Web search engines Paolo Ferragina Dipartimento di Informatica

Web search engines Paolo Ferragina Dipartimento di Informatica Università di Pisa

Two main difficulties The Web: Extracting “significant data” is difficult !! n Size: more than tens of billions of pages n Language and encodings: hundreds… n Distributed authorship: SPAM, format-less, … n Dynamic: in one year 35% survive, 20% untouched The User: Matching “user needs” is difficult !! n Query composition: short (2. 5 terms avg) and imprecise n Query results: 85% users look at just one result-page n Several needs: Informational, Navigational, Transactional

Evolution of Search Engines n First generation -- use only on-page, web-text data n n 1995 -1997 Alta. Vista, Excite, Lycos, etc Second generation -- use off-page, web-graph data n n n Word frequency and language Link (or connectivity) analysis Anchor-text (How people refer to a page) 1998: Google Third generation -- answer “the need behind the query” n n n Focus on “user need”, rather than on query Integrate multiple data-sources Click-through data Google, Yahoo, MSN, ASK, ……… Fourth generation Information Supply [Andrei Broder, VP emerging search tech, Yahoo! Research]

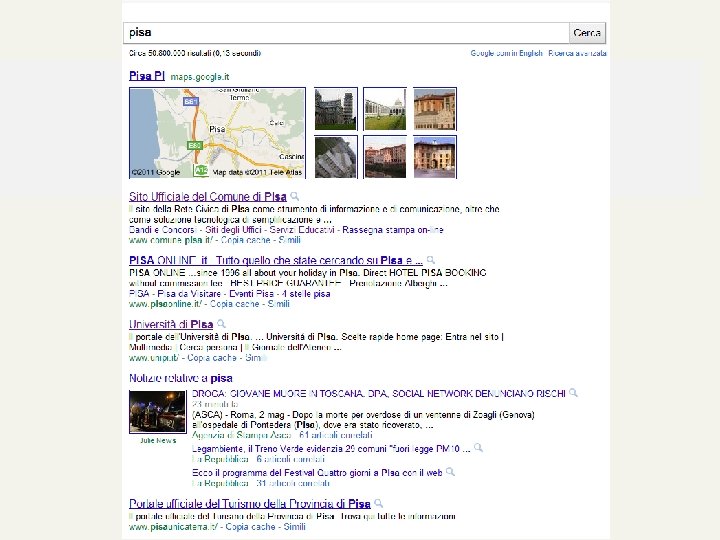

2009 -12
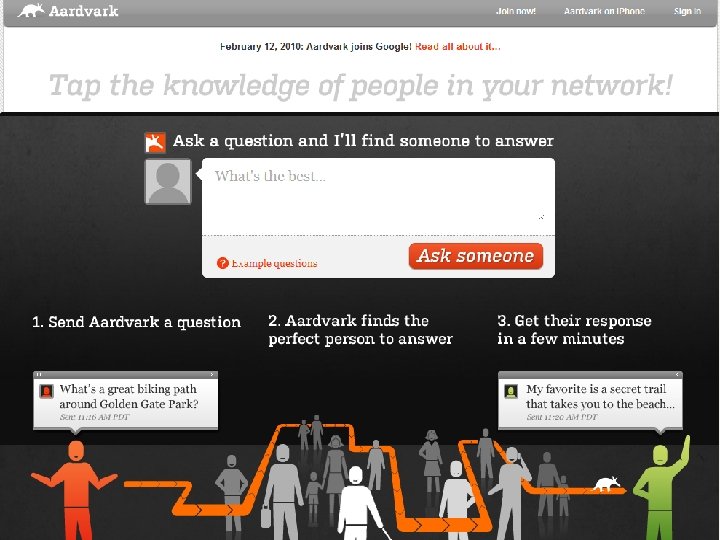
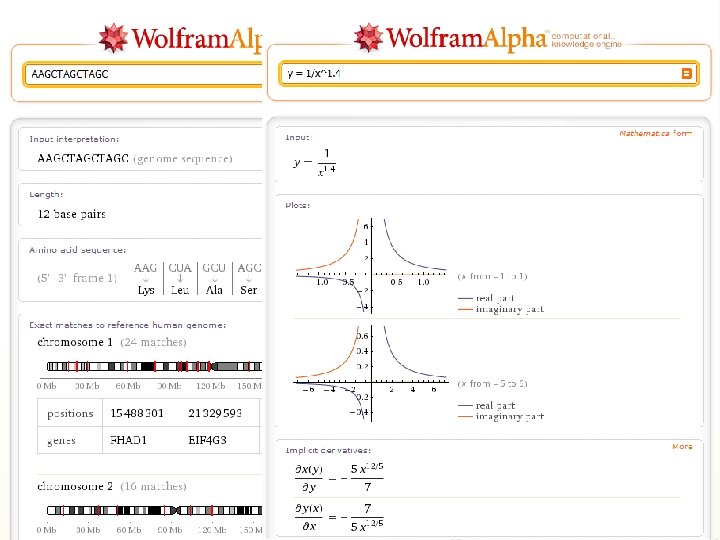

