Lecture on High Performance Processor Architecture CS 05162
 Technology, Applications, Frontier Problems and Research")

&众核 (Manycore) 2021/10/17 USTC CS AN Hong 3")








: 4 -bit processor, 2312 transistors,")





















 2021/10/17 USTC CS AN Hong 34")
 n 1. Finite State Machine n Claim: parallel arch. ,")



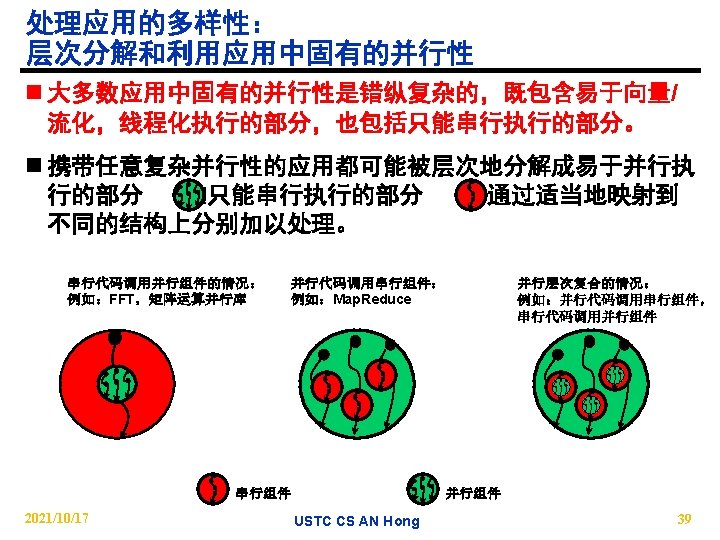


 and")

 vs. Manycore (64, 128…)?")
 CPUs,")





 n 768 = 12 32")






 n Program Sequencing − Sequence through static representation of program")







