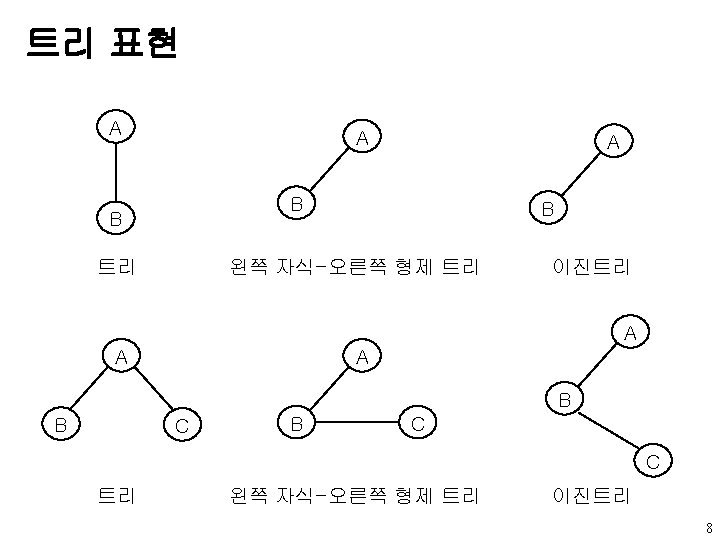
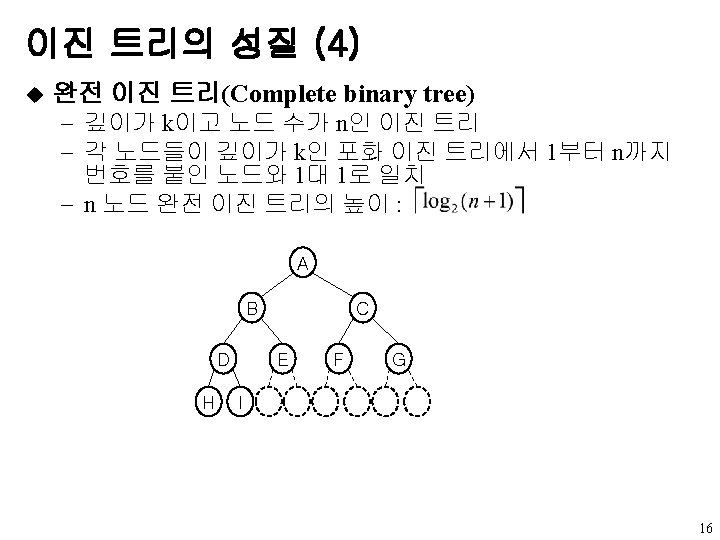
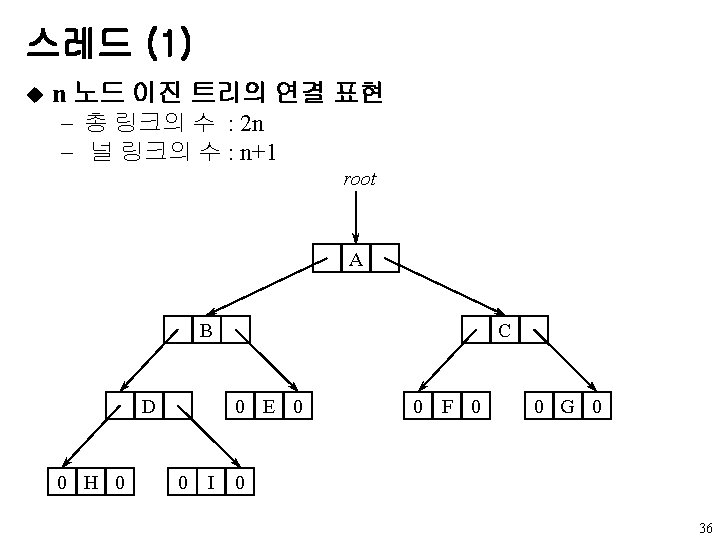
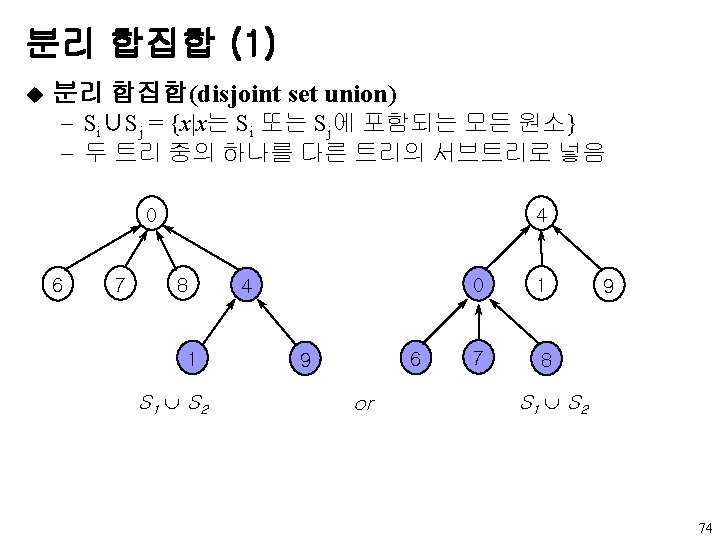
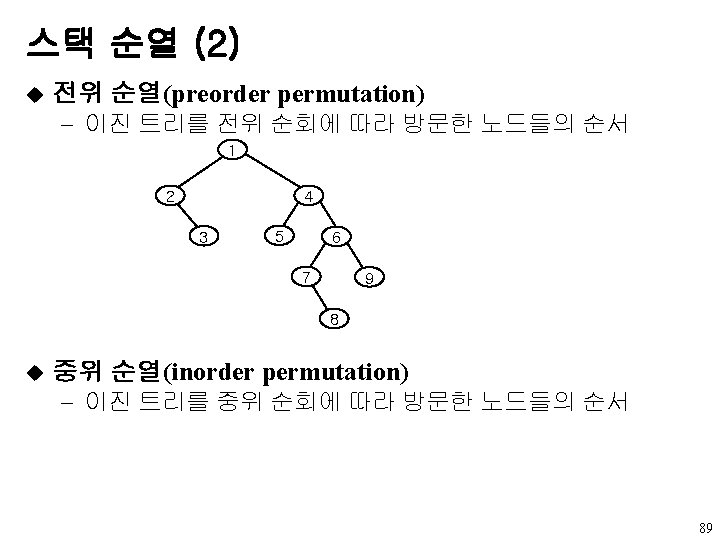
u data left child right sibling u A

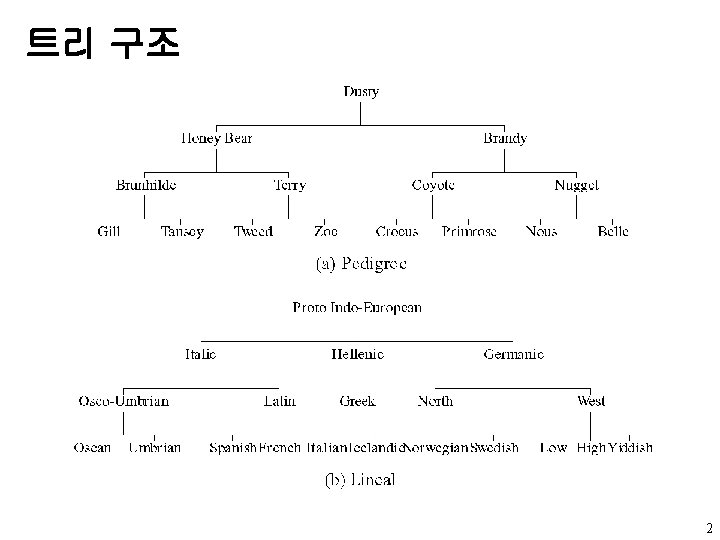


왼쪽 자식-오른쪽 형제 표현 u 노드 구조 data left child right sibling u 트리 A B E K L F C G D H I J M 6

