Information Retrieval cutarea regsirea informaiei Information overload suprancrcarea
 informației поиск информации")










 de caracteristici (features)")
 de caracteristici (features)")
 de caracteristici (features)")





=log(1, 5)=0.")






















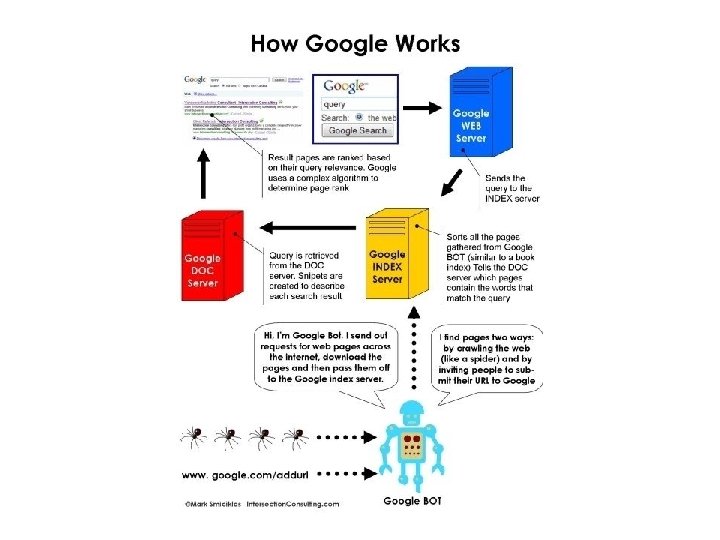
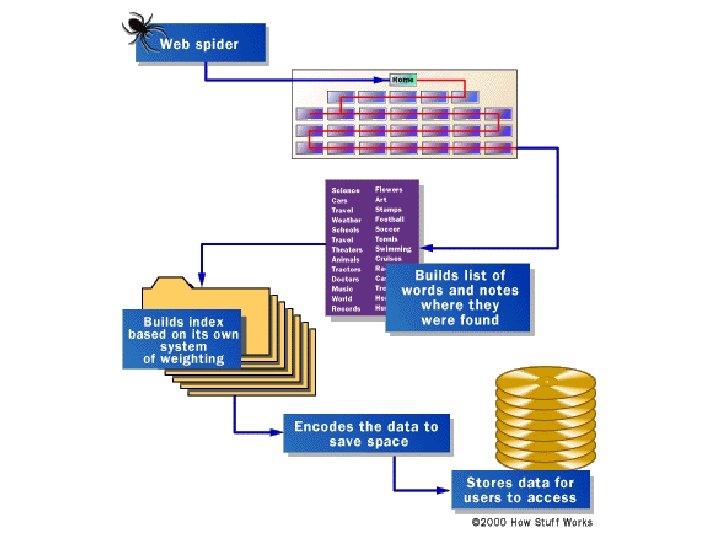















- Slides: 59
Information Retrieval căutarea (regăsirea) informației поиск информации
Information overload supraîncărcarea informațională Информационная перегрузка
Search engine text indexing Indexing web pages
Terminologia IR • documentul este o unitate de text. - un articol din ziar, un capitol din carte, un paragraf, o pagină WEB ş. a. m. d. • colecţie este un set de documente. • Cuvinte-cheie prezintă unităţi lexicale după care se face selectarea documentelor. - unităţile lexicale pot fi cuvintele, îmbinările de cuvinte. • Interogarea (query) utilizatorului : informaţia prezentată de către utilizator motorului de căutare în baza căruia se execută selectarea documentelor.
IR: Definiții • documentul relevant unei interogări • similaritatea între interogare și document sau între două documente
IR: Definiții • documente relevante interogărilor
IR: Definiții • similaritatea între interogare și document interogare: ce este prelucrarea limbajului natural document:
IR: Definiții • similaritatea între interogare și document sau între două documente
Terminologia IR: bag of words
Terminologia IR: bag of words
Terminologia IR: bag of words
În IR interogarea utilizatorului şi documentele sunt prezentate ca vectori (seturi) de caracteristici (features) de fapt, cuvintele-cheie care apar în interogare sau în document.