 be designed to be easier to use efficienctly")
- Slides: 66
Lecture on High Performance Processor Architecture (CS 05162) Technology, Applications, Frontier Problems and Research Directions An Hong han@ustc. edu. cn Fall 2009 School of Computer Science and Technology University of Science and Technology of China USTC CS AN Hong
Outline n The Challenges and Opportunities of the Multi. Core/Many-Core System − The state-of-the-art of multi-core and many-core − What are multi-core and many-core? − Why multi-core and many-core? − Problem with Performance, Technology, Power, Frequency and Programming − What is the fundamental issue that multiple cores faced? 2021/10/17 USTC CS AN Hong 2
CPU芯片结构的大趋势:单核->多核(Multicore)&众核 (Manycore) 2021/10/17 USTC CS AN Hong 3
Multicore Products Nowadays n Lots of dual-core products now: − Intel: Pentium D and Pentium Extreme Edition, Core Duo, Woodcrest, Montecito − IBM Power 5, 6, 7 − AMD Opteron / Athlon 64 − Sun Ultra. SPARC IV. n Systems with more than two cores are here with more coming: − IBM Cell (asymmetric). l 1 core Power. PC plus 8 “synergistic processing elements”. − Sun Niagara l 8 cores, 4 hyper-threaded threads per core. − n. Vidia l General Purpose Computation on Graphics Processors (GPGPU) − Intel expects to produce 16 - or even 32 -core chips within a decade. 2021/10/17 USTC CS AN Hong 4
Architecture of Dual-Core Chips n INTEL CORE DUO − Two physical cores in a package − Each with its own execution resources − Each with its own L 1 cache l 32 K instruction and 32 K data − Both cores share the L 2 cache l 2 MB 8 -way set associative; 64 -byte line size l 10 clock cycles latency; Write Back update policy FP Unit EXE Core L 1 Cache L 2 Cache System Bus (667 MHz, 5333 MB/s) n AMD Opteron − Separate 1 Mbyte L 2 caches − Improvement for Memory affinity and Thread affinity 2021/10/17 USTC CS AN Hong 5
Intel Multi-core Plan 2021/10/17 USTC CS AN Hong 6 6
Intel Multi-core Plan 2021/10/17 USTC CS AN Hong 7 7
Cell from IBM and Sony 2021/10/17 USTC CS AN Hong 8 8
Cell from IBM and Sony 2021/10/17 USTC CS AN Hong 9 9
Niagara from SUN 2021/10/17 USTC CS AN Hong 10 10
GPU Fundamentals: The Modern Graphics Pipeline Vertex Processor Geometry Processor Fragment Processor Graphics State GPU Shade Final Pixels (Color, Depth) Rasterize Fragments (pre-pixels) Assemble Primitives Screenspace triangles (2 D) Transform Xformed, Lit Vertices (2 D) CPU Vertices (3 D) Application Video Memory (Textures) Render-to-texture n. Programmable vertex processor! n. Programmable pixel processor! 2021/10/17 USTC CS AN Hong 11 11
Sea Change in Chip Design n Intel 4004 (1971): 4 -bit processor, 2312 transistors, 0. 4 MHz, 10 micron PMOS, 11 mm 2 chip n RISC II (1983): 32 -bit, 5 stage pipeline, 40, 760 transistors, 3 MHz, 3 micron NMOS, 60 mm 2 chip n 125 mm 2 chip, 0. 065 micron CMOS = 2312 RISC II+FPU+Icache+Dcache − RISC II shrinks to ~ 0. 02 mm 2 at 65 nm CMOS − Caches via DRAM or 1 transistor SRAM (www. t-ram. com) ? − Proximity Communication via capacitive coupling at > 1 TB/s ? (Ivan Sutherland @ Sun / Berkeley) Processor is the new transistor? 2021/10/17 USTC CS AN Hong 12
Era of multi-core and many-core is coming n Transistor count still rising n Clock speed stopped Increasing n Issues − Heat and Power − Complexity − Hard to exploit ILP n Intel’s multi-core and many-core roadmap Borkar, Dubey, Kahn, et al. “Platform 2015. ” Intel White Paper, 2005. 2021/10/17 USTC CS AN Hong 13
Multicore vs. Manycore n Multicore: 2 X / 2 yrs ≈ 64 cores in 8 years n Manycore: 8 X to 16 X multicore Automatic Parallelization, Thread Level Speculation 2021/10/17 USTC CS AN Hong 14 14
Technology Trends: Microprocessor Capacity 2 X transistors/Chip Every 1. 5 years, called “Moore’s Law” Microprocessors have become smaller, denser, and more powerful. Not just processors, bandwidth, storage, etc 2021/10/17 n. Dr. Gordon E. Moore co-founded Intel in 1968. n. Gordon Moore (co-founder of Intel in 1968), His observation in 1965 that number of transistors doubled roughly every 18 months became known as “Moore’s Law” USTC CS AN Hong 15 15
Moore’s Law Still Holds n No Exponential is Forever, but perhaps we can Delay it Forever 2021/10/17 USTC CS AN Hong 17
What is the fundamental issue that multiple cores faced ? n Writing correct and efficient parallel programs is very difficult and time consuming Parallel programming = Decomposition of computation in tasks + Assignment of tasks to threads + Orchestration of data access, comm, synch. + Mapping threads to cores n Designing easy-to-implement and scalable and adaptive microarchitecture is very challenging Multiple Cores Arch. = Computing Arch. + Communication Arch. = Cores/Processors Arch. + On-chip Memory Arch. + On-chip Interconnection and I/O Arch. 2021/10/17 USTC CS AN Hong 25