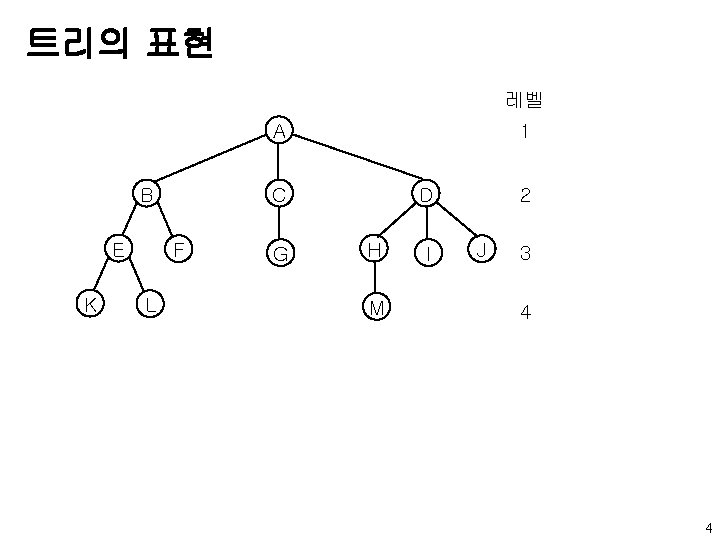
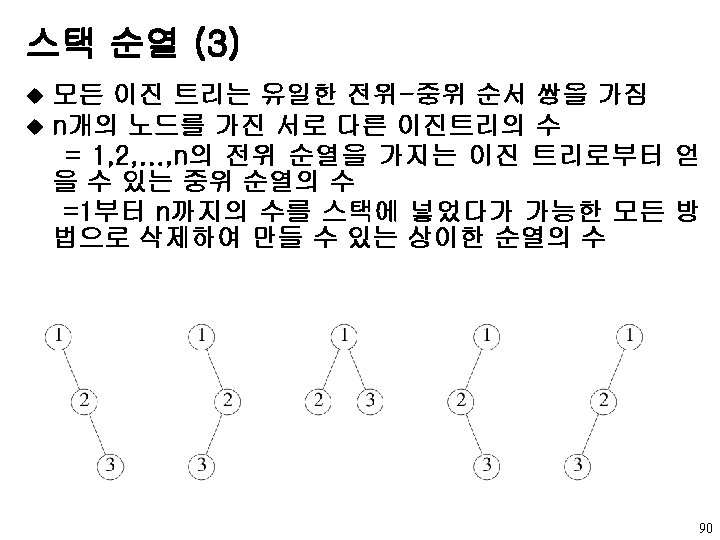
 object: 공백이거나 루트 노드, 왼쪽")
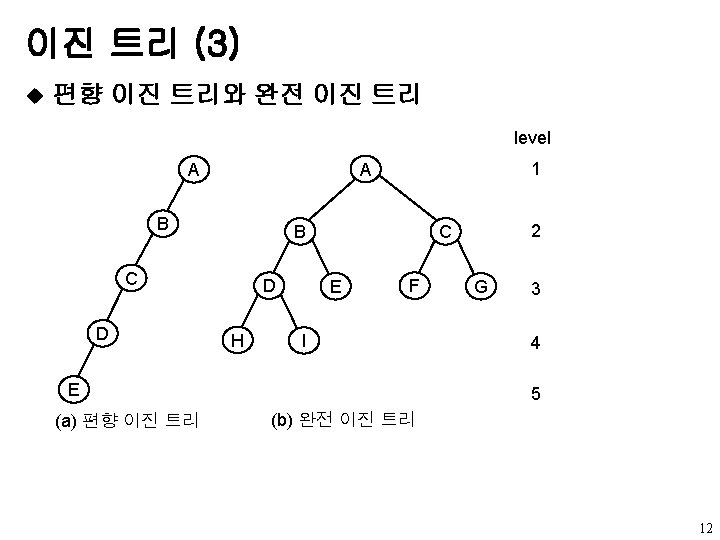
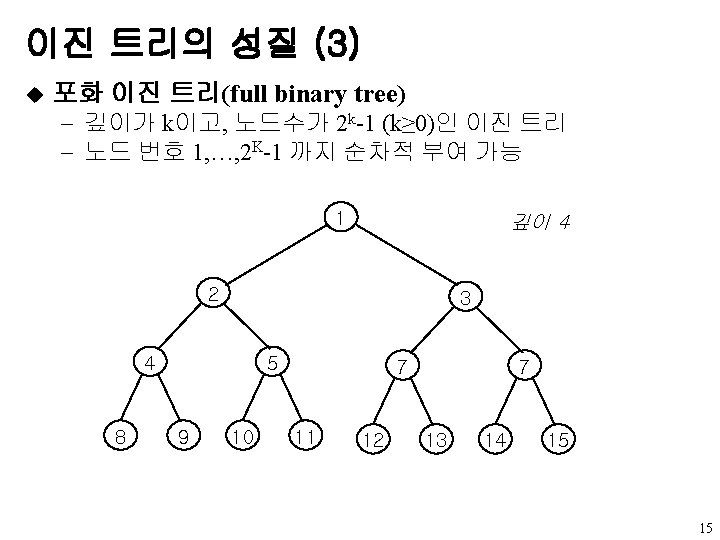
Binary. Tree 추상 데이타 타입 ADT Binary_Tree(줄여서 Bin. Tree) object: 공백이거나 루트 노드, 왼쪽 Binary_Tree, 오른쪽 Binary_Tree로 구성되는 노드들의 유한집합 functions: 모든 bt, bt 1, bt 2 ∈ Bin. Tree, item ∈ element Bin. Tree Create() : : = 공백 이진 트리를 생성 Boolean Is. Empty(bt) : : = if (bt == 공백 이진트리) return TRUE else return FALSE Bin. Tree Make. BT(bt 1, item, bt 2) : : = 왼쪽 서브트리가 bt 1, 오른쪽 서브트리가 bt 2, 루트는 데이타를 갖는 이진 트리를 반환 Bin. Tree Lchild(bt) : : = if(Is. Empty(bt)) return 에러 else bt의 왼쪽 서브트리를 반환 element Data(bt) : : = if(Is. Empty(bt)) return 에러 else bt의 루트에 있는 데이타를 반환 Bin. Tree Rchild(bt) : : = if(Is. Empty(bt)) return 에러 else bt의 오른쪽 서브트리를 반환 10