This is a search engine!!!

II° generation IV° generation

Quality of a search engine Paolo Ferragina Dipartimento di Informatica Università di Pisa Reading 8

Is it good ? n How fast does it index n n n How fast does it search n n Number of documents/hour (Average document size) Latency as a function of index size Expressiveness of the query language

Measures for a search engine n All of the preceding criteria are measurable n The key measure: user happiness …useless answers won’t make a user happy

Happiness: elusive to measure n Commonest approach is given by the relevance of search results n n How do we measure it ? Requires 3 elements: 1. 2. 3. A benchmark document collection A benchmark suite of queries A binary assessment of either Relevant or Irrelevant for each query-doc pair

Evaluating an IR system n Standard benchmarks n TREC: National Institute of Standards and Testing (NIST) has run large IR testbed for many years n Other doc collections: marked by human experts, for each query and for each doc, Relevant or Irrelevant L On the Web everything is more complicated since we cannot mark the entire corpus !!

General scenario collection Retrieved Relevant

Precision vs. Recall n n Precision: % docs retrieved that are relevant [issue “junk” found] Recall: % docs relevant that are retrieved [issue “info” found] collection Retrieved Relevant

How to compute them n n Precision: fraction of retrieved docs that are relevant Recall: fraction of relevant docs that are retrieved Relevant Not Relevant tp (true positive) fp (false positive) (false negative) tn (true negative) Not Retrieved fn n n Precision P = tp/(tp + fp) Recall R = tp/(tp + fn)
 by retrieving")
Some considerations n n n Can get high recall (but low precision) by retrieving all docs for all queries! Recall is a non-decreasing function of the number of docs retrieved Precision usually decreases

Precision-Recall curve n n We measures Precision at various levels of Recall Note: it is an AVERAGE over many queries precision x x x recall x

A common picture precision x x x recall x
: n People usually use balanced F")
F measure n Combined measure (weighted harmonic mean): n People usually use balanced F 1 measure n n i. e. , with = ½ thus 1/F = ½ (1/P + 1/R) Use this if you need to optimize a single measure that balances precision and recall.

The web-graph: properties Paolo Ferragina Dipartimento di Informatica Università di Pisa Reading 19. 1 and 19. 2
")
The Web’s Characteristics n Size n 1 trillion of pages is available (Google 7/08) n n 50 billion static pages 5 -40 K per page => terabytes & terabytes Size grows every day!! Change n n 8% new pages, 25% new links change weekly Life time of about 10 days

The Bow Tie
 n n Set of nodes such that")
Some definitions n Weakly connected components (WCC) n n Set of nodes such that from any node can go to any node via an undirected path. Strongly connected components (SCC) n Set of nodes such that from any node can go to any node via a directed path. WCC SCC

