Compression of documents Paolo Ferragina Dipartimento di Informatica













 Problem: We have two files fknown and fnew (known to both")
 located")

 Problem: Constructing G is very costly, n 2 edge calculations")



 n simple, widely used, single roundtrip n optimizations: 4 -byte")
, clients checks")
 Server sends hashes to client per levels Client checks")
- Slides: 30
Compression of documents Paolo Ferragina Dipartimento di Informatica Università di Pisa
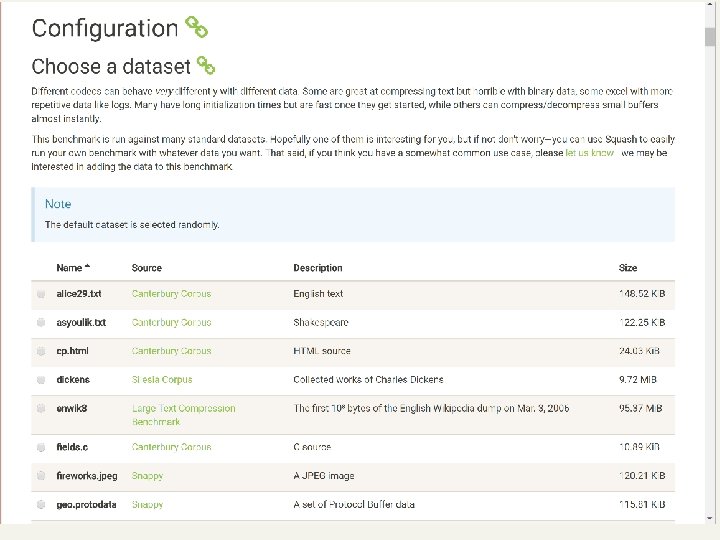
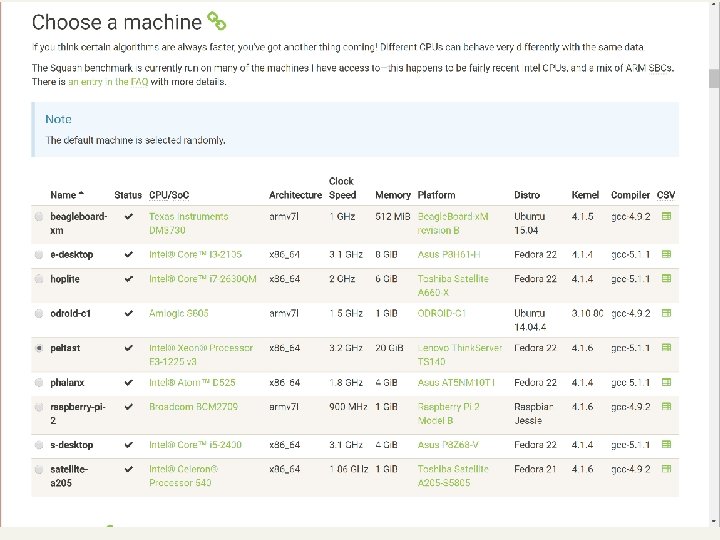
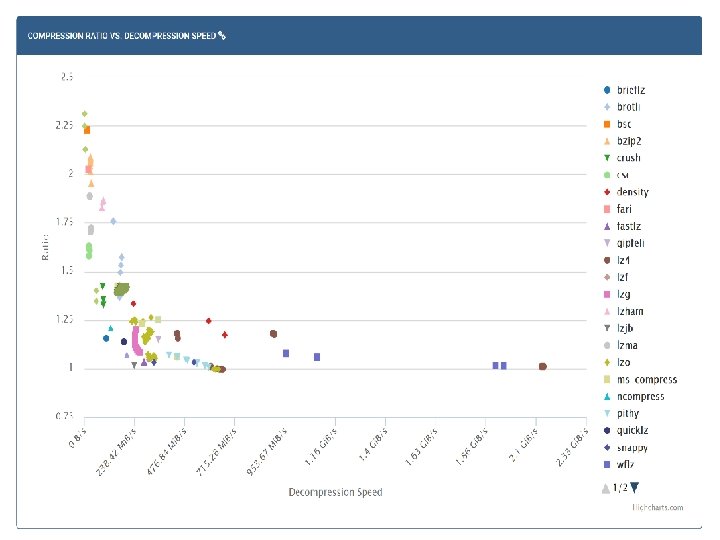
Raw docs are needed
LZ 77 a a c a b c a a a a c <6, 3, a> Dictionary (all substrings starting here) a a c a b c a a a a c c <3, 4, c> Algorithm’s step: n n Output <dist, len, next-char> Advance by len + 1 A buffer “window” has fixed length and moves
Example: LZ 77 with window a a c a b a a a c (0, 0, a) a a c a b a a a c (1, 1, c) a a c a b c a b a a a c (3, 3, a) a a c a b a a a c (1, 2, c) Window size = 6 Longest match within W Next character Gzip -1…-9
LZ 77 Decoding Which is faster in decompression among gzip -1…-9 ? Decoder keeps same dictionary window as encoder. n n Finds substring <len, dist, char> in previously decoded text Inserts a copy of it What if len > dist ? (overlap with text to be compressed) n E. g. seen = abcd, next codeword is <2, 9, e> for (i = 0; i < len; i++) out[cursor+i] = out[cursor-d+i] n Output is correct: abcdcdcdce
You find this at: www. gzip. org/zlib/
Transfer + Decompression
https: //quixdb. github. io/squash-benchmark/
Compression & Networking
Background knowledge about data at receiver data sender receiver Ø network links are getting faster and faster but Ø many clients still connected by fairly slow links (mobile? ) Ø people wish to send more and more data Ø battery life is a king problem how can we make this transparent to the user?
Two standard techniques n n caching: “avoid sending the same object again” n Done on the basis of “atomic” objects n Thus only works if objects are unchanged n How about objects that are slightly changed? compression: “remove redundancy in transmitted data” n avoid repeated substrings in transmitted data n can be extended to history of past transmissions n How if the sender has never seen data at receiver ? (overhead)
Types of Techniques n Common knowledge between sender & receiver n n Unstructured file: delta compression “partial” knowledge n n Unstructured files: file synchronization Record-based data: set reconciliation
Formalization n Delta compression n n n Compress file f deploying known file f’ Compress a group of files Speed-up web access by sending differences between the requested page and the ones available in cache File synchronization n [diff, zdelta, REBL, …] [rsynch, zsync] Client updates its old file fold with fnew available on a server Mirroring, Shared Crawling, Content Distr. Net Set reconciliation n n Client updates its structured file fold with file fnew available on server Update of contacts or appointments, intersect IL in P 2 P search engine