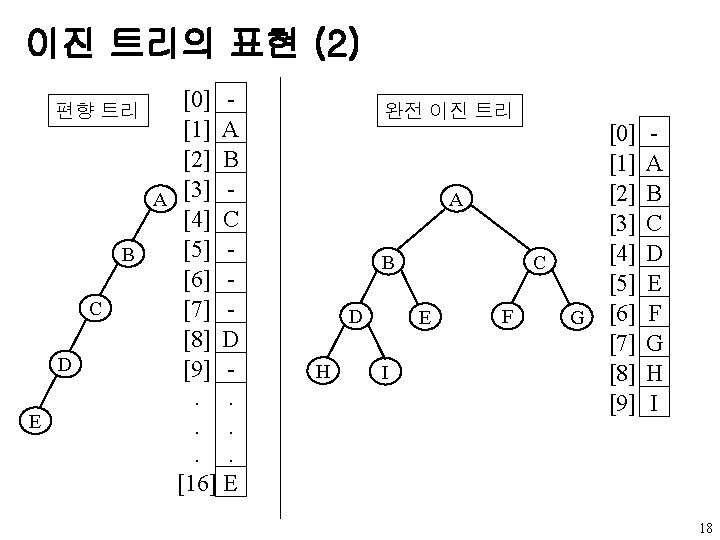
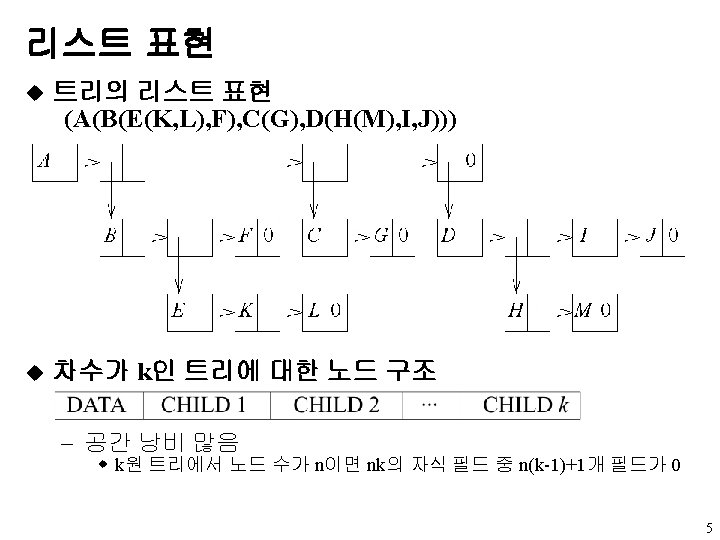
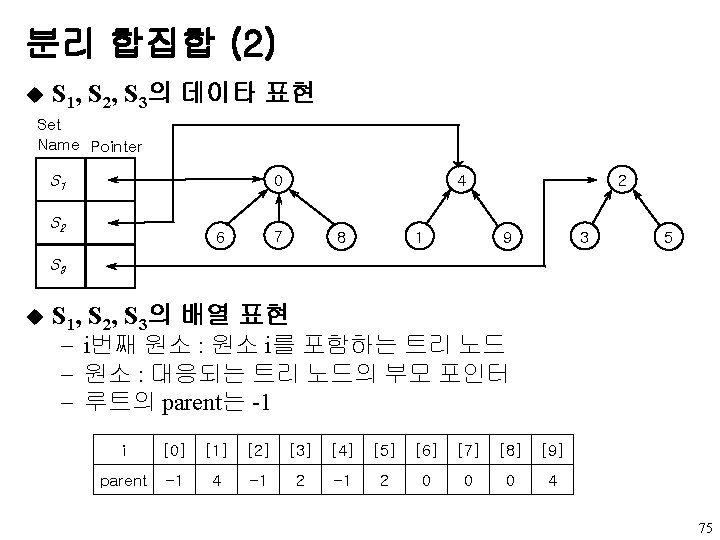
 u 연결 표현 - 노드 표현 data left child data")
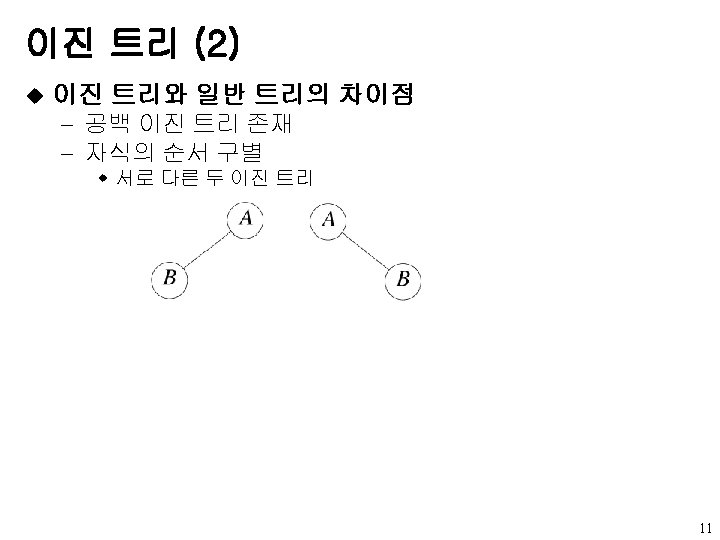
이진 트리의 표현 (4) u 연결 표현 - 노드 표현 data left child data right child Left. Child Right. Child typedef struct node * tree. Pointer; typedef struct node{ int data; tree. Pointer left. Child, right. Child; }; - 부모 알기 어려움 w parent 필드 추가 19
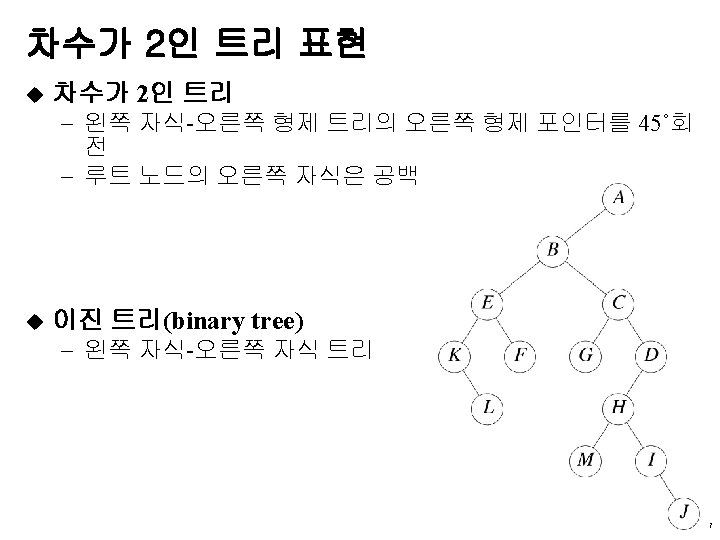
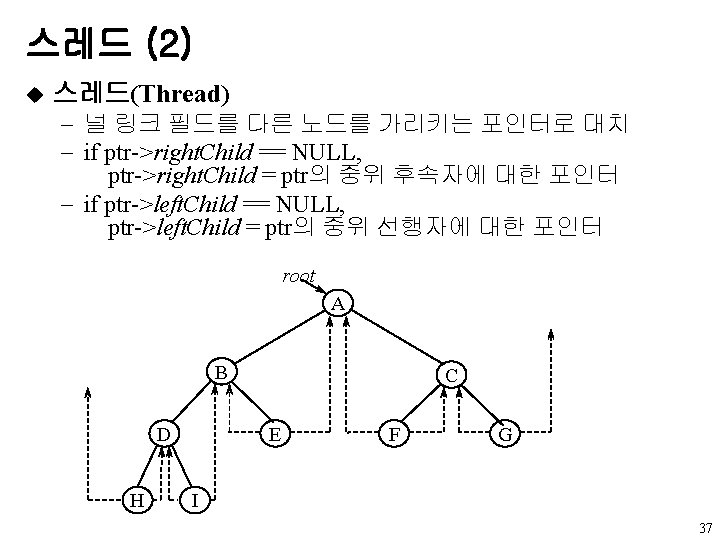
 u 연결 표현의 예 A root B A 0 B")
이진 트리의 표현 (5) u 연결 표현의 예 A root B A 0 B 0 C C 0 D D 0 E 0 root A A B D H E I B C F C D G 0 H 0 E 0 0 I 0 F 0 0 G 0 0 20
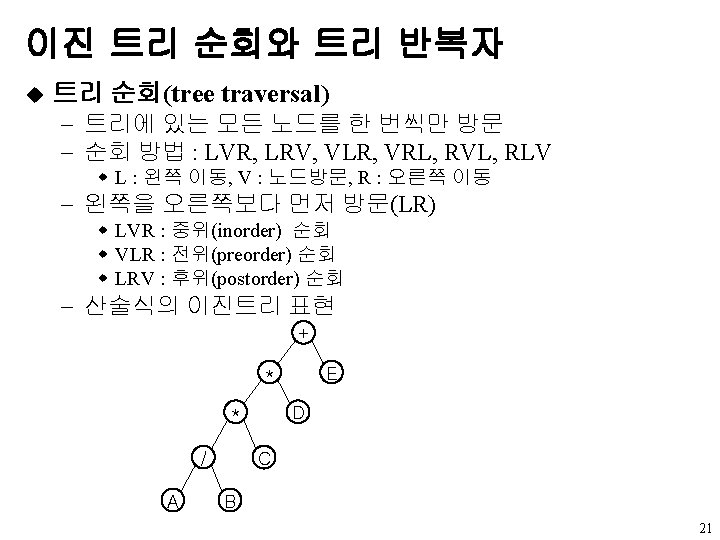
 u LVR : A/B*C*D+E void inorder(tree. Pointer ptr) /* 중위 트리")
중위 순회 (1) u LVR : A/B*C*D+E void inorder(tree. Pointer ptr) /* 중위 트리 순회 */ { if (ptr) { inorder(ptr->left. Child); printf(“%d”, ptr->data); inorder(ptr->right. Child); } } 22
 Call of inorder 1 2 3 4 5 6 5 7")
중위 순회 (2) Call of inorder 1 2 3 4 5 6 5 7 4 8 9 8 10 3 Value in root + * * / A NULL / B NULL * Action printf inorder 11 12 11 13 2 14 15 14 16 1 17 18 17 19 in root C NULL * D NULL + E NULL Value Action printf printf 출력 : A/B*C*D+E 23

