awk shell programming http www kame co kr
com 인사이트")










 문자열 출력 예제")



![pattern: REGEX v /REGEX/ 를 이용하여 조건 사용 $ awk '/C[A-Z]-[0 -9 A-Z]+/ {print}'](https://slidetodoc.com/presentation_image_h/995a072f4f2c917c73532193ad2c1dbc/image-17.jpg "pattern: REGEX v /REGEX/ 를 이용하여 조건 사용 $ awk '/C[A-Z]-[0 -9 A-Z]+/ {print}'")



 v BEGIN 사용 방식 $ awk 'BEGIN {FS=\": \"} (NR ==")
 v BEGIN, END를 이용한 계산 $ cat pi. awk BEGIN {")

![flow control Flow control statement Desc. if (conditional) {statement_list 1} [else {statement_list 2}] C-style](https://slidetodoc.com/presentation_image_h/995a072f4f2c917c73532193ad2c1dbc/image-25.jpg "flow control Flow control statement Desc. if (conditional) {statement_list 1} [else {statement_list 2}] C-style")


 v 2번째 과목의 평균 계산 $ cat avg. awk $0 !~ /^#.")

는 x의 길이를 리턴한다. $ awk -F: '(length($2)<11 && NR>1) {printf \"%d:")
![function: string function name description gsub(r, s[, t]) 정규표현식 r과 매치되는 문자열 t를 s로](https://slidetodoc.com/presentation_image_h/995a072f4f2c917c73532193ad2c1dbc/image-31.jpg "function: string function name description gsub(r, s[, t]) 정규표현식 r과 매치되는 문자열 t를 s로")

![function: date, time function description systime() UNIX epoch timestamp를 리턴한다. strftime([fmt [, timestamp]]) C-style](https://slidetodoc.com/presentation_image_h/995a072f4f2c917c73532193ad2c1dbc/image-34.jpg "function: date, time function description systime() UNIX epoch timestamp를 리턴한다. strftime([fmt [, timestamp]]) C-style")



![Practice : function : gensub v gensub(regex, replace, how [, target var. ]) $](https://slidetodoc.com/presentation_image_h/995a072f4f2c917c73532193ad2c1dbc/image-38.jpg "Practice : function : gensub v gensub(regex, replace, how [, target var. ]) $")
 v substitution function - backreference를 지원하는 gensub $")

 v test_posixopt. txt (posixoptions manpage 참조) _POSIX_ADVISORY_INFO _POSIX_ASYNCHRONOUS_IO")
 v Makefile # Makefile AWK = awk OUT")

