Lecture on High Performance Processor Architecture CS 05162
 Control Hazard and Solution An Hong")




![Branch Instruction Semantics n 例: BEQ rs, rt, offset if R[rs] == R[rt] then](https://slidetodoc.com/presentation_image_h2/9cb3d228bce71f25ede24250b9d31e57/image-6.jpg "Branch Instruction Semantics n 例: BEQ rs, rt, offset if R[rs] == R[rt] then")
![What’s the Problem? 例: BEQ rs, rt, offset if R[rs] == R[rt] then PC<](https://slidetodoc.com/presentation_image_h2/9cb3d228bce71f25ede24250b9d31e57/image-7.jpg "What’s the Problem? 例: BEQ rs, rt, offset if R[rs] == R[rt] then PC<")


: Stall Add Beq Reg Mem Lost potential Mem Reg ALU Load")
: Delayed Branch Misc Load Mem Reg Mem Reg ALU Beq")
 n One or more instructions after branch get executed regardless of")

 n Pros: − Low Hardware Cost n Cons: − Depends on")
![Control Hazard Solution (3): 软件循环展开减少分支指令 n 例:向量的每个元素加常数 For (j=1; j<=1000; j++) x[j]=x[j]+s; 编译: 整数寄存器R](https://slidetodoc.com/presentation_image_h2/9cb3d228bce71f25ede24250b9d31e57/image-16.jpg "Control Hazard Solution (3): 软件循环展开减少分支指令 n 例:向量的每个元素加常数 For (j=1; j<=1000; j++) x[j]=x[j]+s; 编译: 整数寄存器R")
 2 stall 3 ADDD F 4,")
 2 stall 3 ADDD F 4,")
的例子 重命名前 1 Loop: LD 2 ADDD 3 SD 4 LD 2 ADDD")
的例子 1 Loop: LD 2 ADDD 3 SD 4 LD 5 ADDD 6")


: Prediction Beq Load Reg Mem Reg ALU Add Mem ALU O")

: Prediction n 单通路执行/多通路执行分支预测 − Single path execution − full eager execution")
 n")




 Branch Predictor Program")
 n Store branch address and predicted target (last target) −")


 Intel 8086 − loop buffer(a")
 l Always not taken Intel")

或预测精度(Branch Prediction Accurary, BPA) − dynamic percentage of branches which are")


 n Predicting return jumps from subroutines is hard 2021/9/10 CS of USTC AN")
 n Hardware stack for subroutine return addresses n Push return address")
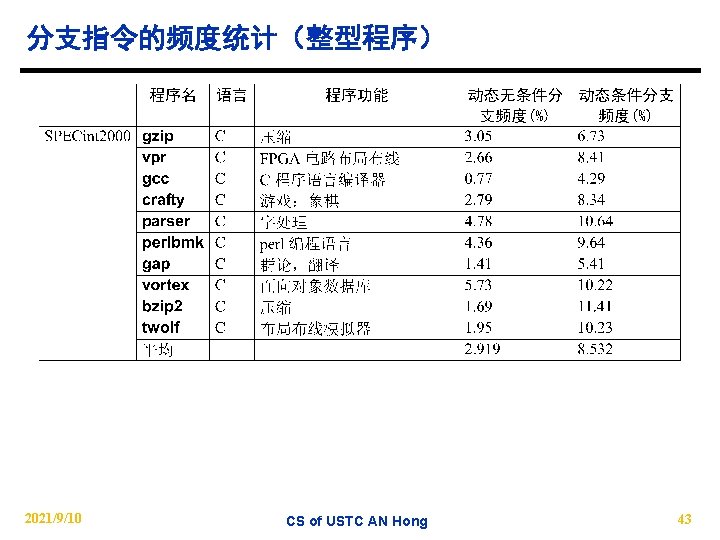
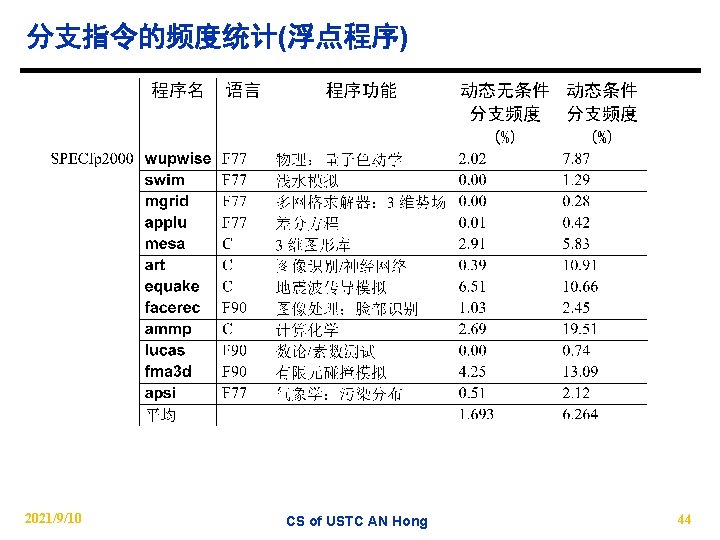
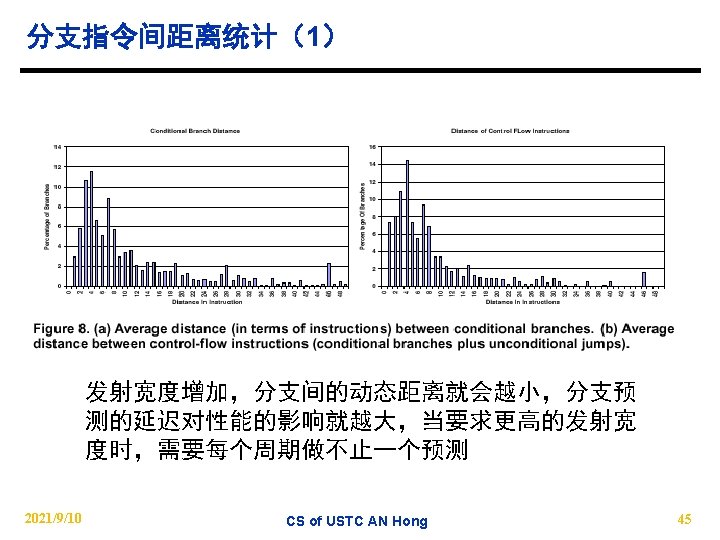
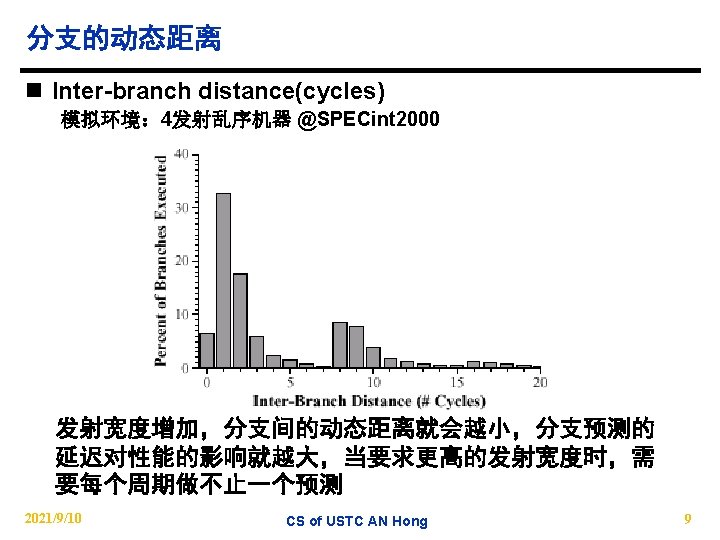
 l. Inter branch distance(cycles) 模拟环境: 4发射乱序机器 @SPECint 2000 2021/9/10 CS of USTC AN")



 2021/9/10 CS of USTC AN Hong 50")
- Slides: 50
Lecture on High Performance Processor Architecture (CS 05162) Control Hazard and Solution An Hong han@ustc. edu. cn Fall 2007 University of Science and Technology of China Department of Computer Science and Technology CS of USTC AN Hong
