We know that different stores are different Different





 25, 4% 13, 5%")





 library(rpart. plot) library(partykit) library(permute) library(maptree)")
![mydata <- read. csv("C: /Users/jlariv/Documents/Hetero. ATE/ln_Required. Data. csv") mydata<- mydata[, 2: ncol(mydata)] colnames(mydata) #](https://slidetodoc.com/presentation_image_h2/44e9da713981f67a7e16eb5577679a5c/image-20.jpg "mydata <- read. csv(\"C: /Users/jlariv/Documents/Hetero. ATE/ln_Required. Data. csv\") mydata<- mydata[, 2: ncol(mydata)] colnames(mydata) #")





![library(geosphere) x <- collapsed[ , c(2: 45, 65: 72)] ##pull variables to cluster on](https://slidetodoc.com/presentation_image_h2/44e9da713981f67a7e16eb5577679a5c/image-27.jpg "library(geosphere) x <- collapsed[ , c(2: 45, 65: 72)] ##pull variables to cluster on")


 • Assume that substitutes exist but they are imperfect and therefore")

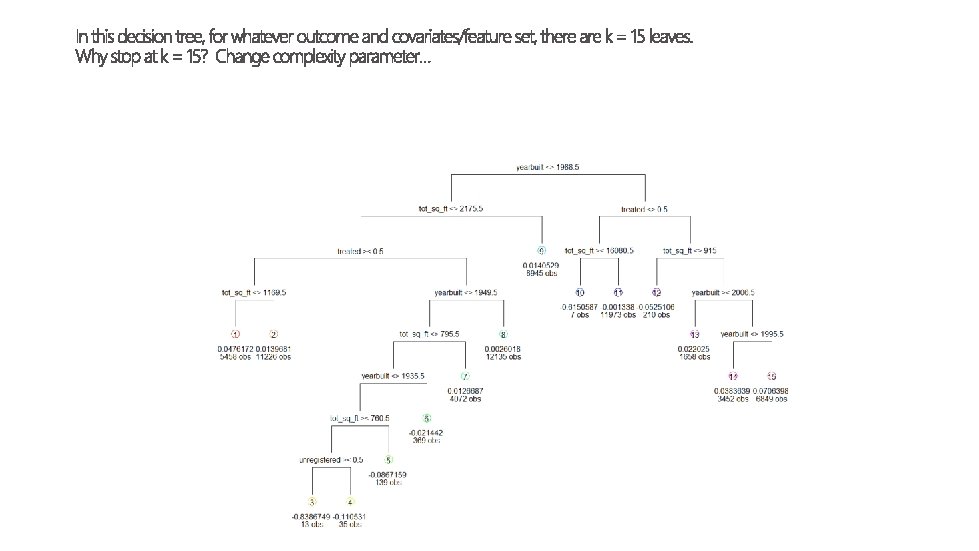
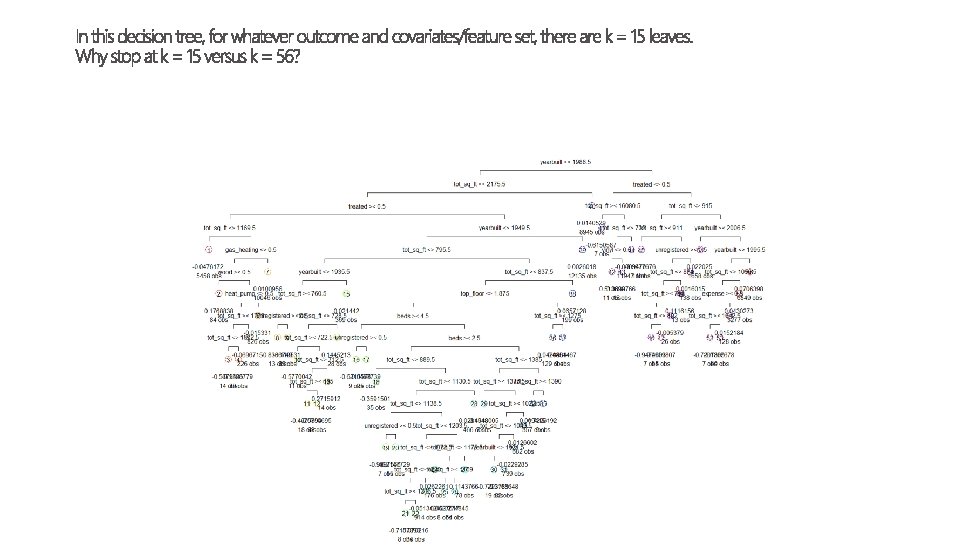
- Slides: 31
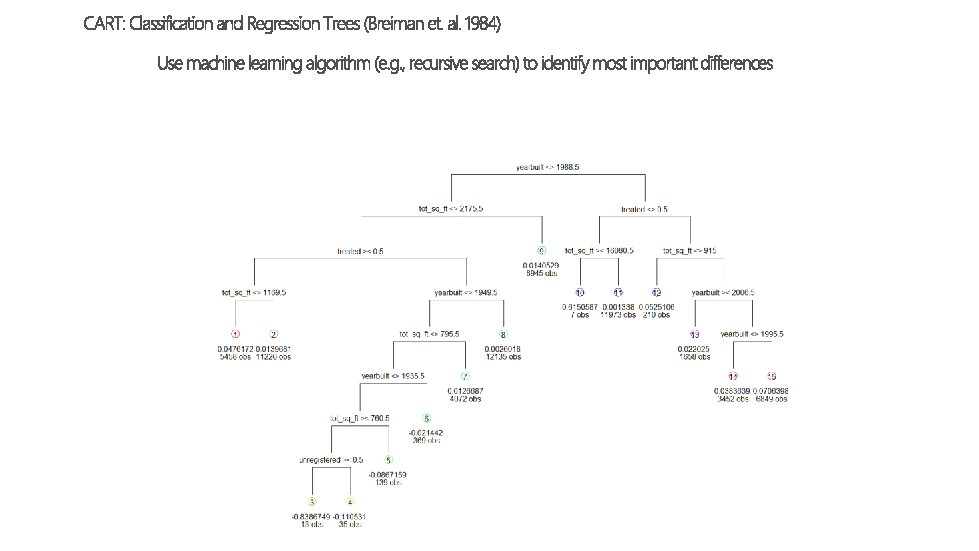