Z-delta compression (one-to-one) Problem: We have two files fknown and fnew (known to both parties) and the goal is to compute a file fd of minimum size such that fnew can be derived from fknown and fd n Assume that block moves and copies are allowed n Find an optimal covering set of fnew based on fknown n LZ 77 -scheme provides and efficient, optimal solution n fknown is “previously encoded text”, compress fknownfnew starting from fnew n zdelta is one of the best implementations n Uses e. g. in Version control, Backups, and Transmission.
Efficient Web Access Dual proxy architecture: pair of proxies (client cache + proxy) located on each side of the slow link use a proprietary protocol to increase comm perf Client Cache reference n request Slow-link Delta-encoding Proxy reference request Fast-link web Page Use zdelta to reduce traffic: n Old version is available at both proxies (one on client cache, and one on proxy) n Restricted to pages already visited (30% cache hits), or URL-prefix match Small cache
Cluster-based delta compression Problem: We wish to compress a group of files F n Useful on a dynamic collection of web pages, back-ups, … n Apply pairwise zdelta: find a good reference for each f F n Reduction to the Min Branching problem on DAGs n Build a (complete? ) weighted graph GF, nodes=files, weights= zdelta-size n Insert a dummy node connected to all, and weights are gzip-coding n Compute the directed spanning tree of min tot cost, covering G’s nodes. 2000 620 90 2 20 123 20 220 3 1 5 space time uncompr 30 Mb --- tgz 20% linear THIS 8% quadratic
Improvement (group of files) Problem: Constructing G is very costly, n 2 edge calculations (zdelta exec) n We wish to exploit some pruning approach n Collection analysis: Cluster the files that appear similar and thus good candidates for zdelta-compression. Build a sparse weighted graph G’F containing only edges between pairs of files in the same cluster n Assign weights: Estimate appropriate edge weights for G’F thus saving zdelta execution. Nonetheless, strict n 2 time space time uncompr 260 Mb --- tgz 12% 2 mins THIS 8% 16 mins
File Synchronization
File synch: The problem request f_new update Server n request to update an old file server n n n Client client n n f_old has new file but does not know the old file updates f_old without sending the entire f_new rsync: file synch tool, distributed with Linux Delta compression is a sort of local synch Since the server knows both files
The rsync algorithm few hashes f_new Server encoded file f_old Client
The rsync algorithm (contd) n simple, widely used, single roundtrip n optimizations: 4 -byte rolling hash + 2 -byte MD 5, gzip for literals n choice of block size problematic (default: max{700, √n} bytes) n not good in theory: granularity of changes may disrupt use of blocks
A new framework: zsync Server sends hashes (unlike the client in rsync), clients checks them Server deploys the common fref to compress the new ftar (rsync compress just it).
Small differences (e. g. agenda) Server sends hashes to client per levels Client checks equality with hash-substrings Log n/k levels match n/k blocks of k elems each If d differences, then on each level d hashes not match, and need to continue Communication complexity is O(d lg(n/k) * lg n) bits [1 upward path per different k-block]