Find the CORE Iterate the following process: n n n Pick a random vertex v Compute all nodes reached from v: O(v) Compute all nodes that reach v: I(v) Compute SCC(v): = I(v) ∩ O(v) Check whether it is the largest SCC If the CORE is about ¼ of the vertices, after 20 iterations, Pb to not find the core < 1% (given that the graph is available).
 2) 3) 4) DFS(G) Transpose G in GT")
Compute SCCs n Classical Algorithm: 1) 2) 3) 4) DFS(G) Transpose G in GT DFS(GT) following vertices in decreasing order of the time their visit ended at step 1. Every tree is a SCC. DFS is hard to compute on disk: no locality
![DFS Classical Approach main(){ foreach vertex v do color[v]=WHITE end. For foreach vertex v](http://slidetodoc.com/presentation_image/72583f09e80f2b00b27193a8ab1f1f7f/image-30.jpg "DFS Classical Approach main(){ foreach vertex v do color[v]=WHITE end. For foreach vertex v")
DFS Classical Approach main(){ foreach vertex v do color[v]=WHITE end. For foreach vertex v do if (color[v]==WHITE) DFS(v); end. For } DFS(u: vertex) color[u]=GRAY d[u] time +1 foreach v in succ[u] do if (color[v]=WHITE) then p[v] u DFS(v) end. For color[u] BLACK f[u] time + 1
 • Array of successors")
Semi-External DFS • Bit array of nodes (visited or not) • Array of successors • Stack of the DFS-recursion Key observation: If bit-array fits in internal memory than a DFS takes |V| + |E|/B disk accesses.

What about million/billion nodes? NO Key observation: A forest is a DFS forest if and only if there are no FORWARD CROSS edges among the non-tree edges Algorithm ? Construct incrementally a tentative DFS forest which minimizes the # of those edges (overall), in passes. . .
 • Array of")
A Semi-External DFS • Bit array of nodes (visited or not) • Array of successors (stack of the DFS-recursion) Key assumption: We assume that 2 n edges, and the auxiliary data structures, fit in memory. Rearrange nodes in adj-lists, the ones with large subtrees go to

Observing Web Graph n n n We do not know which percentage of it we know The only way to discover the graph structure of the web is via large scale crawls Warning: the picture might be distorted by n n n Size limitation of the crawl Crawling rules Perturbations of the "natural" process of birth and death of nodes and links

Why is it interesting? n Largest artifact ever conceived by the human n Exploit its structure of the Web for n n n Crawl strategies Search Spam detection Discovering communities on the web Classification/organization Predict the evolution of the Web n Sociological understanding

Many other large graphs… n Physical network graph n n n The “cosine” graph (undirected, weighted) n n n V = static web pages E = semantic distance between pages Query-Log graph (bipartite, weighted) n n n V = Routers E = communication links V = queries and URL E = (q, u) u is a result for q, and has been clicked by some user who issued q Social graph (undirected, unweighted) n n V = users E = (x, y) if x knows y (facebook, address book, email, . . )

The size of the web Paolo Ferragina Dipartimento di Informatica Università di Pisa Reading 19. 5

What is the size of the web ? n Issues n The web is really infinite n n Dynamic content, e. g. , calendar Static web contains syntactic duplication, mostly due to mirroring (~30%) Some servers are seldom connected Who cares? n n Media, and consequently the user Engine design

What can we attempt to measure? n The relative sizes of search engines n n Document extension: e. g. engines index pages not yet crawled, by indexing anchor-text. Document restriction: All engines restrict what is indexed (first n words, only relevant words, etc. ) The coverage of a search engine relative to another particular crawling process. n

Relative Size from Overlap Given two engines A and B Sec. 19. 5 Sample URLs randomly from A Check if contained in B and vice versa AÇB = (1/2) * Size A AÇB = (1/6) * Size B (1/2)*Size A = (1/6)*Size B Size A / Size B = (1/6)/(1/2) = 1/3 Each test involves: (i) Sampling URL (ii) Checking URL

Sampling URLs n n Ideal strategy: Generate a random URL and check for containment in each index. Problem: Random URLs are hard to find! Approach 1: Generate a random URL surely contained in a given search engine Approach 2: Random walks or random IP addresses

#1: Random URL in SE via random queries n Generate random query: n n Lexicon: 400, 000+ words from a web crawl Conjunctive Queries: w 1 and w 2 e. g. , vocalists AND rsi n n Get 100 result URLs from engine A Choose a random URL as the candidate to check for presence in search engine B (next slide) This induces a probability weight W(p) for each page. Conjecture: W(SEA) / W(SEB) ~ |SEA| / |SEB|

URL checking n Download D at address URL. n n Get list of words. Use 8 low frequency words as AND query to B Check if D is present in result set. Problems: n n n Near duplicates Engine time-outs Is 8 -word query good enough?