- Slides: 43
awk / shell programming 김선영 가메 출판사 http: //www. kame. co. kr sunyzero@gmail(dot)com 인사이트 http: //blog. insightbook. co. kr 버 저자블로그 http: //sunyzero. tistory. com 전: 2014 -12 -22
awk syntax, practice
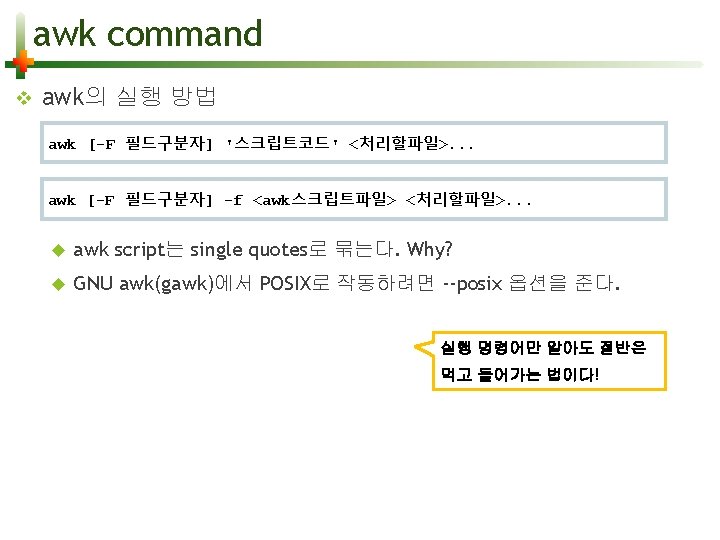
awk CLI v data file : account. txt # UNIX ACCOUNT : No. 00704 sunyzero: Sunyoung Kim: 1600: AA-1342 R: 010 -2007 -8080: 19991222 ppan: Peter Pan: 1200: CC-0100 R: 010 -3593 -1277: 19921202 clyde 47: John Smith: 650: CC-1106 R: 010 -6532 -1004: 20000123 banaba: John Kennis: 1100: CA-0971 R: 010 -4321 -1234: 20000123 jamtaeng: Jambo Park: 880: AD-1000 R: 010 -6420 -3578: 19970802 $ awk -F : '{print $1, $4; }' account. txt # UNIX ACCOUNT sunyzero AA-1342 R ppan CC-0100 R clyde 47 CC-1106 R banaba CA-0971 R jamtaeng AD-1000 R -F : # field separator $1, $4 # fields print 명령은 자동 개행!
awk script file v data file : account. txt $ cat pr_1 a 4. awk { print $1, $4 } comma의 역할은? print $1 $4로 해보자 $ awk -F : -f pr_1 a 4. awk account. txt # UNIX ACCOUNT sunyzero AA-1342 R ppan CC-0100 R clyde 47 CC-1106 R banaba CA-0971 R jamtaeng AD-1000 R -f file # script filename
awk script block v 조건/패턴이 true일 때 { command; . . . } 실행 [ condition or pattern ] { command; . . . } $ awk -F : 'NR>1 { printf "%s(%s)n", $1, $2 }' account. txt sunyzero(Sunyoung Kim) ppan(Peter Pan) clyde 47(John Smith) banaba(John Kennis) jamtaeng(Jambo Park) NR>1 # Line number printf # formating
printf: practice 숫자 출력 예제
printf: practice (con't) 문자열 출력 예제
awk field v field 선택 $ awk -F: 'NR>1 {var=$2; $2=$3; $3=var; print}' account. txt sunyzero 1600 Sunyoung Kim AA-1342 R 010 -2007 -8080 19991222 ppan 1200 Peter Pan CC-0100 R 010 -3593 -1277 19921202 clyde 47 650 John Smith CC-1106 R 010 -6532 -1004 20000123 banaba 1100 John Kennis CA-0971 R 010 -4321 -1234 20000123 jamtaeng 880 Jambo Park AD-1000 R 010 -6420 -3578 19970802 2 th, 3 th 필드의 스왑 awk variable string, integer, real number 모두 지원
Pratice v 조건 적용하여 출력해보자. $ awk 'NR>1 {printf "%d: %sn", NR-1, $1}' account. txt 1: sunyzero: Sunyoung 2: ppan: Peter 3: clyde 47: John 4: banaba: John 5: jamtaeng: Jambo $ awk -F: 'NR>1 {printf "%d: %sn", NR-1, $1}' account. txt 1: sunyzero 2: ppan 3: clyde 47 4: banaba 5: jamtaeng
awk pattern v 패턴 형식 pattern {. . } /regular expression/ relational expression pattern && pattern || pattern ? pattern : pattern (pattern) ! pattern 1, pattern 2 range 패턴은 데이터 파일을 처리하는데 유용하다.
pattern: REGEX v /REGEX/ 를 이용하여 조건 사용 $ awk '/C[A-Z]-[0 -9 A-Z]+/ {print}' account. txt ppan: Peter Pan: 1200: CC-0100 R: 010 -3593 -1277: 19921202 clyde 47: John Smith: 650: CC-1106 R: 010 -6532 -1004: 20000123 banaba: John Kennis: 1100: CA-0971 R: 010 -4321 -1234: 20000123 $ awk -F: '$4 ~ /C[A-Z]-[0 -9 A-Z]+/ {print}' account. txt ppan: Peter Pan: 1200: CC-0100 R: 010 -3593 -1277: 19921202 clyde 47: John Smith: 650: CC-1106 R: 010 -6532 -1004: 20000123 banaba: John Kennis: 1100: CA-0971 R: 010 -4321 -1234: 20000123
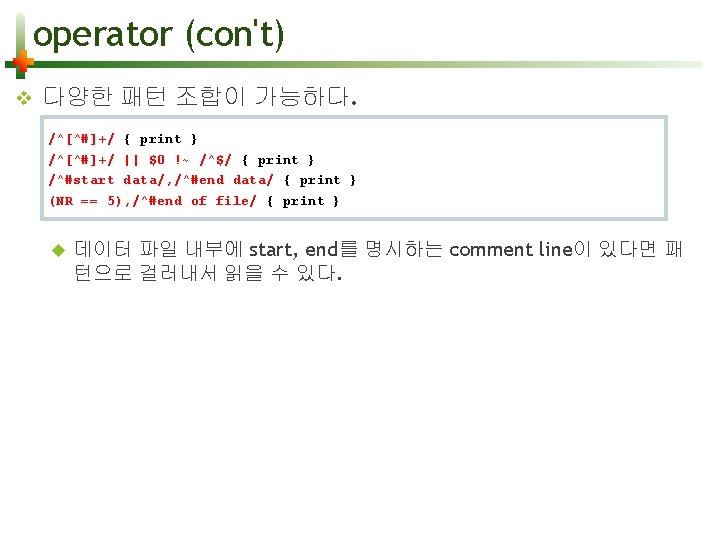
