Support Vector Machines SVM Brenda Thomson Peter Fox
 Brenda Thomson/ Peter Fox Data Analytics ITWS-4600/6600/MATP-4450/CSCI-4960 Group 3 Module")
Support Vector Machines (SVM) Brenda Thomson/ Peter Fox Data Analytics ITWS-4600/6600/MATP-4450/CSCI-4960 Group 3 Module 8, October 23, 2018 1
")
Support Vector Machine • Conceptual theory, formulae… see Reading! • SVM - general (nonlinear) classification, regression and outlier detection with an intuitive model representation • Hyperplanes separate the classification spaces (can be multi-dimensional) • Kernel functions can play a key role 2

Kernel Function • The learning of the hyperplane in linear SVM is done by transforming the problem using some linear algebra. • Uses the inner product of any two given observations, rather than the observations themselves. The inner product between two vectors is the sum of the multiplication of each pair of input values. • The equation for making a prediction for a new input using the dot product between the input (x) and each support vector (xi) is calculated as follows: f(x) = B 0 + sum(ai * (x, xi)) • The coefficients B 0 and ai (for each input) must be estimated from the training data by the learning 3 algorithm.
. svg")
Schematically 4 http: //en. wikipedia. org/wiki/File: Svm_separating_hyperplanes_(SVG). svg
 http: //en. wikipedia. org/wiki/File: Svm_max_sep_hyperplane_with_margin. png")
Schematically Support Vectors 5 b=bias term, b=0 (unbiased) http: //en. wikipedia. org/wiki/File: Svm_max_sep_hyperplane_with_margin. png

Construction • Construct an optimization objective function that is inherently subject to some constraints – Like minimizing least square error (quadratic) • Most important: the classifier gets the points right by “at least” the margin • Support Vectors can then be defined as those points in the dataset that have "non zero” Lagrange multipliers*. – make a classification on a new point by using only the support vectors – why? 6

Support vectors • Support the “plane” 7

What about the “machine” part • Ignore it – somewhat leftover from the “machine learning” era – It is trained and then – Classifies 8

No clear separation = no hyperplane? Soft-margins… Non-linearity or transformation 9
 using a function, i. e. a kernel Ø goal is")
Feature space Mapping (transformation) using a function, i. e. a kernel Ø goal is – linear separability 10

Kernels or “non-linearity”… http: //www. statsoft. com/Textbook/Support-Vector-Machines the kernel function, represents a dot product of input data points mapped into the higher dimensional feature space by transformation phi + note presence of “gamma” parameter 11

Best Linear Separator: Supporting Plane Method Maximize distance Between two paral supporting planes Distance = “Margin” =

Soft Margin SVM Just add non-negative error vector z.

Method 2: Find Closest Points in Convex Hulls d c

Plane Bisects Closest Points d c

Find using quadratic program Many existing and new QP solvers.

Dual of Closest Points Method is Support Plane Method Solution only depends on support vectors:

One bad example? Convex Hulls Intersect! Same argument won’t work.

Don’t trust a single point! Each point must depend on at least two actual data points.

Depend on >= two points Each point must depend on at least two actual data points.

Depend on >= two points Each point must depend on at least two actual data points.

Depend on >= two points Each point must depend on at least two actual data points.

Depend on >= two points Each point must depend on at least two actual data points.

Final Reduced/Robust Set Each point must depend on at least two actual data points. Called Reduced Convex Hull

Reduced Convex Hulls Don’t Intersect Reduce by adding upper bound D

Find Closest Points Then Bisect No change except for D. D determines number of Support Vectors.

Dual of Closest Points Method is Soft Margin Method Solution only depends on support vectors:

What will linear SVM do?

