UNIX File Systems Chap 4 in the book
")
UNIX File Systems (Chap 4. in the book “the design of the UNIX OS”)

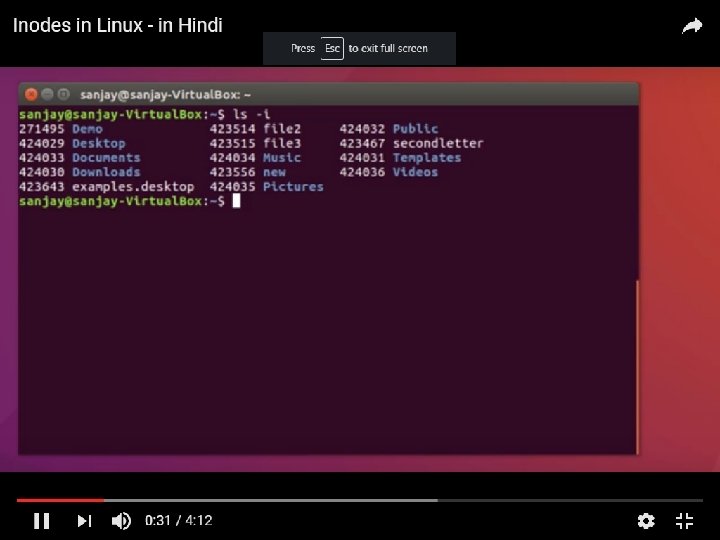
Definition of Inodes • The information of file map table is stored in a data structure is called Inode or Index Node. • Every file has a unique inode • Contain the information necessary for a process to access a file • Exist in a static form on disk • Kernel reads them into an in-core inode to manipulate them.

• This index node stores the Disk layout of the every file or every directory in the file system. • Disk Layout structure is: • • Boot block: Boot Volume Super block – state of the file system Inode List: Number of Inode Specifies the size of File system Data Blocks: Contents of any file or directory is stored in these locations and Location information available in Inodes list. BOOT BLOCK SUPER BLOCK INODE LIST DATA BLOCKS

BOOT BLOCK SUPER BLOCK INODE LIST DATA BLOCKS HOW LARGE IS THE FILE SYSTEM HOW MANY FILES IT CAN STORE WHERE TO FIND FREE BLOCKS ON THE FILE SYSTEM FREE INODES ON INODE LIST

• Two Types of Inodes: Disk Inode & Incore Inode • Whenever we open a file , want to read the contents from file , That means to find out where the data resides or where the block resides on the Disk, so we have to refer Inode. • For Every Disk access , we have to refer to Inode , which usually needs one additionally Disk access for getting information from Inode , so the no of disk access willing this , To reduce that whenever we open a file , the Inode corresponding to that file is copied from disk to Main memeory

• So As long as Inode exist in main memory it is usually maintained in the system area – it is called as In Core Inode. • So Inode on Disk is called as Disk Inode • A Copy of that on Main memory is called Incore Inode.
 File type (regular, directory, .")
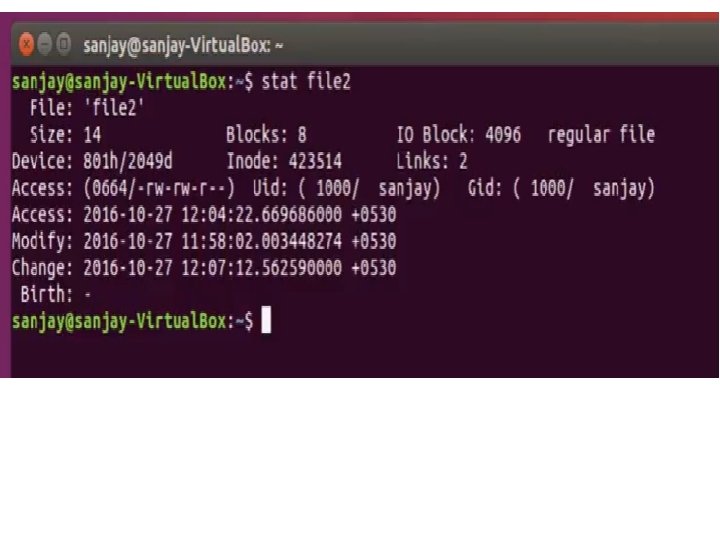
Contents of Disk Inodes File owner identifier (individual/group owner) File type (regular, directory, . . ) File access permission (owner, group, other) File access time Number of links to the file (chap 5) Table of contents for the disk address of data in a file (byte stream vs discontiguous disk blocks) • File size * Inode does not specify the path name that access the file • • •