4 Steps in creating and executing a parallel program on multiprocessor system architecture n Decomposition of computation in tasks n Assignment of tasks to processes n Orchestration of data access, comm, synch. n Mapping processes to processors 2021/10/17 USTC CS AN Hong 26
UC Bekeley的观点: 七个关键问题 2021/10/17 USTC CS AN Hong 27
A view from UC Berkeley: seven critical questions for 21 st century parallel computing 2008 -8 -24 2021/10/17 USTC CS AN Hong 28
7 Questions for Parallelism n Applications: − 1. What are the apps? − 2. What are kernels of apps? n Hardware: − 3. What are the HW building blocks? − 4. How to connect them? n Programming Model & Systems Software: − 5. How to describe apps and kernels? − 6. How to program the HW? n Evaluation: − 7. How to measure success? 2021/10/17 USTC CS AN Hong 29
Par Lab Research Overview Easy to write correct programs that run efficiently on manycore p p A tio a lic y t i v ti c u r d o Pr Laye cy n e i c i Eff ayer L OS. h Arc 2021/10/17 Personal Image Hearing, Parallel Speech Health Retrieval Music Browser Dwarfs Composition & Coordination Language (C&CL) C&CL Compiler/Interpreter Parallel Libraries Efficiency Languages Parallel Frameworks Sketching Static Verification Type Systems Directed Testing Autotuners Dynamic Legacy Communication & Schedulers Checking Code Synch. Primitives Efficiency Language Compilers Debugging OS Libraries & Services with Replay Legacy OS Hypervisor Intel Multicore/GPGPU Correctness ns RAMP Manycore USTC CS AN Hong 30
7 Questions for Parallelism n Applications: − 1. What are the apps? − 2. What are kernels of apps? n Hardware: − 3. What are the HW building blocks? − 4. How to connect them? n Programming Model & Systems Software: − 5. How to describe apps and kernels? − 6. How to program the HW? n Evaluation: − 7. How to measure success? 2021/10/17 USTC CS AN Hong 31
Apps and Kernels Tower: What are the problems? n Who needs 100 s of cores? − Failure of imagination? (CS education? ) − Need compelling apps that use 100 s of cores n What about parallel benchmarks? − Few examples (e. g. , SPLASH, NAS) l Optimized to old models, languages, architectures… n How invent parallel systems of future when tied to old code, programming models of the past? 2021/10/17 USTC CS AN Hong 32
Can find patterns widely used? n Look for common patterns of communication and computation − 1. Embedded Computing (EEMBC benchmark) − 2. Desktop/Server Computing (SPEC 2006) − 3. Data Base / Text Mining Software l Advice from Jim Gray of Microsoft and Joe Hellerstein of UC − 4. Games/Graphics/Vision − 5. Machine Learning l Advice from Mike Jordan and Dan Klein of UC Berkeley − 6. High Performance Computing (Original “ 7 Dwarfs”) n Result: 13 “Dwarfs” 2021/10/17 USTC CS AN Hong 33
Dwarf Popularity (Red Hot, Blue Cool) 2021/10/17 USTC CS AN Hong 34
13 Dwarfs (so far) n 1. Finite State Machine n Claim: parallel arch. , lang. , compiler … must do at least these well to do future parallel apps well n 2. Combinational Logic n 3. Graph Traversal n 4. Structured Grids n 5. Dense Linear Algebra n Note: Map. Reduce is embarrassingly parallel; perhaps FSM is embarrassingly sequential? n 6. Sparse Linear Algebra n 7. Spectral Methods (FFT) n 8. Dynamic Programming n 9. N-Body Methods n 10. Map. Reduce n 11. Back-track/Branch & Bound n 12. Graphical Model Inference n 13. Unstructured Grids 2021/10/17 USTC CS AN Hong 35
Application-Driven Research vs. CS Solution. Driven Research n Drill down on 4 app areas to guide research agenda n Dwarfs to represent broader set of apps to guide research agenda n Dwarfs help break through traditional interfaces − Benchmarking, multidisciplinary conversations, target for libraries, and parallelizing parallel research 2021/10/17 USTC CS AN Hong 36
7 Questions for Parallelism n Applications: − 1. What are the apps? − 2. What are kernels of apps? n Hardware: − 3. What are the HW building blocks? − 4. How to connect them? n Programming Model & Systems Software: − 5. How to describe apps and kernels? − 6. How to program the HW? n Evaluation: − 7. How to measure success? 2021/10/17 USTC CS AN Hong 37
How do we program the HW? What are the problems? n For parallelism to succeed, must provide productivity, efficiency, and correctness simultaneously for scalable hardware − Can‟t make SW productivity even worse! − Why do in parallel if efficiency doesn‟t matter? − Correctness usually considered orthogonal problem − Productivity slows if code incorrect or inefficient n Most programmers not ready to produce correct parallel programs − IBM SP customer escalations: concurrency bugs worst, can take months to fix 2021/10/17 USTC CS AN Hong 38