Outline n What’s the Problem from Von Neumann Programming Model n A Taxonomy of Speculation Execution Techniques n What’s Control Hazard and Solution? n What makes Control Speculation possible? 2021/9/10 CS of USTC AN Hong 2
What’s the Problem? n Von Neumann Programming Model − Instructions are fetched, and then executed in the order in which they appear in a program − A program is a static sequence of instructions produced by a programmer or by a compiler. l A compiler translates static sequences of high-level language into static sequences of lower-level instructions − A machine(processor) executes a dynamic sequence of events based on the static sequence of instructions in the program. n Programs contain four primary types of instructions: − Data movement instructions(called Loads and Stores) − Data processing instructions (e. g. , add, subtract, multiply, AND, OR, etc. ) − Branch instructions − Environmental instructions 2021/9/10 CS of USTC AN Hong 3
What’s the Problem? n There are two fundamental restrictions in von Neumann programming model, which limit the amount of instruction level parallelism(ILP) that can be extracted from sequential programs − A control flow, which dynamically determined the sequences in which these manipulations were done − A data flow, which did the physical manipulation of the data values 2021/9/10 CS of USTC AN Hong 4
A Taxonomy of Speculation Execution Techniques What can we speculate on? Speculative Execution Control Speculation Branch Direction (binary) Data Speculation Data Location Aliased (binary) Branch Target (multi valued) Address(multi valued) Data Value (multi valued) What makes speculation possible? 2021/9/10 CS of USTC AN Hong 5
Branch Instruction Semantics n 例: BEQ rs, rt, offset if R[rs] == R[rt] then PC< PC+offset n If <condition> Then Go. To <address> − <condition>: specifies some bits that can be set by other instruction; − <address>: is the address of a place in the program to which instruction sequencing is diverted if <condition> is true n Unconditional branch: <condition> is the constant value true, then the branch is always taken − E. g. : Jump n Conditional branch: <condition> is variable , may or may not be true 2021/9/10 CS of USTC AN Hong 6