Disk Inode Structure • OWNERSHIP Specification of a File i. e We have to specify who is the owner of a particular file • In UNIX O. S , two types of Ownerships i. e Individual ownership and GROUP OWNERSHIP • TYPE : specifies type of inode i. e Its Regular file type / directory type inode • PERMISSION: It is specified in the form of rwx, rwx (1 st Owner of the file has all three permission read , write & execute), (2 nd Group has read , write & execute ) (3 rd permission for other users)

• • • ACCESS TIME: MODIFIED TIME INODE MODIFIED TIME FILE SIZE DISK ADDRESS of different Data blocks of file

Sample Disk Inode File owner identifier File type File access permission File access time Number of links to the file • Table of contents for the disk address of data in a file • File size • • • Owner mjb Group os Type regular file Perms rwxr-xr-x Accessed Oct 23 1984 1: 45 P. M Modified Oct 22 1984 10: 3 A. M Inode Oct 23 1984 1: 30 P. M Size 6030 bytes Disk addresses

Distinction Between Writing in Inode and File • File change only when writing it. • Inode change when changing the file, or when changing its owner, permisson, or link settings. • Changing a file implies a change to the inode, • But, changing the inode does not imply that the file change.

Contents of The In-core copy of The Inode • Fields of the disk inode 1. Status of the in-core inode, indicating whether – Inode is locked – Process is waiting for the inode to become unlocked – Differ from the disk copy as a result of a change to the data in the inode – Differ from the disk copy as a result of a change to the file data

2. Logical device number of the file system that contains a file 3. Inode number (linear array on disk, disk inode does not need this field) 4. Pointers to other in-core inodes 5. Reference count, indicating the number of instances of the file that are active

Disk free

Lower Level File System Algorithms • The algorithm iget returns a previously identified inode, possible reading it from disk via the buffer cache and the algorithm iput releases this inode. • The algorithm bmap sets kernel parameter for accessing a file. • The algorithm namei converts a user-level path name to an inode, using the algorithms iget, iput, and bmap. • Algorithms alloc and free allocate and free disk blocks for files and algorithms ialloc and ifree assign and free inodes for files.

Accessing Inodes • Kernel identifies inodes by their file system and inode number • Allocate in-core inodes at the request of higherlevel algorithms (in-core inode, by iget algorithm) • Kernel maps the device number & inode number into a hash queue • Search the queue for the inode

Block Number & Byte Offset • Computing logical disk block number – Block number = ((inode number – 1) / number of inodes per block) + start block inode list • Ex: Assuming the block 2 is the beginning of the inode list and that there are 8 inodes per blocks, then inode number 8 is in disk block 2, and inode number 9 is in disk block 3. If there are 16 inodes in a disk block, then inode numbers 8 and 9 are in disk block 2, and inode number 17 is the first inode in disk block 3.

• Computing byte offset of the inode in the block – ((inode number – 1) mod (number of inodes per block)) * size of disk inode Example: If each disk inode occupies 64 bytes and there are 8 inodes per disk block, then inode number 8 starts at byte offset 448 in the disk block!