전위 순회 u VLR : + * * / A B C D E void preorder(tree. Pointer ptr) /* 전위 트리 순회 */ { if (ptr) { printf(“%d”, ptr->data); preorder(ptr->left. Child); preorder(ptr->right. Child); } } 24
 u LRV : A B / C * D * E")
후위 순회(Postorder traversal) u LRV : A B / C * D * E + void postorder(tree. Pointer ptr) /* 후위 트리 순회 */ { if (ptr) { postorder(ptr->left. Child); postorder(ptr->right. Child); printf(“%d”, ptr->data); 25
")
반복적 중위 순회 u 중위 순회를 위한 비순환 프로그램 void iter. Inorder(tree. Pointer node) { int top = -1; /* 스택 초기화 */ tree. Pointer stack[MAX_STACK_SIZE]; for (; ; ) { for (; node = node->left. Child) add(&top, node); /*스택에 삽입 */ node = delete(^top); /*스택에서 삭제 */ if (!node) break; /* 공백 스택 */ printf(“%d”, node->data); node = node->right. Child; } } - 시간 복잡도 w O(n) - 저장 공간 w O(n) 26

레벨 순서 순회 u u u 큐 사용 루트 방문->왼쪽 자식 방문->오른쪽 자식 방문 +*E*D/CAB void level. Order(tree. Pointer ptr) /* 레벨 순서 트리 순회 */ { int front = rear = 0; tree. Pointer queue[MAX_QUEUE_SIZE]; if (!ptr) return; /* 공백 트리 */ addq(front, &rear, ptr); for ( ; ; ) { ptr = deleteq(&front, rear); if (ptr) { printf(“%d”, ptr->data); if (ptr->left. Child) addq(front, &rear, ptr->left. Child); if (ptr->right. Child) addq(front, &rear, ptr->right. Child); } else break; } } 27

 /* 주어진")
이진 트리의 복사 u 이진 트리의 복사 tree. Pointer copy(tree. Pointer original) /* 주어진 트리를 복사하고 복사된 트리의 tree. Pointer를 반환한다. */ { tree. Pointer temp; if (orginal) { temp = (tree. Pointer) malloc(sizeof(node)); if ( IS_FULL(temp)) { fprintf(stderr, “The memory is fulln”); exit(1); } temp->left. Child = copy(original->left. Child); temp->right. Child = copy(original->right. Child); temp->data = original->data; return temp; } return NULL; } 29

동일성 검사 u 두 이진 트리가 동일한지 검사 int equal(tree. Pointer first, tree. Pointer second) {/* 두 이진 트리가 동일하면 TRUE, 그렇지 않으면 FALSE를 반환한다. */ return ((!first && !second) || (first && second && (first->data == second->data) && equal(first->left. Child, second->left. Child) && equal(first->right. Child, second->right. Child)); } 30

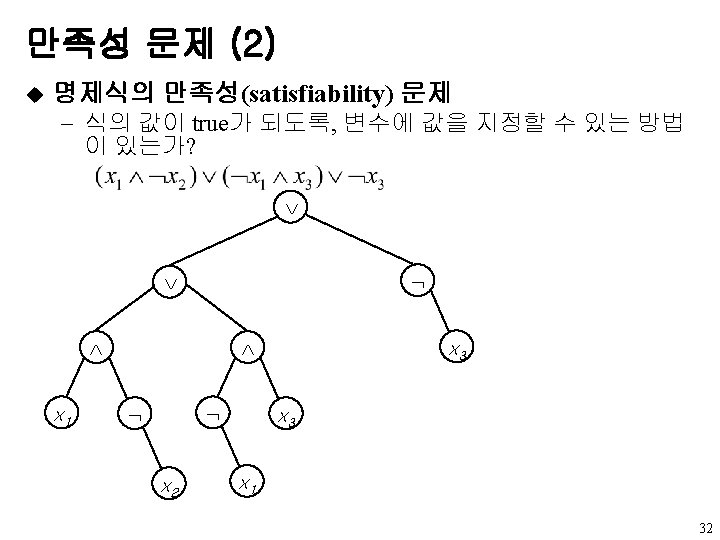
 u 만족성 문제를 위한 노드 구조 left. Child data value right.")
만족성 문제 (3) u 만족성 문제를 위한 노드 구조 left. Child data value right. Child typedef enum {not, and, or, true, false} logical; typedef struct node *tree. Pointer; typedef struct node { tree. Pointer left. Child; logical data; short int value; tree. Pointer right. Child; }; 33
 u 만족성 알고리즘의 첫 번째 버전 - 리프의 data는 이 노드가")
만족성 문제 (4) u 만족성 알고리즘의 첫 번째 버전 - 리프의 data는 이 노드가 나타내는 변수의 현재 값을 가짐 - root가 n개의 변수를 갖는 명제식의 트리를 가리킴 for (all 2 n possible combinations) { generate the next combination; replace the variables by their values; evaluate root by traversing it in postorder; if (root->value) { printf(<combination>); return; } } printf(“No satisfiable combinationn”); 34
 u 후위 순회 연산 함수 void post. Order. Eval(tree. Pointer node)")
만족성 문제 (5) u 후위 순회 연산 함수 void post. Order. Eval(tree. Pointer node) {/* 명제 해석 트리를 계산하기 위해 수정된 후위 순회 */ if (node) { post. Order. Eval (node->left. Child); post. Order. Eval (node->right. Child); switch(node->data) { case not: node->value = !node->right. Child->value; break; case and: node->value = node->right. Child->value && node->left. Child->value; break; case or: node->value = node->right. Child->value || node->left. Child->value; break; case true: node->value = TRUE; break; case false: node->value = FALSE; } } } 35
 u 노드 구조 left. Thread left. Child data right. Child true right.")
스레드 (3) u 노드 구조 left. Thread left. Child data right. Child true right. Thread false - left. Thread == false if left. Child가 포인터 == true if left. Child가 스레드 - right. Thread == false if right. Child 가 포인터 == true if right. Child 가 스레드 u 헤드 노드 - 분실 스레드 문제 해결 38