What’s the Problem? 例: BEQ rs, rt, offset if R[rs] == R[rt] then PC< PC+offset Need address here bne r 2, #0, r 3 NT add r 4, r 5, r 6 Instruction Fetch T sub r 7, r 8, r 9 Branch Delay Compute address here Decode Execute n分支处理问题可划分为两个子问题 −决定分支的方向(分支条件相关) −对需要跳转的分支,使执行延迟最小化 -> 尽快 获得转移的目标地址(分支地址相关) 2021/9/10 CS of USTC AN Hong Memory Access Writeback 7
Control Hazard Solution(1): Stall Add Beq Reg Mem Lost potential Mem Reg ALU Load Mem ALU O r d e r Time (clock cycles) ALU I n s t r. Mem Reg n Stall: wait until decision is clear n Impact: 2 lost cycles (i. e. 3 clock cycles per branch instruction) => slow 2021/9/10 CS of USTC AN Hong 11
Control Hazard Solution (2): Delayed Branch Misc Load Mem Reg Mem Reg ALU Beq Reg ALU Add Mem ALU O r d e r Time (clock cycles) ALU I n s t r. Mem Reg n Delayed Branch: Redefine branch behavior (takes place after next instruction) n Impact: 0 clock cycles per branch instruction if can find instruction to put in “slot” ( 50% of time) n As launch more instruction per clock cycle, less useful 2021/9/10 CS of USTC AN Hong 12
Delayed Branches(Delay slot,延迟槽) n One or more instructions after branch get executed regardless of whether branch taken add r 2, r 3, r 4 sub r 7, r 8, r 9 bne r 5, #0, r 10 add r 2, r 3, r 4 (delay slot) (stall) sub r 7, r 8, r 9 (delay slot) (stall) div r 2, r 1, r 7 NOTE: Here, branch delay is 2 cycle. n Exposes branch delay to compiler 2021/9/10 CS of USTC AN Hong 13
Delayed Branches(Delay slot,延迟槽) n Pros: − Low Hardware Cost n Cons: − Depends on compiler to fill delay slots l Ability to fill delay slots drops as # of slots increases − Exposes implementation details to compiler l Can’t change pipeline without breaking software compatibility l Can’t add to existing architecture and retain compatibility 2021/9/10 CS of USTC AN Hong 15
Control Hazard Solution (3): 软件循环展开减少分支指令 n 例:向量的每个元素加常数 For (j=1; j<=1000; j++) x[j]=x[j]+s; 编译: 整数寄存器R 1:循环计数器,初值为向量中最高端地址元素的地址 浮点寄存器F 2:保存常数s 1 Loop: LD F 0, 0(R 1) ; F 0=vector element 2 ADD F 4, F 0, F 2 ; add scalar in F 2 3 SD 0(R 1), F 4 ; store result 4 SUBI R 1, 8 ; decrement pointer 8 B (DW) 5 BNEZ R 1, Loop ; branch R 1!=zero 2021/9/10 CS of USTC AN Hong 16
每次循环都有数据相关/控制相关引起的停顿 1 Loop: LD F 0, 0(R 1) 2 stall 3 ADDD F 4, F 0, F 2 4 stall 5 stall 6 SD 0(R 1), F 4 7 SUBI R 1, 8 8 BNEZ R 1, Loop 9 stall Instruction producing result FP ALU op Load double ; F 0=vector element ; add scalar in F 2 ; store result ; decrement pointer 8 B (DW) ; branch R 1!=zero ; delayed branch slot Instruction using result Another FP ALU op Store double FP ALU op Latency in clock cycles 3 2 1 n 每次循环需要 9 clocks n Rewrite code to minimize stalls? 2021/9/10 CS of USTC AN Hong 17