Inode Lock and Reference Count • Kernel manipulates them independently • Inode lock – Set during execution of a system call to prevent other processes from accessing the inode while it is in use. – Kernel releases the lock at the conclusion of the system call – Inode is never locked across system calls. • Reference count – Kernel increase/decrease when reference is active/inactive – Prevent the kernel from reallocating an active in-core inode

Direct and Indirect Blocks in Inode TOC Inode Direct 0 Direct 1 Direct 2 Direct 3 Direct 4 Direct 5 Direct 6 Direct 7 Direct 8 Direct 9 single indirect double indirect triple indirect 22 2020 -11 -22 Data Blocks

• Direct and Indirect Pointer mean: When I say Direct 0 is Direct Pointer means 0 th entry in Inode Table of Content(TOC), contains the address of block , which contains the file data. • All the entry from 0 th to 9 th , they all contain address of block , which contains data. • Entry 10 is a Single Direct entry pointer means , it contains the address of a block, which does not contain file data but rather it contains a set of pointers. Each of these pointers , point to a block , which contains a file data.

• 11 th entry is Double indirect entry, this entry contains the address of a block , which contains a no of pointers, each of these pointers , point to a block , which again conatins a no of pointers, these pointers in second level , they point to block , that contains the file data. • Similarly in triple indirect entry, address of a block , that contains a set of pointers , each of them points to a block which again contains a set of pointers, which of them will again points to set of block which again contains a set of pointers, finally these pointers point to block which contains file data.

Byte Capacity of a File • System V UNIX. Assume that – Run with 13 entries – 1 logical block : 1 K bytes – Block number address : a 32 bit (4 byte) integer [Address of block] • • • 1 block can hold up to 256 block number [pointers] (1024 byte / 4 byte) 10 direct blocks with 1 K bytes each =10 K bytes 1 indirect block with 256 direct blocks= 1 K*256=256 K bytes 1 double indirect block with 256 indirect blocks=256 K*256=64 M bytes 1 triple indirect block with 256 double indirect blocks=64 M*256=16 G – 256*256 k bytes = 2^34 = 16 GB • Size of a file : 4 G (232), if file size field in inode is 32 bits 25 2020 -11 -22

• With only triple indirect pointers, I can access 16 Gbytes , then if we add all direct and indirect pointers , then it will be more then 16 GBytes. • If we follow the format of Inode Table, then maximum size of a file is accessed more then 16 GBytes.

Sequence of operation during any file operation: • Whenever any process wants to make use of any file it has to get the Inode no of that file , once it gets Inode no , Inode has to be read from Secondary storage, put into main memory then becomes In. Core copy of Inode , Now once it is there in Incore copy in Main Memory then we can check the permission field (whether watever permission we have to perform on file is permitted to do or not) , For that we have to access different data in file. • For accessing different data have to check , ihave to access inode table of content , we ll get address for different data blocks. Using those address we can read the data block or modify the data block

Algorithm for allocation of in-core inodes algorithm iget input: file system inode number output: locked inode { while (not done) { if (inode in inode cache) { if (inode locked) { sleep (event inode becomes unlocked); continue; /*loop back to while */ } /*special processing for mount points */ if (inode on inode free list) remove from free list; increment inode reference count; return (inode); } /*inode not in inode cache */ if (no inodes on free list) // inodes are active by some process and No guaranty when inodes become free so Instead of putting in sleep mode it gives an error. return (error); remove new inode from free list; //other case if inode is free in inode list reset inode number and file system; remove inode from old hash queue, place on new one; read inode from disk (algorithm bread); //put diskinode in inore inode copy initialise inode (e. g. reference count to 1); return (inode); }

Algorithm iget 1. The kernel finds the inode in inode cache and it is on inode free list remove from free list increment inode reference count 2. The kernel cannot find the inode in inode cache so it allocates a inode from inode free list remove new inode from free list reset inode number and file system remove inode from old hash queue, place on new one read inode from disk(algorithm bread) initialize inode 29

Algorithm iget cont… 3. The kernel cannot find the inode in inode cache but finds the free list empty error : process have control over the allocation of inodes at user level via execution of open and close system calls and consequently the kernel cannot guarantee when an inode will become available 4. The kernel finds the inode in inode cache but it was locked sleep until inode becomes unlocked 30
, it decrements in-core")
Releasing Inodes • When the kernel releases an inode (algorithm iput), it decrements in-core reference count. • If the count drops to 0, the kernel writes the inode to disk , if the in-core copy differs from the disk copy. They differ if the file data has changed, if the file access time has changed or if the file owner or access permissions have changed. • The kernel places the inode on the free list of inodes, effectively caching the inode in case it is needed again soon. The kernel may release all data blocks associated with the file and free the inode if the number of links to the file is 0.