스레드 이진 트리의 메모리 표현 root f f t H D t B f t f E t f f f t I A - t F C t f t G t t f = false; t = true 39

스레드 이진 트리의 중위 순회 스택을 이용하지 않고 중위 순회 가능 u 중위 순회의 후속자 u - x->right. Thread == true : x->right. Child == false : 오른쪽 자식의 왼쪽 자식 링크를 따라 가서 Left. Thread==true인 노드 u 스레드 이진 트리에서 중위 후속자의 탐색 threaded. Pointer insucc(threaded. Pointer tree) {/* 스레드 이진 트리에서 중위 후속자를 찾는다. */ threaded. Pointer temp; temp = tree->right. Child; if (!tree->right. Thread) while (!temp->left. Thread) temp = temp->left. Child; return temp; } 40

스레드 이진 트리의 중위 순회 u 스레드 이진 트리에서 중위 순회 void tinorder(threaded. Pointer tree) {/* 스레드 이진 트리의 중위 순회 */ threaded. Pointer temp = tree; for ( ; ; ) { temp = insucc(temp); if (temp = tree) break; printf(“%3 c”, temp->data); } } 41
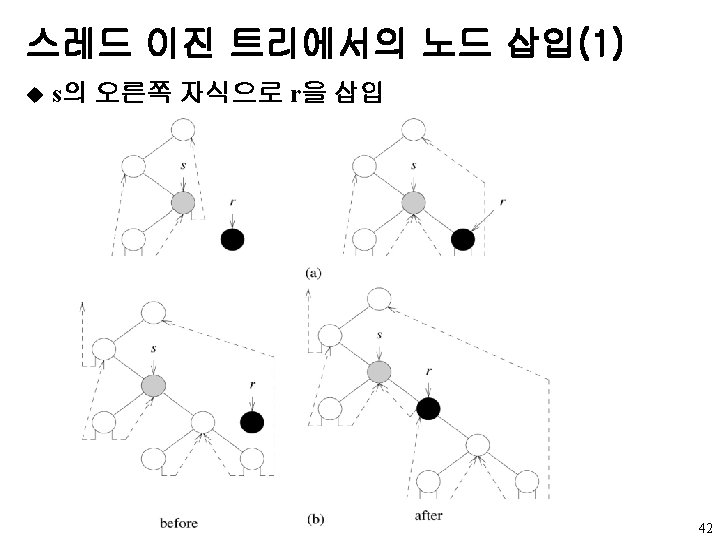
 u s의 오른쪽 자식으로 r을 삽입 void insert. Right(threaded.")
스레드 이진 트리에서의 노드 삽입(2) u s의 오른쪽 자식으로 r을 삽입 void insert. Right(threaded. Pointer s, threaded. Pointer r) {/* 스레드 이진 트리에서 r을 s의 오른쪽 자식으로 삽입 */ threaded. Pointer temp; r->right. Child = parent->right. Child; r->right. Thread = parent->right. Thread; r->left. Child = parent; r->left. Thread = TRUE; s->right. Child = child; s->right. Thread = FALSE; if (!r->right. Thread) { temp = insucc(r); temp->left. Child = r; } } 43
 원소를 먼저 삭제 u 임의의 우선순위를 가진 원소 삽입")
우선순위 큐 우선순위가 가장 높은(낮은) 원소를 먼저 삭제 u 임의의 우선순위를 가진 원소 삽입 가능 u 추상 데이타 타입 Max. Priority. Queue u ADT Max. Priority. Queue is objects: a collection of n>0 elements, each element has a key functions: for all q ∈ Max. Priority. Queue, item ∈ Element, n ∈ integer Max. Priority. Queue create(max_size) : : = create an empty priority queue. Boolean is. Empty(q, n) : : = if(n>0) return TRUE; else return FALSE; Element top(q, n) : : = if(!is. Empty(q, n)) return an instance of the largest element in q else return error. Element pop(q, n) : : = if(!is. Empty(q, n)) return an instance of the largest element in q and remove it from the heap else return error. Max. Priority. Queue push(q, item, n) : : = insert item into pq and return the resulting priority queue. 44

