and improved pipeline utilization that is gained by switching among threads. Multithreaded processors have been proposed or used in several machines, such as the Denelcor HEP, MIT/Motorola Monsoon, Tera MTA and Mc. Gill MTA. 2021/2/23 CS of USTC AN Hong 57
重要的前驱 作 n Simultaneous Multithreading − Whereas a multithreaded processor interleaves executions on a scalar RISC or VLIW machine, an SMT uses a superscalar core where all hardware contexts are simultaneously active. So, not only can different threads have instructions execution interleaved, the instructions can be executed in parallel. n Chip Multiprocessor − Independent processors combined on a single chip, with shared memory at the level of main memory, second level cache, or even first level cache. It is as yet unclear which of the SMT or CMP approaches leads to the best performance. CMP is easier to implement but only the SMT can hide latencies. CMPs using moderately sized SMT cores have also been proposed, and in fact such combinations lead to the greatest throughput for a given hardware budget. 2021/2/23 CS of USTC AN Hong 58
重要的前驱 作 n Other Researches Related to Multithreaded Architectures − Value Prediction for Speculative Multithreaded Architectures, Marcuello, Tubella, Gonzalez, MICRO, 1999 − Correctly Implementing Value Prediction in Microprocessors that Support Multithreading or Multiprocessing, Martin, et al MICRO 2001 − The Need for Fast Communication in Hardware-Based Speculative Chip Multiprocessors, Krishnan and Torrellas, PACT 1999 2021/2/23 CS of USTC AN Hong 59