În IR interogarea utilizatorului şi documentele sunt prezentate ca vectori (seturi) de caracteristici (features) de fapt, cuvintele-cheie care apar în interogare sau în document. dj = ( t 1, j, t 2, j, t 3, j, . . . t. N, j ) qk = ( t 1, k, t 2, k, t 3, k, . . . t. N, k ) Atunci relevanţa documentului interogării se calculează ca similaritatea între document şi interogare: sim (qk, dj ) = ti, k × ti, j i=1, N
În IR interogarea utilizatorului şi documentele sunt prezentate ca vectori (seturi) de caracteristici (features) de fapt, cuvintele-cheie care apar în interogare sau în document. sim (qk, dj ) = ti, k × ti, j i=1, N
importanţa cuvintelor-cheie weight - ponderea
importanţa cuvintelor-cheie weight - ponderea Matricea de ponderi a cuvintelor Ci în documentele dj
importanţa cuvintelor-cheie Ponderea cuvîntului în dependență de mărimea documentului TF - TERM FREQUENCY Wi, j = ti, j / ti, j 2 j
importanţa cuvintelor-cheie Ponderea cuvîntului în dependență de mărimea documentului TERM FREQUENCY
importanţa cuvintelor-cheie Ponderea cuvîntului în dependență de numărul de documente în care acesta apare IDF – INVERSE DOCUMENT FREQUENCY idfi = log(N / ni) idfi log(3/2)=log(1, 5)=0. 176 log(3/3)=log(1)=?
importanţa cuvintelor-cheie Ponderea cuvîntului TF-IDF METRICS idfi = N / ni idfi log(3/2)=log(1, 5)=0. 176 log(3/3)=log(1)=0
importanţa cuvintelor-cheie Ponderea cuvîntului TF-IDF METRICS idfi = N / ni doc 1 0. 07 speech language 0. 14 processing 0. 00 doc 2 0. 17 0. 00 doc 3 0. 00 0. 17 0. 00
SAU. . . • Indexarea booleana
Stop words de în şi la a să cu nu pe se ce că mai o un din dar când ca el iar eu lui care sunt cum tot prin nici pentru mă este tu ei căci lor au le am te numai fi asa noi însă fost prea fără îi toti apoi sau ai face cel voi decât poate ea ne pot
IR: Similaritatea • similaritatea între interogare: speech and language processing q=( 1 1 1 doc 2 ) și document doc 1, doc 2, doc 3 sim (q, d) = d x q speech 0. 07 language 0. 14 processing 0. 00 0. 17 0. 00 doc 3 0. 00 0. 17 0. 00
IR: Similaritatea • similaritatea între interogare: speech and language processing q=( 1 1 1 doc 2 ) și document doc 1, doc 2, doc 3 sim (q, d) = d x q speech language processing 1 1 0 0 doc 3 0 1 0
IR: Similaritatea
IR: Similaritatea
Modelul vectorilor în spațiu
Modelul vectorilor în spațiu
IR: Implementarea preprocesarea documentelor 1. Tokenization împărțirea în cuvinte Opriți-vă copiii până-n 12 ani Opriți-vă , până-n - un cuvînt sau două? Rowan dă exemplu jocul Grand Theft Auto V impărțim Grand Theft Auto V în cuvinte? Potrivit Ministerului Dezvoltării Regionale și Construcțiilor, . . . - impărțim?
IR: Implementarea preprocesarea documentelor 2. Normalizarea convertăm tot textul in litere mici Ce facem cu abrevieri? Viorel Bostan este noul rector al UTM viorel bostan utm
IR: Implementarea preprocesarea documentelor 2. Normalizarea ce facem cu diacritice? Caut informația despre pește caut informatia despre peste măi – mai, român – roman, in - în
IR: Implementarea preprocesarea documentelor 2. Normalizarea ce facem cu cifre? U. S. , 3/12/91 U. S. , Mar. 12, 1991. Europa, 3 Dec 1991
IR: Implementarea preprocesarea documentelor 2. Normalizarea stemming worked working worker ? ? ? work
IR: Implementarea preprocesarea documentelor 2. Normalizarea lemmatization lucrai lucram lucrarăm lucrarăți lucrași lucrată lucrate lucrați lucrau lucrăm lucra
IR: Implementarea ce facem cu ambiguitatea cuvintelor? From Wikipedia, the free encyclopedia Washington commonly refers to: 1. 2. 3. 4. George Washington (1732– 1799), first president of the United States Washington (state), United States Washington, D. C. , the capital of the United States Washington (name), including a list of people with the given name or surname Washington may also refer to: 1. The Washington metropolitan area 2. A metonym for the Federal government of the United States
IR: stocarea datelor
IR: stocarea datelor • 2. 7 Zetabytes of data exist in the digital universe today. • Facebook stores, accesses, and analyzes 30+ Petabytes of user generated data. • 571 new websites are created every minute of the day. • 2008 Google was processing 20, 000 terabytes of data (20 petabytes) a day. • Decoding the human genome originally took 10 years to process; now it can be achieved in one week. http: //wikibon. org/blog/big-data-statistics/
IR: Similaritatea
Search engine text indexing Indexing web pages
Search Engines Optimization • http: //www. webdesignstuff. co. uk/fc 103/
Text Retrieval Conference TREC
IR: Evaluarea
Text Analysis analiza textului