Linear SVM Fails

High Dimensional Mapping trick http: //www. slideshare. net/ankitksh arma/svm-37753690
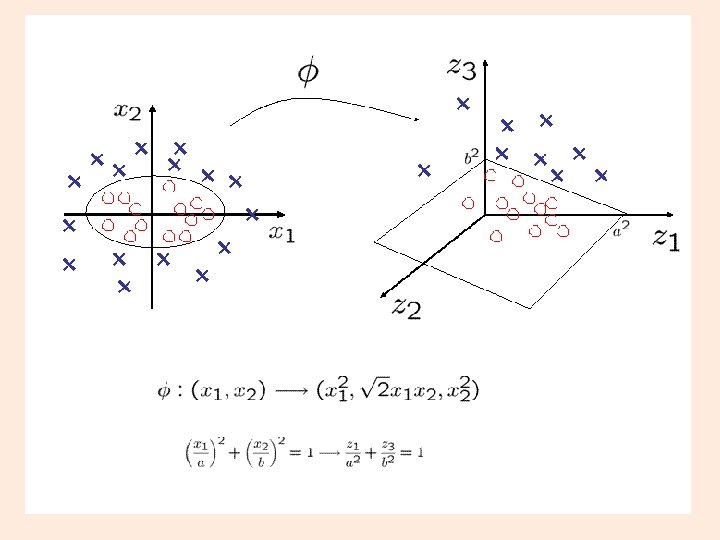

Nonlinear Classification: Map to higher dimensional space IDEA: Map each point to higher dimensional feature space and construct linear discriminant in the higher dimensional space. Dual SVM becomes:

Kernel Calculates Inner Product

Final Classification via Kernels The Dual SVM becomes:
 for certain and K,")
Generalized Inner Product By Hilbert-Schmidt Kernels (Courant and Hilbert 1953) for certain and K, e. g. Also kernels for nonvector data like strings, histograms, dna, …

Final SVM Algorithm • Solve Dual SVM QP • Recover primal variable b • Classify new x Solution only depends on support vectors:

S 5: Recall linear solution

RBF results on Sample Data

Have to pick parameters Effect of C

Effect of RBF parameter

General Kernel methodology • • • Pick a learning task Start with linear function and data Define loss function Define regularization Formulate optimization problem in dual space/inner product space • Construct an appropriate kernel • Solve problem in dual space

kernlab, svmpath and kla. R • http: //aquarius. tw. rpi. edu/html/DA/v 15 i 09. pdf Karatzoglou et al. 2006 • Work through the examples (lab) – Familiar datasets and samples procedures from 4 libraries (these are the most used) – kernlab – e 1071 – svmpath – kla. R 42

Application of SVM • Classification, outlier, regression… • Can produce labels or probabilities (and when used with tree partitioning can produce decision values) • Different minimizations functions subject to different constraints (Lagrange multipliers) See Karatzoglou et al. 2006 • Observe the effect of changing the C parameter and the kernel 43
 • Classification SVM Type 1 (also known as CSVM classification)")
Types of SVM (names) • Classification SVM Type 1 (also known as CSVM classification) • Classification SVM Type 2 (also known as nu. SVM classification) • Regression SVM Type 1 (also known as epsilon-SVM regression) • Regression SVM Type 2 (also known as nu. SVM regression) 44

More kernels 45 Karatzoglou et al. 2006

Timing 46 Karatzoglou et al. 2006

Library capabilities Karatzoglou et al. 2006 47

Extensions • Many Inference Tasks – – – – Regression One-class Classification, novelty detection Ranking Clustering Multi-Task Learning Kernels Canonical Correlation Analysis Principal Component Analysis

Algorithms Types: • General Purpose solvers – CPLEX by ILOG – Matlab optimization toolkit • Special purpose solvers exploit structure of the problem – Best linear SVM take time linear in the number of training data points. – Best kernel SVM solvers take time quadratic in the number of training data points. • Good news since convex, algorithm doesn’t really matter as long as solvable.

Hallelujah! • Generalization theory and practice meet • General methodology for many types of inference problems • Same Program + New Kernel = New method • No problems with local minima • Few model parameters. Avoids overfitting • Robust optimization methods. • Applicable to non-vector problems. • Easy to use and tune • Successful Applications BUT…

Catches • Will SVMs beat my best hand-tuned method Z on problem X? • Do SVMs scale to massive datasets? • How to chose C and Kernel? • How to transform data? • How to incorporate domain knowledge? • How to interpret results? • Are linear methods enough?
- Slides: 51