We know that different stores are “different” - Different level of sales - Different sales price - Different sociodemographic characteristics Is there a smart way to group them?
common task
ID Age Educ Politics Treated 1 59 BA D 0 2 33 Ph. D n/a 1 3 41 HS I 1 … … …
CTR Loss in CTR from Link Demotion (US All Non-Navigational) 25, 4% 13, 5% 17, 9% 4, 9% 6, 9% 3, 5% 4, 0% Control (1, 3) (1, 5) (1 st Position) Original CTR of Position Gain from Increased Relevance 21, 6% 1, 7% 2, 1% (1, 10)
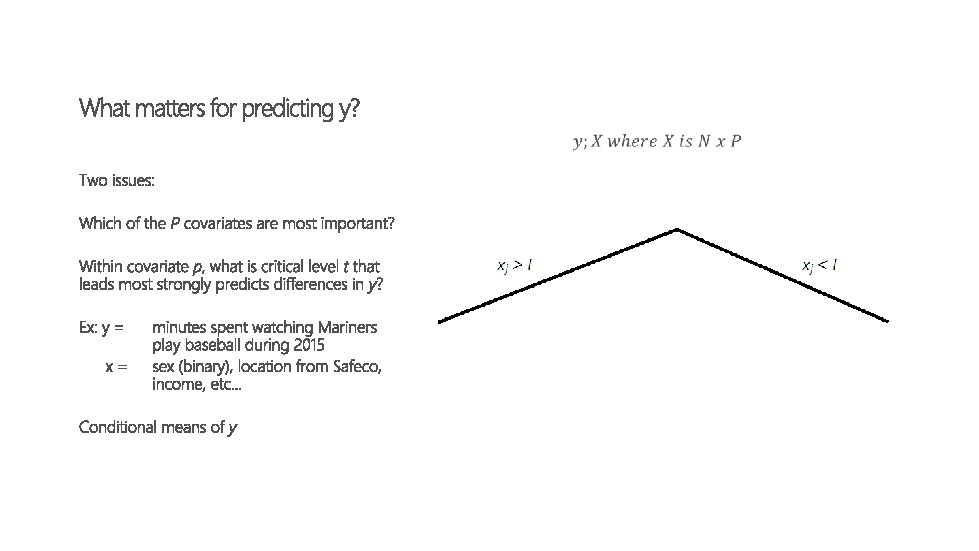
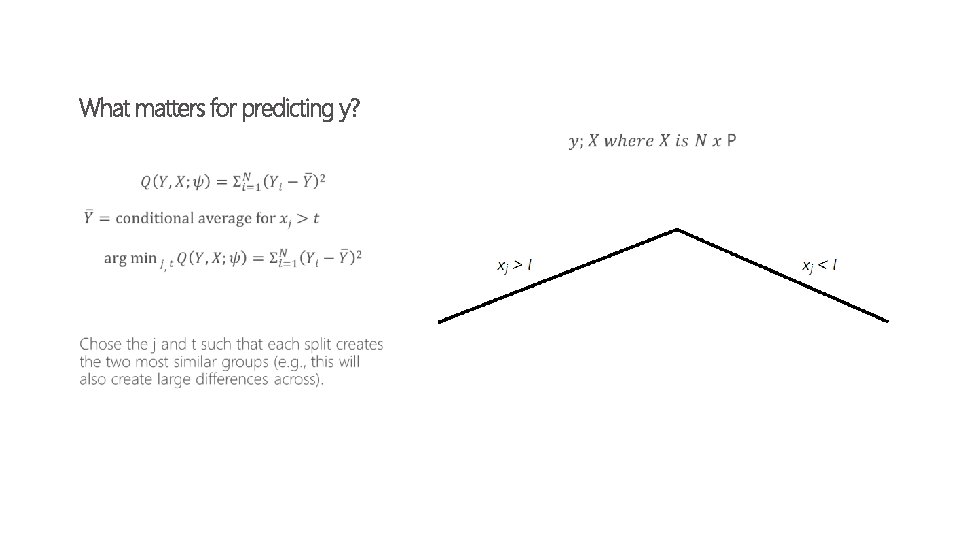
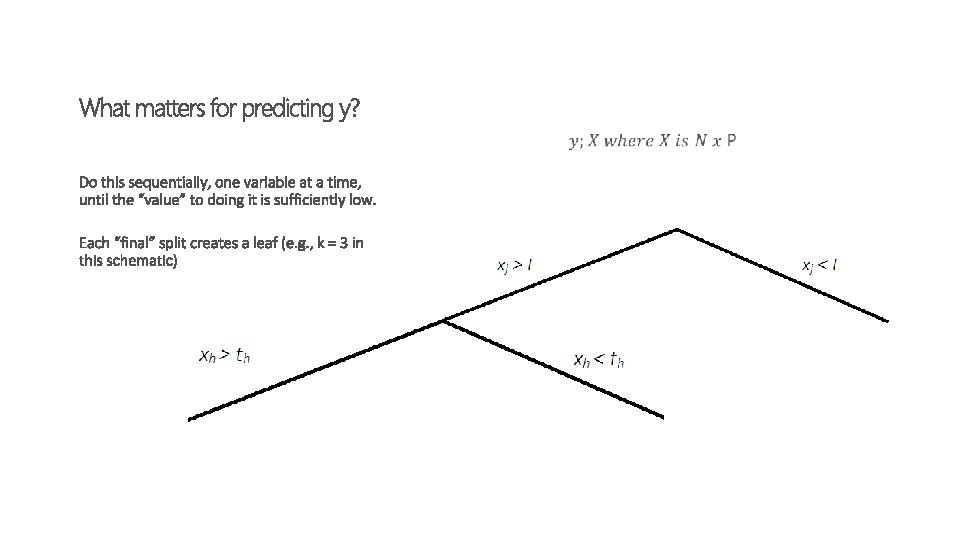
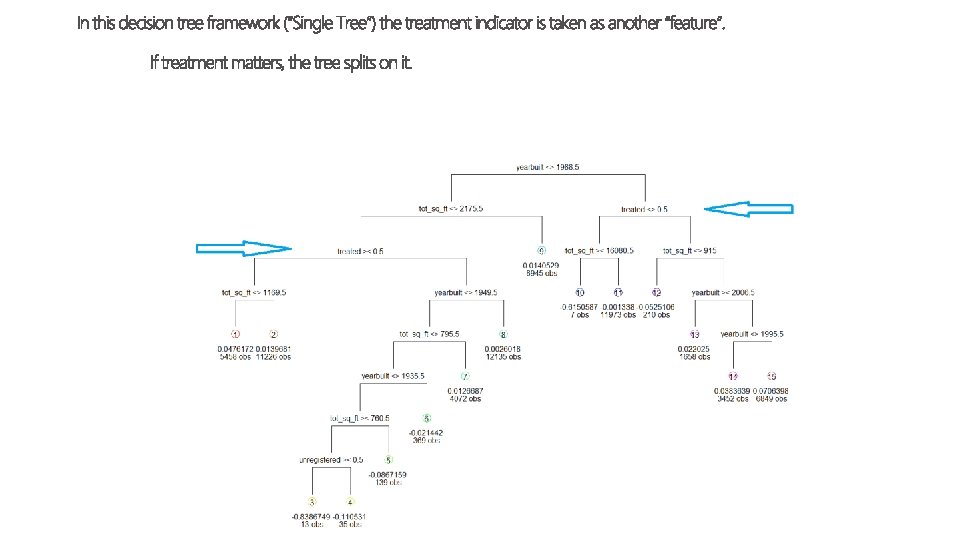
how does this matter for treatment?
library(rpart) library(rpart. plot) library(partykit) library(permute) library(maptree)
mydata <- read. csv("C: /Users/jlariv/Documents/Hetero. ATE/ln_Required. Data. csv") mydata<- mydata[, 2: ncol(mydata)] colnames(mydata) # This just gets the data in a format where everything has a name I can work