Algorithm iput - The kernel locks the inode if it has not been already locked - The kernel decrements inode reference count - The kernel checks if reference count is 0 or not - If the reference count is 0 and the number of links to the file is 0, then the kernel releases disk blocks for file(algorithm free), free the inode(algorithm ifree) • If the file was accessed or the inode was changed or the file was changed , then the kernel updates the disk inode • The kernel puts the inode on free list - If the reference count is not 0, the kernel releases the inode lock 32
 //release. Incore. Inode – Input: pointer to In core inode – Output:")
iput (inode_no) //release. Incore. Inode – Input: pointer to In core inode – Output: none { lock inode if not locked decrement inode refernece count if (refernce count==0) { if (inode link==0) { free disk block set file type to 0 free inode } if (file accessed or inode changed or file changed) – update disk inode } put inode on free list Release inode lock } 33

Directories • A directory is a file whose data is a sequence of entries, each consisting of an inode number and the name of a file contained in the directory • Path name is a null terminated character string divided by slash (“/”) • Each component except the last must be the name of a directory, last component may be a non-directory file • Directory layout for /etc Byte Offset in Directory 0 16 32 48 Inode Number 83 2 1798 61 File Name. . . init passwd • Passwd [ This indicates if we are in the current direcctory , accessing file passwd] • /etc/ passwd [ To access file passwd, path name for passwd] 34

Directory Layout for /etc • with a 2 byte entry for the inode number, the size of a directory entry is 16 bytes.

• Every directory contains the file names dot and dot-dot (". " and “. . ") whose inode numbers are those of the directory and its parent directory, respectively. • The inode number of ". " in "/etc" is located at offset 0 in the file, and its value is 83. The inode number of ". . " is located at offset 16, and its value is 2. Directory entries may be empty, indicated by an inode number of 0. • The kernel stores data for a directory just as it stores data for an ordinary file, using the inode structure and levels of direct and indirect blocks.

• Processes may read directories in the same way they read regular files, but the kernel reserves exclusive right to write a directory, thus insuring its correct structure. • The access permissions of a directory have the following meaning: read permission on a directory allows a process to read a directory; write permission allows a process to create new directory entries or remove old ones (via the creat, mknod, link, and unlink system calls).

• So whichever the way I specify the file , i have to find out what is the inode number of corresponding file or Directory which we interesting. • There should be an algorithm , which converts path name or file name to corresponding inode number. • Let us call this algorithm is namei Algorithm.

Algorithm for conversion of path name to an inode algorithm namei /* convert path name to inode */ input: path name output: locked inode { if (path name starts from root) /* first check whether path name starts from root or current directory */ working inode = root inode (algorithm iget); else working inode = current directory inode (algorithm iget); while (there is more path name) { read next path name component from input; verify that working inode is of directory, access permissions OK; /* Permission to search in directory i. e read directory */ if (working inode is of root and component is “. . ”) continue; /*loop back to while */ read directory (working inode) by repeated use of algorithms bmap, bread and brelse; if (component matches an entry in directory (working inode)) { get inode number for matched component; release working inode (algorithm iput); working inode = inode of matched component (algorithm iget); } else /*component not in directory */ return (no inode); } return (working node); }

• namei uses intermediate inodes as it parses a path name; call them working inodes. The inode where the search starts is the first working inode.

• For example, suppose a process wants to open the file "/etc/passwd". When the kernel starts parsing the file name, it encounters "/" and gets the system root inode. Making root its current working inode, the kernel gathers in the string "etc". • After checking that the current inode is that of a directory ("/") and that the process has the necessary permissions to search it, the kernel searches root for a file whose name is "etc": It accesses the data in the root directory block by block and searches each block one entry at a time until it locates an entry for "etc".

