Algoritmos paralelos Teo 1 Introduccin Glen Rodrguez Por


 se mide en: ¡")





 temperatura,")


 • Una")














 Granularidad")




 CPU “Ley de Moore” 100 10 1 µProc 60%/año Gap")


 ¡ n LINPACK Benchmark ¡ ¡")

- Slides: 38
Algoritmos paralelos Teo. 1: Introducción Glen Rodríguez
Por qué se necesita gran poder de cómputo?
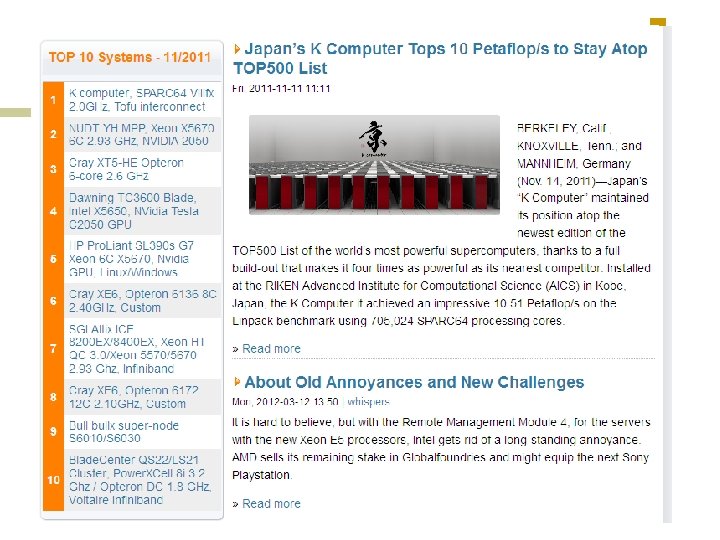
Unidades de medida en HPC n High Performance Computing (HPC) se mide en: ¡ ¡ ¡ n Flop: floating point operation Flops/s: floating point operations per second Bytes: para el tamaño de datos en memoria (una variable flotante de double precision ocupa 8 bytes) Generalmente hablamos de millones, billones, … Mega Giga Tera Peta Exa Zetta Yotta n Mflop/s = 106 flop/sec Gflop/s = 109 flop/sec Tflop/s = 1012 flop/sec Pflop/s = 1015 flop/sec Eflop/s = 1018 flop/sec Zflop/s = 1021 flop/sec Yflop/s = 1024 flop/sec Mbyte = 220 ~ 106 bytes Gbyte = 230 ~ 109 bytes Tbyte = 240 ~ 1012 bytes Pbyte = 250 ~ 1015 bytes Ebyte = 260 ~ 1018 bytes Zbyte = 270 ~ 1021 bytes Ybyte = 280 ~ 1024 bytes Ver en www. top 500. org la lista de supercomputadoras más veloces
A noviembre 2011
A noviembre 2011
Simulación: tercer pilar de la ciencia n n n Paradigma tradicional en Ciencia e Ingeniería: 1) Elaborar la teoría o crear un paper. 2) Hacer experimentos o construir un sistema. Limitaciones: ¡ Muy difícil – ej: grandes estructuras para experimentos. ¡ Muy caro – construir un auto o avión de pueba. ¡ Muy lento –verificar efecto de medicinas en animales. ¡ Muy peligroso -- armas, experimentos climáticos. Paradigma de la ciencia computacional: 3) Usar sistemas HPC para simular el fenómeno n Basandose en leyes físicas y en métodos numéricos.
Algunos Cómputos difíciles n Ciencia ¡ ¡ ¡ n Ingeniería ¡ ¡ ¡ n Diseño de semiconductores Terremotos y modelos de edificaciones Dinámica de fluidos por computadora (diseño de aviones) Combustión (diseño de motores) Simulación de choques de autos Negocios ¡ ¡ n Modelo del clima global Biología: genómica; “protein folding”; diseño de medicinas Modelos astrofísicos Química computacional Ciencia de los materiales por computadora Modelos económicos y financieros Proceso de transacciones, motores de búsqueda Defensa ¡ ¡ Test por simulación de armas nucleares Criptografía
Impacto económico de la HPC n Aerolíneas: ¡ ¡ n Optimización de logística a escala mundial en sistemas paralelos. Ahorros: aprox. $100 millones anuales por aerolínea. Diseño de autos: ¡ Las grandes compañías usan HPC (500 o más CPUs) para: n ¡ n Ahorros: aprox. $1000 millones al año. Industria de Semiconductores: ¡ Usan HPC grandes (500 o más CPUs) para n ¡ n CAD-CAM, test de choques, integridad estructural y aerodinámica. Simulación de dispositivos electrónicos y validación lógica. Ahorros: aprox. $1000 millones al año. Finanzas: ¡ Ahorros: aprox. $15000 millones al año en hipotecas en USA.
Modelo global del clima n n Problema a computar: f(latitud, longitud, elevación, tiempo) temperatura, presión, humedad, velocidad del viento Enfoque: ¡ Discretizar el dominio, ej: , un punto cada 10 km ¡ Diseñar el algoritmo que prediga el clima en t+dt dado el clima en t • Usos: - Predecir eventos importante como el Niño - Estudiar políticas de estándares ambientales fuente: http: //www. epm. ornl. gov/chammp. html