How do we describe apps and kernels? n Observation: Use Dwarfs are of 2 types n Algorithms in the dwarfs can either be implemented as: − Compact parallel computations within a traditional library l Dense matrices, Sparse matrices, Spectral, Combinational, Finite state machines − Compute/communicate pattern implemented as pattern/framework l Map. Reduce, Graph traversal, graphical models, Dynamic programming, Backtracking/B&B, N-Body, (Un) Structured Grid n Computations may be viewed a multiple levels: e. g. , an FFT library may be built by instantiating a Map-Reduce framework, mapping 1 D FFTs and then transposing (generalize reduce) 2021/10/17 USTC CS AN Hong 40
Ensuring Correctness n Productivity Layer: − Enforce independence of tasks using decomposition (partitioning) and copying operators − Goal: Remove concurrency errors (nondeterminism from execution order, not just low level data races) l E. g. , the race-free program “atomic delete” + “atomic insert” does not compose to an “atomic replace”; need higher level properties, not solved with transactions (or locks) n Efficiency Layer: Check for subtle concurrency bugs (races, deadlocks, and so on) − Mixture of verification and automated directed testing − Error detection on framework and libraries; some techniques applicable to third-party software 2021/10/17 USTC CS AN Hong 42
7 Questions for Parallelism n Applications: − 1. What are the apps? − 2. What are kernels of apps? n Hardware: − 3. What are the HW building blocks? − 4. How to connect them? n Programming Model & Systems Software: − 5. How to describe apps and kernels? − 6. How to program the HW? n Evaluation: − 7. How to measure success? 2021/10/17 USTC CS AN Hong 43
Hardware Tower: What are the problems? n Multicore (2, 4…) vs. Manycore (64, 128…)? n How can novel architectural support improve productivity, efficiency, and correctness for scalable hardware? − Efficiency instead of performance to capture energy as well as performance n Also, power, design and verification costs, low yield, higher error rates 2021/10/17 USTC CS AN Hong 44
HW Solution: Small is Beautiful n Expect modestly pipelined (5 -to 9 -stage) CPUs, FPUs, vector, SIMD PEs − Small cores not much slower than large cores n Parallel is energy efficient path to performance: CV 2 F − Lower threshold and supply voltages lowers energy per op n Redundant processors can improve chip yield − Cisco Metro 188 CPUs + 4 spares; Sun Niagara sells 6 or 8 CPUs n Small, regular processing elements easier to verify n One size fits all? − Amdahl‟s Law �Heterogeneous processors − Special function units to accelerate popular functions 2021/10/17 USTC CS AN Hong 45
HW features supporting Parallel SW n Want Composable Primitives, Not Packaged Solutions − Transactional Memory is usually a Packaged Solution n Partitions n Fast Barrier Synchronization & Atomic Fetch-and-Op n Active messages plus user-level event handling − Used by parallel language runtimes to provide fast communication, synchronization, thread scheduling n Configurable Memory Hierarchy (Cell v. Clovertown) − Can configure on-chip memory as cache or local store − Programmable DMA to move data without occupying CPU − Cache coherence: Mostly HW but SW handlers for complex cases − Hardware logging of memory writes to allow rollback 2021/10/17 USTC CS AN Hong 46
Partitions n Partition: hardware-isolated group − Chip divided into hardwareisolated partition, under control of supervisor software − User-level software has almost complete control of hardware inside partition − Power-of-2 size, naturally aligned Infini. Core chip with 16 x 16 tile array 2021/10/17 USTC CS AN Hong 47
7 Questions for Parallelism n Applications: − 1. What are the apps? − 2. What are kernels of apps? n Hardware: − 3. What are the HW building blocks? − 4. How to connect them? n Programming Model & Systems Software: − 5. How to describe apps and kernels? − 6. How to program the HW? n Evaluation: − 7. How to measure success? 2021/10/17 USTC CS AN Hong 48
Measuring Success: What are the problems? n 1. Only companies can build HW, and it takes years n 2. Software people don’t start working hard until hardware arrives − 3 months after HW arrives, SW people list everything that must be fixed, then we all wait 4 years for next iteration of HW/SW n 3. How to quickly get 100 -1000 CPU systems in hands of researchers to let them innovate in algorithms, compilers, languages, OS, architectures, … ASAP? n 4. Can avoid waiting 4 years + 3 months between HW/SW iterations? 2021/10/17 USTC CS AN Hong 49
Build Academic Manycore from FPGAs n As ~10 CPUs will fit in Field Programmable Gate Array (FPGA), 1000 -CPU system from 100 FPGAs? − 8 32 -bit simple “soft core” RISC at 100 MHz in 2004 (Virtex-II) − FPGA generations every 1. 5 yrs; � 2 X CPUs, � 1. 2 X clock rate n HW research community does logic design (“gate shareware”) to create out-of-the-box, Manycore − E. g. , 1000 processor, standard ISA binary-compatible, 64 -bit, cachecoherent supercomputer @ � 150 MHz/CPU in 2007 − Ideal for heterogeneous chip architectures − RAMPants: 10 faculty at Berkeley, CMU, MIT, Stanford, Texas, and Washington n “Research Accelerator for Multiple Processors” as a vehicle to lure more researchers to parallel challenge and decrease time to parallel salvation 2021/10/17 USTC CS AN Hong 50