• On finding the entry, the kernel releases the inode for root (algorithm iput) and allocates the inode for "etc" (algorithm iget) according to the inode number of the entry just found. • After ascertaining the “etc” is a directory and that it has the requisite search permissions, the kernel searches “etc” block by block for the file “passwd”. On finding it, releases the inode for “etc” and allocate sthe inode for “passwd” and… returns that inode

• Till now all algorithms assumes inode is already allocated to a file • namei also assumes inode is already bound to a file or directory which is requested. • Now if I want open a file for creation, want to create a file, in that case inode is not allocated to a file, we have to get inode and allocate that new inode to file, which is not allocated to any file or any directory so far. • And that new inode is allocated to newly created file

• So the operation involved is , you have to search for such an unallocated inode from inode list. i. e list of inodes are there in inode block. • Super blocks contains number of information including

Super block • File System boot block super block inode list data blocks • consists of - the size of the file system - the number of free blocks in the file system - a list of free blocks available on the file system - the index of the next free block in the free block list - the size of the inode list - the number of free inodes in the file system - a list of free inodes in the file system - the index of the next free inode in the free inode list - lock fields for the free block and free inode lists - a flag indicating that the super block has been modified 45

Super block free inode list 499 402 401 400 Remembered inode • 1 st Inode no 400 is head of the list, itshould be minimum of inode integer. • All entries in the super block free inode list is full. • Whenever a process ask for inode then inode 400 is given to process for allocating to file or directory. • After this , 1 st entry 400 is empty Next time another process wants to create new file or directory , then next inode 401 will be given to that process and it will continue till end 499 entry. • So whenever a process puts a request for a new inode always this super inode free list is checked first, if there is inode in freelist then inode will be given from list. • Out of this last inode 499 or highest numbered inode is called Remembered inode

• Suppose I have a situation , All 100 inodes have been allocated, when inode 499 allocated then inode list becomes empty. • Next time another process puts a request for inode then it will check super block free inode list , it finds no free inode in free list, so it has get inode from Disk. • Highest number inode gives an indication that where a free new inode is available on disk inode.

• Whenever super block inode list is empty , kernel will read next 100 inodes and fill up the super block free inode list. • Assuming that all other inodes from 500 onwards are all free i. e unallocated • i. e After filling inode super block list 500 inode is given to process 599 502 501 500

599 598 597 Free inodes … … Empty Put unallocated entry In Empty entries

algorithm ialloc: Inode assignment to a new file • algorithm ialloc : assigns a disk inode to a newly created file -super block is locked 1. There are inodes in super block free inode list and inode is free get inode number from super block inode list get inode (iget) initialize inode write inode to disk decrement file system free inode count 2. If super block is locked, sleep 50

Inode assignment to a new file 3. Inode list in super block is empty lock super block get remembered inode for free inode search disk for free inode until super block full or no more free inodes(bread and brelse) unlock super block becomes free if no free inodes found on disk , stop otherwise, set remembered inode for next free inode search - 51

ialloc Algorithm for assigning new inodes algorithm ialloc /* allocate inode */ input: file system output: locked inode { while (not done) { if (super blocked) { sleep (event super block becomes free); continue; /*loop back to while */ } if (inode list in super block is empty) { lock super block; /* working on super block – copy unallocated or free inodes in super block free list*/ get remembered inode for free inode search; search disk for free inodes until super block full, or no more free inodes (algorithms bread and brelse); /* if super block inode list contains 100 entry , then we can put 100 inodes maximum */ unlock super block; wake up (event super block becomes free); /* wake up all process */ if (no free inodes found on disk) /* super block was empty , i couldn’t found any unallocated inodes on disk which unallocated can be copied to super block free list */ return (no inode); set remembered inode for next free inode search; /* otherwise if we get one or more inode on disk which are then to facilitate search operation for next free inode no then we have to set remember inode */ } /*there are inodes in super block inode list */ /*inode is free */ get inode number form super block inode list; get inode (algorithm iget); /* incore inode */ initialise inode; /* increse reference count to 1 */ write inode to disk; decrement file system free inode count; return (inode); } }