Computación del clima n Una parte es modelar el flujo de fluidos en la atmósfera ¡ Resolver las ecuaciones de Navier-Stokes n n Requisitos de computo: ¡ ¡ n n n Aprox. 100 Flops por punto en la malla con dt de 1 minuto Para tiempo real, 5 x 1011 flops en 60 seconds = 8 Gflop/s Predecir el clima para la TV (7 días en 24 horas) 56 Gflop/s Predecir el clima para papers (50 años en 30 días) 4. 8 Tflop/s Para usar en negociaciones (50 años en 12 horas) 288 Tflop/s Si se dobla la resolución de la malla, el computo aumenta por un factor de 8 x u 16 x Modelos “de estado del arte” necesitan más partes: oceanos, hielos polares, elevación del terreno, ciclo del carbono, geoquímica, contaminantes, etc. Modelos actuales no llegan a tanto.
Modelo climático de alta resolución NERSC-3 – P. Duffy, et al. , LLNL
Simulación para 100 años • Demostración del Community Climate Model (CCSM 2) • Una simulación a 1000 años muestra una tendencia estable y de largo plazo. • Se usaron 760, 000 horas de CPU • Se ve el cambio de la temperatura. n n Warren Washington and Jerry Meehl, National Center for Atmospheric Research; Bert Semtner, Naval Postgraduate School; John Weatherly, U. S. Army Cold Regions Research and Engineering Laboratory et al. http: //www. nersc. gov/news/science/bigsplash 2002. pdf
Modelo del clima en el Earth Simulator System m El ESS se empezó a crear en 1997 para estudiar el cambio de clima global y el calentamiento global. m Su construcción se completó en Febreo del 2002 y empezó a trabajar desde el 1 ro de Marzo del 2002 m 35. 86 Tflops (87. 5% de la performance pico) obtenida en el benchmark Linpack (máquina más rápida del mundo del 2002 al 2004). m 26. 58 Tflops obtenidos con los simuladores del clima global.
Dinámica de agujeros negros binarios n Núcleo de grades supernovas colapsan en agujeros negros. n En el centro de los agujeros negros el tiempo espacio se altera. n Son un test crucial para teorías de gravedad – de la relatividad gral. a gravedad cuántica. n Observación indirecta – muchas galaxias tiene un agujero negro en su centro. n Ondas gravitacionales muestras al agujero negro y sus parámetros. n Agujeros negros binarios son una gran fuente de ondas gravitacionales. n Su simulación es muy compleja – el espacio tiempo se altera !
Paralelismo en Análisis de datos n n n Hallar información entre grandes cantidades de datos. Para qué husmear en grandes cantidades de datos? : ¡ Hay alguna dolencia inusual en una ciudad? ¡ Qué clientes son más propensos a tratar de hacer fraude al seguro de salud? ¡ Cuándo conviene poner en oferta la cerveza? ¡ Qué tipo de publicidad mandarte a la casa? Hay data que se recolecta y guarda a gran velocidad (Gbyte/hour) ¡ Sensores remotos en un satélite ¡ Telescopios ¡ Microarrays generando data de genes ¡ Simulaciones generando terabytes de datos ¡ Espionaje (NSA)
Por qué las computadoras poderosas son paralelas?
Tendencia tecnológica: Capac. del microprocesador Moore’s Law 2 X transistores/Chip cada 1. 5 años Es la “Ley de Moore” Microprocesadores son cada vez más chicos, densos y poderosos. Gordon Moore (co-fundador de Intel) predijo en 1965 la densidad de transistores en chips de semiconductores se duplicaría más o menos cada 18 meses. fuente: Jack Dongarra
