Lecture on High Performance Processor Architecture CS 05162
 Introduction on Novel Memory-on-chip Architectures An")

 more than 30 years ago in the IBM")




 1 st session on caches 2021/6/13 CS")








 speed increases")




 − Associate")
 − Integrates memory")







- Slides: 31
Lecture on High Performance Processor Architecture (CS 05162) Introduction on Novel Memory-on-chip Architectures An Hong han@ustc. edu. cn Fall 2007 University of Science and Technology of China Department of Computer Science and Technology CS of USTC AN Hong
Outline n Cache − History − Problems and Solutions − 2 K papers on caches by Y 2 K: Do we need more? n Processor-in-Memory(PIM) − Understand what PIM architectures are − Understand motivation for PIM architectures l Performance Issues l Technological Motivations/Constraints − Be able to discuss different PIM architectures l Different Applications l Different Implementations n IRAM 2021/6/13 CS of USTC AN Hong 2
Cache history n Caches introduced (commercially) more than 30 years ago in the IBM 360/85 − already a processor-memory gap n Oblivious to the ISA − caches were organization, not architecture n Many different organizations − direct-mapped, set-associative, skewed-associative, sector, decoupled sector etc. n Caches are ubiquitous − On-chip, off-chip − But also, disk caches, web caches, trace caches etc. n Multilevel cache hierarchy − With inclusion or exclusion 2021/6/13 CS of USTC AN Hong 3
Cache history n Cache exposed to the ISA − Prefetch, Fence, Purge etc. n Cache exposed to the compiler − Code and data placement n Cache exposed to the O. S. − Page coloring n Many different write policies − copy-back, write-through, fetch-on-write, write-around, writeallocate etc. 2021/6/13 CS of USTC AN Hong 4
Cache history n Numerous cache assists, for example: − For storage: write-buffers, victim caches, temporal/spatial caches − For overlap: lock-up free caches − For latency reduction: prefetch − For better cache utilization: bypass mechanisms, dynamic line sizes − etc. . . 2021/6/13 CS of USTC AN Hong 5
Cache history: Caches and Parallelism n Cache coherence − Directory schemes − Snoopy protocols n Synchronization − Test-and-test-and-set − load linked -- store conditional n Models of memory consistency 2021/6/13 CS of USTC AN Hong 6
When were the 2 K papers being written? n A few facts: − 1980 textbook: < 10 pages on caches (2%) − 1996 textbook: > 120 pages on caches (20%) n Smith survey (1982) − About 40 references on caches n Uhlig and Mudge survey on trace-driven simulation (1997) − About 25 references specific to cache performance only − Many more on tools for performance etc. 2021/6/13 CS of USTC AN Hong 7
Cache research vs. time Largest number (14) 1 st session on caches 2021/6/13 CS of USTC AN Hong 8
The Memory Latency Problem n Technological Trend: Memory latency is getting longer relative to microprocessor speed (50% per year) n Problem: Memory Latency - Conventional Memory Hierarchy Insufficient: − Many applications have large data sets that are accessed noncontiguously. − Some SPEC benchmarks spend more than half of their time stalling [Lebeck and Wood 1994]. n Domain: benchmarks with large data sets: symbolic, signal processing and scientific programs 2021/6/13 CS of USTC AN Hong 9
Present Latency Solutions and Limitations Solution Larger Caches 1. Slow 2. Works well only if working set fits cache and there is temporal locality Hardware Prefetching 3. Cannot be tailored for each application 4. Behavior based on past and present executiontime behavior Software Prefetching 5. Ensure overheads of prefetching do not outweigh the benefits> conservative prefetching 6. Adaptive software prefetching is required to change prefetch distance during run-time Multithreading 7. Hard to insert prefetches for irregular access patterns 8. focus on solving the throughput problem, not the memory latency problem 2021/6/13 CS of USTC AN Hong 10