Algorithm ifree - The kernel increments file system free inode count - If super block is locked, avoids race conditions by returning - If super block is unlock and inode list is full , • If inode number is less than remembered inode for search, then the kernel remembers the newly freed inode number, discarding the old remembered inode number from the super block - If super block is unlock and inode list is not full, then the kernel stores inode number in inode list 53
 { Increment free inode count ; If (super blocked )")
Freeing inode • ifree(inode_no) { Increment free inode count ; If (super blocked ) return ; If (Super block free inode list full) //at super block { Else } if (inode number < remembered inode) Set remembered inode = input inode number; Store inode number in super block inode list } return; 54

• We have seen that when a process creates a file then how the new inode is allocated to file or when the process deletes a file or directory then how the inode number is free and it has to be reflected in super block inode free list if possible.

• Now when a process opens a file or Directory then naturally there will be some modification in file or directory. • i. e a process require data blocks , earlier we have seen inode for every file or directory. • To store content of file or directory , the process will need data blocks where the contents of file or directory is stored. • As in case of inode allocation , when you allocate a new free inode for new process , lly the process will request for new data blocks which are free.

• Also the process will release the data blocks, if the file size is reduced or even in case file is deleted then all data blocks occupied by data of file has to be released and they has to go free data block list. • To help this process of allocation of data blocks or removal of data blocks , the super block contains a list called super block free data block list. • The way super block free block list is maintained different from the way inodes are maintained.

• When you say super block free block list , we can assume that it is single block which will contain a list of other data block number which are free so this part is similar to super block inode list where it contains free inodes. • In super block free block list, all free blocks are maintained in form of linked list.

Allocation of disk blocks 109 106 103 100 …………… 84. . 80 109 211 208 205 202 ………………… 112 211 310 307 304 301 ………………… 214 310 409 406 403 400 ………………… 313 linked list of free disk block number 60

• Block no 109 is pointer to block no 109. • Block no 109 contains no of entries with number of free blocks in file system • It is maintained in the form of linked list. (Block no 109 Pointer to block no 109, Block no 109 contains additional list of other free blocks) • This type of structure is necessary to tell what are free data blocks and it is responsibility of make file system (mkfs) function to organize data blocks in the form of linked list. • So all data blocks are part of linked list and some data blocks are link blocks(108, 211).

• Whenever a process request a free block , it goes to super block free block list , it takes out block 80, Next time it takes out block no 84 and so on.

Algorithm alloc - The kernel wants to allocate a block from a file system it allocates the next available block in the super block list - Once allocated , the block cannot be reallocated until it becomes free - If the allocated block is the last block , the kernel treats it as a pointer to a block that contains a list of free blocks • The kernel locks super block, reads block jut taken from free list, copies block numbers in block into super block, releases block buffer, and unlocks super block - Otherwise, • The kernels gets buffer for block removed from super block list , zero buffer contents, decrements total count 63 of free blocks, and marks super block modified

Algorithm for Allocating Disk Block Algorithm alloc /* file system block allocation */ Input : file system number Output : buffer for new block { while(super blocked) sleep (event super block not locked); remove block from super block free list; if(removed last block from free list) { lock super block; read block just taken from free list (algorithm bread); copy block numbers in block into super block; release block buffer (algorithm brelse); unlock super block; wake up processes (event super block not locked); } 2020 -11 -22 64 …

Algorithm for Allocating Disk Block … get buffer form block removed from super block list (algorithm getblk); zero buffer contents; decrement total count of free blocks; mark super block modified; return buffer; } 65 2020 -11 -22

Allocation of disk blocks super block list 109 …………………………… 109 211 208 112 109 211 112 205 202 ………………. . original configuration 949 …………………………. . 208 205 202 ………………. After freeing block number 949 66

Allocation of disk blocks 211 |208 | 205 | 202 ………………. |112 109 ……………………………. . 109 211 208 112 211 344 341 243 205 338 202 ………………. 335 ………………. After assigning block number(109) replenish super block free list 67

- Slides: 68