operator Operator ==, != < <== > ? : Description Example equality operator, not equal to $1=="Fred", $4!=NF less than $1<$3 less than or equal to $1<=$1+NR greater than $10>100 Condition operator (equal to C) ~ contain regular expressions (match) $4~/LOC/ , $9~/[A-Z]/ !- Dose not contain regular expression $9!~/. . [a-z]/
BEGIN, END v BEGIN 연산이 일어나기 에 수행 v initialization, pre-processing 작업 END 연산이 끝난 뒤에 수행 주로 출력을 수행한다. BEGIN { action } pattern { action }. . . END { action }
BEGIN, END (con't) v BEGIN 사용 방식 $ awk 'BEGIN {FS=": "} (NR == 3), (NR == 10)' /etc/passwd v END 사용 방식 $ awk 'END { print NR }' /etc/passwd 34 $ wc -l /etc/passwd 34 /etc/passwd
BEGIN, END (con't) v BEGIN, END를 이용한 계산 $ cat pi. awk BEGIN { print "Pi (numerical integration method)" } { n_steps = $1; sz_step = 1. 0/n_steps; sum=0. 0; } END { for (i=0; i<n_steps; i++) { atan 2() - arc-tangent in radians angle x = (i+0. 5) * sz_step; sum += 4. 0/(1. 0 + x*x); } printf("n_steps = %d, sz_step = %. 8 fn", n_steps, sz_step); printf("pi = %. 8 f, 4*atan(1) = %. 8 fn", sz_step*sum, atan 2(1, 1)*4); } $ time echo 2000000 | awk -f pi. awk Pi (numerical integration method) n_steps = 2000000, sz_step = 0. 00000050 pi = 3. 14159265, 4*atan(1) = 3. 14159265 real user sys 0 m 0. 546 s 0 m 0. 544 s 0 m 0. 001 s
flow control Flow control statement Desc. if (conditional) {statement_list 1} [else {statement_list 2}] C-style if while (conditional) {statement_list} C-style while for (init; condition; ctrl) {statement_list} C-style for loop break 루프를 종료시키고 다음 statement로 넘어가게 한다. continue 현재 위치에서 루프의 다음 iteration으로 넘어가게 한다. next 현재 input line에 대해서 남아있는 pattern을 skip exit 남아있는 input을 모두 skip한다. 만일 END pattern이 있다면 처리한 후 awk를 종료시킨다.
print , var control print control statement expr_list에 있는 expression을 stdout이나 특정 파일로 리다이렉트 한다. file은 file descriptor를 사용한다. print [expr_list] [>file] C언어의 printf문과 동일 printf format [, expr_list] [>file] 포맷된 형식의 expression을 보여준다. 출력은 위와 같다. sprintf (format [, expression]) C언어의 sprintf처럼 버퍼에 리턴하기만 하고, 출력하 지 않는다. 변수에 저장할 때 사용한다. assignment statement variable=awk_expr awk expr에서 나온 expression을 variable에 할당한다. printf의 default precision은 6자리이다. userdefined fd는 3 -19까지 사용 가능하다.
Practice v 합산 계산, 새로운 필드 할당 $ cat score. txt #name: math 1: math 2: datastructure: algorithm Jack, 78, 45, 68, 49 Mick, 77, 32, 86, 67 Fred, 95, 55, 85, 62 Kim, 88, 42, 85, 60 $ awk -F, 'NR>1 { $6=$2+$3+$4+$5; print $0 }' score. txt Jack 78 45 68 49 240 Mick 77 32 86 67 262 6 th field는 새로 할당된 필드다. Fred 95 55 85 62 297 Kim 88 42 85 60 275 $ awk -F, '$0 !~ /^#. */ { $6=$2+$3+$4+$5; print $0 }' score. txt. . . 생략. . .
Practice (con't) v 2번째 과목의 평균 계산 $ cat avg. awk $0 !~ /^#. */ { sum += $3 } END { printf "math 2 avg = %. 2 fn", sum/(NR-1) } $ awk -F, -f avg. awk score. txt math 2 avg = 43. 50
Practice v System daemon의 Minor pagefault, RSS 계산 $ cat chk_sysdaemon. sh #!/bin/bash ps -eo user, uid, ppid, sz, rss, vsz, min_flt, maj_flt, cmd | awk ' BEGIN { n_ps=0; n_tot_minflt=0; n_tot_rss=0; } ($1 == "root") && ($4 == 1) { n_ps++; n_tot_minflt+=$8; n_tot_rss+=$6; } END { printf "---- Daemon process monitor ----n"; printf "Processest. Min. Page. Faultt. Total. RSSn"; printf "%9 d t %12 d t %7 dn", n_ps, n_tot_minflt, n_tot_rss; }'