768 CPU “RAMP Blue” (Wawrzynek, Krasnov, … at Berkeley) n 768 = 12 32 -bit RISC cores / FPGA, 4 FGPAs/board, 16 boards, $10 k/bd − Simple Micro. Blaze soft cores @ 90 MHz l Full star-connection between modules − 1008 node RAMP Blue soon (21 boards) n NASA Advanced Supercomputing (NAS) Parallel Benchmarks (all class S) − UPC versions (C plus shared-memory abstraction) CG, EP, IS, MG; DEMO? n RAMPants creating HW & SW for many-core community using next gen FPGAs − Chuck Thacker & Microsoft designing next boards − 3 rd party to manufacture and sell boards: 1 H 08 2021/10/17 USTC CS AN Hong 51
Why do we care RAMP? n Traditional simulators proved to be inefficient − Four years and many millions of dollars to prototype a new architecture in hardware − Software engineers are ineffective with simulators until the new hardware actually shows up − Feedback from software engineers can not impact the immediate next generation n RAMP use Field-Programmable Gate Arrays (FPGAs) to emulate highly parallel architectures at hardware speeds. It is a practical approach to modularizing the model, separation of the functional and timing aspects of the simulation − Fast enough − Easy to “tape out” a design everyday − Can include research features that would be impractical or impossible to include in real hardware systems 2021/10/17 USTC CS AN Hong 52
Why do we care RAMP? 2008 -8 -20 2021/10/17 USTC CS AN Hong 53
The Stanford Pervasive Parallelism Laboratory Vision Virtual Worlds Rendering DSL Autonomous Vehicle Physics DSL Scripting DSL Financial Services Probabilistic DSL Analytics DSL Parallel Object Language Common Parallel Runtime Explicit / Static Implicit / Dynamic Hardware Architecture SIMD Cores OOO Cores Scalable Interconnects 2021/10/17 Partitionable Hierarchies Scalable Coherence USTC CS AN Hong Threaded Cores Isolation & Atomicity Pervasive Monitoring 54
Summary: A Berkeley View 2. 0 n Our industry has bet its future on parallelism (!) n Goal: Productive, Efficient, Correct Parallel Programs while doubling number of cores every 2 years (!) n Try Apps-Driven vs. CS Solution-Driven Research − Laptop-Handhelds/Datacenters as modern Client/Server n 13 Dwarfs as lingua franca , anti-benchmarks n Composition is critical to parallel computing success − Composition is open problem for Transactional Memory n Productivity layer for ≈90% today’s programmers − Use C&C Lang to reuse expert‟s code n Efficiency layer for ≈10% today’s programmers − Create libraries, frameworks, … for use in productivity layer n Autotuners over Parallelizing Compilers n OS & HW: Composable Primitives over CS Solutions 2021/10/17 USTC CS AN Hong 55
The Computing Problem n Aspect 1: computation representation − How to create a static representation for the desired computation? l HLL, compilers, instruction set, etc. n Aspect 2: program execution ! ! ! − How is the dynamic computation recreated and performed? l Program Execution model and microarchitecture n Aspect 3: Interface − How are “program external”interactions performed? l OS and run time environment 10 s billion transistors on a chip can (fundamentally) change Aspect 2? How might change in Aspect 2 affect Aspects 1 and 3? 2021/10/17 USTC CS AN Hong 57
Program Execution (Aspect 2) n Program Sequencing − Sequence through static representation of program to create dynamic stream of operations − Q: How to create the dynamic sequence of operations from the static representation? n Operation Execution − Execute operations in the dynamic stream l Determine dependence relationships l Schedule operations for execution l Execute operations l Communicate values − Q: How to perform the effects of the operation? Higher performance means speeding up the above 2021/10/17 USTC CS AN Hong 58
Impact on Aspect 1 n What does the static program representation look like? n How does static representation impact software used to create it ? − e. g. , compilers,HLL,ISA 2021/10/17 USTC CS AN Hong 59
Impact on Aspect 3 n Operating systems allow a program to interact with external entities n Existing Operating system mindset is sequential execution, i. e. , single sequencer, with little or no speculation n Operating system mindset will have to change to adapt to the multiple sequencer, heavily speculative hardware − what does it mean to handle multiple exceptions simultaneously? − what does it mean to handle exceptions speculatively? 2021/10/17 USTC CS AN Hong 60
Key architectural question Can single-Chip Multiprocessors(CMP) be designed to be easier to use efficienctly than today’s MPs? 2021/10/17 USTC CS AN Hong 66