Advantages & disadvantages n n Statistically sound under the induced weight. Biases induced by random query n Query bias: Favors content-rich pages in the language(s) of the lexicon n n Ranking bias [Solution: Use conjunctive queries & fetch all] Query restriction bias: engine might not deal properly with 8 words conjunctive query n n Malicious bias: Sabotage by engine Operational Problems: Time-outs, failures, engine inconsistencies, index modification.

#2: Random IP addresses n Find a web server at the given IP address n If there’s one n Collect all pages from server n From this, choose a page at random

Advantages & disadvantages n Advantages n n n Clean statistics Independent of crawling strategies Disadvantages n Many hosts might share one IP, or not accept requests n No guarantee all pages are linked to root page, and thus can be collected. n Power law for # pages/hosts generates bias towards

Conclusions n No sampling solution is perfect. Lots of new ideas. . . . but the problem is getting harder n n Quantitative studies are fascinating and a good research problem

The web-graph: storage Paolo Ferragina Dipartimento di Informatica Università di Pisa Reading 20. 4
 n V = URLs, E = (u,")
Definition Directed graph G = (V, E) n V = URLs, E = (u, v) if u has an hyperlink to v Isolated URLs are ignored (no IN & no OUT) Three key properties: n Skewed distribution: Pb that a node has x links is 1/x , ≈ 2. 1

The In-degree distribution Altavista crawl, 1999 Web. Base Crawl 2001 Indegree follows power law distribution This is true also for: out-degree, size components, . . .
 n V = URLs, E = (u,")
Definition Directed graph G = (V, E) n V = URLs, E = (u, v) if u has an hyperlink to v Isolated URLs are ignored (no IN, no OUT) Three key properties: n Skewed distribution: Pb that a node has x links is 1/x , ≈ 2. 1 n Locality: usually most of the hyperlinks point to other URLs on the same host (about 80%). n Similarity: pages close in lexicographic order tend to share many outgoing lists

A Picture of the Web Graph j i 21 millions of pages, 150 millions of links

URL-sorting Berkeley Stanford

Front-compression of URLs + delta encoding of IDs Front-coding
 = {s 1 -x,")
The library Web. Graph Uncompressed adjacency list Successor list S(x) = {s 1 -x, s 2 -s 1 -1, . . . , sk-sk-1 -1} For negative entries: Adjacency list with compressed gaps (locality)

Copy-lists: successors Reference chains close nodes sharemany possibly limited Uncompressed adjacency list Adjacency list with copy lists (similarity) Each bit of the copy-list informs whether the corresponding successor of y is also a successor of the reference x; The reference index is chosen in [0, W] that gives the best compression.
 Adjacency list with copy lists. Adjacency list with copy blocks (RLE")
Copy-blocks = RLE(Copy-list) Adjacency list with copy lists. Adjacency list with copy blocks (RLE on bit sequences) 1, 3 The first copy block is 0 if the copy list starts with 0; Each RLE-length is decremented by one for all blocks The last block is omitted (we know the length from Outd);
 Extra-nodes: Compressing Intervals Adjacency list")
This is a Java and C++ lib (≈3 bits/edge) Extra-nodes: Compressing Intervals Adjacency list with copy blocks. Consecutivity in extra-nodes 3 0 = (15 -15)*2 (positive) Intervals: encoded by left extreme and length 2 = (23 -19)-2 (jump >= 2) Int. length: decremented by Lmin = 2 600 = (316 -16)*2 Residuals: differences between residuals, 12 = (22 -16)*2 (positive) or the source (the first) 3018 = 3041 -22 -1 (difference)
- Slides: 58