Clustering Introduccin al Aprendizaje No supervisado M Sc





 - Training set (drop convention)")



 to which")
















- Slides: 37
Clustering Introducción al Aprendizaje No supervisado M. Sc. Carlo Corrales Capitulo Ocho
Aprendizaje Supervisado Training set:
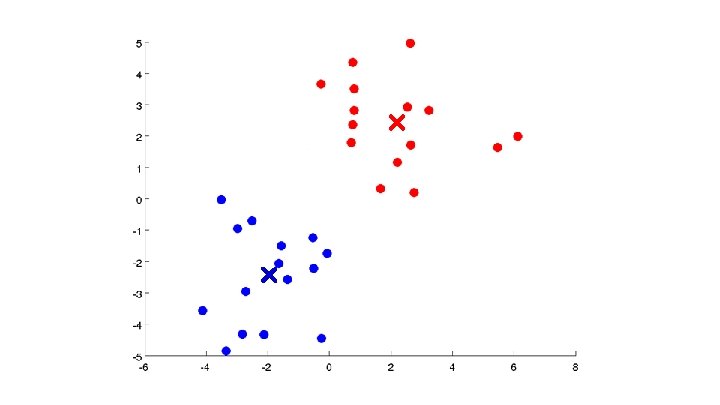
Aprendizaje no Supervisado Training set:
Aplicaciones del clustering Market segmentation Social network analysis Image credit: NASA/JPL-Caltech/E. Churchwell (Univ. of Wisconsin, Madison) Organize computing clusters Astronomical data analysis
Clustering Algoritmo K-means
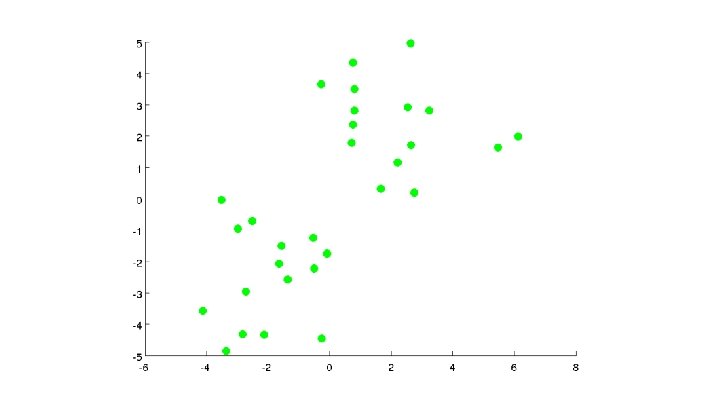
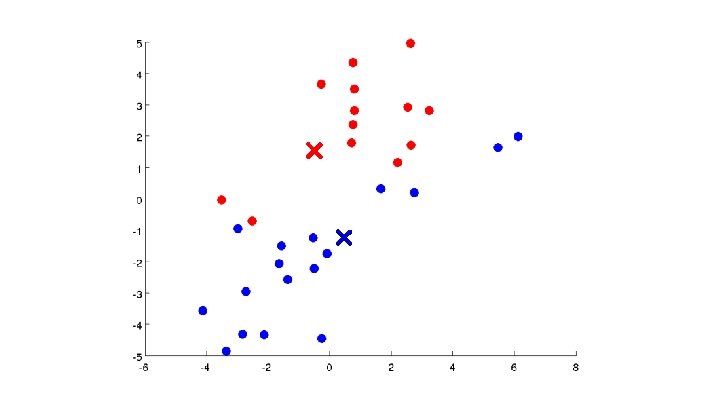
Algoritmo K-means Entrada: (número de clusters) - Training set (drop convention)
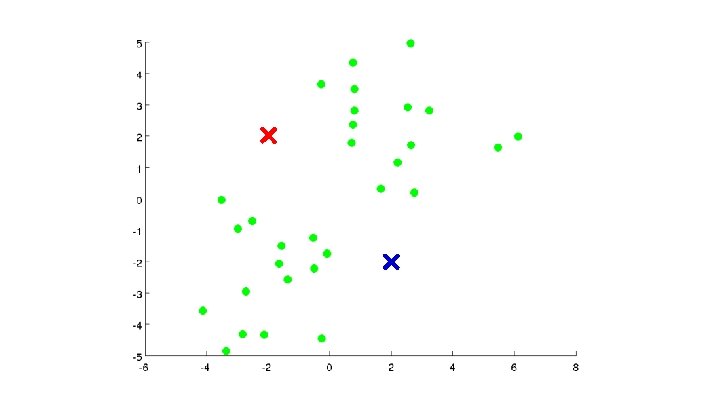
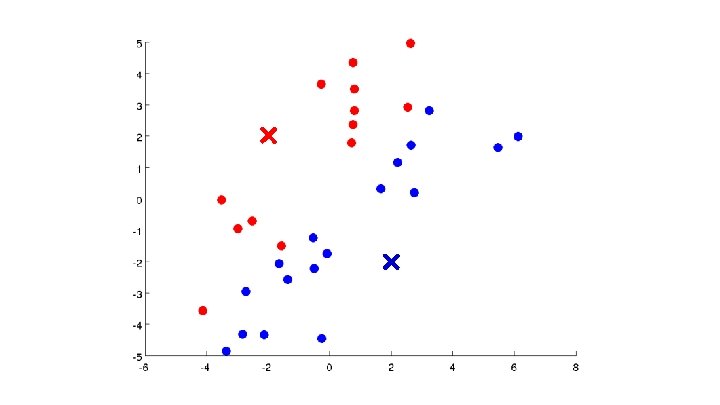
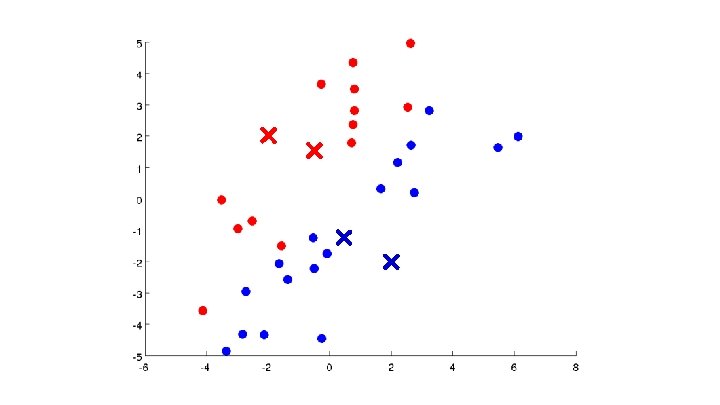
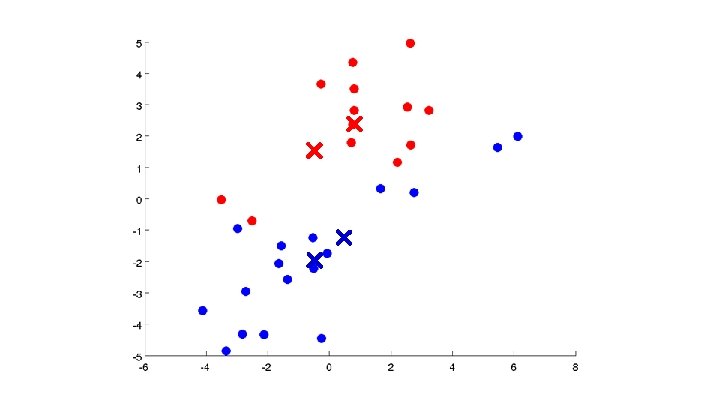