静态调度的例子 1 Loop: LD F 0, 0(R 1) 2 stall 3 ADDD F 4, F 0, F 2 4 SUBI R 1, 8 5 BNEZ R 1, Loop 6 SD 8(R 1), F 4 ; delayed branch ; altered when move past SUBI (1) Put SUBI to ADDD’s first stall slot (2) Addjust the displacement of SD from 0(R 1) to 8(R 1) (3) Swap BNEZ and SD by changing address of SD n 每次循环需要 6 clocks n Unroll loop (循环展开) 4 times code to make faster? 2021/9/10 CS of USTC AN Hong 18
循环展开+寄存器重命名(Register Renaming)的例子 重命名前 1 Loop: LD 2 ADDD 3 SD 4 LD 2 ADDD 3 SD 7 LD 8 ADDD 9 SD 10 LD 11 ADDD 12 SD 13 SUBI 14 BNEZ 15 NOP F 0, 0(R 1) F 4, F 0, F 2 0(R 1), F 4 F 0, -8(R 1) F 4, F 0, F 2 -8(R 1), F 4 F 0, -16(R 1) F 4, F 0, F 2 -16(R 1), F 4 F 0, -24(R 1) F 4, F 0, F 2 -24(R 1), F 4 R 1, #32 R 1, LOOP 重命名后 1 Loop: LD 2 ADDD 3 SD 4 LD 5 ADDD 6 SD 7 LD 8 ADDD 9 SD 10 LD 11 ADDD 12 SD 13 SUBI 14 BNEZ 15 NOP F 0, 0(R 1) F 4, F 0, F 2 0(R 1), F 4 F 6, -8(R 1) F 8, F 6, F 2 -8(R 1), F 8 F 10, -16(R 1) F 12, F 10, F 2 -16(R 1), F 12 F 14, -24(R 1) F 16, F 14, F 2 -24(R 1), F 16 R 1, #32 R 1, LOOP n 寄存器重命名的目的是避免引入新的WAW和WAR数据相关 2021/9/10 CS of USTC AN Hong 19
循环展开+寄存器重命名(Register Renaming)的例子 1 Loop: LD 2 ADDD 3 SD 4 LD 5 ADDD 6 SD 7 LD 8 ADDD 9 SD 10 LD 11 ADDD 12 SD 13 SUBI 14 BNEZ 15 NOP F 0, 0(R 1) F 4, F 0, F 2 0(R 1), F 4 F 6, -8(R 1) F 8, F 6, F 2 -8(R 1), F 8 F 10, -16(R 1) F 12, F 10, F 2 -16(R 1), F 12 F 14, -24(R 1) F 16, F 14, F 2 -24(R 1), F 16 R 1, #32 R 1, LOOP 1 cycle stall Rewrite loop to 2 cycles stall ; drop SUBI & BNEZ minimize stalls? ; drop SUBI & BNEZ ; alter to 4*8 15 + 4 x (1+2) = 27 clock cycles, or 6. 8 per iteration Assumes R 1 is multiple of 4 2021/9/10 CS of USTC AN Hong 20
静态调度减少停顿, 减少分支的例子 1 Loop: LD 2 LD 3 LD 4 LD 5 ADDD 6 ADDD 7 ADDD 8 ADDD 9 SD 10 SD 11 SD 12 SUBI 13 BNEZ 14 SD F 0, 0(R 1) F 6, -8(R 1) F 10, -16(R 1) F 14, -24(R 1) F 4, F 0, F 2 F 8, F 6, F 2 F 12, F 10, F 2 F 16, F 14, F 2 0(R 1), F 4 -8(R 1), F 8 -16(R 1), F 12 R 1, #32 R 1, LOOP 8(R 1), F 16 n What assumptions made when moved code? − OK to move store past SUBI even though changes register − OK to move loads before stores: get right data? − When is it safe for compiler to do such changes? ; 8 -32 = -24 14 clock cycles, or 3. 5 per iteration When safe to move instructions? 2021/9/10 CS of USTC AN Hong 21