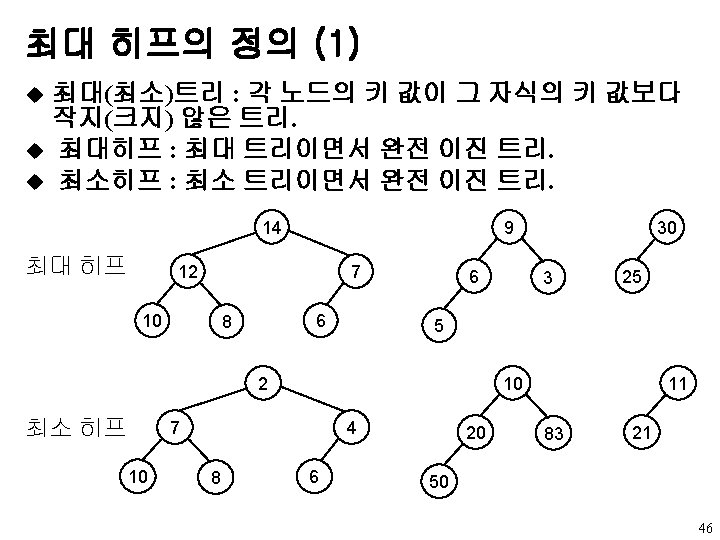
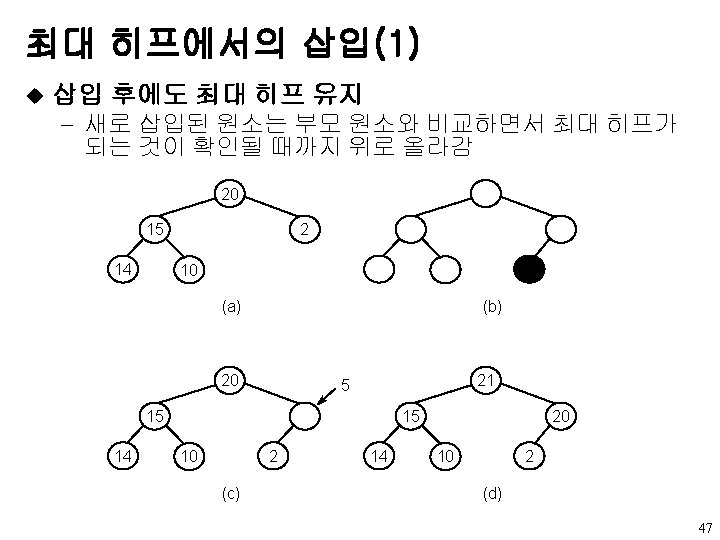
 {/* insert item into a max")
최대 히프에서의 삽입 void push(element item, int *n) {/* insert item into a max heap of current size *n */ int i; if (HEAP_FULL(*n)){ fprintf(stderr, “The heap is full. n”); exit(EXIT_FAILURE); } i = ++(*n); while ((i != 1) && (item. key > heap[i/2]. key)){ heap[i] = heap[i/2]; i /= 2; } heap[i] = item; } u 복잡도 : O(log 2 n) 48
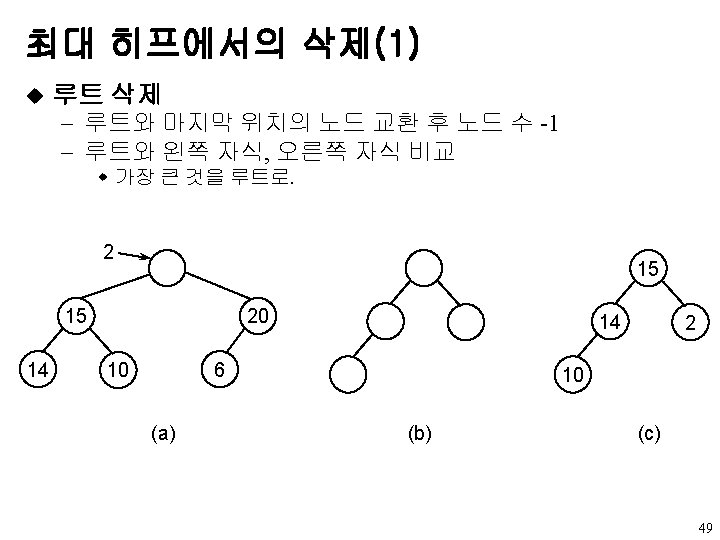
 element pop(int *n) { int parent, child; element item, temp; if(HEAP_EMPTY(*n))")
최대 히프에서의 삭제(2) element pop(int *n) { int parent, child; element item, temp; if(HEAP_EMPTY(*n)) { fprintf(stderr, “The heap is emptyn”); exit(EXIT_FAILURE); } item = hea[1]; temp = heap[(*n)--]; parent = 1; child = 2; while(child<= *n){ if (child< *n) && (heap[child]. key < heap[child+1]. key) child++; if(temp. key >= heap[child]. key) break; heap[parent] = heap[child]; parent = child; child *= 2; } u 복잡도 : heap[parent] = temp; return item; } O(log n) 50
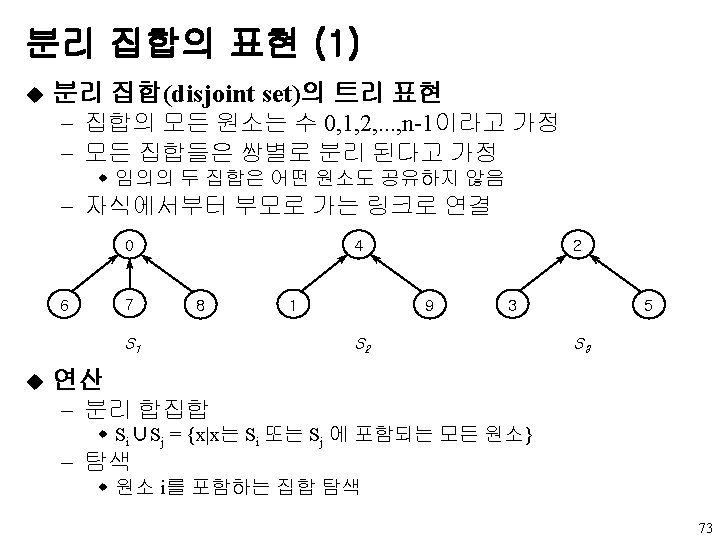
 - pair<키, 원소>의 집합 ADT Dictionary is objects: a")
이원 탐색 트리 u 사전(dictionary) - pair<키, 원소>의 집합 ADT Dictionary is objects: a collection of n>0 pairs, each pair has a key and an associated item functions: for all d∈Dictionary, item ∈ Item, k ∈ Key, n∈ integer Dictionary Create(max_size) : : = create an empty dictionary Boolean Is. Empty(d, n) : : = if(n>0) return TRUE else return FALSE Element Search(d, k) : : = return item with key k, return NULL if no such element. Element Delete(d, k) : : = delete and return item (if any) with key k; void Insert(d, item, k) : : = insert item with key k into d. 51
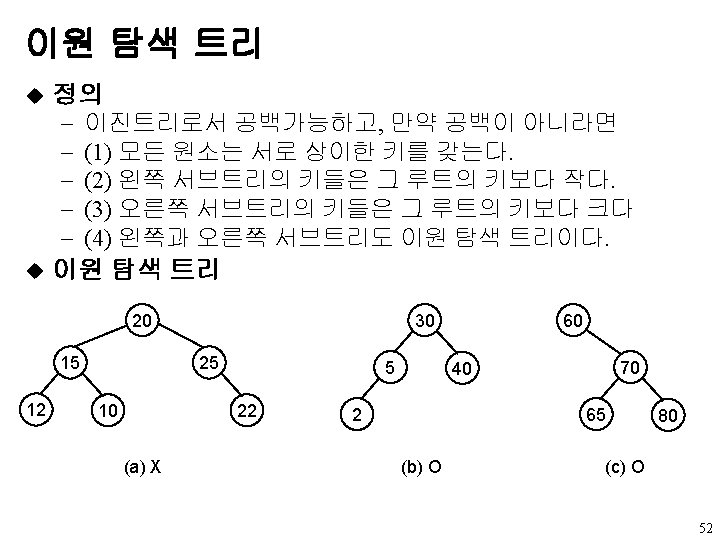

이원 탐색 트리의 탐색 k = 루트의 키 : 성공적 종료 u k < 루트의 키 : 왼쪽 서브트리 탐색 u k > 루트의 키 : 오른쪽 서브트리 탐색 u element* search(tree. Pointer tree, int key) { /* 키값이 key인 노드에 대한 포인터를 반환함. 그런 노드가 없는 경우에는 NULL을 반환 */ if (!root) return NULL; if (key == root->data) return root; if (key < root->data) return search(root->left_child, key); return search(root->right_child, key); } 53
 { /*")
이원 탐색 트리의 반복적 탐색 element* iter. Search(tree. Pointer tree, int key) { /* 키값이 key인 노드에 대한 포인터를 반환함. 그런 노드가 없는 경우는 NULL을 반환 */ while (tree) { if (key == tree->data) return tree; if (key < tree->data) tree = tree->left_child; else tree = tree->right_child; return NULL; } 54
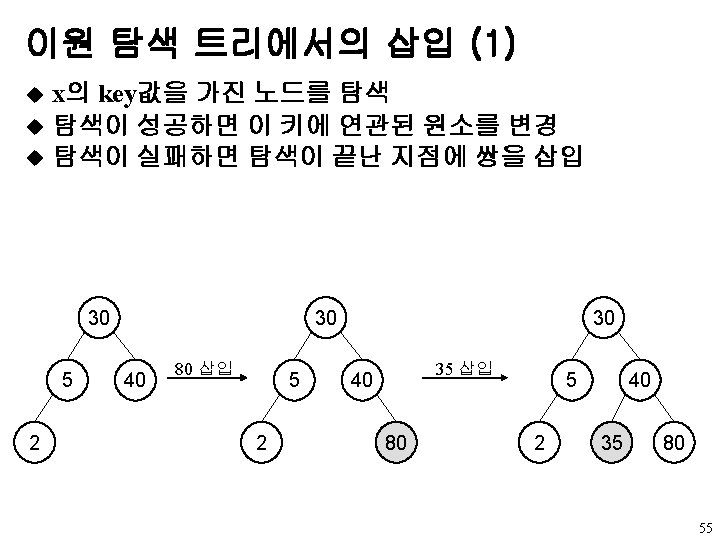
 void insert (tree. Pointer *node, int k, i. Type")
이원 탐색 트리에서의 삽입 (2) void insert (tree. Pointer *node, int k, i. Type the. Item) {/* 트리내의 노드가 k를 가리키고 있으면 아무 일도 하지 않음; 그렇지 않은 경우는 data=(k, the. Item)인 새 노드를 첨가 */ tree. Pointer ptr, temp = modified. Search(*node, k); if(temp || !(*node)) { /* k is not in the tree */ MALLOC(ptr, sizeof(*ptr)); ptr->data. key k; ptr->data. item = the. Item; ptr->left. Child = ptr->right. Child = NULL; if(*node) /* insert as child of temp */ if(k<temp->data. key) temp->left. Child = ptr; else temp->right. Child = ptr; else *node = ptr; } } 56