function v length(x)는 x의 길이를 리턴한다. $ awk -F: '(length($2)<11 && NR>1) {printf "%d: %s, %sn", NR-1, $2}' account. txt 2: ppan, Peter Pan 3: clyde 47, John Smith 5: jamtaeng, Jambo Park
function: string function name description gsub(r, s[, t]) 정규표현식 r과 매치되는 문자열 t를 s로 대치한다. (t를 지정하지 않으면 $0 ; 문자열 자체가 변경되니 조심할 것!) * return value : 대치에 성공한 패턴 개수 (양수) index(str 1, str 2) Returns the starting position of str 2 in str 1. If str 2 is not present in str 1, then 0 is returned length(str) Returns the length of string str match(s, r) 문자열 s에서 정규표현식 r과 매치되는 부분의 위치를 넘겨준다 split(str, array[, sep]) 구분자 sep를 기준으로(default는 space) 문자열 str을 배열로 변환 sprintf(fmt, awk_exp) Returns the values of awk_exp formatted as defined by fmt sub(r, s[, t]) 정규표현식 r과 매치되는 문자열 t를 s로 대치한다. gsub와 다른점은 t에서 r과 매치되는 부분이 여러 개라 할지라도 처음 한 개만 대치한다는 것이다. * return value: 대치에 성공한 패턴 개수 (0 or 1) * gsub (global sub) * gawk는 gsub, sub의 general version인 gensub를 지원한다. * gawk는 strtonum()으로 base 진수로 표기된 문자열을 숫자로 변환할 수 있다.
function: string function name description Returns a substring of the string str starting at substr(str, start, length) position start for length characters ex) substr("believe", 3, 5) == "lieve" tolower(str) 문자열 str을 모두 소문자로 바꾼다 toupper(str) 문자열 str을 모두 대문자로 바꾼다
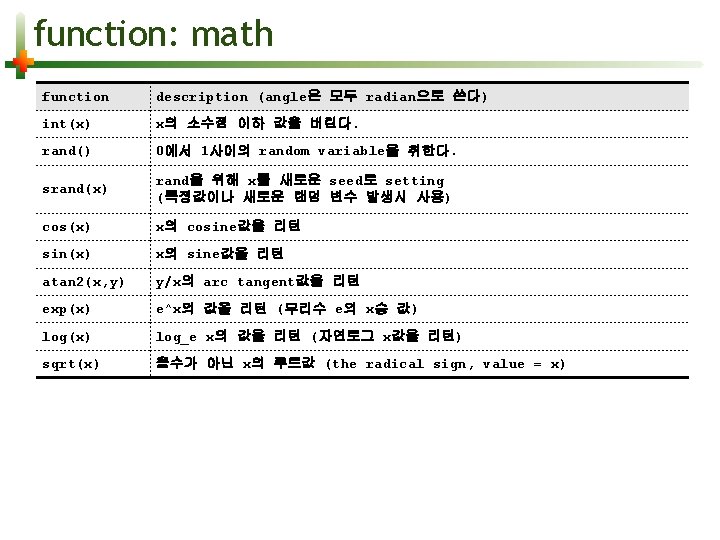
function: date, time function description systime() UNIX epoch timestamp를 리턴한다. strftime([fmt [, timestamp]]) C-style strftime $ awk 'BEGIN { print systime() }' 1400908965 $ awk 'BEGIN { print strftime("%Y%m%d-%H%M%S %z") }' 20140524 -143007 +0900
Practice : function : substr v substr - substring $ cat contdata. txt B 6011 KR 700538000100000038863900023400000023350000030310 B 6012 KR 7035760008000082690003844000003843000000140 B 6011 KR 7005930000001237900014410000014400000007510 B 6011 KR 7005930000001238240014410000014400000007270 B 6012 KR 70357600080000000126490003837000003836000000280 B 6011 KR 700538000100000038866300023400000023350000030310 $ awk 'substr($0, 6, 12) == "KR 7005380001" { print substr($0, 18, 12) }' contdata. txt 000000388639 000000388663
Practice : function : match v POSIX awk에서는 {n, m} 표현을 지원하지 않는다. $ gawk --re-interval 'match($0, /KR[0 -9]{10}/) { print substr($0, RSTART+3, RLENGTH-6) }' contdata. txt 005380 035760 005930 035760 005380 --re-interval 옵션 : REGEX interval expression을 지원 --re-interval 대신에 --posix 으로 실행해보자. gawk manual>>extensions in gawk Not in POSIX awk 참고
Practice : function : gsub, gensub v substitution function $ cat contdata. txt B 6011 KR 700538000100000038863900023400000023350000030310 B 6012 KR 7035760008000082690003844000003843000000140 B 6011 KR 7005930000001237900014410000014400000007510 B 6011 KR 7005930000001238240014410000014400000007270 B 6012 KR 70357600080000000126490003837000003836000000280 B 6011 KR 700538000100000038866300023400000023350000030310 $ awk --re-interval '{ sub(/KR 7[0 -9]{9}/, "###123456789"); print }' contdata. txt B 6011###12345678900000038863900023400000023350000030310 B 6012###123456789000082690003844000003843000000140 B 6011###1234567890000001237900014410000014400000007510 B 6011###1234567890000001238240014410000014400000007270 B 6012###1234567890000000126490003837000003836000000280 B 6011###12345678900000038866300023400000023350000030310