with. data. To. Pass<mydata[, c("ln_resid_use", "heat_pump", "gas_heating", "vinyl", "wood", "brick", "beds", "top_floor", "basement", "tot_sq_ft", "yearbuilt", "unregistered", … …"undeclared", "rep", "dem", "treated", "k. Wh", "expense", "CO 2")] #This creates a dataframe with only the variables I want to use to explain variation in the variable I care to examine (e. g. , ln(residual use) #This next line actually fits the tree. bfit<-rpart(as. formula(ln_resid_use ~. ), data=data. To. Pass, method="anova", cp=0. 0003) #NOTE: cp=. 0003 is the "complexity parameter" and the lower it goes, the more complicated the tree gets (e. g. , more leaves). draw. tree(bfit) #This command draws the tree data. To. Pass$leaf = bfit$where #This final command identifies which observation is associated with what leaf and creates a new variable for it in the original dataframe #disco #Now you know where hashtags came from
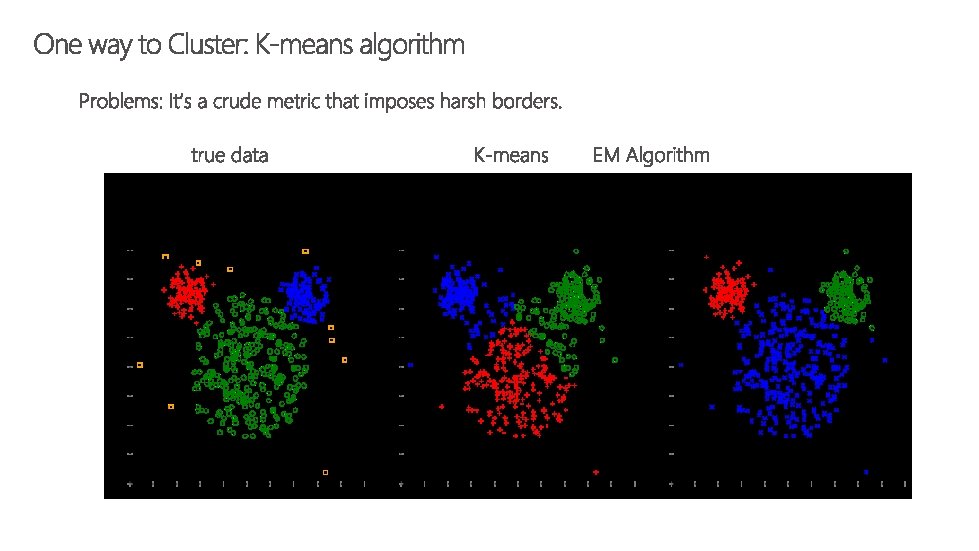