Crecimiento en performance de CPUs
Impacto de la miniaturización de dispositivos n Qué pasa cuando el tamaño del transistor se achica en un factor de x ? n El reloj de la CPU aumenta en x porque los cables entre transistores son más cortos ¡Realmente es menos que x, debido a la disipación de energía n Nro. De Transistores/area sube en x 2 n Tamaño del “dado” crece ¡Generalmente n Poder en un factor cercano a x de proceso del chip sube cerca de x 4 ! ¡Del cuál x 3 se dedica al paralelismo o localidad
Transistores por Chip • Mejora en Transistores por chip • Mejora en reloj de CPU
Crecimiento en performance de CPUs n n Ley de Moore para 1 sola CPU: hasta cuándo? Ver pendiente del gráfico del 2002 en adelante Problemas para obtener CPUs más veloces: ¡ ¡ Disipación del calor Poco paralelismo a nivel de instrucciones Latencia de memoria no baja Más básico: física cuántica es probabilística, y circuitos muy chicos se vuelven de naturaleza cuántica.
Otros límites: Creciente costo y dificultad de fabricación n 2 da ley de Moore (ley de Rock) Demo de CMOS de 0. 06 micrones
Más Limites: Qué tan rápida puede ser una comput. serial? CPU secuencial de 1 Tflop/s, 1 Tbyte n Considerar un CPU secuencial de 1 Tflop/s : ¡ ¡ n Data debe viajar cierta distancia r, para ir de la memoria a la CPU. Para conseguir 1 elemento de data por ciclo, o sea 1012 veces por segundo, a la velocidad de la luz c = 3 x 108 m/s. Tenemos que r < c/1012 = 0. 3 mm. Como poner 1 Tbyte en un área de 0. 3 mm x 0. 3 mm: ¡ n r = 0. 3 mm Cada bit ocupa 1 A 2, o el tamaño de un átomo. No se puede. Sólo queda usar paralelismo.
Performance en el test LINPACK
Análisis de los reportes TOP 500 n Crecimiento anual de performance cerca de 1. 82 n Dos factores contribuyen casi en par en este crecimiento n Número de procesadores crece anualmente por un factor de 1. 30, y n Performance de un procesador crece en 1. 40 vs. 1. 58 según la Ley de Moore 1. 3 x 1. 4 = 1. 82
Por qué escribir programas paralelos rápidos es difícil?
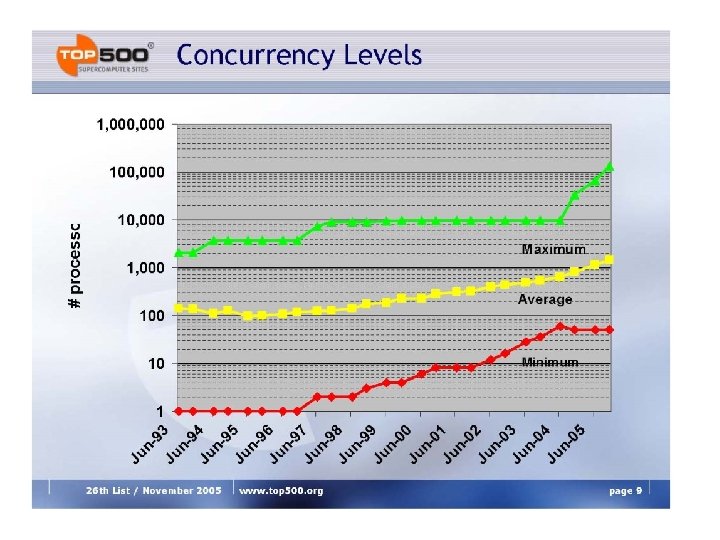
Principios de Computación paralela n n n Encontrar suficiente paralelismo (Ley de Amdahl) Granularidad Localidad Balance de carga Coordinación y sincronización Modelamiento de la performance Estos detalles hacen que la BUENA programación paralela sea más difícil que la secuencial.
Paralelismo automático en computadoras modernas n n A nivel de bit ¡ Dentro de operaciones de punto flotante, etc. A nivel de instrucción (ILP) ¡ Ejecutar múltiples instrucciones en un solo ciclo de reloj A nivel de memoria del sistema ¡ Computar y leer/escribir en memoria a la vez A nivel del Sistema Operativo ¡ Muchos jobs corriendo en paralelo en SMPs Todos tienen un límite – para excelente perfomance, el humano debe identificar, calendarizar y coordinar tareas paralelas.
Encontrar suficiente Paralelismo n n Suponer que solo una parte de un programa se puede paralelizar. Ley de Amdahl ¡ ¡ Si s es la fracción de trabajo no paralelizable (secuencial), entonces (1 -s) es la fracción paralelizable P = número de procesos Speedup(P) = Tiempo(1)/Tiempo(P) <= 1/(s + (1 -s)/P) <= 1/s n Aún si la parte paralela se acelera (speeds up) a la perfección, la performance está limitada por la parte secuencial.