 void split (node. Pointer *the. Tree, int k, node.")
이원 탐색 트리의 분할 (1) void split (node. Pointer *the. Tree, int k, node. Pinter *small, element *mid, node. Pointer *big) {/* split the binary search tree with respect to key k */ if (!the. Tree) {*small = *big = 0; (*mid). key = -1; return ; } /* empty tree */ node. Pointer s. Head, b. Head, s, b, current. Node; /* create header nodes for small and big */ MALLOC(s. Head, sizeof(*s. Head)); MALLOC(BHead, sizeof(*b. Head)); s = s. Head; b = b. Head; /*do the split */ current. Node = *the. Tree; while (current. Node) if(k < current. Node->data. key){/*add to big */ b->left. Child = current. Node; b = current. Node; current. Node = current. Node->left. Child; } else if (k > current. Node->data. key){ /* add to small */ s->right. Child = current. Node; s = current. Node; current. Node = current. Node->right. Child; } 60
 else {/*split at current. Node */ s->right. Child =")
이원 탐색 트리의 분할 (2) else {/*split at current. Node */ s->right. Child = current. Node->left. Child; b->left. Child = current. Node->right. Child; *small = s. Head->right. Child; free(s. Head); *big = b. Head->left. Child; free(b. Head); (*mid). item = current. Node->data. item; (*mid). key = current. Node->data. key; free(current. Node); return; } /* no pair with key k */ s->right. Child = b->left. Child = 0; *small = s. Head->right. Child; free(s. Head); *big = b. Head->left. Child; free(b. Head); (*mid). key = -1; return; } 61


 u K=8인 경우의 승자 트리 1 6 2 3 6 8")
승자 트리 (2) u K=8인 경우의 승자 트리 1 6 2 3 6 8 4 5 9 6 8 9 7 6 8 10 11 17 12 13 14 10 9 20 6 8 9 90 15 17 15 20 20 15 15 11 95 18 16 38 30 25 50 16 99 20 run 5 run 6 run 7 run 8 28 run 1 run 2 run 3 run 4 64
 u 승자 트리에서 한 레코드가 출력되고 나서 재구성 - 새로 삽입된")
승자 트리 (3) u 승자 트리에서 한 레코드가 출력되고 나서 재구성 - 새로 삽입된 노드에서 루트까지의 경로를 따라 토너먼트 재 수행 1 8 2 3 9 8 4 5 9 15 8 9 7 6 8 10 11 17 10 9 20 15 8 9 90 15 17 15 20 20 25 15 11 95 18 16 38 30 28 50 16 99 20 run 1 run 2 run 3 run 5 run 6 run 7 run 8 run 4 12 13 14 65

 0 1 6 전체 승자 6 6 8 8 2 3")
패자 트리 (2) 0 1 6 전체 승자 6 6 8 8 2 3 9 9 6 4 10 5 8 9 10 9 Run 1 2 10 20 3 8 6 20 17 17 7 90 9 11 6 12 8 13 9 14 90 4 5 6 7 15 17 8 67



![합집합과 탐색을 위한 간단한 함수 int simple. Find(int i) { for(; parent[i] >= 0](http://slidetodoc.com/presentation_image/5b937558551595351e02a86038388533/image-76.jpg "합집합과 탐색을 위한 간단한 함수 int simple. Find(int i) { for(; parent[i] >= 0")
합집합과 탐색을 위한 간단한 함수 int simple. Find(int i) { for(; parent[i] >= 0 ; i = parent[i]) ; return i; } void simple. Union(int i, int j) { parent[i] = j; } 76

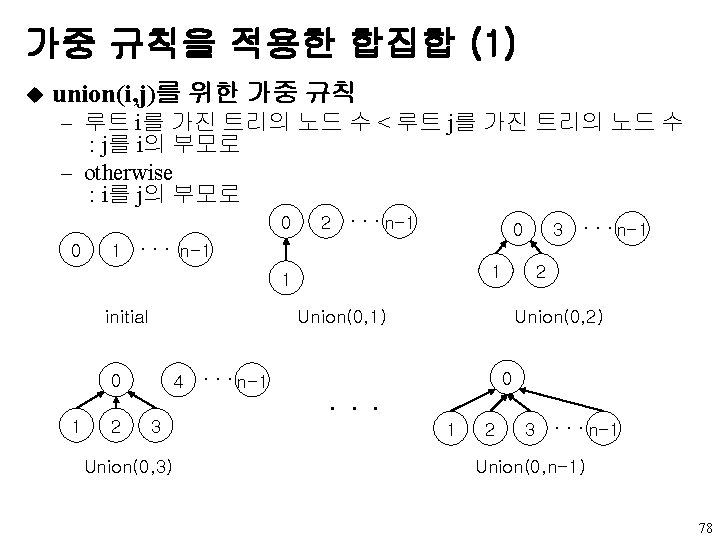
 u 모든 트리의 루트에 count(계수) 필드 유지 - 루트의")
가중 규칙을 이용한 합집합 (2) u 모든 트리의 루트에 count(계수) 필드 유지 - 루트의 parent는 -1이므로, 루트의 parent에 –count 유지 void weighted. Union(int i , int j) {/* union the sets with roots i and j, i !=j, using the weighting rule. parent[i] = -count[i] and parent[j] = -count[j] */ int temp = parent[i] + parent[j]; if(parent[i]>parent[j]){ parent[i] = j; /* make j the new root */ parent[j] = temp; } else { parent[j] = i; /*make i the new root */ parent[i] = temp; } } 79
 u Weighted. Find(=Simple. Find)")
Weighted. Union과 Weighted. Find의 분석 u Weighted. Union : O(1) u Weighted. Find(=Simple. Find) : O(log m) - 합집합의 결과가 m개의 노드를 가진 트리의 높이≤ u u-1개의 합집합 + f개의 탐색 : O(u+f log u) - 트리의 노드 수 ≤ u 80
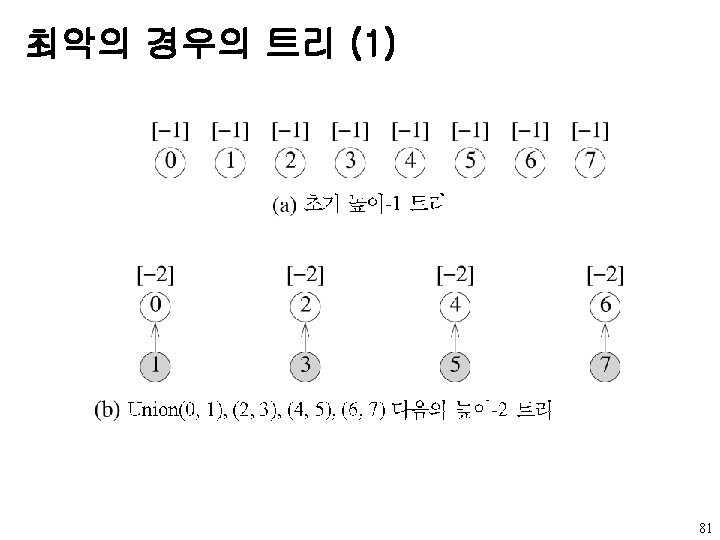
 - 만일 j가 i에서 루트로 가는")
붕괴규칙을 이용한 탐색 알고리즘 u 붕괴 규칙(collapsing rule) - 만일 j가 i에서 루트로 가는 경로 상에 있고 parent[i]≠root(i)면 parent[j]를 root(i)로 지정 int collapsing. Find(int i) { /* find the root of the tree containing elemnt i. Use the collapsing rule to collapse all nodes from i to root */ int root, trail, lead; for(root = i; parent[root] >=0; root = parent[root]) ; for(trail = i; trail !=root; trail = lead){ lead = parent[trail]; parent[trail] = root; } return root; } 83