So… Regression trees are cool at categorizing variables with a continuous LHS variable (e. g. , minutes on application) What if there is no LHS variable? Example: rather than minutes on an application as a function of covariates, you care about how people use the application. -> e. g. , user types or “road types”
library(geosphere) x <- collapsed[ , c(2: 45, 65: 72)] ##pull variables to cluster on from dataframe “c” colnames(x) <- colnames(collapsed)[c(2: 45, 65: 72)] ##Clustering for(i in 1: 1){ ##10 tries for each cluster size so we can test with multiple groupings if we choose set. seed(i) ##set the number of clusters we want to use for(j in c(8)){ ##clusters of size 8, 10, 15) k <- j ##K means clustering cl <- kmeans(x, k) ##k is the number of clusters, x is our set of clustering variables collapsed <- cbind(collapsed, cl$cluster) ##append data with cluster ids colnames(collapsed)[ncol(collapsed)] <- paste("cluster_", k, "_seed_", i, sep="") } } segment_clusters = data. frame(cbind(as. character(collapsed$tmc), collapsed$cluster_8_seed_1)) ##using k=10 segmentscsv$tmc <- as. character(segmentscsv$tmc) ##making sure segements aren't stored as factors segment_clusters$X 1 <- as. character(segment_clusters$X 1) ##X 1 is the segment variable segmentscsv <- merge(segmentscsv, segment_clusters, by. x = "tmc", by. y="X 1") colnames(segmentscsv) <- c(colnames(segmentscsv)[1: (ncol(segmentscsv)-1)], "cluster_id")
Non-Price Competition
1/1/2022 Game Theory, Market Structures, and Firms Slide by Will Wang 29
Hotelling (horizontal differentiation) • Assume that substitutes exist but they are imperfect and therefore costly. - ex: Stevens Pass versus Crystal Mountain • Idea: How much should firms charge given where they are in horizontal “product space”? • Assume firms identical in every way but location (simplest possible model of differentiation). 1/1/2022 • Monopoly? • Anywhere • Duopoly? • Middle • Three players? • No pure strategy equilibrium • Median voter theorem? • How might it break down? “Walk” is costly and distribution not uniform Game Theory, Market Structures, and Firms 30
Vertical differentiation 1/1/2022 • Game Theory, Market Structures, and Firms 31