The Memory Bandwidth Problem n It’s expensive! n Often ignored n Processor-centric optimization to bridge the gap but lead to memory-bandwidth problems − Prefetching − Speculation − Multithreading hide latency Can we always just trade bandwidth for latency? 2021/6/13 CS of USTC AN Hong 11
Present Bandwidth Solutions n Wider/faster connections to memory − Rambus DRAM − Use higher signaling rates on existing pins − Use more pins for the memory interface n Larger on-chip caches − Fewer requests to DRAM − Only effective if larger caches improve hit rate n Traffic-efficient requests − Only request what you need − Caches are “guessing” that you might need adjacent data − Compression? 2021/6/13 CS of USTC AN Hong 12
Present Bandwidth Solutions n More efficient on-chip caches − Only 1/20 – 1/3 of the data in a cache is live − Again, caches are “guessing” what will be used again − Spatial vs. temporal vs. no locality n Logic/DRAM integration(Processor-centric architectures),E. g. IRAM − Put the memory on the processor − On-chip bandwidth is cheaper than pin bandwidth − You will still probably have external DRAM as well n Memory-centric architectures, E. g. PIM − “Smart” memory (PIM) − Put processing elements wherever there is memory 2021/6/13 CS of USTC AN Hong 13
Modern DRAM n Not truly random access n Synchronous n Three-dimensional − Bank − Row − Column n Shared address lines n Shared data lines 2021/6/13 CS of USTC AN Hong 14
DRAM Throughput and Latency 2021/6/13 CS of USTC AN Hong 15
What is a PIM Architectures? PIM = Processor-in-Memory, or Processing in Memory, Computing in Memory n Traditional System Architecture: Processor on one chip, memory on others n Processor-in-memory Architecture: Integrate processor and memory onto the same die − Depend on ability to fabricate DRAM on same chip as processor − Enabling huge improvements in Latency and Bandwidth 2021/6/13 CS of USTC AN Hong 16
Motivation n Growing gap between processor and memory performance − Memory (DRAM) speed increases 7%/year − Processor speed increases 55%/year − Caches help some, but not enough n Increase in number of transistors/chip − 1 GB DRAMs predicted for 2001 (Might not make this) − Processor architectures approaching 1000 M transistors n Bandwidth loss at chip crossings − DRAM chips not getting wider at same rate their capacity increases − Time to read/write entire contents of chip increasing with DRAM generations − Maybe !! Logic close to memory ‘may’ provide high bandwidth, low latency access to memory 2021/6/13 CS of USTC AN Hong 17
Motivation n System Issues − Memory demands of applications increasing at half the rate of DRAM density − System memory size being set by bandwidth needs, not memory capacity requirements − Would shifting data-intensive computations to the memory system help ? … n Advances in fabrication technology make integration of logic and memory practical 2021/6/13 CS of USTC AN Hong 18
Technological Hurdles n DRAM fabrication processes traditionally very different than logic − DRAM: Minimize size of bit cell l Want to maximize capacitances for memory stability and slow refresh rates l Many polysilicon layers to build capacitors l Regular layout doesn’t require many metal layers − Logic: Optimize for circuit speed, density l Want to minmize capacitances for high-speed operation l Many metal layers to connect gates l Transistors optimized for speed − Logic also has a much less standard structure than memory n Effect: − Implementing DRAM in logic process hurts density − Implementing logic in DRAM process hurts speed (20 -100%) n Need fabrication processes that provide both DRAM and logic features − IBM has a production fab line optimized for integrating DRAM and logic 2021/6/13 CS of USTC AN Hong 19