Control Hazard Solution(5): Prediction Beq Load Reg Mem Reg ALU Add Mem ALU O r d e r Time (clock cycles) ALU I n s t r. Mem Reg n Predict: guess one direction then back up if wrong n Impact: 0 lost cycles per branch instruction if right, 1 if wrong (right 50% of time) n More dynamic scheme: history of 1 branch ( 90%) 2021/9/10 CS of USTC AN Hong 23
Control Hazard Solution(5): Prediction n 单通路执行/多通路执行分支预测 − Single path execution − full eager execution − disjoint eager execution. 7 . 34 . 24 . 17 . 21 . 09 (b) 完全急进执行 . 21 . 49 . 10 . 34 . 07 . 05 . 24 (a) 单通路推测执行 2021/9/10 . 21 . 15 . 12 . 49 . 3 . 49 . 7 . 3 . 21 . 15 . 10 (c) dis-joint 急进执行 CS of USTC AN Hong 25
Static Prediction n Predict whether branches will be taken before execution (compile time) n Predict Branch Not Taken − Execute successor instructions in sequence − “Squash” instructions in pipeline if branch actually taken − Advantage of late pipeline state update − 47% DLX branches not taken on average − PC+4 already calculated, so use it to get next instruction n Predict Branch Taken − 53% DLX branches taken on average − But haven’t calculated branch target address in DLX l DLX still incurs 1 cycle branch penalty l Other machines: branch target known before outcome 2021/9/10 CS of USTC AN Hong 26
Static Prediction n Pros: good performance for loops n Cons: bad performance for data dependent branches if (a == 0) b = 3; else b = 4; 2021/9/10 CS of USTC AN Hong 27
高性能分支处理机制的任务 Branch outcome and other info 用于指导预测 Predicted direction (taken/not taken) Branch Predictor Program Counter (PC) Predicted target address (where the branch is going) Predicting where the next instruction is in the instruction stream. 2021/9/10 CS of USTC AN Hong 31
分支目标缓存(BTB, Branch Target Buffer) n Store branch address and predicted target (last target) − only store targets for taken branches − can combine with any prediction scheme 2021/9/10 CS of USTC AN Hong 32
Example: BHT with BTB n Address of branch index to get prediction AND branch address (if taken) − Must check for branch match now, since can’t use wrong branch address − Grab predicted PC from table since may take several cycles to compute n Update predicted PC when branch is actually resolved n Return instruction addresses predicted with stack PC of instruction FETCH BHT Branch PC Predicted PC (Branch Address) (Taken Target Address) =? 2021/9/10 Predict taken or untaken CS of USTC AN Hong 33