Sentiment analysis analiza sentimentelor http: //sentistrength. wlv. ac. uk/
Sentiment analysis analiza sentimentelor https: //www. metamind. io/classifiers/155
Sentiment analysis analiza sentimentelor https: //www. csc. ncsu. edu/faculty/healey/tweet_viz/tweet_app/
Sentiment analysis analiza sentimentelor http: //blog. datumbox. com/how-to-build-your-own-twitter-sentiment-analysis-tool/ In order to build the Sentiment Analysis tool we will need 2 things: 1) connect on Twitter and search for tweets that contain a particular keyword. 2) evaluate the polarity (positive, negative or neutral) of the tweets based on their words. For the first task we will use the Twitter REST API 1. 1 v and for the second the Datumbox API 1. 0 v. You can find the complete PHP code of the Twitter Sentiment Analysis tool on Github. In order to detect the Sentiment of the tweets we used our Machine Learning framework to build a classifier capable of detecting Positive, Negative and Neutral tweets. Our training set consisted of 1. 2 million tweets evenly distributed across the 3 categories.
Google's machine learning Inbox can now reply to your emails A new feature in Google's Inbox app can recognise the content of emails and tailor responses using natural language, without a human being having to do a thing. Machine learning is used to scan emails and understand if they need replying to or not, before creating three response options. An email asking about vacation plans, for example, could be replied to with "No plans yet", "I just sent them to you" or "I'm working on them". The feature, dubbed Smart Reply, is only available in Google's Inbox app for Android and i. OS. It has been designed for emails that can be answered with a short reply such as "I'll send it to you" or 'I don't, sorry'. http: //www. wired. co. uk/news/archive/2015 -11/03/google-smart-reply-machinelearning-email
Google is not selling access to its deep learning engine. It’s open sourcing that engine, freely sharing the underlying code with the world at large. This software is called Tensor. Flow, and in literally giving the technology away, Google believes it can accelerate the evolution of AI. http: //www. wired. com/2015/11/google-open-sources-its-artificial-intelligence-engine/
Conversational system on a robotic platform We recently bought a humanoid robot and want to port an inhouse developed virtual agent on it. Ideal for a student interested in deploying cutting-edge tecnology to a consumer-facing platform. http: //www. xrce. xerox. com/About. XRCE/Internships/Conversational-system-on-a-roboticplatform
*************** To prospective Master students *************** • The Erasmus Mundus Masters Program in Language and Communication Technologies (EMMLCT) http: //lct-master. org invites applications for Erasmus-Mundus scholarships from both European and non-European students for start in fall 2016. Key facts: + duration 2 years (120 ECTS credits) + in-depth instruction in computational linguistics methods and technologies + scholarship scheme from the Erasmus Mundus Program of the European Union for EU and non-EU students + study one year each at two different partner universities in Europe + double degree + possibility to visit one of two non-European partners for a part of the study + courses and academic and administrative support in English Deadline for scholarship applications is January 10, 2016.
*************** To prospective Master students *************** • The EMMLCT program is offered by the following consortium of Universities: European partners: 1. Saarland University in Saarbruecken, Germany (coordinator) 2. University of Trento, Italy 3. University of Malta, Malta 4. University of Lorraine, Nancy, France 5. Charles University, Prague, Czech Republic 6. Rijksuniversiteit Groningen, The Netherlands 7. The University of the Basque Country / Euskal Herriko University, San Sebastian, Spain Non-European partners: 8. Shanghai Jiao Tong University, China 9. The University of Melbourne, Australia
*************** To prospective Master students *************** • The EMMLCT program is offered by the following consortium of Universities: European partners: 1. Saarland University in Saarbruecken, Germany (coordinator) 2. University of Trento, Italy 3. University of Malta, Malta 4. University of Lorraine, Nancy, France 5. Charles University, Prague, Czech Republic 6. Rijksuniversiteit Groningen, The Netherlands 7. The University of the Basque Country / Euskal Herriko University, San Sebastian, Spain Non-European partners: 8. Shanghai Jiao Tong University, China 9. The University of Melbourne, Australia