Costos del Paralelismo n n Si hay bastante paralelizable, la mayor barrera para lograr buen speedup es el costo del paralelismo. Ese costo incluye: ¡ ¡ n n Costo de empezar un hilo o un proceso Costo de comunicar data compartida Costo de sincronización Computación extra o redundante Cada uno de ellos pueden estar en el rango de ms (= millones de flops) en algunos sistemas. Solución de Compromiso: los algoritmos necesitan unidades de trabajo suficientemente grandes para correr rápido en paralelo (o sea, grano grueso), pero no tan grandes que no hay suficiente trabajo paralelo o trabajo para menos procesadores.
Localidad y Paralelismo Jerarquía del almacenamiento en memoria Proc Cache L 2 Cache L 3 Cache Memoria Posibles interconexiones L 3 Cache Las memorias grandes son lentas, las rápidas son las chicas n La memoria es rápida y grande en promedio n Los procesadores paralelos, colectivamente, tienen mayor caché y memoria n ¡ n El acceso lento a data “remota” se llama “comunicación” Los algoritmos deben tratar de trabajar mayormente en data local.
Gap entre Procesador-DRAM (latencia) CPU “Ley de Moore” 100 10 1 µProc 60%/año Gap de performance entre CPU y DRAM: (crece 50% / año) DRAM 7%/año 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 Performance 1000 Año
Desbalance de carga n El desbalance de carga es el tiempo que algunos CPUs en el sistema están ociosos debido a: ¡ ¡ n Ejemplos de trabajos desiguales ¡ ¡ ¡ n Insuficiente paralelismo (durante esa fase) Trabajos de tamaño desigual Adaptarse a “partes interesantes del dominio” Cómputos con estructuras de árbol (ej: ajedrez) Problemas no estructurados. Se necesita algoritmos para balancear la carga.
Mejorando la Performance real Performance pico crece exponencialmente, como dice la ley de Moore l En los 90 s, creció 100 x; en esta década, crecerá 1000 x 1, 000 Performance pico Pero la eficiencia (performance relativa al pico de hardware) ha caído l Era 40 -50% en las supercomputadoras vectoriales de los 90 s Ahora entre 5 -10% en muchas supercomputadoras paralelas El gap se cierra vía. . . l l Métodos matemáticos y algoritmos que logran mejor performance en un solo CPU y escalan a miles de CPUs Modelos de programación más eficientes y mejores herramientas (compiladores, etc. ) Teraflops l 100 Gap de Performance 10 1 Performance real 0. 1 1996 2000 2004
Midiendo la Performance n Peak advertised performance (PAP) ¡ n LINPACK Benchmark ¡ ¡ n El programa “hello world” en computación paralela Resolver Ax=b por Eliminación Gaussiana. Gordon Bell Prize winning applications performance ¡ n La que dice el fabricante. Máximo teórico. La mejor combinación de aplicación/algoritmo/plataforma Performance sostenida promedio ¡ Lo que se puede esperar razonablemente en el caso de aplicaciones comunes. Ojo, muchas veces se confunden unas evaluaciones por otras, incluso en libros y revistas
Qué deberíamos sacar de este curso? n. Cuándo es útil el cómputo paralelo? n. Saber las diferentes opciones de hardware en computación paralela. n. Modelos de programación (software) y herramientas. n. Algunas aplicaciones y algoritmos paralelos n. Análisis y mejora de Performance. Ver: http: //www-unix. mcs. anl. gov/dbpp/