Example: PAg with BTB 2021/9/10 CS of USTC AN Hong 34
控制推测执行机制的分类 n Not predict − no branch prediction(block pipeline) Intel 8086 − loop buffer(a very small I Cache) Intel 80386 − delayed branches(delay slots) − eager execution(EE) IBM 360/91, Sun Super. Sparc l the number of paths grow exponentially l unlimited resources l not predictable branch, the branch direction changes in an irregular fashion − disjoint eager execution(DEE) l Alone l with minimal control dependencies(MCD) 2021/9/10 CS of USTC AN Hong 35
推测执行机制的分类 n Predict − Static(at compile time, via software) l Always not taken Intel 80486 l Always taken Super. Sparc l Backward taken; Forward not taken(BTFN) HP PA-7 x 00 l Semistatic(Profiling) Early Power. PC − Dynamic(at runtime, via hardware ) l 1 bit DEC Alpha 21064, AMD-K 5 l 2 bit Next. Gen 586, Power. PC 604, Cyrix 6 x 86, Cyrix. M 2, MIPS R 10000 l Two-level adaptive P 6, AMD-K 6 l Selector(local/global) DEC Alpha 21264 − Hybrid (combining static and dynamic scheme) ? − Multiscalar Pentium IV ? 2021/9/10 CS of USTC AN Hong 36
推测执行机制的分类 n Others − Predication alone − Predication with software − VLIW 2021/9/10 CS of USTC AN Hong Denelcor HEP Cydrome Cydra 5, P 6 Itanium 37
术语 n 预测率(Prediction Rate)或预测精度(Branch Prediction Accurary, BPA) − dynamic percentage of branches which are predicted correctly n 误预测率(Misprediction Rate) − dynamic percentage of branches that are not predicted correctly n 误预测代价(Misprediction Penalty) − Delay when a branch is not predicted correctly (squash ops, refill pipeline) n Taken Delay − Delay when a taken branch is correctly predicted n Not taken (fall through) Delay − Delay when a not taken branch is correctly predicted. 2021/9/10 CS of USTC AN Hong 38
间接分支(call/return) n Predicting return jumps from subroutines is hard 2021/9/10 CS of USTC AN Hong 41
返回地址栈(Return Address Stack) n Hardware stack for subroutine return addresses n Push return address (in HW) when make call n Pop return address to exit n Most programs don’ t have deep call trees,can use small stack(e. g. 32 entries) 2021/9/10 CS of USTC AN Hong 42
分支指令间距离统计(2) l. Inter branch distance(cycles) 模拟环境: 4发射乱序机器 @SPECint 2000 2021/9/10 CS of USTC AN Hong 46
分支的可预测性分析(4) 2021/9/10 CS of USTC AN Hong 50