Practice : function : gensub v gensub(regex, replace, how [, target var. ]) $ awk '{ a=gensub(/([0 -9]+)/, "(\1)", "g"); print a}' /etc/passwd. . . 생략. . . sunyzero: x: (500): SY Kim: /home/sunyzero: /bin/bash $ awk '{ a=gensub(/([0 -9]+)/, "(\1)", "1"); print a}' /etc/passwd. . . 생략. . . sunyzero: x: (500): 500: SY Kim: /home/sunyzero: /bin/bash $ awk '{ a=gensub(/([0 -9]+)/, "(\1)", "2"); print a}' /etc/passwd. . . 생략. . . sunyzero: x: 500: (500): SY Kim: /home/sunyzero: /bin/bash gawk를 사용한다면 gensub는 매우 유용하다. * how : g (global) , index (replace the n-th field)
Practice : function : gensub (con't) v substitution function - backreference를 지원하는 gensub $ cat contdata. txt B 6011 KR 700538000100000038863900023400000023350000030310 B 6012 KR 7035760008000082690003844000003843000000140 B 6011 KR 7005930000001237900014410000014400000007510 B 6011 KR 7005930000001238240014410000014400000007270 B 6012 KR 70357600080000000126490003837000003836000000280 B 6011 KR 700538000100000038866300023400000023350000030310 $ awk --re-interval '{ a=gensub(/KR 7([0 -9]{9})/, "###\1", "g"); print a}' contdata. txt B 6011###00538000100000038863900023400000023350000030310 B 6012###035760008000082690003844000003843000000140 B 6011###005930000001237900014410000014400000007510 B 6011###005930000001238240014410000014400000007270 B 6012###0357600080000000126490003837000003836000000280 B 6011###00538000100000038866300023400000023350000030310 * gsub, sub는 backreference를 지원하지 못한다.
Practice : gen. source code v test_posixopt. awk BEGIN { cnt = 0 } # get posix options from file. { elem[cnt++] = $1; } # end; print them; generate C source code. END { for (i=0; i<=cnt; i++) { if (i == 0) { print "#include <unistd. h>n#include <stdio. h>nint main()n{n" } else if (i == cnt) { print "treturn 0; n}" } else { printf("#if %s > 0 Lntprintf("[O] %s\n"); n", elem[i]); printf("#elsentprintf("[X] %s\n"); n", elem[i]); printf("#endifn"); } } }
Practice : gen. source code (con't) v test_posixopt. txt (posixoptions manpage 참조) _POSIX_ADVISORY_INFO _POSIX_ASYNCHRONOUS_IO _POSIX_BARRIERS _POSIX_CLOCK_SELECTION _POSIX_CPUTIME. . . 생략. . .
Practice : gen. source code (con't) v Makefile # Makefile AWK = awk OUT = test_posixopt all: $(OUT). SUFFIXES: . PRECIOUS: . o %. c: %. awk $(AWK) -f $< $*. txt | tee $@ %: %. o $(CC) $< $(LOADLIBES) $(LDLIBS) -o $@ %. o: %. c $(CC) -c $(CFLAGS) $(CPPFLAGS) $< -o $@ clean: rm -f *. o core. * $(OUT)
shell variable v -v varname="$shell_var" $ $ msg="Hello unixer" var_r="unix" var_s="linux" echo $msg | awk '{gsub($var_r, $var_s); print}' $ echo $msg | awk -v r 1="$var_r" -v s 1="$var_s" '{gsub(r 1, s 1); print}'