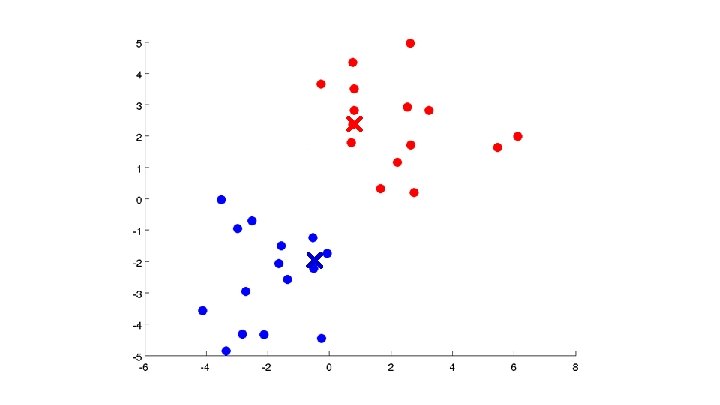
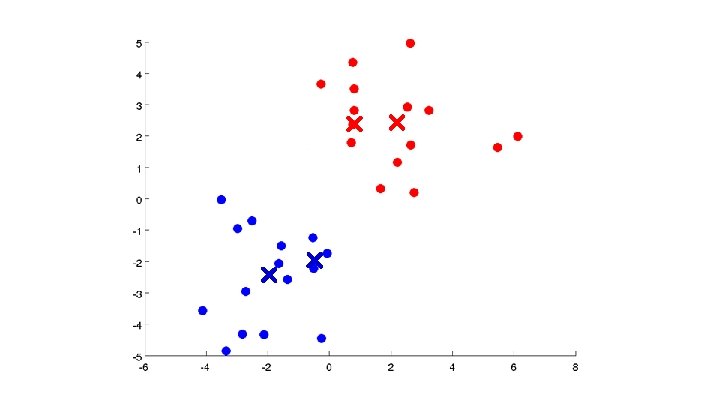
Algoritmo K-means Randomly initialize cluster centroids Repeat { for = 1 to : = index (from 1 to ) of cluster centroid closest to for = 1 to : = average (mean) of points assigned to cluster }
K-means para clusters no-separados Weight T-shirt sizing Height
Clustering Objetivo de Optimización
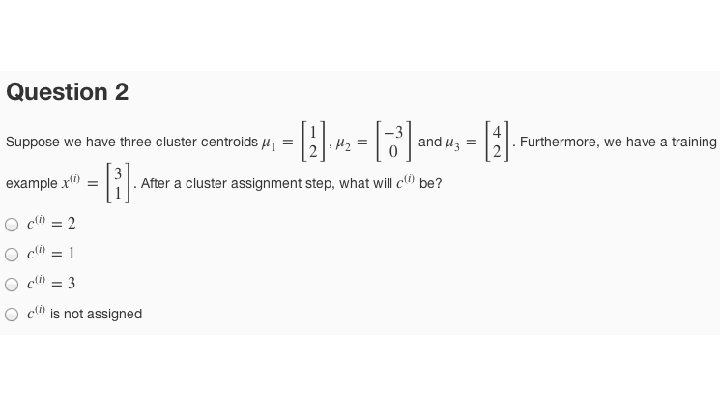
Objetivo de optimización K-means = index of cluster (1, 2, …, ) to which example assigned = cluster centroid ( ) = cluster centroid of cluster to which example assigned Optimization objective: is currently has been
Algoritmo K-means Randomly initialize cluster centroids Repeat { for = 1 to : = index (from 1 to ) of cluster centroid closest to for = 1 to : = average (mean) of points assigned to cluster }
Clustering Inicialización Aleatoria