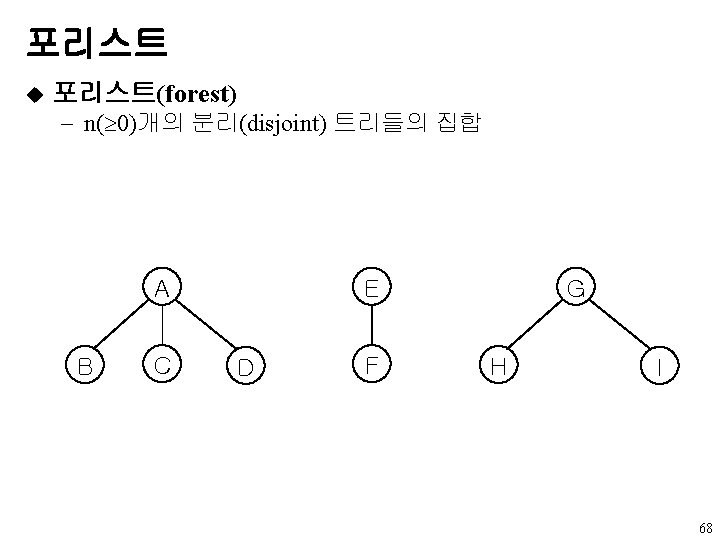
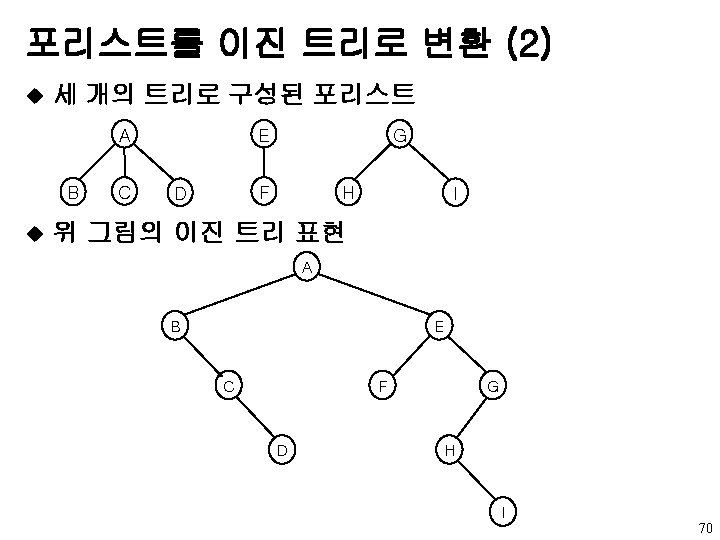
![동치 부류의 응용 예제 (1) [-1][-1][-1][-1][-1][-1] 0 1 2 3 4 5 6 7](http://slidetodoc.com/presentation_image/5b937558551595351e02a86038388533/image-85.jpg "동치 부류의 응용 예제 (1) [-1][-1][-1][-1][-1][-1] 0 1 2 3 4 5 6 7")
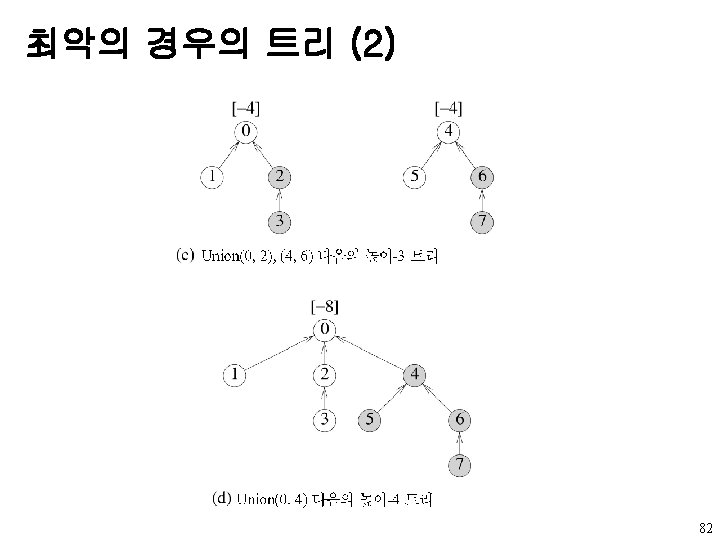
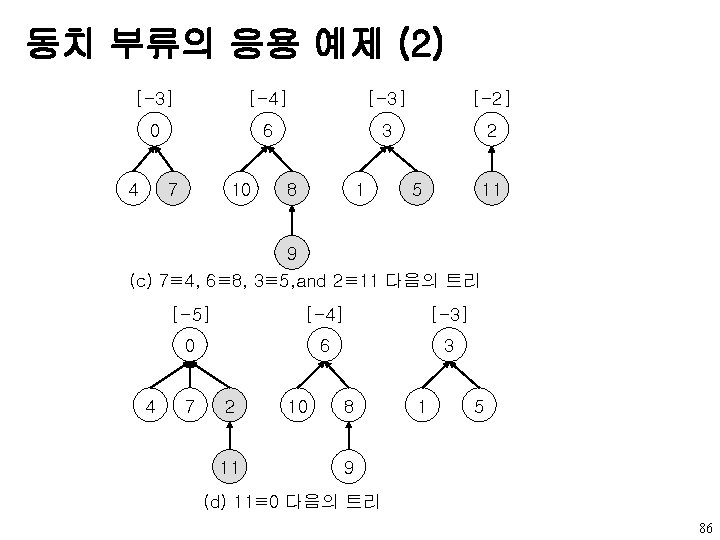
동치 부류의 응용 예제 (1) [-1][-1][-1][-1][-1][-1] 0 1 2 3 4 5 6 7 8 10 9 11 (a) Initial trees [-2] [-1] [-1] 0 3 6 8 2 5 7 11 4 1 10 9 0≡ 4, 3≡ 1, 6≡ 10, and 8≡ 9 다음의 높이-2 트리 85



- Slides: 93