What to do with PIM? n Simplest approach: just integrate system’s main memory onto the die − Relatively easy to design − Reduces system cost − Provides at best incremental performance improvements n Evolutionary approach: optimize memory system for PIM − Much wider connections between levels − Can make structure of main memory visible to processor n Revolutionary approach: move computing into memory − Powerful main processor − Less-powerful processors associated with memory − Distribute computation across different resources 2021/6/13 CS of USTC AN Hong 20
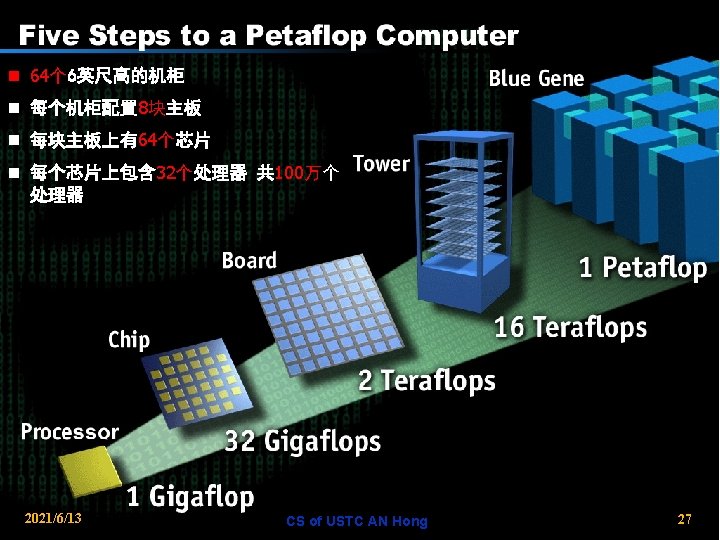
Classification: PIM Based Systems n Integral parts of larger systems augmenting the system performance − e. g. Active Pages, Flex. RAM, Smart Memories n Separate standalone systems individually for embedded processing − e. g. IRAM n Arrays for high performance computing − e. g. Blue Gene 2021/6/13 CS of USTC AN Hong 21
Classification: PIM Based Systems n Davis Active Pages (Chong et al. 1998) − Associate small processor with each page of DRAM − Effectively, multiprocessor on each memory chip − Co-processor paradigm; reconfigurable logic in memory; apps such as scatter-gather − A memory + FPGA n Illinois Flex. RAM (Torrellas et al. 1999) − Place a processor on each memory chip − Divide computation − Memory chip = Simple multiprocessor + superscalar + banks of DRAM; memory intensive apps. n Blue Gene(IBM, 1999) 2021/6/13 CS of USTC AN Hong 22
Classification: PIM Based Systems n Berkeley IRAM (Patterson et al. 1997) − Integrates memory onto main processor die − Explores on-chip memory architectures − Vector processor; data stream apps; low power n FBRAM (Deering et al. 1994) − Graphics in memory n 1 T-SRAM(1999) − Simple logic + DRAM => as if SRAM chip − Include: on-chip refresh controller, a small true SRAM cache 2021/6/13 CS of USTC AN Hong 23
IRAM n Computing Target − Computer Architecture Research biased towards desktop and server application − IRAM research inclined towards personal mobile computing − IRAM goals l High performance for multimedia functions l Small size, and power efficiency l Low design complexity n Merging technology of processor and memory n All the memory accesses remain within a single chip − Bandwidth can be as high as 100 to 200 Gbytes/sec − Access latency is less than 20 ns n Good solution for data intensive streaming application 2021/6/13 CS of USTC AN Hong 24
IRAM : Architecture Back Treating on-chip memory as main memory Berkeley V-IRAM 2021/6/13 CS of USTC AN Hong 25
Comparison n Applicability n Cost-Performance Benefit n Ease of Programming n Scalability n Chip area and power requirements n Extent of success achieved n Other Issues like … 2021/6/13 CS of USTC AN Hong 28
Current Industry Response n Manufacturing techniques for memory are different from those for logic n PIM would ‘decommodatize’ the memory market, and hurt interoperability n Power Consumption: Effect on DRAM n Memory chip-to-chip communication can become a primary bottleneck n Research in high speed memory interfaces for faster performance than PIMs might bring in new structural design issues. n At Intel, CRL PIM is not being pursued as a hot option right now 2021/6/13 CS of USTC AN Hong 29
Future of PIM n Optimal PIM ISA and Organization n Simple-Strong-Accurate PIM CAD-tools n Programming Model n Operating System Support n Compiler Support n Algorithms and Data Structures n Static/Dynamic Load Balancing n Interface between PIM and Non-PIM Systems 2021/6/13 CS of USTC AN Hong 30
Issues n Bridging the Gap !! Can we really do it ? n How do we program these things? − IRAM: Standard model of computation − Flex. RAM: Compiler allocates work to processors l View PIM as multiprocessor system − Active Pages: It’s the programmer’s problem l Programmer responsible for selecting work for each processor − Blue. Gene n How is the PIM Potential to influence industry ? 2021/6/13 CS of USTC AN Hong 31