Algoritmo K-means Randomly initialize cluster centroids Repeat { for = 1 to : = index (from 1 to ) of cluster centroid closest to for = 1 to : = average (mean) of points assigned to cluster }
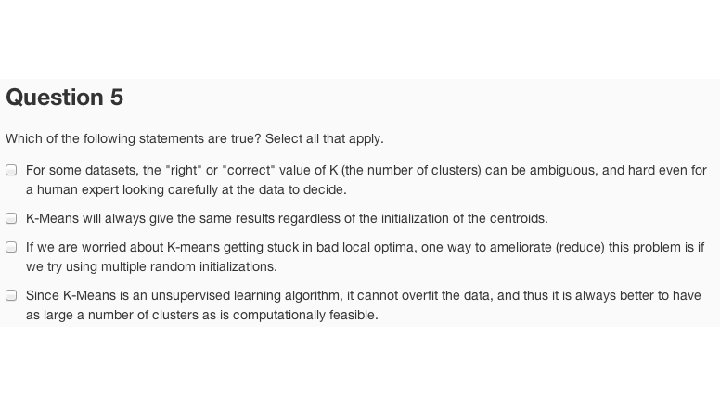
Inicialización aleatoria Should have Randomly pick examples. Set examples. training equal to these
Óptimo Local Buena solución Atrapados en óptimos locales
Inicialización Aleatoria For i = 1 to 100 { Randomly initialize K-means. Run K-means. Get Compute cost function (distortion) } Pick clustering that gave lowest cost .
Clustering Escogiendo el número de clusters
Cuál es el correcto valor de K?
Cuál es el correcto valor de K?
Escogiendo el valor de K Cost function Elbow method: 1 2 3 4 5 6 (no. of clusters) 7 8
Escogiendo el valor de K Sometimes, you’re running K-means to get clusters to use for some later/downstream purpose. Evaluate K-means based on a metric for how well it performs for that later purpose. E. g. T-shirt sizing Weight T-shirt sizing Height
Problemas
FIN